 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDefeating Catastrophic Forgetting via Enhanced Orthogonal Weights Modification
Nov 19, 2021
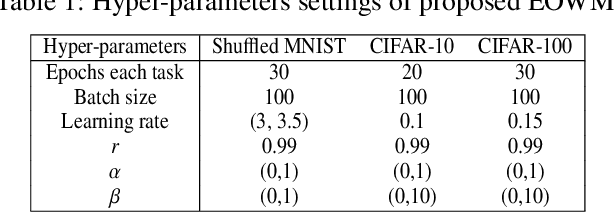
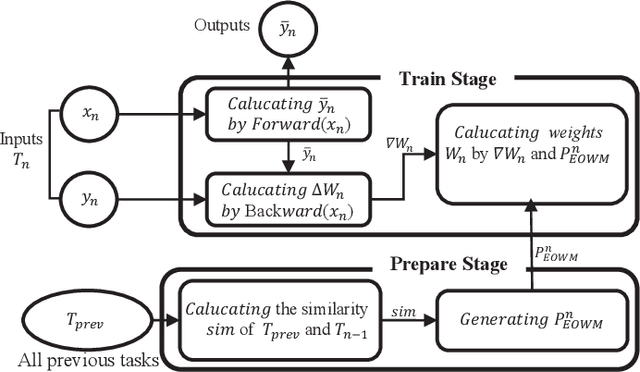
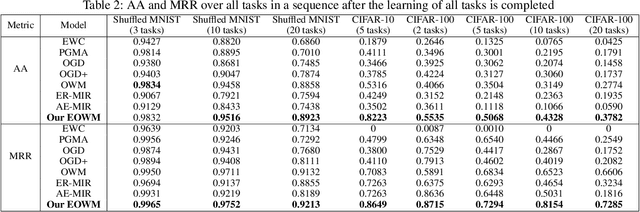
The ability of neural networks (NNs) to learn and remember multiple tasks sequentially is facing tough challenges in achieving general artificial intelligence due to their catastrophic forgetting (CF) issues. Fortunately, the latest OWM Orthogonal Weights Modification) and other several continual learning (CL) methods suggest some promising ways to overcome the CF issue. However, none of existing CL methods explores the following three crucial questions for effectively overcoming the CF issue: that is, what knowledge does it contribute to the effective weights modification of the NN during its sequential tasks learning? When the data distribution of a new learning task changes corresponding to the previous learned tasks, should a uniform/specific weight modification strategy be adopted or not? what is the upper bound of the learningable tasks sequentially for a given CL method? ect. To achieve this, in this paper, we first reveals the fact that of the weight gradient of a new learning task is determined by both the input space of the new task and the weight space of the previous learned tasks sequentially. On this observation and the recursive least square optimal method, we propose a new efficient and effective continual learning method EOWM via enhanced OWM. And we have theoretically and definitively given the upper bound of the learningable tasks sequentially of our EOWM. Extensive experiments conducted on the benchmarks demonstrate that our EOWM is effectiveness and outperform all of the state-of-the-art CL baselines.
Self-Initiated Open World Learning for Autonomous AI Agents
Oct 21, 2021As more and more AI agents are used in practice, it is time to think about how to make these agents fully autonomous so that they can learn by themselves in a self-motivated and self-supervised manner rather than being retrained periodically on the initiation of human engineers using expanded training data. As the real-world is an open environment with unknowns or novelties, detecting novelties or unknowns, gathering ground-truth training data, and incrementally learning the unknowns make the agent more and more knowledgeable and powerful over time. The key challenge is how to automate the process so that it is carried out on the agent's own initiative and through its own interactions with humans and the environment. Since an AI agent usually has a performance task, characterizing each novelty becomes necessary so that the agent can formulate an appropriate response to adapt its behavior to cope with the novelty and to learn from it to improve its future responses and task performance. This paper proposes a theoretic framework for this learning paradigm to promote the research of building self-initiated open world learning agents.
