 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUnderstanding Pre-trained BERT for Aspect-based Sentiment Analysis
Oct 31, 2020


This paper analyzes the pre-trained hidden representations learned from reviews on BERT for tasks in aspect-based sentiment analysis (ABSA). Our work is motivated by the recent progress in BERT-based language models for ABSA. However, it is not clear how the general proxy task of (masked) language model trained on unlabeled corpus without annotations of aspects or opinions can provide important features for downstream tasks in ABSA. By leveraging the annotated datasets in ABSA, we investigate both the attentions and the learned representations of BERT pre-trained on reviews. We found that BERT uses very few self-attention heads to encode context words (such as prepositions or pronouns that indicating an aspect) and opinion words for an aspect. Most features in the representation of an aspect are dedicated to the fine-grained semantics of the domain (or product category) and the aspect itself, instead of carrying summarized opinions from its context. We hope this investigation can help future research in improving self-supervised learning, unsupervised learning and fine-tuning for ABSA. The pre-trained model and code can be found at https://github.com/howardhsu/BERT-for-RRC-ABSA.
NUANCED: Natural Utterance Annotation for Nuanced Conversation with Estimated Distributions
Oct 24, 2020

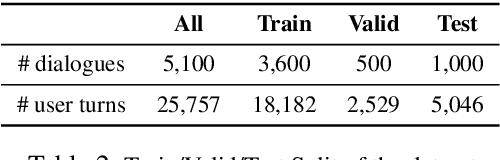
Existing conversational systems are mostly agent-centric, which assumes the user utterances would closely follow the system ontology (for NLU or dialogue state tracking). However, in real-world scenarios, it is highly desirable that the users can speak freely in their own way. It is extremely hard, if not impossible, for the users to adapt to the unknown system ontology. In this work, we attempt to build a user-centric dialogue system. As there is no clean mapping for a user's free form utterance to an ontology, we first model the user preferences as estimated distributions over the system ontology and map the users' utterances to such distributions. Learning such a mapping poses new challenges on reasoning over existing knowledge, ranging from factoid knowledge, commonsense knowledge to the users' own situations. To this end, we build a new dataset named NUANCED that focuses on such realistic settings for conversational recommendation. Collected via dialogue simulation and paraphrasing, NUANCED contains 5.1k dialogues, 26k turns of high-quality user responses. We conduct experiments, showing both the usefulness and challenges of our problem setting. We believe NUANCED can serve as a valuable resource to push existing research from the agent-centric system to the user-centric system. The code and data will be made publicly available.
