 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePAI3D: Painting Adaptive Instance-Prior for 3D Object Detection
Nov 15, 2022



3D object detection is a critical task in autonomous driving. Recently multi-modal fusion-based 3D object detection methods, which combine the complementary advantages of LiDAR and camera, have shown great performance improvements over mono-modal methods. However, so far, no methods have attempted to utilize the instance-level contextual image semantics to guide the 3D object detection. In this paper, we propose a simple and effective Painting Adaptive Instance-prior for 3D object detection (PAI3D) to fuse instance-level image semantics flexibly with point cloud features. PAI3D is a multi-modal sequential instance-level fusion framework. It first extracts instance-level semantic information from images, the extracted information, including objects categorical label, point-to-object membership and object position, are then used to augment each LiDAR point in the subsequent 3D detection network to guide and improve detection performance. PAI3D outperforms the state-of-the-art with a large margin on the nuScenes dataset, achieving 71.4 in mAP and 74.2 in NDS on the test split. Our comprehensive experiments show that instance-level image semantics contribute the most to the performance gain, and PAI3D works well with any good-quality instance segmentation models and any modern point cloud 3D encoders, making it a strong candidate for deployment on autonomous vehicles.
Fast DistilBERT on CPUs
Oct 27, 2022Transformer-based language models have become the standard approach to solving natural language processing tasks. However, industry adoption usually requires the maximum throughput to comply with certain latency constraints that prevents Transformer models from being used in production. To address this gap, model compression techniques such as quantization and pruning may be used to improve inference efficiency. However, these compression techniques require specialized software to apply and deploy at scale. In this work, we propose a new pipeline for creating and running Fast Transformer models on CPUs, utilizing hardware-aware pruning, knowledge distillation, quantization, and our own Transformer inference runtime engine with optimized kernels for sparse and quantized operators. We demonstrate the efficiency of our pipeline by creating a Fast DistilBERT model showing minimal accuracy loss on the question-answering SQuADv1.1 benchmark, and throughput results under typical production constraints and environments. Our results outperform existing state-of-the-art Neural Magic's DeepSparse runtime performance by up to 50% and up to 4.1x performance speedup over ONNX Runtime.
ASD: Towards Attribute Spatial Decomposition for Prior-Free Facial Attribute Recognition
Oct 25, 2022



Representing the spatial properties of facial attributes is a vital challenge for facial attribute recognition (FAR). Recent advances have achieved the reliable performances for FAR, benefiting from the description of spatial properties via extra prior information. However, the extra prior information might not be always available, resulting in the restricted application scenario of the prior-based methods. Meanwhile, the spatial ambiguity of facial attributes caused by inherent spatial diversities of facial parts is ignored. To address these issues, we propose a prior-free method for attribute spatial decomposition (ASD), mitigating the spatial ambiguity of facial attributes without any extra prior information. Specifically, assignment-embedding module (AEM) is proposed to enable the procedure of ASD, which consists of two operations: attribute-to-location assignment and location-to-attribute embedding. The attribute-to-location assignment first decomposes the feature map based on latent factors, assigning the magnitude of attribute components on each spatial location. Then, the assigned attribute components from all locations to represent the global-level attribute embeddings. Furthermore, correlation matrix minimization (CMM) is introduced to enlarge the discriminability of attribute embeddings. Experimental results demonstrate the superiority of ASD compared with state-of-the-art prior-based methods, while the reliable performance of ASD for the case of limited training data is further validated.