ActiveEA: Active Learning for Neural Entity Alignment
Oct 13, 2021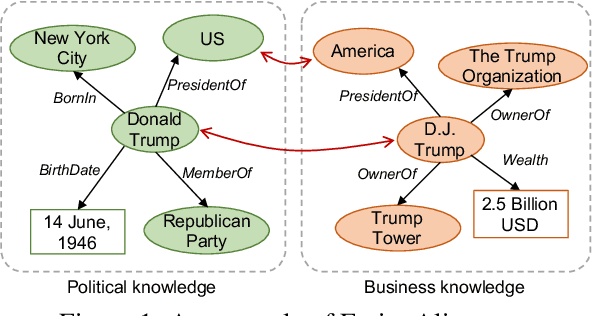
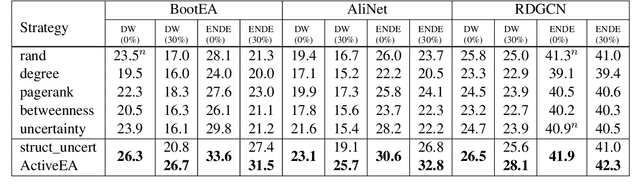
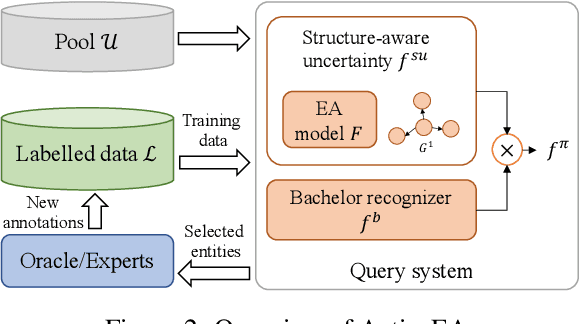
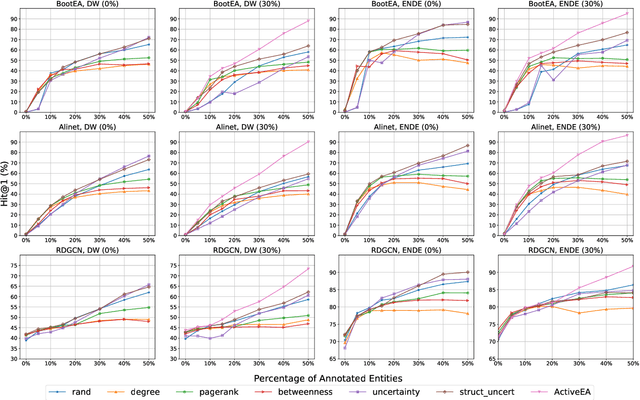
Entity Alignment (EA) aims to match equivalent entities across different Knowledge Graphs (KGs) and is an essential step of KG fusion. Current mainstream methods -- neural EA models -- rely on training with seed alignment, i.e., a set of pre-aligned entity pairs which are very costly to annotate. In this paper, we devise a novel Active Learning (AL) framework for neural EA, aiming to create highly informative seed alignment to obtain more effective EA models with less annotation cost. Our framework tackles two main challenges encountered when applying AL to EA: (1) How to exploit dependencies between entities within the AL strategy. Most AL strategies assume that the data instances to sample are independent and identically distributed. However, entities in KGs are related. To address this challenge, we propose a structure-aware uncertainty sampling strategy that can measure the uncertainty of each entity as well as its impact on its neighbour entities in the KG. (2) How to recognise entities that appear in one KG but not in the other KG (i.e., bachelors). Identifying bachelors would likely save annotation budget. To address this challenge, we devise a bachelor recognizer paying attention to alleviate the effect of sampling bias. Empirical results show that our proposed AL strategy can significantly improve sampling quality with good generality across different datasets, EA models and amount of bachelors.
