 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTED: Training-Free Experience Distillation for Multimodal Reasoning
Mar 25, 2026Knowledge distillation is typically realized by transferring a teacher model's knowledge into a student's parameters through supervised or reinforcement-based optimization. While effective, such approaches require repeated parameter updates and large-scale training data, limiting their applicability in resource-constrained environments. In this work, we propose TED, a training-free, context-based distillation framework that shifts the update target of distillation from model parameters to an in-context experience injected into the student's prompt. For each input, the student generates multiple reasoning trajectories, while a teacher independently produces its own solution. The teacher then compares the student trajectories with its reasoning and the ground-truth answer, extracting generalized experiences that capture effective reasoning patterns. These experiences are continuously refined and updated over time. A key challenge of context-based distillation is unbounded experience growth and noise accumulation. TED addresses this with an experience compression mechanism that tracks usage statistics and selectively merges, rewrites, or removes low-utility experiences. Experiments on multimodal reasoning benchmarks MathVision and VisualPuzzles show that TED consistently improves performance. On MathVision, TED raises the performance of Qwen3-VL-8B from 0.627 to 0.702, and on VisualPuzzles from 0.517 to 0.561 with just 100 training samples. Under this low-data, no-update setting, TED achieves performance competitive with fully trained parameter-based distillation while reducing training cost by over 5x, demonstrating that meaningful knowledge transfer can be achieved through contextual experience.
OpenSUN3D: 1st Workshop Challenge on Open-Vocabulary 3D Scene Understanding
Feb 23, 2024



This report provides an overview of the challenge hosted at the OpenSUN3D Workshop on Open-Vocabulary 3D Scene Understanding held in conjunction with ICCV 2023. The goal of this workshop series is to provide a platform for exploration and discussion of open-vocabulary 3D scene understanding tasks, including but not limited to segmentation, detection and mapping. We provide an overview of the challenge hosted at the workshop, present the challenge dataset, the evaluation methodology, and brief descriptions of the winning methods. For additional details, please see https://opensun3d.github.io/index_iccv23.html.
Multi-Features Guidance Network for partial-to-partial point cloud registration
Nov 24, 2020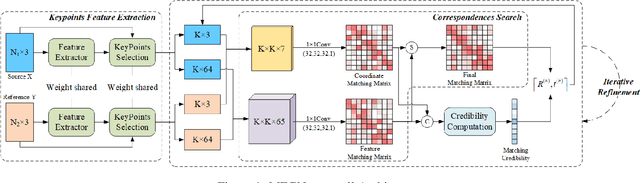
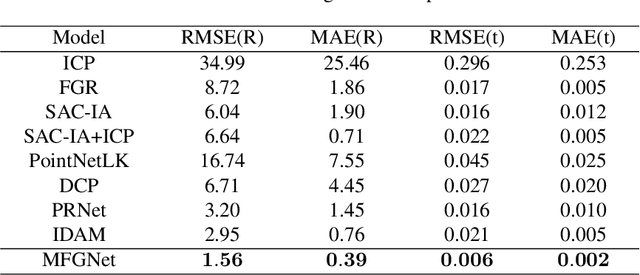
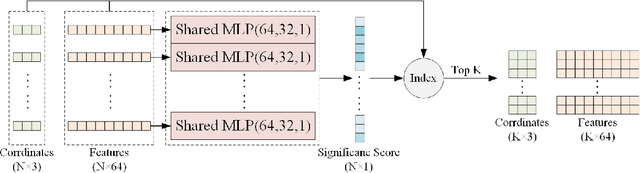
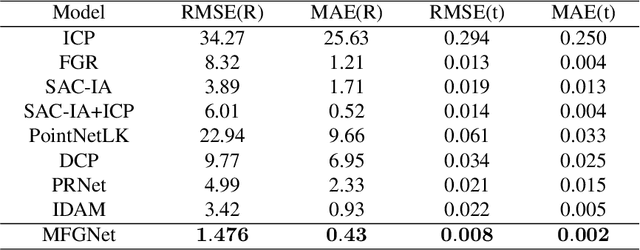
To eliminate the problems of large dimensional differences, big semantic gap, and mutual interference caused by hybrid features, in this paper, we propose a novel Multi-Features Guidance Network for partial-to-partial point cloud registration(MFG). The proposed network mainly includes four parts: keypoints' feature extraction, correspondences searching, correspondences credibility computation, and SVD, among which correspondences searching and correspondence credibility computation are the cores of the network. Unlike the previous work, we utilize the shape features and the spatial coordinates to guide correspondences search independently and fusing the matching results to obtain the final matching matrix. In the correspondences credibility computation module, based on the conflicted relationship between the features matching matrix and the coordinates matching matrix, we score the reliability for each correspondence, which can reduce the impact of mismatched or non-matched points. Experimental results show that our network outperforms the current state-of-the-art while maintaining computational efficiency.