 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeContinual Learning with Knowledge Transfer for Sentiment Classification
Dec 18, 2021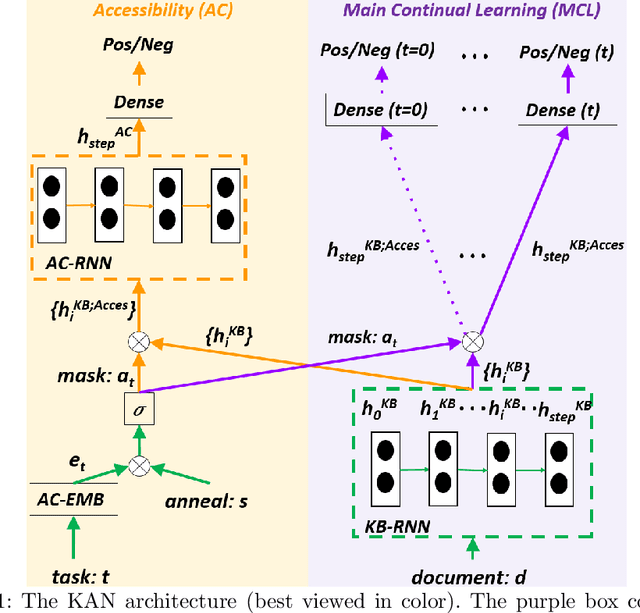
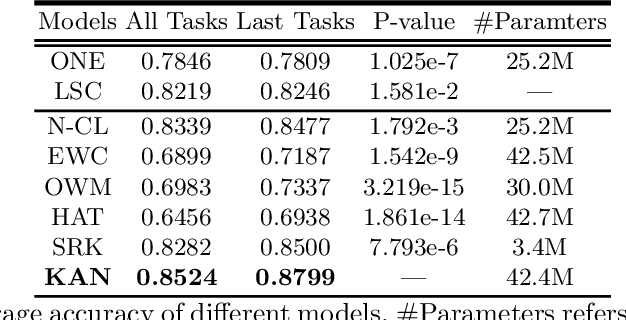
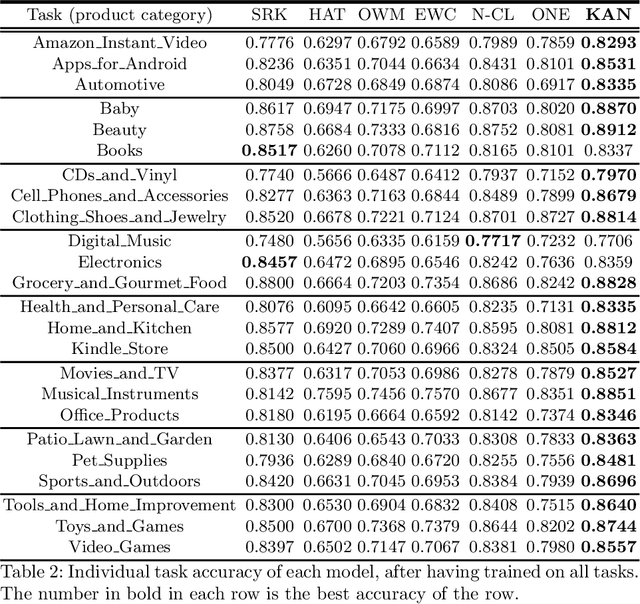
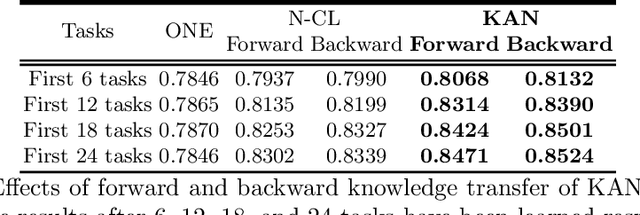
This paper studies continual learning (CL) for sentiment classification (SC). In this setting, the CL system learns a sequence of SC tasks incrementally in a neural network, where each task builds a classifier to classify the sentiment of reviews of a particular product category or domain. Two natural questions are: Can the system transfer the knowledge learned in the past from the previous tasks to the new task to help it learn a better model for the new task? And, can old models for previous tasks be improved in the process as well? This paper proposes a novel technique called KAN to achieve these objectives. KAN can markedly improve the SC accuracy of both the new task and the old tasks via forward and backward knowledge transfer. The effectiveness of KAN is demonstrated through extensive experiments.