Point Cloud Scene Completion with Joint Color and Semantic Estimation from Single RGB-D Image
Oct 12, 2022
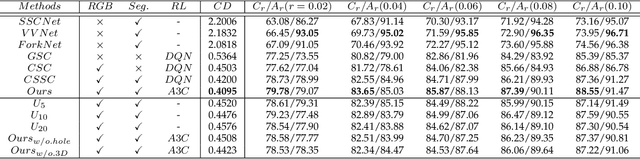
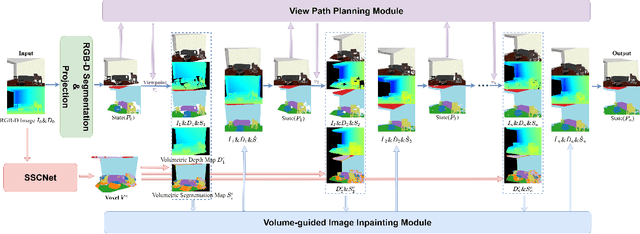
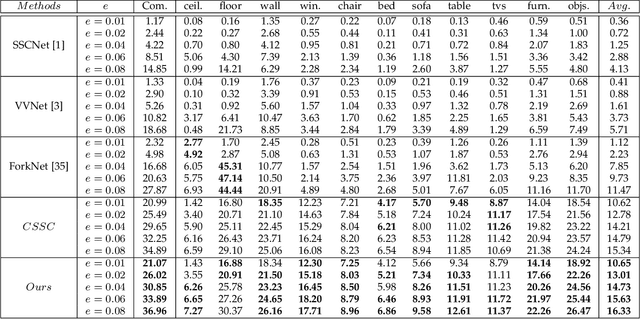
We present a deep reinforcement learning method of progressive view inpainting for colored semantic point cloud scene completion under volume guidance, achieving high-quality scene reconstruction from only a single RGB-D image with severe occlusion. Our approach is end-to-end, consisting of three modules: 3D scene volume reconstruction, 2D RGB-D and segmentation image inpainting, and multi-view selection for completion. Given a single RGB-D image, our method first predicts its semantic segmentation map and goes through the 3D volume branch to obtain a volumetric scene reconstruction as a guide to the next view inpainting step, which attempts to make up the missing information; the third step involves projecting the volume under the same view of the input, concatenating them to complete the current view RGB-D and segmentation map, and integrating all RGB-D and segmentation maps into the point cloud. Since the occluded areas are unavailable, we resort to a A3C network to glance around and pick the next best view for large hole completion progressively until a scene is adequately reconstructed while guaranteeing validity. All steps are learned jointly to achieve robust and consistent results. We perform qualitative and quantitative evaluations with extensive experiments on the 3D-FUTURE data, obtaining better results than state-of-the-arts.
Biologically Inspired Dynamic Thresholds for Spiking Neural Networks
Jun 09, 2022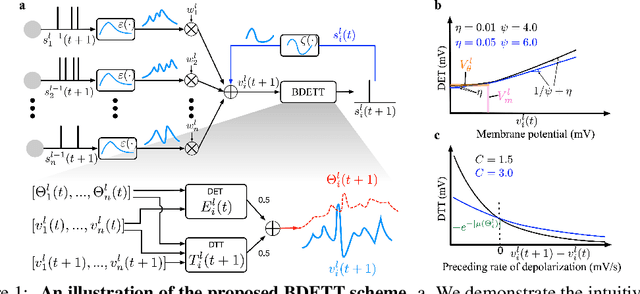
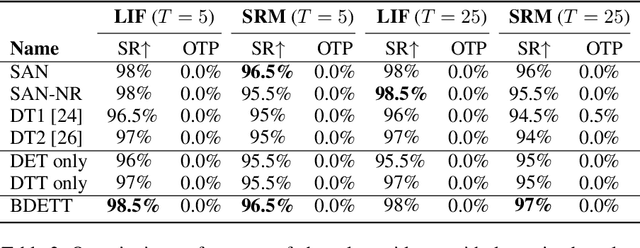
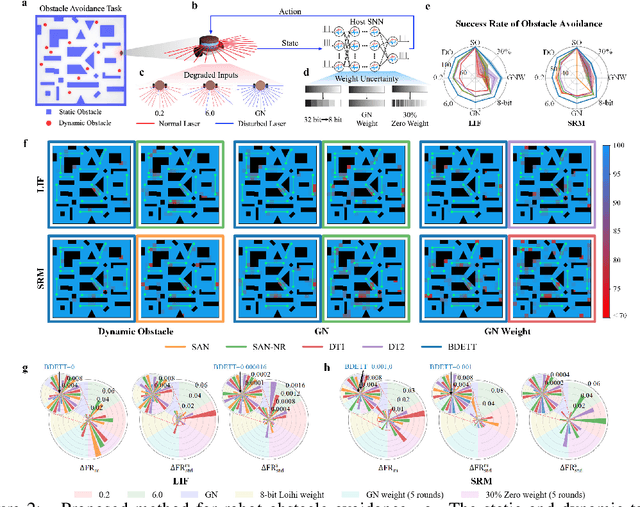
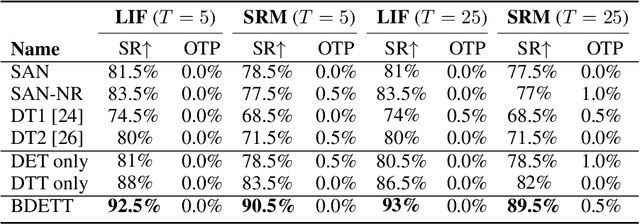
The dynamic membrane potential threshold, as one of the essential properties of a biological neuron, is a spontaneous regulation mechanism that maintains neuronal homeostasis, i.e., the constant overall spiking firing rate of a neuron. As such, the neuron firing rate is regulated by a dynamic spiking threshold, which has been extensively studied in biology. Existing work in the machine learning community does not employ bioplausible spiking threshold schemes. This work aims at bridging this gap by introducing a novel bioinspired dynamic energy-temporal threshold (BDETT) scheme for spiking neural networks (SNNs). The proposed BDETT scheme mirrors two