Zero-Shot Open Set Detection by Extending CLIP
Sep 10, 2021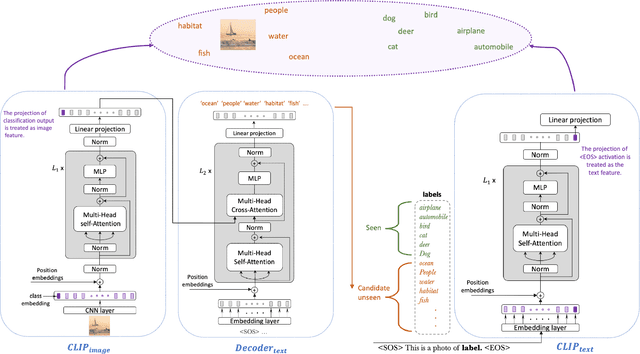
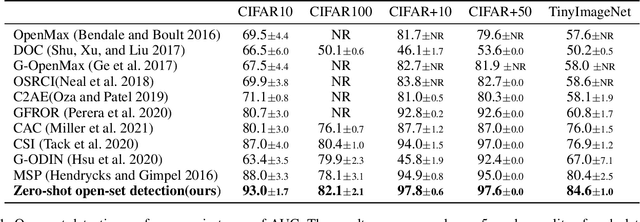
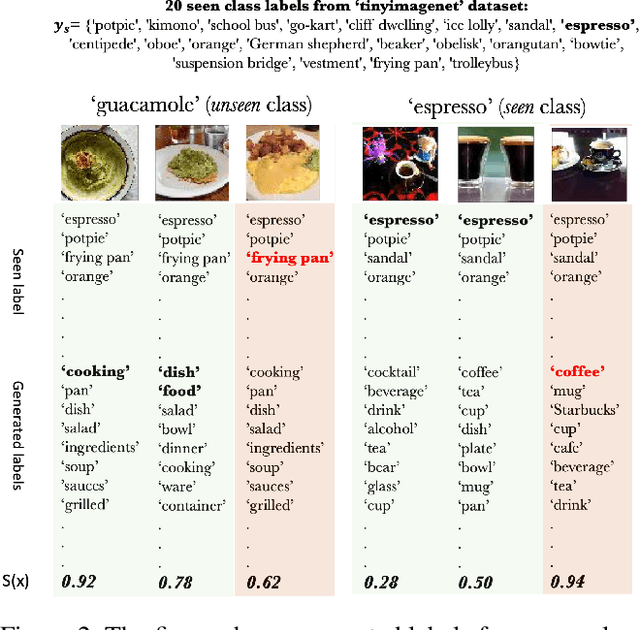
In a regular open set detection problem, samples of known classes (also called closed set classes) are used to train a special classifier. In testing, the classifier can (1) classify the test samples of known classes to their respective classes and (2) also detect samples that do not belong to any of the known classes (we say they belong to some unknown or open set classes). This paper studies the problem of zero-shot open-set detection, which still performs the same two tasks in testing but has no training except using the given known class names. This paper proposes a novel and yet simple method (called ZO-CLIP) to solve the problem. ZO-CLIP builds on top of the recent advances in zero-shot classification through multi-modal representation learning. It first extends the pre-trained multi-modal model CLIP by training a text-based image description generator on top of CLIP. In testing, it uses the extended model to generate some candidate unknown class names for each test sample and computes a confidence score based on both the known class names and candidate unknown class names for zero-shot open set detection. Experimental results on 5 benchmark datasets for open set detection confirm that ZO-CLIP outperforms the baselines by a large margin.
Zero-Shot Dialogue State Tracking via Cross-Task Transfer
Sep 10, 2021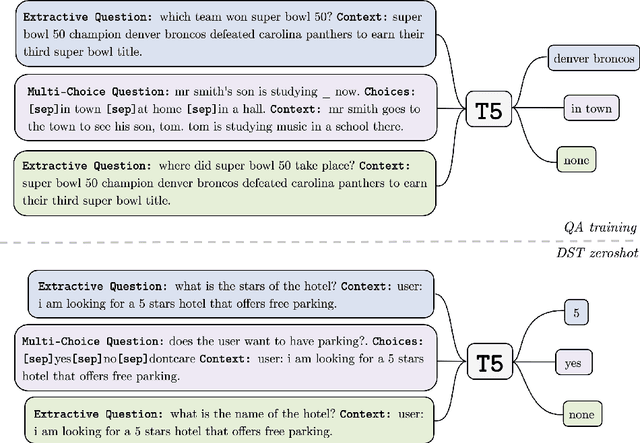
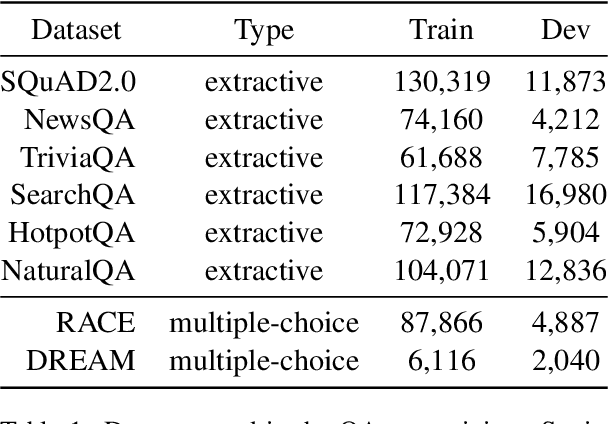
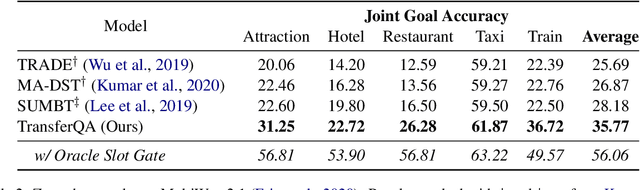
Zero-shot transfer learning for dialogue state tracking (DST) enables us to handle a variety of task-oriented dialogue domains without the expense of collecting in-domain data. In this work, we propose to transfer the \textit{cross-task} knowledge from general question answering (QA) corpora for the zero-shot DST task. Specifically, we propose TransferQA, a transferable generative QA model that seamlessly combines extractive QA and multi-choice QA via a text-to-text transformer framework, and tracks both categorical slots and non-categorical slots in DST. In addition, we introduce two effective ways to construct unanswerable questions, namely, negative question sampling and context truncation, which enable our model to handle "none" value slots in the zero-shot DST setting. The extensive experiments show that our approaches substantially improve the existing zero-shot and few-shot results on MultiWoz. Moreover, compared to the fully trained baseline on the Schema-Guided Dialogue dataset, our approach shows better generalization ability in unseen domains.