Continual Learning of a Mixed Sequence of Similar and Dissimilar Tasks
Dec 18, 2021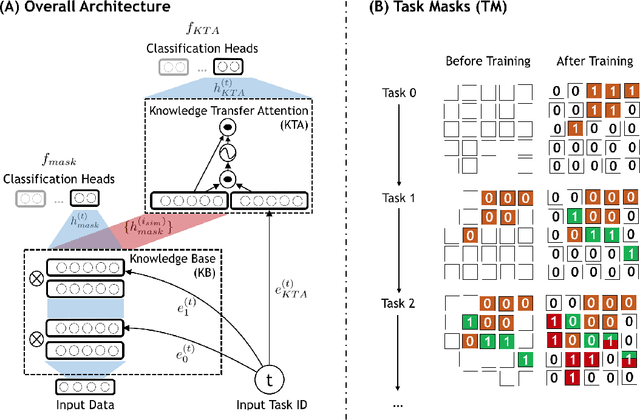
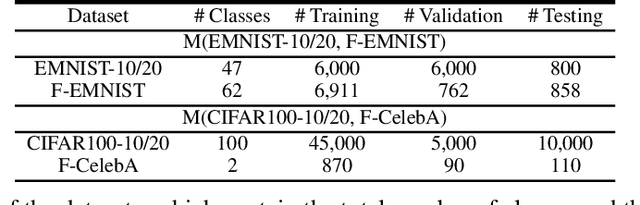
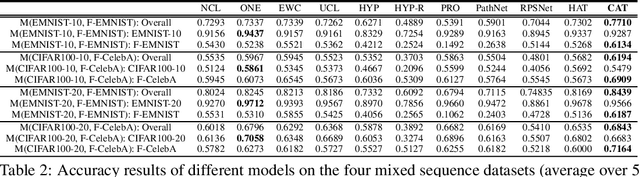
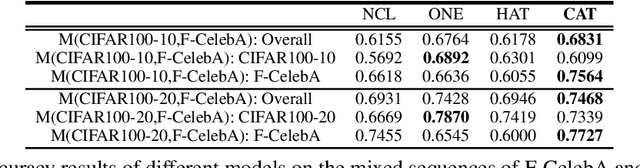
Existing research on continual learning of a sequence of tasks focused on dealing with catastrophic forgetting, where the tasks are assumed to be dissimilar and have little shared knowledge. Some work has also been done to transfer previously learned knowledge to the new task when the tasks are similar and have shared knowledge. To the best of our knowledge, no technique has been proposed to learn a sequence of mixed similar and dissimilar tasks that can deal with forgetting and also transfer knowledge forward and backward. This paper proposes such a technique to learn both types of tasks in the same network. For dissimilar tasks, the algorithm focuses on dealing with forgetting, and for similar tasks, the algorithm focuses on selectively transferring the knowledge learned from some similar previous tasks to improve the new task learning. Additionally, the algorithm automatically detects whether a new task is similar to any previous tasks. Empirical evaluation using sequences of mixed tasks demonstrates the effectiveness of the proposed model.