Adding Chit-Chats to Enhance Task-Oriented Dialogues
Oct 24, 2020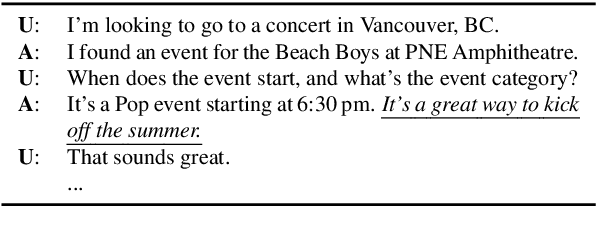
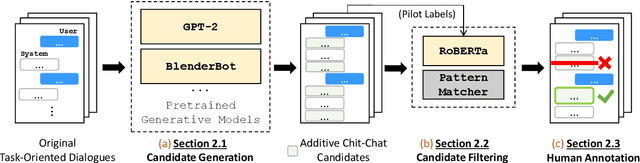
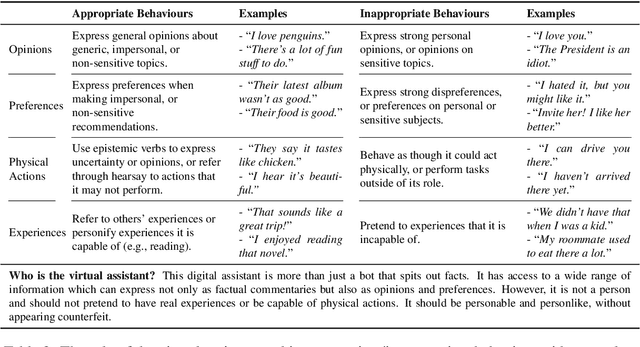
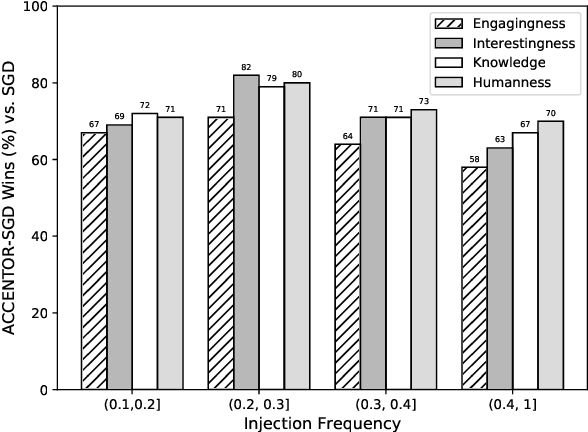
The existing dialogue corpora and models are typically designed under two disjoint motives: while task-oriented systems focus on achieving functional goals (e.g., booking hotels), open-domain chatbots aim at making socially engaging conversations. In this work, we propose to integrate both types of systems by Adding Chit-Chats to ENhance Task-ORiented dialogues (ACCENTOR), with the goal of making virtual assistant conversations more engaging and interactive. Specifically, we propose a flexible approach for generating diverse chit-chat responses to augment task-oriented dialogues with minimal annotation effort. We then present our new chit-chat annotations to 23.8K dialogues from the popular task-oriented datasets (Schema-Guided Dialogue and MultiWOZ 2.1) and demonstrate their advantage over the originals via human evaluation. Lastly, we propose three new models for ACCENTOR explicitly trained to predict user goals and to generate contextually relevant chit-chat responses. Automatic and human evaluations show that, compared with the state-of-the-art task-oriented baseline, our models can code-switch between task and chit-chat to be more engaging, interesting, knowledgeable, and humanlike, while maintaining competitive task performance.
A Knowledge-Driven Approach to Classifying Object and Attribute Coreferences in Opinion Mining
Oct 11, 2020
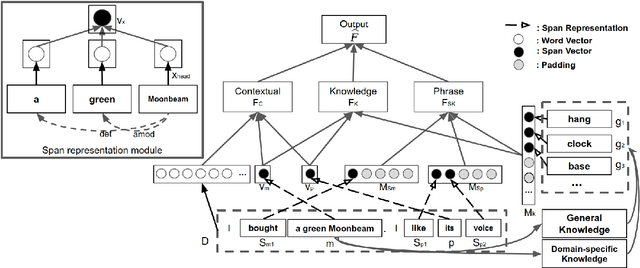

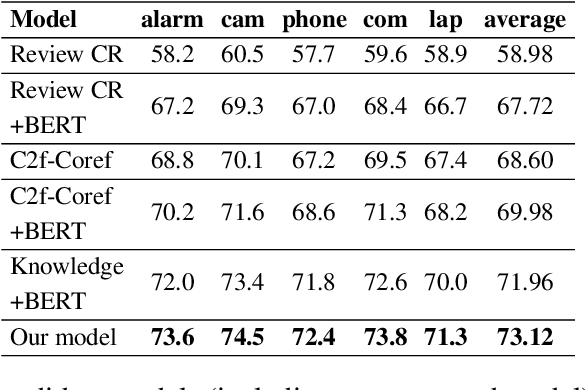
Classifying and resolving coreferences of objects (e.g., product names) and attributes (e.g., product aspects) in opinionated reviews is crucial for improving the opinion mining performance. However, the task is challenging as one often needs to consider domain-specific knowledge (e.g., iPad is a tablet and has aspect resolution) to identify coreferences in opinionated reviews. Also, compiling a handcrafted and curated domain-specific knowledge base for each domain is very time consuming and arduous. This paper proposes an approach to automatically mine and leverage domain-specific knowledge for classifying objects and attribute coreferences. The approach extracts domain-specific knowledge from unlabeled review data and trains a knowledgeaware neural coreference classification model to leverage (useful) domain knowledge together with general commonsense knowledge for the task. Experimental evaluation on realworld datasets involving five domains (product types) shows the effectiveness of the approach.