Leveraging Slot Descriptions for Zero-Shot Cross-Domain Dialogue State Tracking
May 10, 2021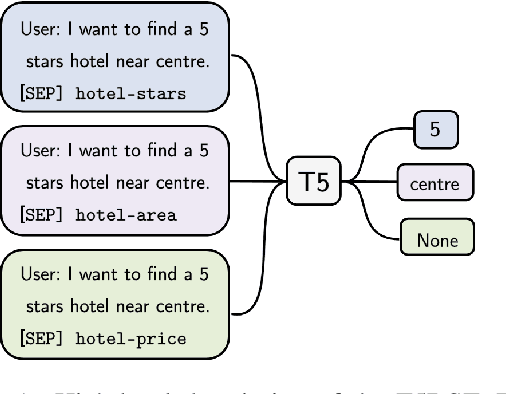
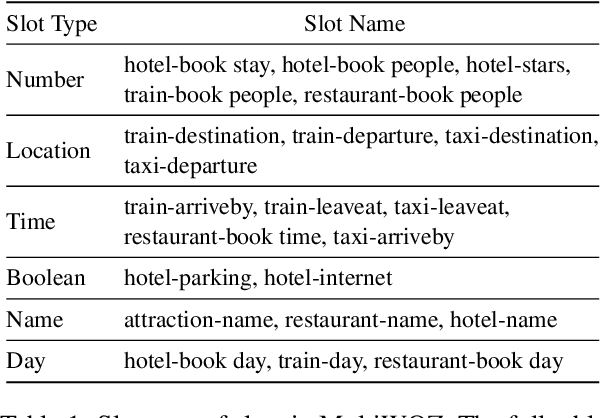

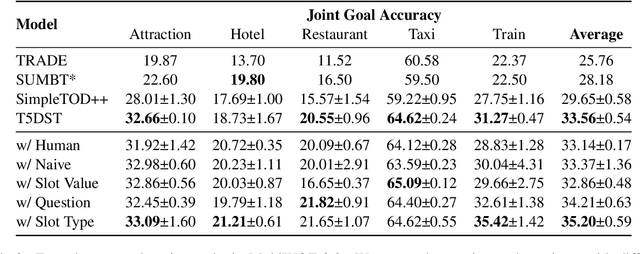
Zero-shot cross-domain dialogue state tracking (DST) enables us to handle task-oriented dialogue in unseen domains without the expense of collecting in-domain data. In this paper, we propose a slot description enhanced generative approach for zero-shot cross-domain DST. Specifically, our model first encodes dialogue context and slots with a pre-trained self-attentive encoder, and generates slot values in an auto-regressive manner. In addition, we incorporate Slot Type Informed Descriptions that capture the shared information across slots to facilitate cross-domain knowledge transfer. Experimental results on the MultiWOZ dataset show that our proposed method significantly improves existing state-of-the-art results in the zero-shot cross-domain setting.