bioplausible observations: a dynamic threshold has 1) a positive correlation with the average membrane potential and 2) a negative correlation with the preceding rate of depolarization. We validate the effectiveness of the proposed BDETT on robot obstacle avoidance and continuous control tasks under both normal conditions and various degraded conditions, including noisy observations, weights, and dynamic environments. We find that the BDETT outperforms existing static and heuristic threshold approaches by significant margins in all tested conditions, and we confirm that the proposed bioinspired dynamic threshold scheme offers bioplausible homeostasis to SNNs in complex real-world tasks.
Computationally Efficient Approximations for Matrix-based Renyi's Entropy
Dec 27, 2021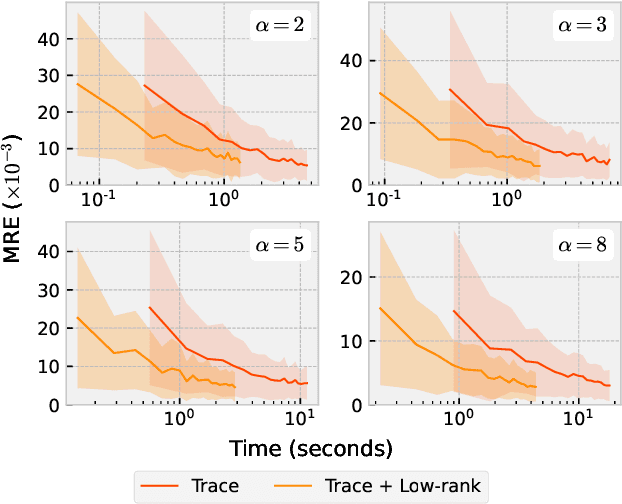
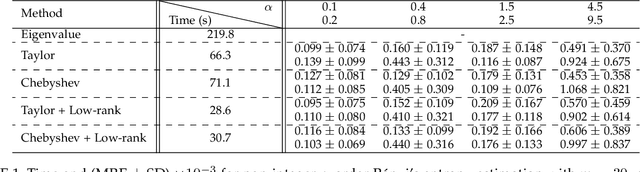
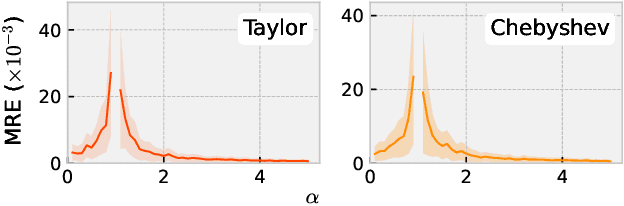
The recently developed matrix based Renyi's entropy enables measurement of information in data simply using the eigenspectrum of symmetric positive semi definite (PSD) matrices in reproducing kernel Hilbert space, without estimation of the underlying data distribution. This intriguing property makes the new information measurement widely adopted in multiple statistical inference and learning tasks. However, the computation of such quantity involves the trace operator on a PSD matrix $G$ to power $\alpha$(i.e., $tr(G^\alpha)$), with a normal complexity of nearly $O(n^3)$, which severely hampers its practical usage when the number of samples (i.e., $n$) is large. In this work, we present computationally efficient approximations to this new entropy functional that can reduce its complexity to even significantly less than $O(n^2)$. To this end, we first develop randomized approximations to $\tr(\G^\alpha)$ that transform the trace estimation into matrix-vector multiplications problem. We extend such strategy for arbitrary values of $\alpha$ (integer or non-integer). We then establish the connection between the matrix-based Renyi's entropy and PSD matrix approximation, which enables us to exploit both clustering and block low-rank structure of $\G$ to further reduce the computational cost. We theoretically provide approximation accuracy guarantees and illustrate the properties of different approximations. Large-scale experimental evaluations on both synthetic and real-world data corroborate our theoretical findings, showing promising speedup with negligible loss in accuracy.
