 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLeveraging Semantic Type Dependencies for Clinical Named Entity Recognition
Mar 07, 2025



Previous work on clinical relation extraction from free-text sentences leveraged information about semantic types from clinical knowledge bases as a part of entity representations. In this paper, we exploit additional evidence by also making use of domain-specific semantic type dependencies. We encode the relation between a span of tokens matching a Unified Medical Language System (UMLS) concept and other tokens in the sentence. We implement our method and compare against different named entity recognition (NER) architectures (i.e., BiLSTM-CRF and BiLSTM-GCN-CRF) using different pre-trained clinical embeddings (i.e., BERT, BioBERT, UMLSBert). Our experimental results on clinical datasets show that in some cases NER effectiveness can be significantly improved by making use of domain-specific semantic type dependencies. Our work is also the first study generating a matrix encoding to make use of more than three dependencies in one pass for the NER task.
Guiding Neural Entity Alignment with Compatibility
Nov 29, 2022



Entity Alignment (EA) aims to find equivalent entities between two Knowledge Graphs (KGs). While numerous neural EA models have been devised, they are mainly learned using labelled data only. In this work, we argue that different entities within one KG should have compatible counterparts in the other KG due to the potential dependencies among the entities. Making compatible predictions thus should be one of the goals of training an EA model along with fitting the labelled data: this aspect however is neglected in current methods. To power neural EA models with compatibility, we devise a training framework by addressing three problems: (1) how to measure the compatibility of an EA model; (2) how to inject the property of being compatible into an EA model; (3) how to optimise parameters of the compatibility model. Extensive experiments on widely-used datasets demonstrate the advantages of integrating compatibility within EA models. In fact, state-of-the-art neural EA models trained within our framework using just 5\% of the labelled data can achieve comparable effectiveness with supervised training using 20\% of the labelled data.
High-quality Task Division for Large-scale Entity Alignment
Aug 22, 2022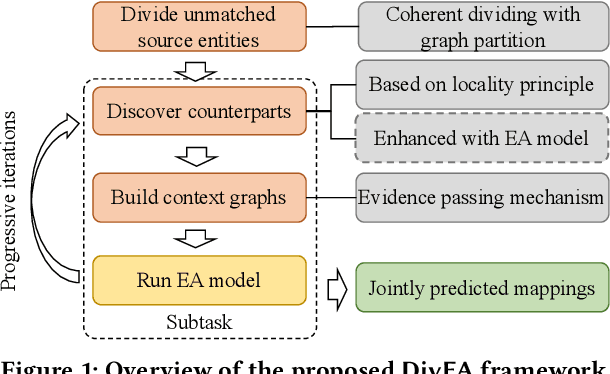