Adapting BERT for Continual Learning of a Sequence of Aspect Sentiment Classification Tasks
Dec 06, 2021
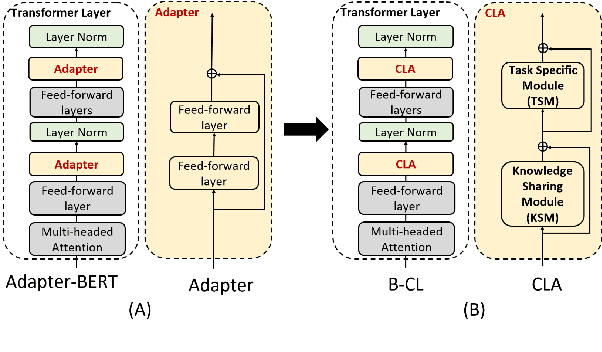
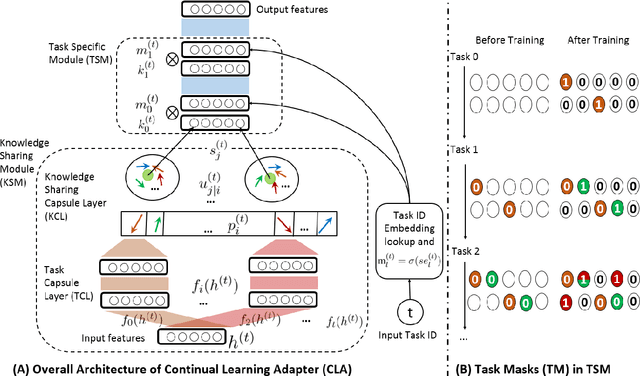
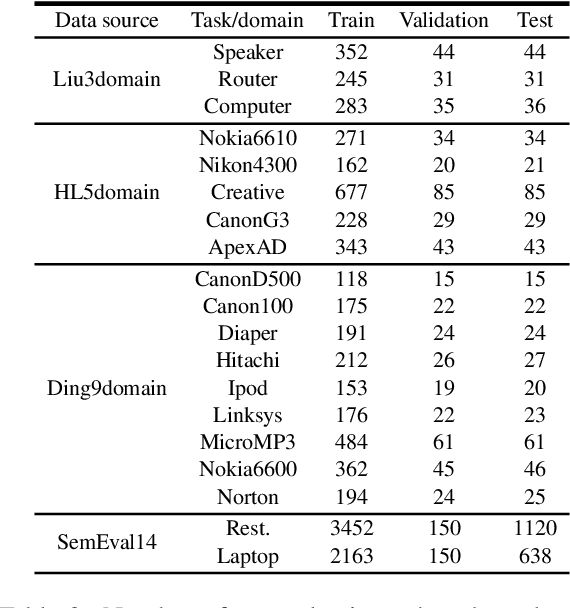
This paper studies continual learning (CL) of a sequence of aspect sentiment classification (ASC) tasks. Although some CL techniques have been proposed for document sentiment classification, we are not aware of any CL work on ASC. A CL system that incrementally learns a sequence of ASC tasks should address the following two issues: (1) transfer knowledge learned from previous tasks to the new task to help it learn a better model, and (2) maintain the performance of the models for previous tasks so that they are not forgotten. This paper proposes a novel capsule network based model called B-CL to address these issues. B-CL markedly improves the ASC performance on both the new task and the old tasks via forward and backward knowledge transfer. The effectiveness of B-CL is demonstrated through extensive experiments.