All You Need is RAW: Defending Against Adversarial Attacks with Camera Image Pipelines
Dec 16, 2021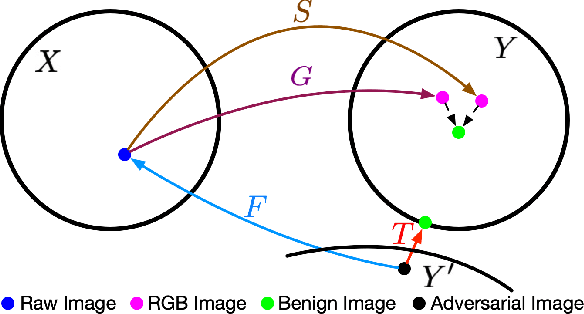
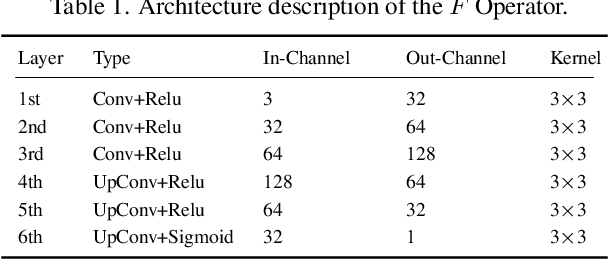
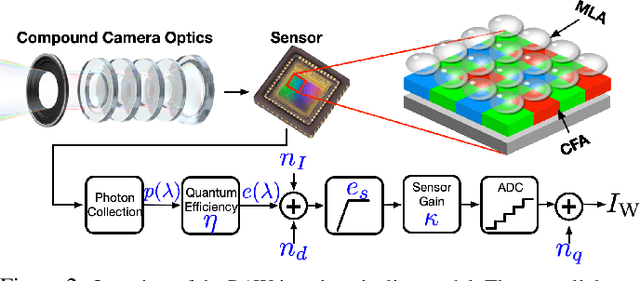
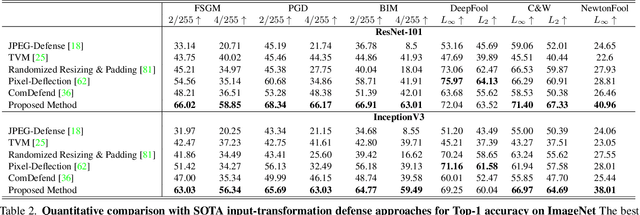
Existing neural networks for computer vision tasks are vulnerable to adversarial attacks: adding imperceptible perturbations to the input images can fool these methods to make a false prediction on an image that was correctly predicted without the perturbation. Various defense methods have proposed image-to-image mapping methods, either including these perturbations in the training process or removing them in a preprocessing denoising step. In doing so, existing methods often ignore that the natural RGB images in today's datasets are not captured but, in fact, recovered from RAW color filter array captures that are subject to various degradations in the capture. In this work, we exploit this RAW data distribution as an empirical prior for adversarial defense. Specifically, we proposed a model-agnostic adversarial defensive method, which maps the input RGB images to Bayer RAW space and back to output RGB using a learned camera image signal processing (ISP) pipeline to eliminate potential adversarial patterns. The proposed method acts as an off-the-shelf preprocessing module and, unlike model-specific adversarial training methods, does not require adversarial images to train. As a result, the method generalizes to unseen tasks without additional retraining. Experiments on large-scale datasets (e.g., ImageNet, COCO) for different vision tasks (e.g., classification, semantic segmentation, object detection) validate that the method significantly outperforms existing methods across task domains.
