 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeIDGI: A Framework to Eliminate Explanation Noise from Integrated Gradients
Mar 24, 2023



Integrated Gradients (IG) as well as its variants are well-known techniques for interpreting the decisions of deep neural networks. While IG-based approaches attain state-of-the-art performance, they often integrate noise into their explanation saliency maps, which reduce their interpretability. To minimize the noise, we examine the source of the noise analytically and propose a new approach to reduce the explanation noise based on our analytical findings. We propose the Important Direction Gradient Integration (IDGI) framework, which can be easily incorporated into any IG-based method that uses the Reimann Integration for integrated gradient computation. Extensive experiments with three IG-based methods show that IDGI improves them drastically on numerous interpretability metrics.
UniCR: Universally Approximated Certified Robustness via Randomized Smoothing
Jul 10, 2022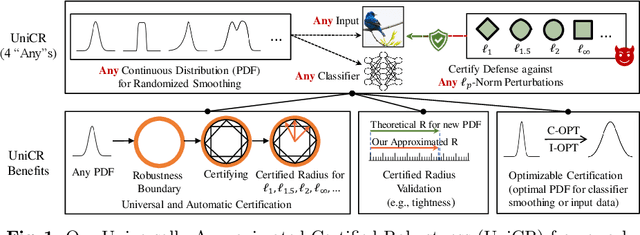
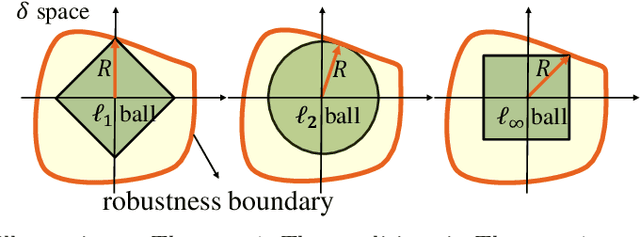
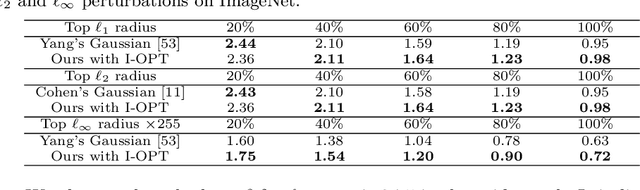
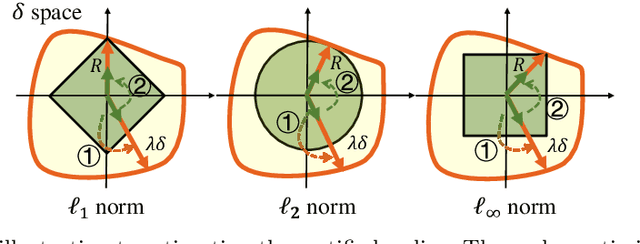
We study certified robustness of machine learning classifiers against adversarial perturbations. In particular, we propose the first universally approximated certified robustness (UniCR) framework, which can approximate the robustness certification of any input on any classifier against any $\ell_p$ perturbations with noise generated by any continuous probability distribution. Compared with the state-of-the-art certified defenses, UniCR provides many significant benefits: (1) the first universal robustness certification framework for the above 4 'any's; (2) automatic robustness certification that avoids case-by-case analysis, (3) tightness validation of certified robustness, and (4) optimality validation of noise distributions used by randomized smoothing. We conduct extensive experiments to validate the above benefits of UniCR and the advantages of UniCR over state-of-the-art certified defenses against $\ell_p$ perturbations.