* arXiv admin note: text overlap with arXiv:2112.02714, arXiv:2112.02706
CLASSIC: Continual and Contrastive Learning of Aspect Sentiment Classification Tasks
Dec 05, 2021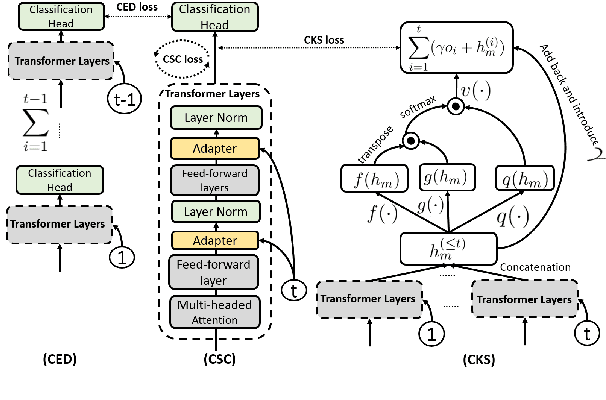
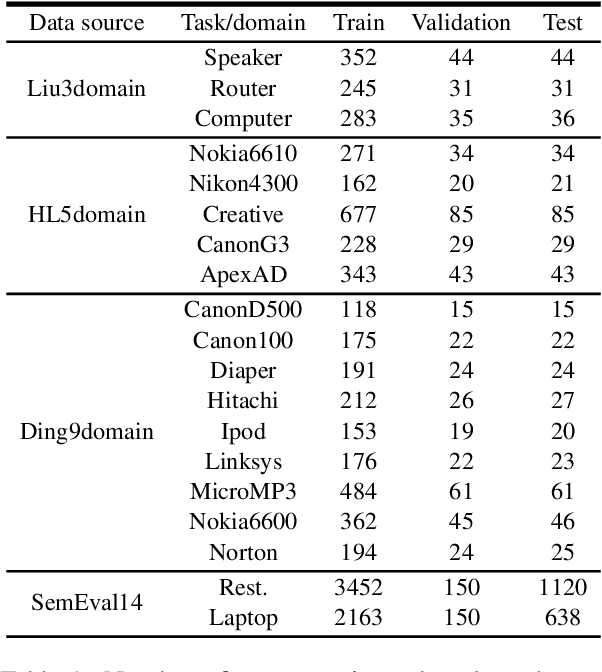

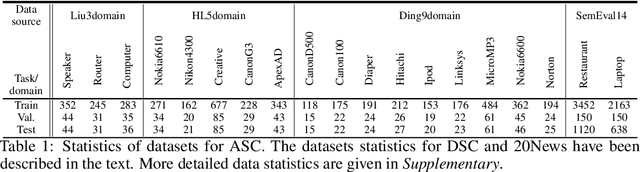
This paper studies continual learning (CL) of a sequence of aspect sentiment classification(ASC) tasks in a particular CL setting called domain incremental learning (DIL). Each task is from a different domain or product. The DIL setting is particularly suited to ASC because in testing the system needs not know the task/domain to which the test data belongs. To our knowledge, this setting has not been studied before for ASC. This paper proposes a novel model called CLASSIC. The key novelty is a contrastive continual learning method that enables both knowledge transfer across tasks and knowledge distillation from old tasks to the new task, which eliminates the need for task ids in testing. Experimental results show the high effectiveness of CLASSIC.
Achieving Forgetting Prevention and Knowledge Transfer in Continual Learning
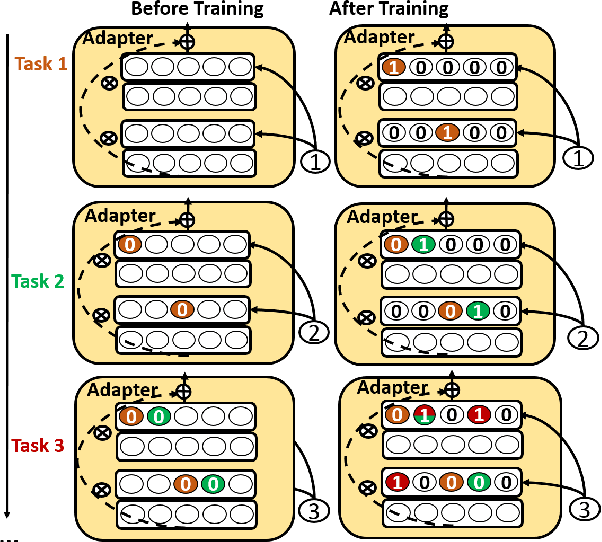
Dec 05, 2021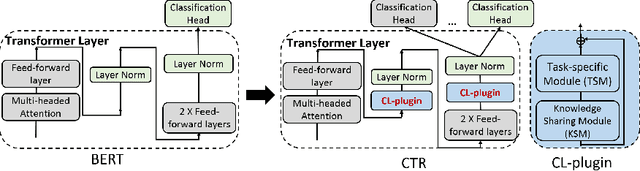
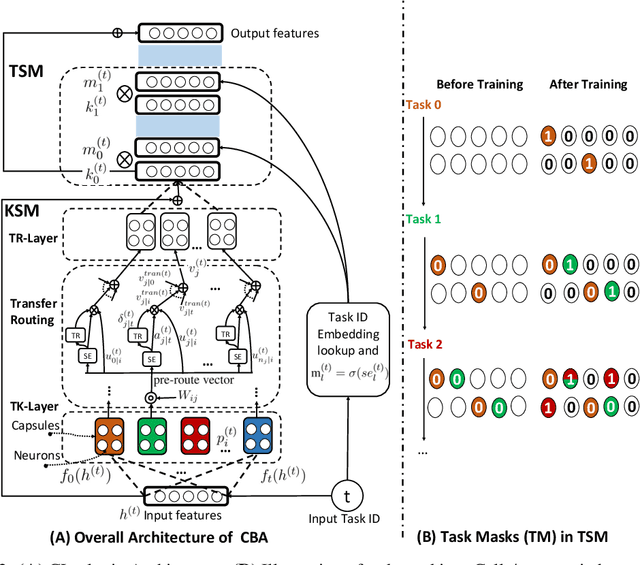