Markov subsampling based Huber Criterion
Dec 12, 2021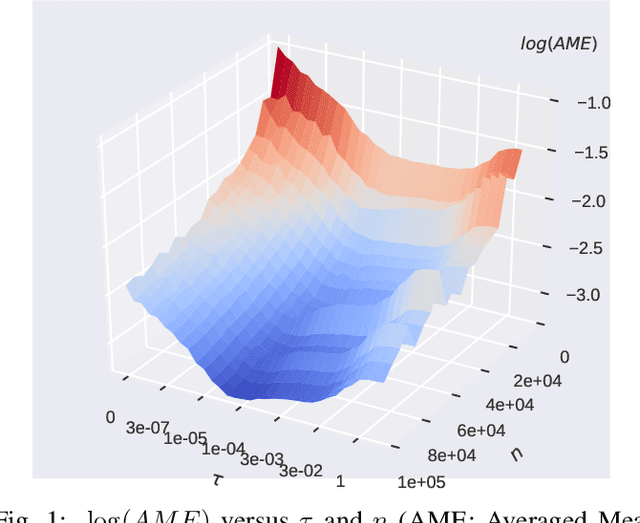
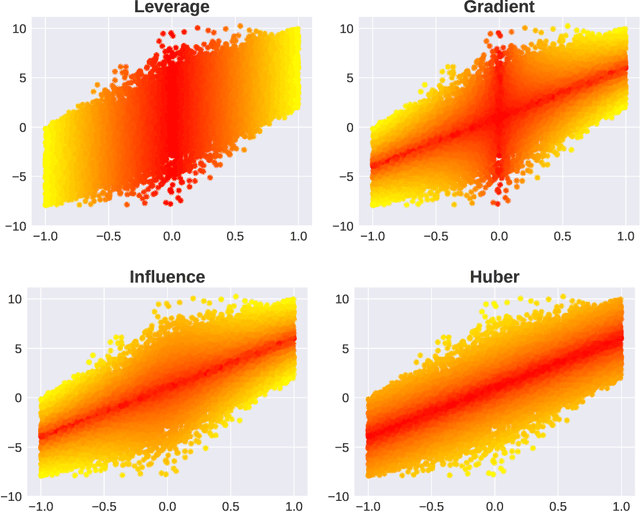
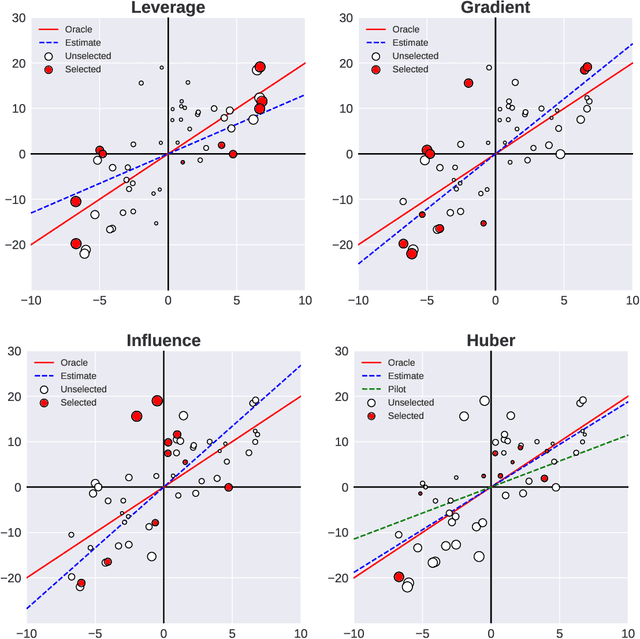
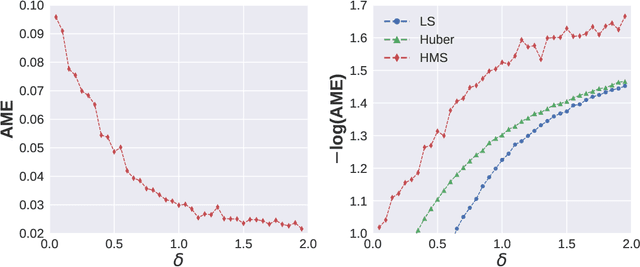
Subsampling is an important technique to tackle the computational challenges brought by big data. Many subsampling procedures fall within the framework of importance sampling, which assigns high sampling probabilities to the samples appearing to have big impacts. When the noise level is high, those sampling procedures tend to pick many outliers and thus often do not perform satisfactorily in practice. To tackle this issue, we design a new Markov subsampling strategy based on Huber criterion (HMS) to construct an informative subset from the noisy full data; the constructed subset then serves as a refined working data for efficient processing. HMS is built upon a Metropolis-Hasting procedure, where the inclusion probability of each sampling unit is determined using the Huber criterion to prevent over scoring the outliers. Under mild conditions, we show that the estimator based on the subsamples selected by HMS is statistically consistent with a sub-Gaussian deviation bound. The promising performance of HMS is demonstrated by extensive studies on large scale simulations and real data examples.