Entity Alignment (EA) aims to match equivalent entities that refer to the same real-world objects and is a key step for Knowledge Graph (KG) fusion. Most neural EA models cannot be applied to large-scale real-life KGs due to their excessive consumption of GPU memory and time. One promising solution is to divide a large EA task into several subtasks such that each subtask only needs to match two small subgraphs of the original KGs. However, it is challenging to divide the EA task without losing effectiveness. Existing methods display low coverage of potential mappings, insufficient evidence in context graphs, and largely differing subtask sizes. In this work, we design the DivEA framework for large-scale EA with high-quality task division. To include in the EA subtasks a high proportion of the potential mappings originally present in the large EA task, we devise a counterpart discovery method that exploits the locality principle of the EA task and the power of trained EA models. Unique to our counterpart discovery method is the explicit modelling of the chance of a potential mapping. We also introduce an evidence passing mechanism to quantify the informativeness of context entities and find the most informative context graphs with flexible control of the subtask size. Extensive experiments show that DivEA achieves higher EA performance than alternative state-of-the-art solutions.
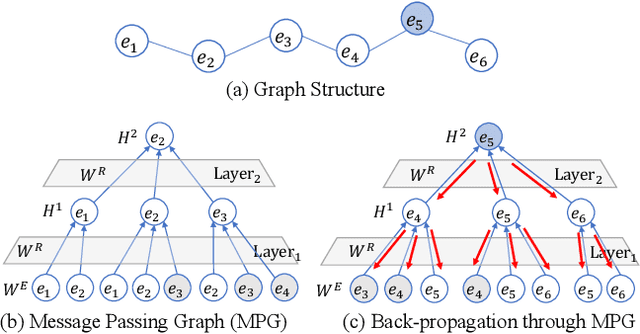
ActiveEA: Active Learning for Neural Entity Alignment
Oct 13, 2021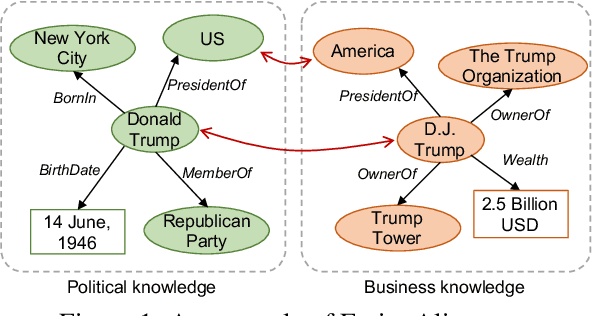
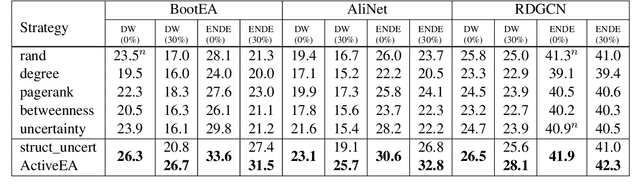
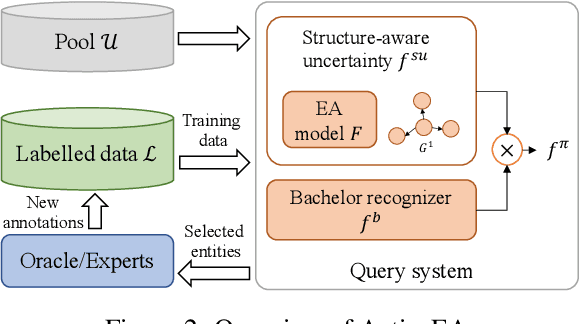
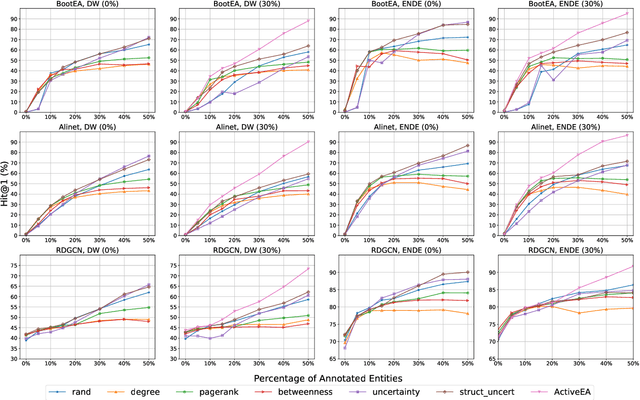
Entity Alignment (EA) aims to match equivalent entities across different Knowledge Graphs (KGs) and is an essential step of KG fusion. Current mainstream methods -- neural EA models -- rely on training with seed alignment, i.e., a set of pre-aligned entity pairs which are very costly to annotate. In this paper, we devise a novel Active Learning (AL) framework for neural EA, aiming to create highly informative seed alignment to obtain more effective EA models with less annotation cost. Our framework tackles two main challenges encountered when applying AL to EA: (1) How to exploit dependencies between entities within the AL strategy. Most AL strategies assume that the data instances to sample are independent and identically distributed. However, entities in KGs are related. To address this challenge, we propose a structure-aware uncertainty sampling strategy that can measure the uncertainty of each entity as well as its impact on its neighbour entities in the KG. (2) How to recognise entities that appear in one KG but not in the other KG (i.e., bachelors). Identifying bachelors would likely save annotation budget. To address this challenge, we devise a bachelor recognizer paying attention to alleviate the effect of sampling bias. Empirical results show that our proposed AL strategy can significantly improve sampling quality with good generality across different datasets, EA models and amount of bachelors.