NeuGuard: Lightweight Neuron-Guided Defense against Membership Inference Attacks
Jun 11, 2022
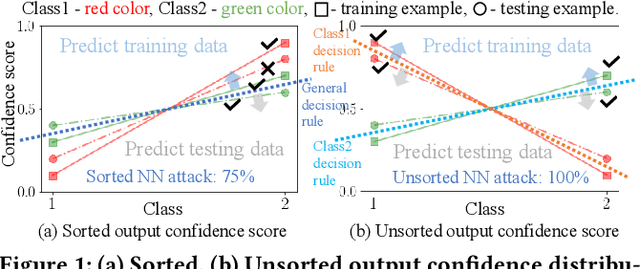
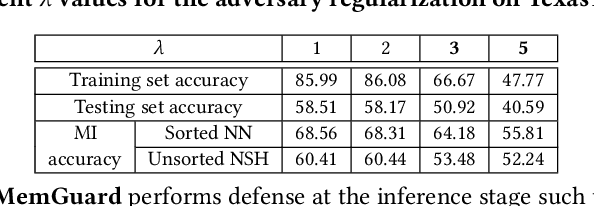
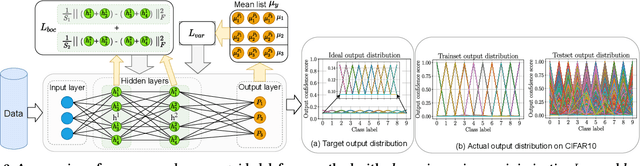
Membership inference attacks (MIAs) against machine learning models can lead to serious privacy risks for the training dataset used in the model training. In this paper, we propose a novel and effective Neuron-Guided Defense method named NeuGuard against membership inference attacks (MIAs). We identify a key weakness in existing defense mechanisms against MIAs wherein they cannot simultaneously defend against two commonly used neural network based MIAs, indicating that these two attacks should be separately evaluated to assure the defense effectiveness. We propose NeuGuard, a new defense approach that jointly controls the output and inner neurons' activation with the object to guide the model output of training set and testing set to have close distributions. NeuGuard consists of class-wise variance minimization targeting restricting the final output neurons and layer-wise balanced output control aiming to constrain the inner neurons in each layer. We evaluate NeuGuard and compare it with state-of-the-art defenses against two neural network based MIAs, five strongest metric based MIAs including the newly proposed label-only MIA on three benchmark datasets. Results show that NeuGuard outperforms the state-of-the-art defenses by offering much improved utility-privacy trade-off, generality, and overhead.
Bandits for Structure Perturbation-based Black-box Attacks to Graph Neural Networks with Theoretical Guarantees
May 07, 2022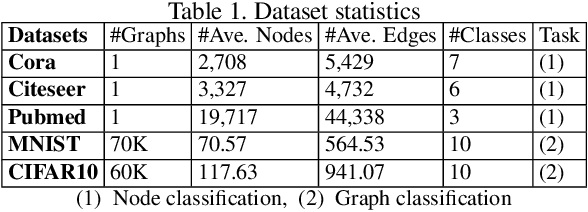
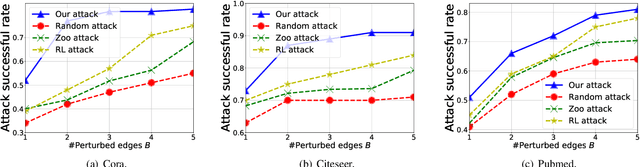
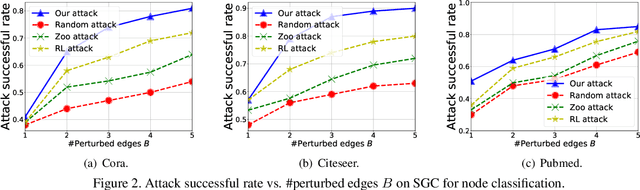
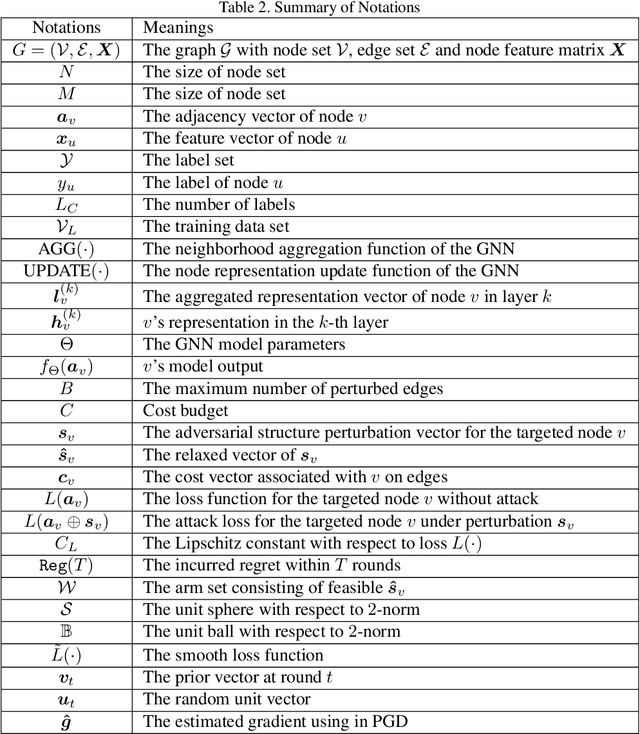
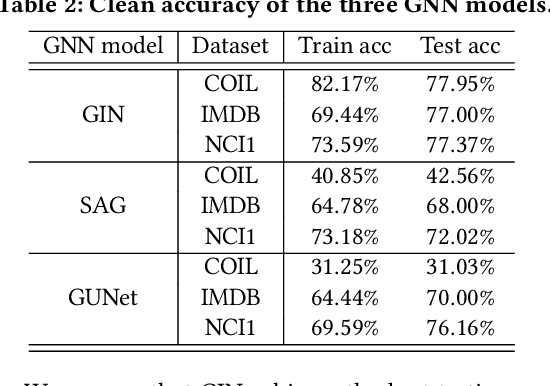
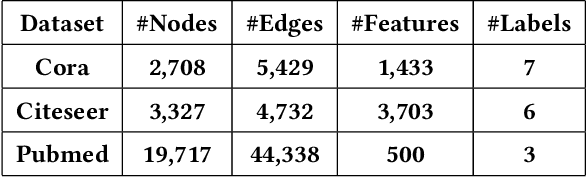