Regularized Modal Regression on Markov-dependent Observations: A Theoretical Assessment
Dec 09, 2021Modal regression, a widely used regression protocol, has been extensively investigated in statistical and machine learning communities due to its robustness to outliers and heavy-tailed noises. Understanding modal regression's theoretical behavior can be fundamental in learning theory. Despite significant progress in characterizing its statistical property, the majority of the results are based on the assumption that samples are independent and identical distributed (i.i.d.), which is too restrictive for real-world applications. This paper concerns the statistical property of regularized modal regression (RMR) within an important dependence structure - Markov dependent. Specifically, we establish the upper bound for RMR estimator under moderate conditions and give an explicit learning rate. Our results show that the Markov dependence impacts on the generalization error in the way that sample size would be discounted by a multiplicative factor depending on the spectral gap of underlying Markov chain. This result shed a new light on characterizing the theoretical underpinning for robust regression.
TNTC: two-stream network with transformer-based complementarity for gait-based emotion recognition
Oct 26, 2021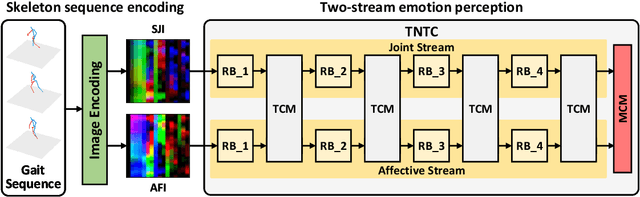
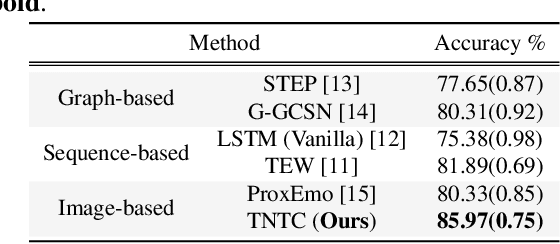

Recognizing the human emotion automatically from visual characteristics plays a vital role in many intelligent applications. Recently, gait-based emotion recognition, especially gait skeletons-based characteristic, has attracted much attention, while many available methods have been proposed gradually. The popular pipeline is to first extract affective features from joint skeletons, and then aggregate the skeleton joint and affective features as the feature vector for classifying the emotion. However, the aggregation procedure of these emerged methods might be rigid, resulting in insufficiently exploiting the complementary relationship between skeleton joint and affective features. Meanwhile, the long range dependencies in both spatial and temporal domains of the gait sequence are scarcely considered. To address these issues, we propose a novel two-stream network with transformer-based complementarity, termed as TNTC. Skeleton joint and affective features are encoded into two individual images as the inputs of two streams, respectively. A new transformer-based complementarity module (TCM) is proposed to bridge the complementarity between two streams hierarchically via capturing long range dependencies. Experimental results demonstrate TNTC outperforms state-of-the-art methods on the latest dataset in terms of accuracy.