Continual Learning in Task-Oriented Dialogue Systems
Dec 31, 2020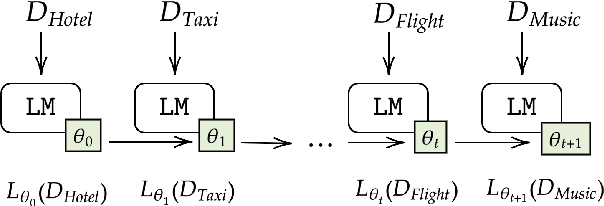
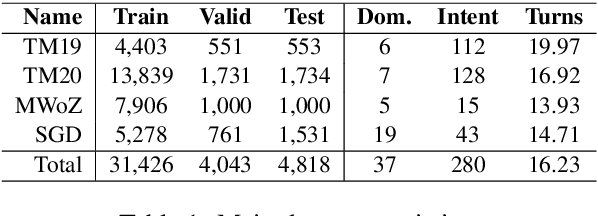

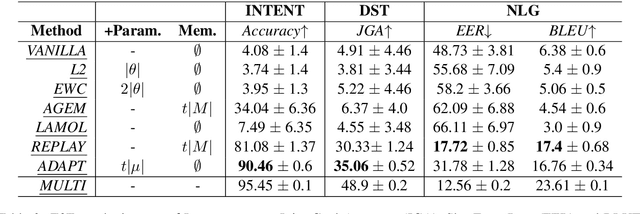
Continual learning in task-oriented dialogue systems can allow us to add new domains and functionalities through time without incurring the high cost of a whole system retraining. In this paper, we propose a continual learning benchmark for task-oriented dialogue systems with 37 domains to be learned continuously in four settings, such as intent recognition, state tracking, natural language generation, and end-to-end. Moreover, we implement and compare multiple existing continual learning baselines, and we propose a simple yet effective architectural method based on residual adapters. Our experiments demonstrate that the proposed architectural method and a simple replay-based strategy perform comparably well but they both achieve inferior performance to the multi-task learning baseline, in where all the data are shown at once, showing that continual learning in task-oriented dialogue systems is a challenging task. Furthermore, we reveal several trade-offs between different continual learning methods in term of parameter usage and memory size, which are important in the design of a task-oriented dialogue system. The proposed benchmark is released together with several baselines to promote more research in this direction.
A Deep Reinforcement Learning Approach for Ramp Metering Based on Traffic Video Data
Dec 09, 2020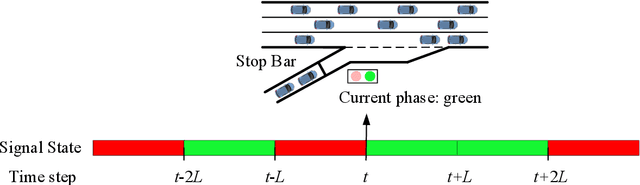

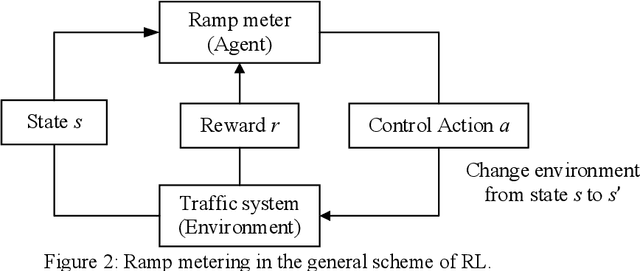
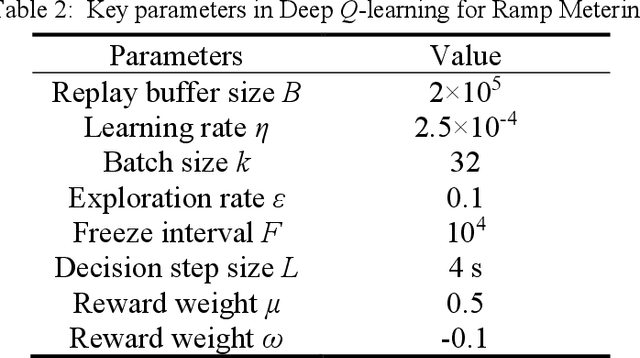
Ramp metering that uses traffic signals to regulate vehicle flows from the on-ramps has been widely implemented to improve vehicle mobility of the freeway. Previous studies generally update signal timings in real-time based on predefined traffic measures collected by point detectors, such as traffic volumes and occupancies. Comparing with point detectors, traffic cameras-which have been increasingly deployed on road networks-could cover larger areas and provide more detailed traffic information. In this work, we propose a deep reinforcement learning (DRL) method to explore the potential of traffic video data in improving the efficiency of ramp metering. The proposed method uses traffic video frames as inputs and learns the optimal control strategies directly from the high-dimensional visual inputs. A real-world case study demonstrates that, in comparison with a state-of-the-practice method, the proposed DRL method results in 1) lower travel times in the mainline, 2) shorter vehicle queues at the on-ramp, and 3) higher traffic flows downstream of the merging area. The results suggest that the proposed method is able to extract useful information from the video data for better ramp metering controls.
