 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRobust Visual Imitation Learning with Inverse Dynamics Representations
Oct 22, 2023



Imitation learning (IL) has achieved considerable success in solving complex sequential decision-making problems. However, current IL methods mainly assume that the environment for learning policies is the same as the environment for collecting expert datasets. Therefore, these methods may fail to work when there are slight differences between the learning and expert environments, especially for challenging problems with high-dimensional image observations. However, in real-world scenarios, it is rare to have the chance to collect expert trajectories precisely in the target learning environment. To address this challenge, we propose a novel robust imitation learning approach, where we develop an inverse dynamics state representation learning objective to align the expert environment and the learning environment. With the abstract state representation, we design an effective reward function, which thoroughly measures the similarity between behavior data and expert data not only element-wise, but also from the trajectory level. We conduct extensive experiments to evaluate the proposed approach under various visual perturbations and in diverse visual control tasks. Our approach can achieve a near-expert performance in most environments, and significantly outperforms the state-of-the-art visual IL methods and robust IL methods.
Density-based Curriculum for Multi-goal Reinforcement Learning with Sparse Rewards
Sep 24, 2021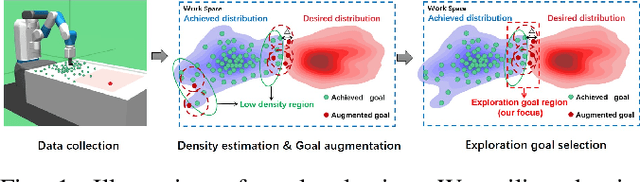
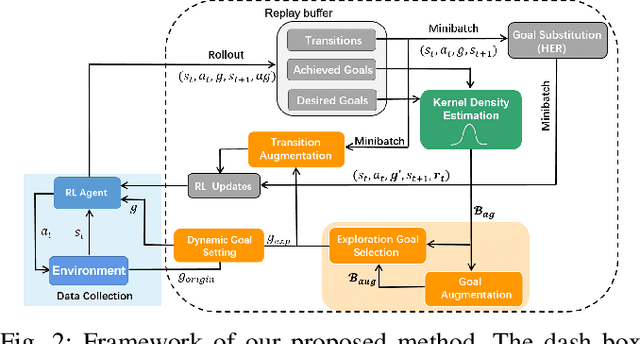

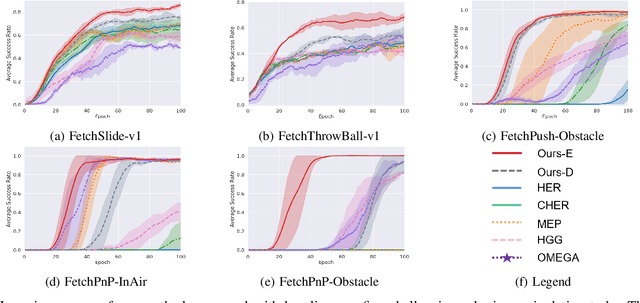
Multi-goal reinforcement learning (RL) aims to qualify the agent to accomplish multi-goal tasks, which is of great importance in learning scalable robotic manipulation skills. However, reward engineering always requires strenuous efforts in multi-goal RL. Moreover, it will introduce inevitable bias causing the suboptimality of the final policy. The sparse reward provides a simple yet efficient way to overcome such limits. Nevertheless, it harms the exploration efficiency and even hinders the policy from convergence. In this paper, we propose a density-based curriculum learning method for efficient exploration with sparse rewards and better generalization to desired goal distribution. Intuitively, our method encourages the robot to gradually broaden the frontier of its ability along the directions to cover the entire desired goal space as much and quickly as possible. To further improve data efficiency and generality, we augment the goals and transitions within the allowed region during training. Finally, We evaluate our method on diversified variants of benchmark manipulation tasks that are challenging for existing methods. Empirical results show that our method outperforms the state-of-the-art baselines in terms of both data efficiency and success rate.