Graph neural networks (GNNs) have achieved state-of-the-art performance in many graph-based tasks such as node classification and graph classification. However, many recent works have demonstrated that an attacker can mislead GNN models by slightly perturbing the graph structure. Existing attacks to GNNs are either under the less practical threat model where the attacker is assumed to access the GNN model parameters, or under the practical black-box threat model but consider perturbing node features that are shown to be not enough effective. In this paper, we aim to bridge this gap and consider black-box attacks to GNNs with structure perturbation as well as with theoretical guarantees. We propose to address this challenge through bandit techniques. Specifically, we formulate our attack as an online optimization with bandit feedback. This original problem is essentially NP-hard due to the fact that perturbing the graph structure is a binary optimization problem. We then propose an online attack based on bandit optimization which is proven to be {sublinear} to the query number $T$, i.e., $\mathcal{O}(\sqrt{N}T^{3/4})$ where $N$ is the number of nodes in the graph. Finally, we evaluate our proposed attack by conducting experiments over multiple datasets and GNN models. The experimental results on various citation graphs and image graphs show that our attack is both effective and efficient. Source code is available at~\url{https://github.com/Metaoblivion/Bandit_GNN_Attack}
Detecting Gender Bias in Transformer-based Models: A Case Study on BERT
Oct 15, 2021
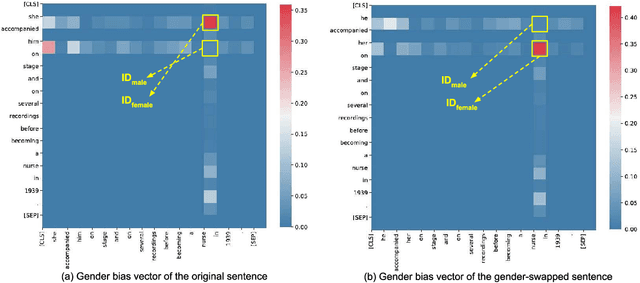
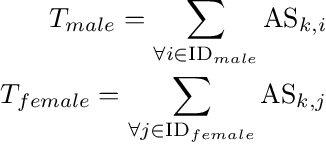
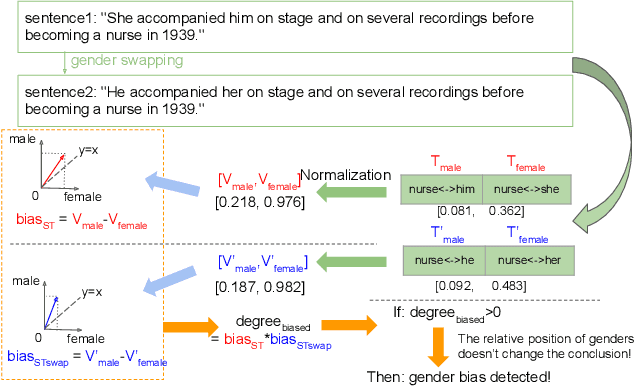
In this paper, we propose a novel gender bias detection method by utilizing attention map for transformer-based models. We 1) give an intuitive gender bias judgement method by comparing the different relation degree between the genders and the occupation according to the attention scores, 2) design a gender bias detector by modifying the attention module, 3) insert the gender bias detector into different positions of the model to present the internal gender bias flow, and 4) draw the consistent gender bias conclusion by scanning the entire Wikipedia, a BERT pretraining dataset. We observe that 1) the attention matrices, Wq and Wk introduce much more gender bias than other modules (including the embedding layer) and 2) the bias degree changes periodically inside of the model (attention matrix Q, K, V, and the remaining part of the attention layer (including the fully-connected layer, the residual connection, and the layer normalization module) enhance the gender bias while the averaged attentions reduces the bias).
