 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeATOM: Instantiating Budget-Controllable Multi-Agent Collaboration via Nucleus-Electron Hierarchy
May 25, 2026Large Language Model (LLM)-based multi-agent systems rely on optimized collaboration topologies to balance performance and communication costs. However, current methods struggle with the inherent stability-extensibility trade-off and often misalign computational budgets with query difficulty. We propose \textsc{ATOM}, an adaptive framework that generates budget-controllable collaboration graphs via a novel task-driven reinforcement learning paradigm. Inspired by atomic structures, \textsc{ATOM} employs a nucleus-electron hierarchy: it maintains a stable, offline-learned collaboration backbone (the nucleus) while dynamically activating query-conditioned agents (electrons) during inference. Crucially, a complexity-aware budgeting strategy aligns resource consumption with task demands by estimating query difficulty to strictly regulate electron instantiation. Extensive experiments across six diverse benchmarks demonstrate that \textsc{ATOM} achieves state-of-the-art performance while improving token efficiency by up to $30\%$ compared to strong baselines.
Video-QTR: Query-Driven Temporal Reasoning Framework for Lightweight Video Understanding
Dec 10, 2025The rapid development of multimodal large-language models (MLLMs) has significantly expanded the scope of visual language reasoning, enabling unified systems to interpret and describe complex visual content. However, applying these models to long-video understanding remains computationally intensive. Dense frame encoding generates excessive visual tokens, leading to high memory consumption, redundant computation, and limited scalability in real-world applications. This inefficiency highlights a key limitation of the traditional process-then-reason paradigm, which analyzes visual streams exhaustively before semantic reasoning. To address this challenge, we introduce Video-QTR (Query-Driven Temporal Reasoning), a lightweight framework that redefines video comprehension as a query-guided reasoning process. Instead of encoding every frame, Video-QTR dynamically allocates perceptual resources based on the semantic intent of the query, creating an adaptive feedback loop between reasoning and perception. Extensive experiments across five benchmarks: MSVD-QA, Activity Net-QA, Movie Chat, and Video MME demonstrate that Video-QTR achieves state-of-the-art performance while reducing input frame consumption by up to 73%. These results confirm that query-driven temporal reasoning provides an efficient and scalable solution for video understanding.
LightRouter: Towards Efficient LLM Collaboration with Minimal Overhead
May 22, 2025



The rapid advancement of large language models has unlocked remarkable capabilities across a diverse array of natural language processing tasks. However, the considerable differences among available LLMs-in terms of cost, performance, and computational demands-pose significant challenges for users aiming to identify the most suitable model for specific tasks. In this work, we present LightRouter, a novel framework designed to systematically select and integrate a small subset of LLMs from a larger pool, with the objective of jointly optimizing both task performance and cost efficiency. LightRouter leverages an adaptive selection mechanism to identify models that require only a minimal number of boot tokens, thereby reducing costs, and further employs an effective integration strategy to combine their outputs. Extensive experiments across multiple benchmarks demonstrate that LightRouter matches or outperforms widely-used ensemble baselines, achieving up to a 25% improvement in accuracy. Compared with leading high-performing models, LightRouter achieves comparable performance while reducing inference costs by up to 27%. Importantly, our framework operates without any prior knowledge of individual models and relies exclusively on inexpensive, lightweight models. This work introduces a practical approach for efficient LLM selection and provides valuable insights into optimal strategies for model combination.
Defeating Catastrophic Forgetting via Enhanced Orthogonal Weights Modification
Nov 19, 2021
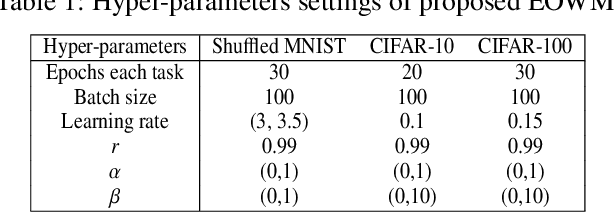
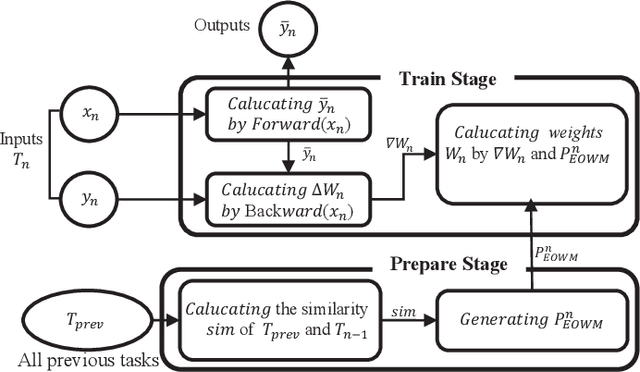
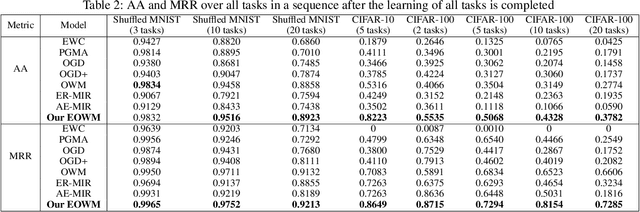
The ability of neural networks (NNs) to learn and remember multiple tasks sequentially is facing tough challenges in achieving general artificial intelligence due to their catastrophic forgetting (CF) issues. Fortunately, the latest OWM Orthogonal Weights Modification) and other several continual learning (CL) methods suggest some promising ways to overcome the CF issue. However, none of existing CL methods explores the following three crucial questions for effectively overcoming the CF issue: that is, what knowledge does it contribute to the effective weights modification of the NN during its sequential tasks learning? When the data distribution of a new learning task changes corresponding to the previous learned tasks, should a uniform/specific weight modification strategy be adopted or not? what is the upper bound of the learningable tasks sequentially for a given CL method? ect. To achieve this, in this paper, we first reveals the fact that of the weight gradient of a new learning task is determined by both the input space of the new task and the weight space of the previous learned tasks sequentially. On this observation and the recursive least square optimal method, we propose a new efficient and effective continual learning method EOWM via enhanced OWM. And we have theoretically and definitively given the upper bound of the learningable tasks sequentially of our EOWM. Extensive experiments conducted on the benchmarks demonstrate that our EOWM is effectiveness and outperform all of the state-of-the-art CL baselines.