Controllable Text Generation with Focused Variation
Sep 25, 2020
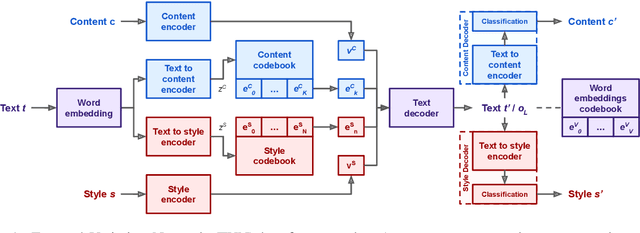
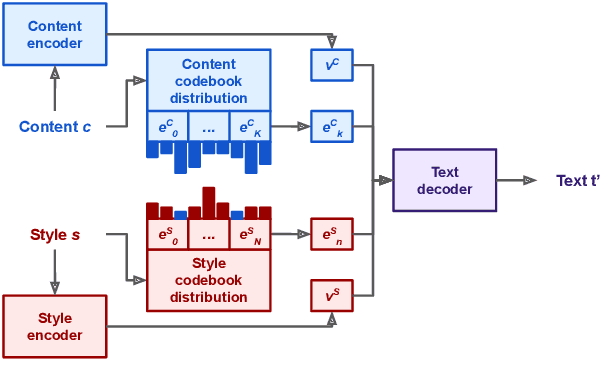
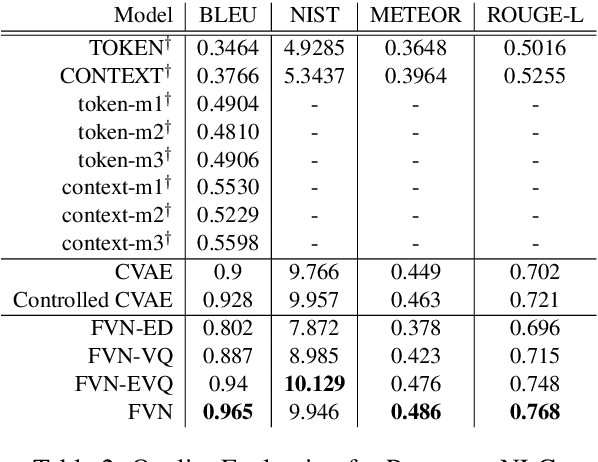
This work introduces Focused-Variation Network (FVN), a novel model to control language generation. The main problems in previous controlled language generation models range from the difficulty of generating text according to the given attributes, to the lack of diversity of the generated texts. FVN addresses these issues by learning disjoint discrete latent spaces for each attribute inside codebooks, which allows for both controllability and diversity, while at the same time generating fluent text. We evaluate FVN on two text generation datasets with annotated content and style, and show state-of-the-art performance as assessed by automatic and human evaluations.
Text Classification with Novelty Detection
Sep 23, 2020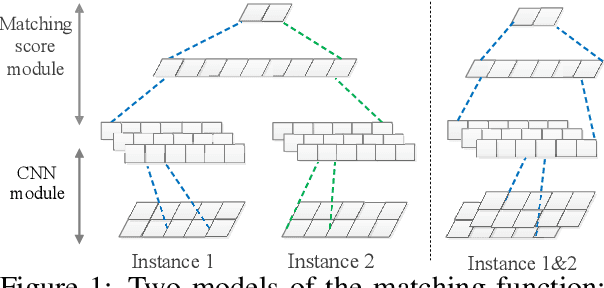
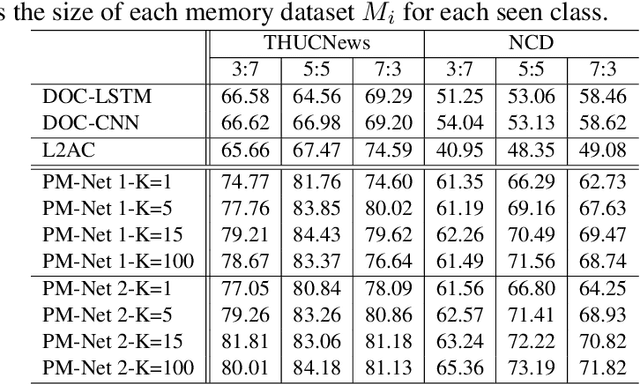
This paper studies the problem of detecting novel or unexpected instances in text classification. In traditional text classification, the classes appeared in testing must have been seen in training. However, in many applications, this is not the case because in testing, we may see unexpected instances that are not from any of the training classes. In this paper, we propose a significantly more effective approach that converts the original problem to a pair-wise matching problem and then outputs how probable two instances belong to the same class. Under this approach, we present two models. The more effective model uses two embedding matrices of a pair of instances as two channels of a CNN. The output probabilities from such pairs are used to judge whether a test instance is from a seen class or is novel/unexpected. Experimental results show that the proposed method substantially outperforms the state-of-the-art baselines.