A Hard Label Black-box Adversarial Attack Against Graph Neural Networks
Aug 21, 2021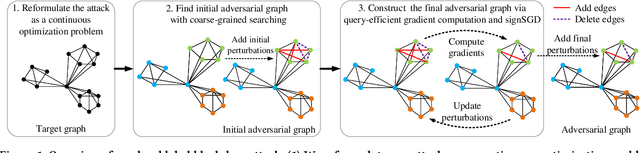
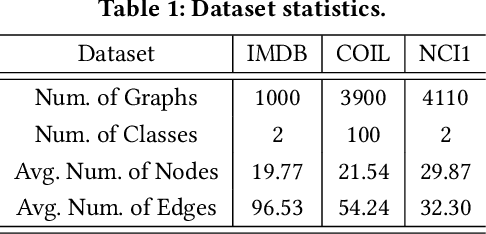
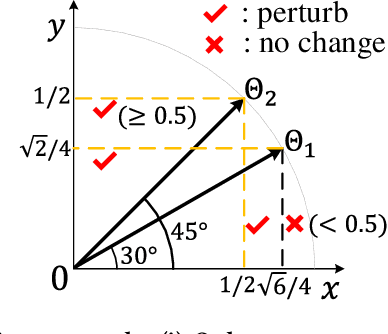
Graph Neural Networks (GNNs) have achieved state-of-the-art performance in various graph structure related tasks such as node classification and graph classification. However, GNNs are vulnerable to adversarial attacks. Existing works mainly focus on attacking GNNs for node classification; nevertheless, the attacks against GNNs for graph classification have not been well explored. In this work, we conduct a systematic study on adversarial attacks against GNNs for graph classification via perturbing the graph structure. In particular, we focus on the most challenging attack, i.e., hard label black-box attack, where an attacker has no knowledge about the target GNN model and can only obtain predicted labels through querying the target model.To achieve this goal, we formulate our attack as an optimization problem, whose objective is to minimize the number of edges to be perturbed in a graph while maintaining the high attack success rate. The original optimization problem is intractable to solve, and we relax the optimization problem to be a tractable one, which is solved with theoretical convergence guarantee. We also design a coarse-grained searching algorithm and a query-efficient gradient computation algorithm to decrease the number of queries to the target GNN model. Our experimental results on three real-world datasets demonstrate that our attack can effectively attack representative GNNs for graph classification with less queries and perturbations. We also evaluate the effectiveness of our attack under two defenses: one is well-designed adversarial graph detector and the other is that the target GNN model itself is equipped with a defense to prevent adversarial graph generation. Our experimental results show that such defenses are not effective enough, which highlights more advanced defenses.