Attention Aware Cost Volume Pyramid Based Multi-view Stereo Network for 3D Reconstruction
Nov 25, 2020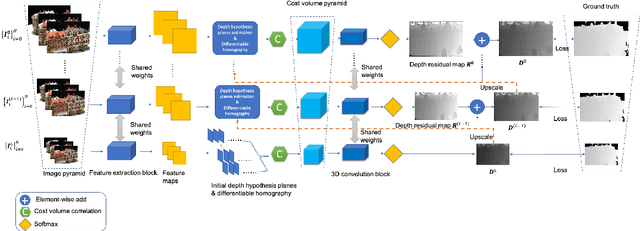
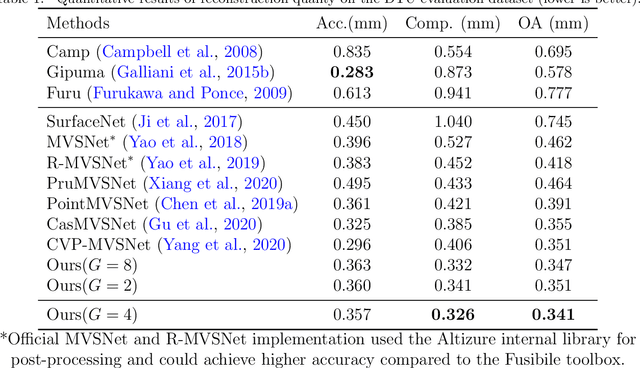
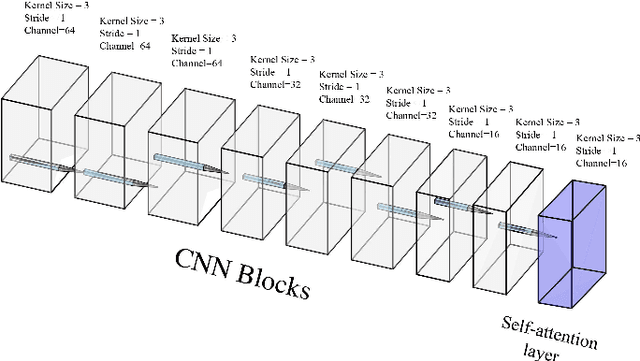

We present an efficient multi-view stereo (MVS) network for 3D reconstruction from multiview images. While previous learning based reconstruction approaches performed quite well, most of them estimate depth maps at a fixed resolution using plane sweep volumes with a fixed depth hypothesis at each plane, which requires densely sampled planes for desired accuracy and therefore is difficult to achieve high resolution depth maps. In this paper we introduce a coarseto-fine depth inference strategy to achieve high resolution depth. This strategy estimates the depth map at coarsest level, while the depth maps at finer levels are considered as the upsampled depth map from previous level with pixel-wise depth residual. Thus, we narrow the depth searching range with priori information from previous level and construct new cost volumes from the pixel-wise depth residual to perform depth map refinement. Then the final depth map could be achieved iteratively since all the parameters are shared between different levels. At each level, the self-attention layer is introduced to the feature extraction block for capturing the long range dependencies for depth inference task, and the cost volume is generated using similarity measurement instead of the variance based methods used in previous work. Experiments were conducted on both the DTU benchmark dataset and recently released BlendedMVS dataset. The results demonstrated that our model could outperform most state-of-the-arts (SOTA) methods. The codebase of this project is at https://github.com/ArthasMil/AACVP-MVSNet.
Lifelong Knowledge Learning in Rule-based Dialogue Systems
Nov 19, 2020One of the main weaknesses of current chatbots or dialogue systems is that they do not learn online during conversations after they are deployed. This is a major loss of opportunity. Clearly, each human user has a great deal of knowledge about the world that may be useful to others. If a chatbot can learn from their users during chatting, it will greatly expand its knowledge base and serve its users better. This paper proposes to build such a learning capability in a rule-based chatbot so that it can continuously acquire new knowledge in its chatting with users. This work is useful because many real-life deployed chatbots are rule-based.