Lifelong Learning Dialogue Systems: Chatbots that Self-Learn On the Job
Sep 22, 2020Dialogue systems, also called chatbots, are now used in a wide range of applications. However, they still have some major weaknesses. One key weakness is that they are typically trained from manually-labeled data and/or written with handcrafted rules, and their knowledge bases (KBs) are also compiled by human experts. Due to the huge amount of manual effort involved, they are difficult to scale and also tend to produce many errors ought to their limited ability to understand natural language and the limited knowledge in their KBs. Thus, the level of user satisfactory is often low. In this paper, we propose to dramatically improve this situation by endowing the system the ability to continually learn (1) new world knowledge, (2) new language expressions to ground them to actions, and (3) new conversational skills, during conversation or "on the job" by themselves so that as the systems chat more and more with users, they become more and more knowledgeable and are better and better able to understand diverse natural language expressions and improve their conversational skills. A key approach to achieving these is to exploit the multi-user environment of such systems to self-learn through interactions with users via verb and non-verb means. The paper discusses not only key challenges and promising directions to learn from users during conversation but also how to ensure the correctness of the learned knowledge.
Active Deep Densely Connected Convolutional Network for Hyperspectral Image Classification
Sep 01, 2020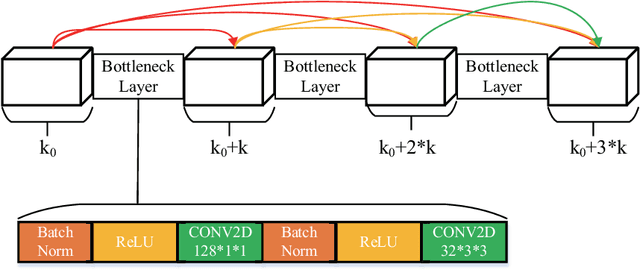

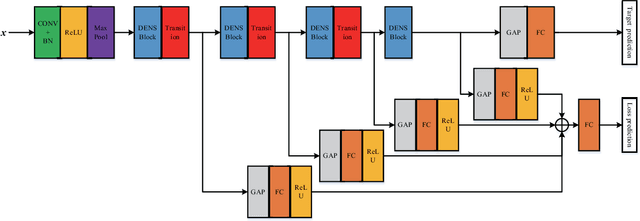
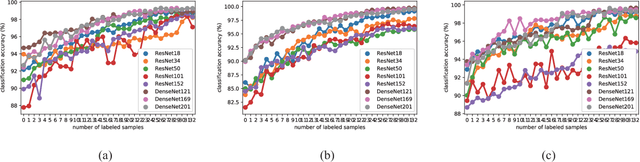
Deep learning based methods have seen a massive rise in popularity for hyperspectral image classification over the past few years. However, the success of deep learning is attributed greatly to numerous labeled samples. It is still very challenging to use only a few labeled samples to train deep learning models to reach a high classification accuracy. An active deep-learning framework trained by an end-to-end manner is, therefore, proposed by this paper in order to minimize the hyperspectral image classification costs. First, a deep densely connected convolutional network is considered for hyperspectral image classification. Different from the traditional active learning methods, an additional network is added to the designed deep densely connected convolutional network to predict the loss of input samples. Then, the additional network could be used to suggest unlabeled samples that the deep densely connected convolutional network is more likely to produce a wrong label. Note that the additional network uses the intermediate features of the deep densely connected convolutional network as input. Therefore, the proposed method is an end-to-end framework. Subsequently, a few of the selected samples are labelled manually and added to the training samples. The deep densely connected convolutional network is therefore trained using the new training set. Finally, the steps above are repeated to train the whole framework iteratively. Extensive experiments illustrates that the method proposed could reach a high accuracy in classification after selecting just a few samples.