Privacy-Preserving Representation Learning on Graphs: A Mutual Information Perspective
Jul 03, 2021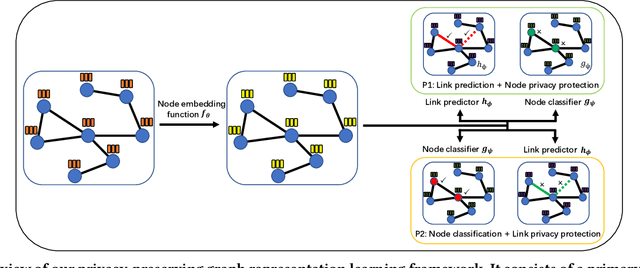
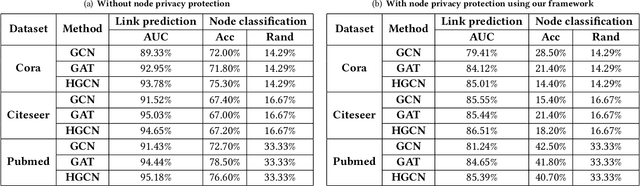
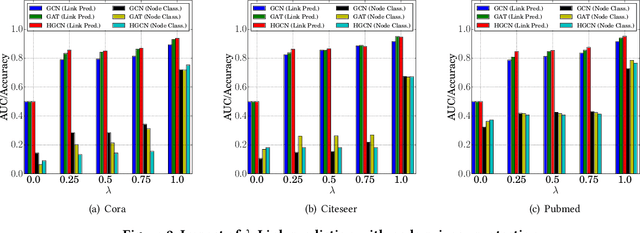
Learning with graphs has attracted significant attention recently. Existing representation learning methods on graphs have achieved state-of-the-art performance on various graph-related tasks such as node classification, link prediction, etc. However, we observe that these methods could leak serious private information. For instance, one can accurately infer the links (or node identity) in a graph from a node classifier (or link predictor) trained on the learnt node representations by existing methods. To address the issue, we propose a privacy-preserving representation learning framework on graphs from the \emph{mutual information} perspective. Specifically, our framework includes a primary learning task and a privacy protection task, and we consider node classification and link prediction as the two tasks of interest. Our goal is to learn node representations such that they can be used to achieve high performance for the primary learning task, while obtaining performance for the privacy protection task close to random guessing. We formally formulate our goal via mutual information objectives. However, it is intractable to compute mutual information in practice. Then, we derive tractable variational bounds for the mutual information terms, where each bound can be parameterized via a neural network. Next, we train these parameterized neural networks to approximate the true mutual information and learn privacy-preserving node representations. We finally evaluate our framework on various graph datasets.