MBDF-Net: Multi-Branch Deep Fusion Network for 3D Object Detection
Aug 29, 2021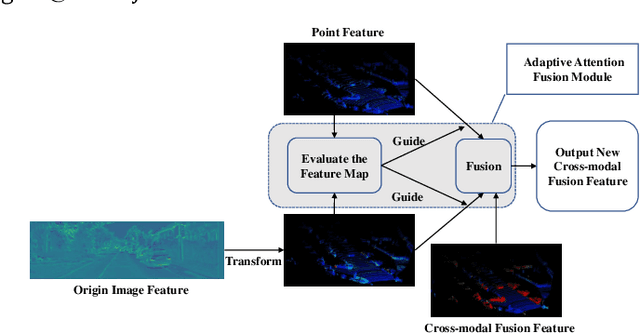
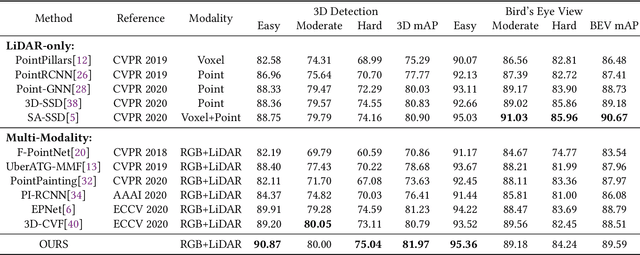
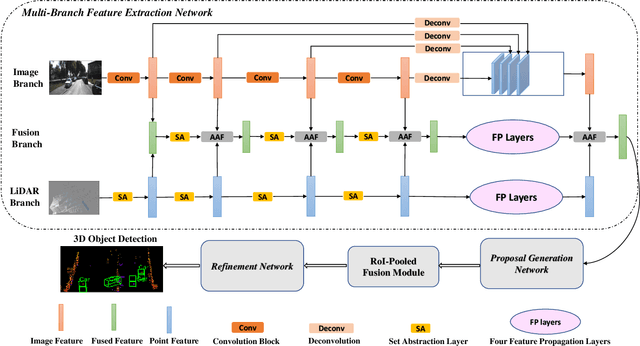
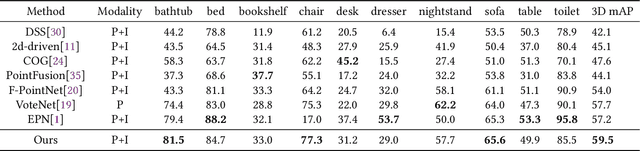
Point clouds and images could provide complementary information when representing 3D objects. Fusing the two kinds of data usually helps to improve the detection results. However, it is challenging to fuse the two data modalities, due to their different characteristics and the interference from the non-interest areas. To solve this problem, we propose a Multi-Branch Deep Fusion Network (MBDF-Net) for 3D object detection. The proposed detector has two stages. In the first stage, our multi-branch feature extraction network utilizes Adaptive Attention Fusion (AAF) modules to produce cross-modal fusion features from single-modal semantic features. In the second stage, we use a region of interest (RoI) -pooled fusion module to generate enhanced local features for refinement. A novel attention-based hybrid sampling strategy is also proposed for selecting key points in the downsampling process. We evaluate our approach on two widely used benchmark datasets including KITTI and SUN-RGBD. The experimental results demonstrate the advantages of our method over state-of-the-art approaches.
REGRAD: A Large-Scale Relational Grasp Dataset for Safe and Object-Specific Robotic Grasping in Clutter
May 31, 2021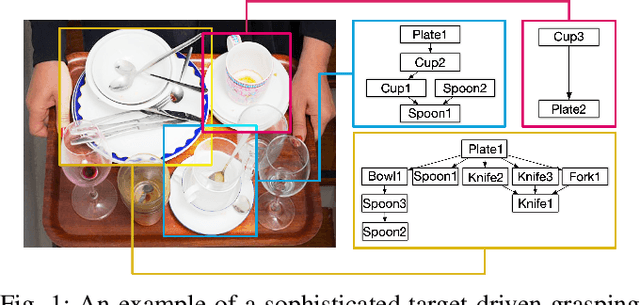
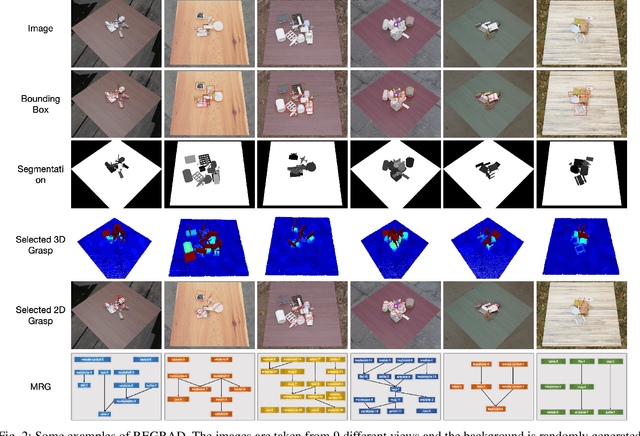
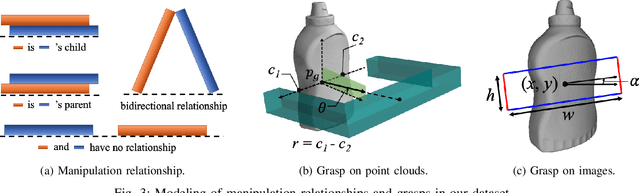
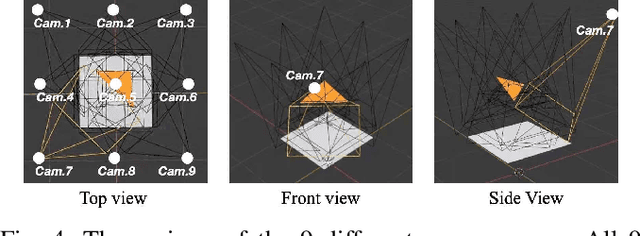
Despite the impressive progress achieved in robust grasp detection, robots are not skilled in sophisticated grasping tasks (e.g. search and grasp a specific object in clutter). Such tasks involve not only grasping, but comprehensive perception of the visual world (e.g. the relationship between objects). Recently, the advanced deep learning techniques provide a promising way for understanding the high-level visual concepts. It encourages robotic researchers to explore solutions for such hard and complicated fields. However, deep learning usually means data-hungry. The lack of data severely limits the performance of deep-learning-based algorithms. In this paper, we present a new dataset named \regrad to sustain the modeling of relationships among objects and grasps. We collect the annotations of object poses, segmentations, grasps, and relationships in each image for comprehensive perception of grasping. Our dataset is collected in both forms of 2D images and 3D point clouds. Moreover, since all the data are generated automatically, users are free to import their own object models for the generation of as many data as they want. We have released our dataset and codes. A video that demonstrates the process of data generation is also available.