User Memory Reasoning for Conversational Recommendation
May 30, 2020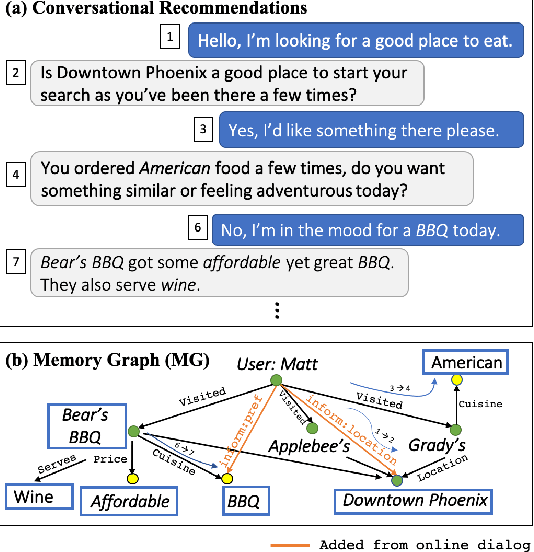
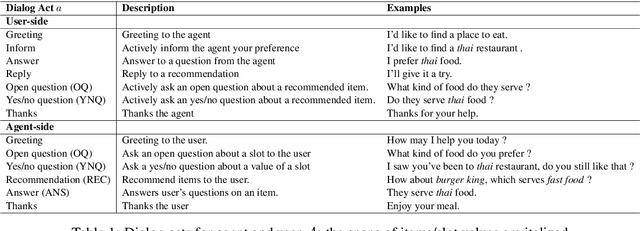

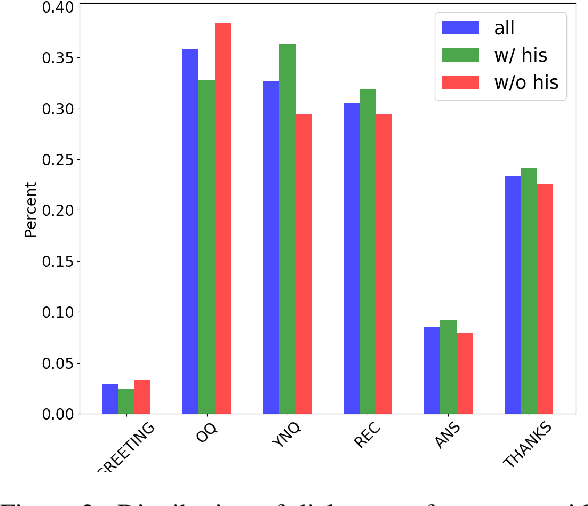
We study a conversational recommendation model which dynamically manages users' past (offline) preferences and current (online) requests through a structured and cumulative user memory knowledge graph, to allow for natural interactions and accurate recommendations. For this study, we create a new Memory Graph (MG) <--> Conversational Recommendation parallel corpus called MGConvRex with 7K+ human-to-human role-playing dialogs, grounded on a large-scale user memory bootstrapped from real-world user scenarios. MGConvRex captures human-level reasoning over user memory and has disjoint training/testing sets of users for zero-shot (cold-start) reasoning for recommendation. We propose a simple yet expandable formulation for constructing and updating the MG, and a reasoning model that predicts optimal dialog policies and recommendation items in unconstrained graph space. The prediction of our proposed model inherits the graph structure, providing a natural way to explain the model's recommendation. Experiments are conducted for both offline metrics and online simulation, showing competitive results.
Detecting Domain Polarity-Changes of Words in a Sentiment Lexicon
Apr 29, 2020
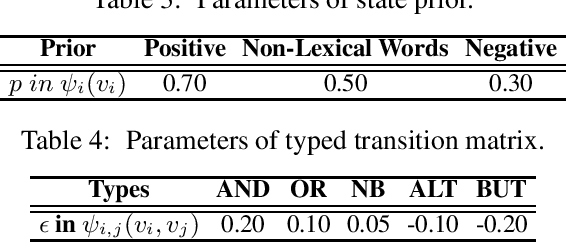
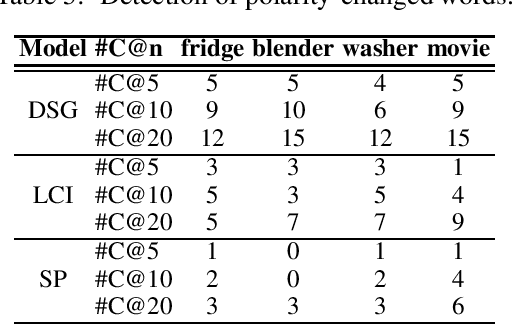
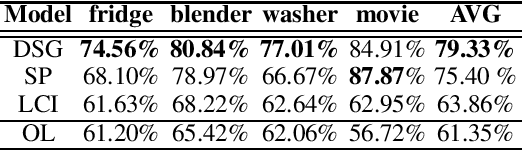
Sentiment lexicons are instrumental for sentiment analysis. One can use a set of sentiment words provided in a sentiment lexicon and a lexicon-based classifier to perform sentiment classification. One major issue with this approach is that many sentiment words are domain dependent. That is, they may be positive in some domains but negative in some others. We refer to this problem as domain polarity-changes of words. Detecting such words and correcting their sentiment for an application domain is very important. In this paper, we propose a graph-based technique to tackle this problem. Experimental results show its effectiveness on multiple real-world datasets.