Towards Adversarial Patch Analysis and Certified Defense against Crowd Counting
Apr 22, 2021
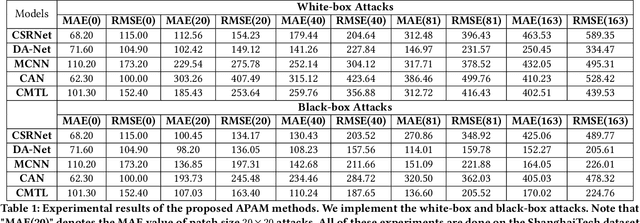

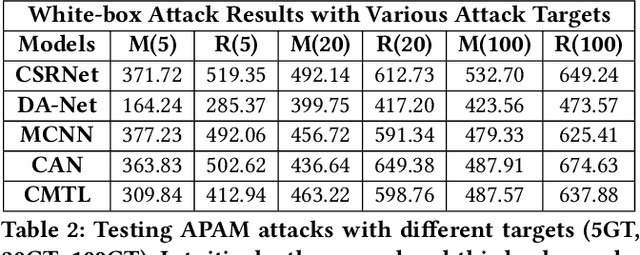
Crowd counting has drawn much attention due to its importance in safety-critical surveillance systems. Especially, deep neural network (DNN) methods have significantly reduced estimation errors for crowd counting missions. Recent studies have demonstrated that DNNs are vulnerable to adversarial attacks, i.e., normal images with human-imperceptible perturbations could mislead DNNs to make false predictions. In this work, we propose a robust attack strategy called Adversarial Patch Attack with Momentum (APAM) to systematically evaluate the robustness of crowd counting models, where the attacker's goal is to create an adversarial perturbation that severely degrades their performances, thus leading to public safety accidents (e.g., stampede accidents). Especially, the proposed attack leverages the extreme-density background information of input images to generate robust adversarial patches via a series of transformations (e.g., interpolation, rotation, etc.). We observe that by perturbing less than 6\% of image pixels, our attacks severely degrade the performance of crowd counting systems, both digitally and physically. To better enhance the adversarial robustness of crowd counting models, we propose the first regression model-based Randomized Ablation (RA), which is more sufficient than Adversarial Training (ADT) (Mean Absolute Error of RA is 5 lower than ADT on clean samples and 30 lower than ADT on adversarial examples). Extensive experiments on five crowd counting models demonstrate the effectiveness and generality of the proposed method. Code is available at \url{https://github.com/harrywuhust2022/Adv-Crowd-analysis}.
Semi-Supervised Node Classification on Graphs: Markov Random Fields vs. Graph Neural Networks
Dec 25, 2020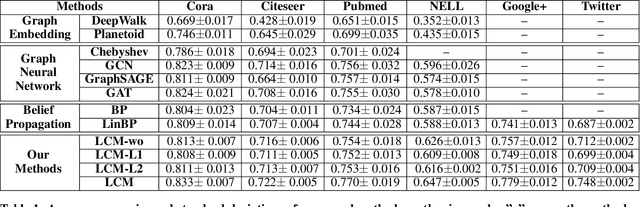
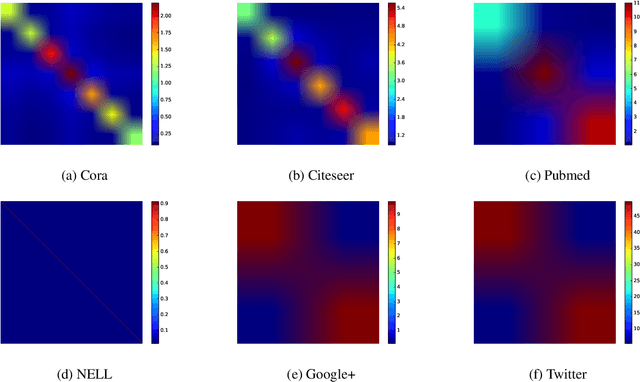

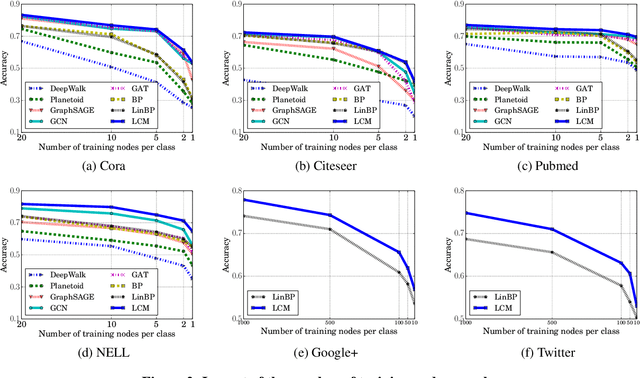
Semi-supervised node classification on graph-structured data has many applications such as fraud detection, fake account and review detection, user's private attribute inference in social networks, and community detection. Various methods such as pairwise Markov Random Fields (pMRF) and graph neural networks were developed for semi-supervised node classification. pMRF is more efficient than graph neural networks. However, existing pMRF-based methods are less accurate than graph neural networks, due to a key limitation that they assume a heuristics-based constant edge potential for all edges. In this work, we aim to address the key limitation of existing pMRF-based methods. In particular, we propose to learn edge potentials for pMRF. Our evaluation results on various types of graph datasets show that our optimized pMRF-based method consistently outperforms existing graph neural networks in terms of both accuracy and efficiency. Our results highlight that previous work may have underestimated the power of pMRF for semi-supervised node classification.
Provable Defense against Privacy Leakage in Federated Learning from Representation Perspective
Dec 08, 2020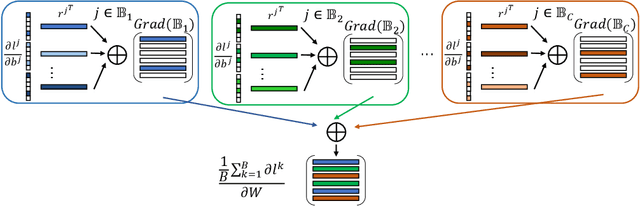
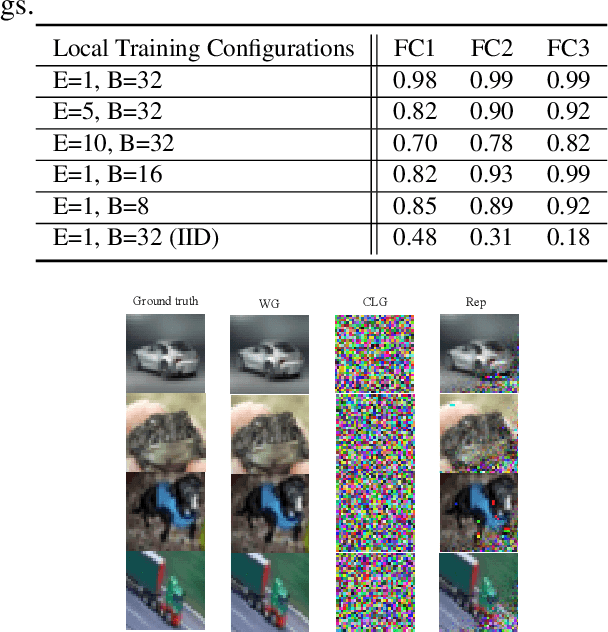
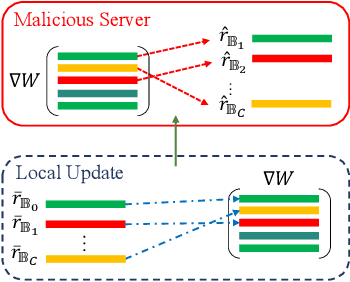
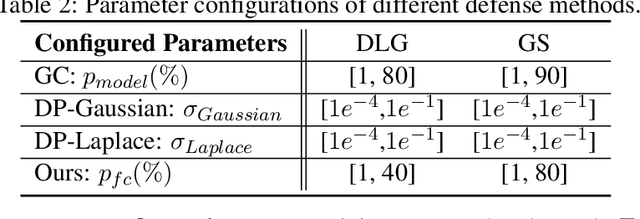
Federated learning (FL) is a popular distributed learning framework that can reduce privacy risks by not explicitly sharing private data. However, recent works demonstrated that sharing model updates makes FL vulnerable to inference attacks. In this work, we show our key observation that the data representation leakage from gradients is the essential cause of privacy leakage in FL. We also provide an analysis of this observation to explain how the data presentation is leaked. Based on this observation, we propose a defense against model inversion attack in FL. The key idea of our defense is learning to perturb data representation such that the quality of the reconstructed data is severely degraded, while FL performance is maintained. In addition, we derive certified robustness guarantee to FL and convergence guarantee to FedAvg, after applying our defense. To evaluate our defense, we conduct experiments on MNIST and CIFAR10 for defending against the DLG attack and GS attack. Without sacrificing accuracy, the results demonstrate that our proposed defense can increase the mean squared error between the reconstructed data and the raw data by as much as more than 160X for both DLG attack and GS attack, compared with baseline defense methods. The privacy of the FL system is significantly improved.