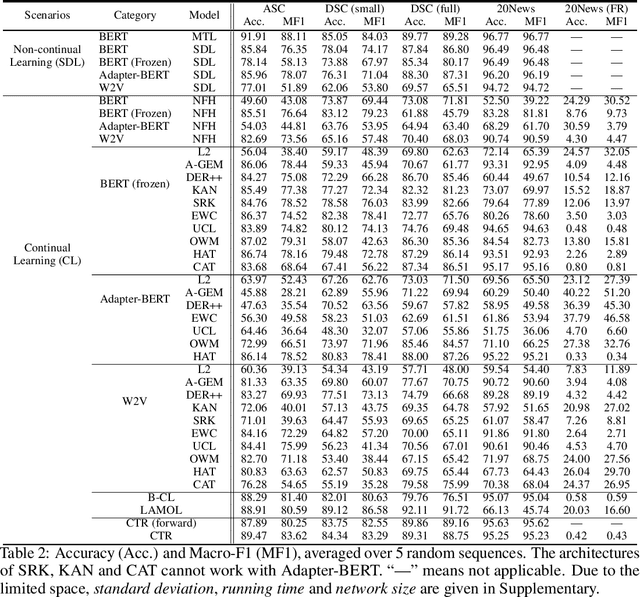
Continual learning (CL) learns a sequence of tasks incrementally with the goal of achieving two main objectives: overcoming catastrophic forgetting (CF) and encouraging knowledge transfer (KT) across tasks. However, most existing techniques focus only on overcoming CF and have no mechanism to encourage KT, and thus do not do well in KT. Although several papers have tried to deal with both CF and KT, our experiments show that they suffer from serious CF when the tasks do not have much shared knowledge. Another observation is that most current CL methods do not use pre-trained models, but it has been shown that such models can significantly improve the end task performance. For example, in natural language processing, fine-tuning a BERT-like pre-trained language model is one of the most effective approaches. However, for CL, this approach suffers from serious CF. An interesting question is how to make the best use of pre-trained models for CL. This paper proposes a novel model called CTR to solve these problems. Our experimental results demonstrate the effectiveness of CTR
Neural Collaborative Graph Machines for Table Structure Recognition
Nov 26, 2021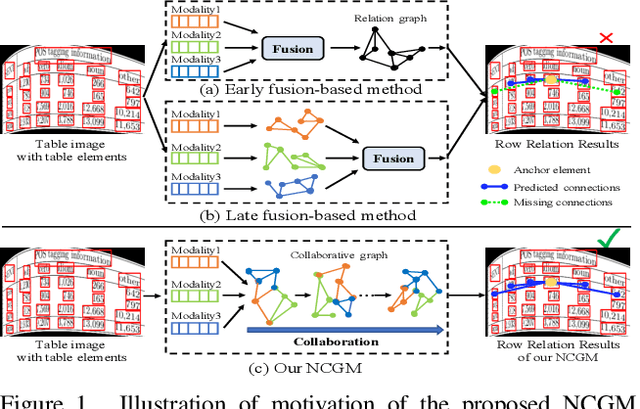
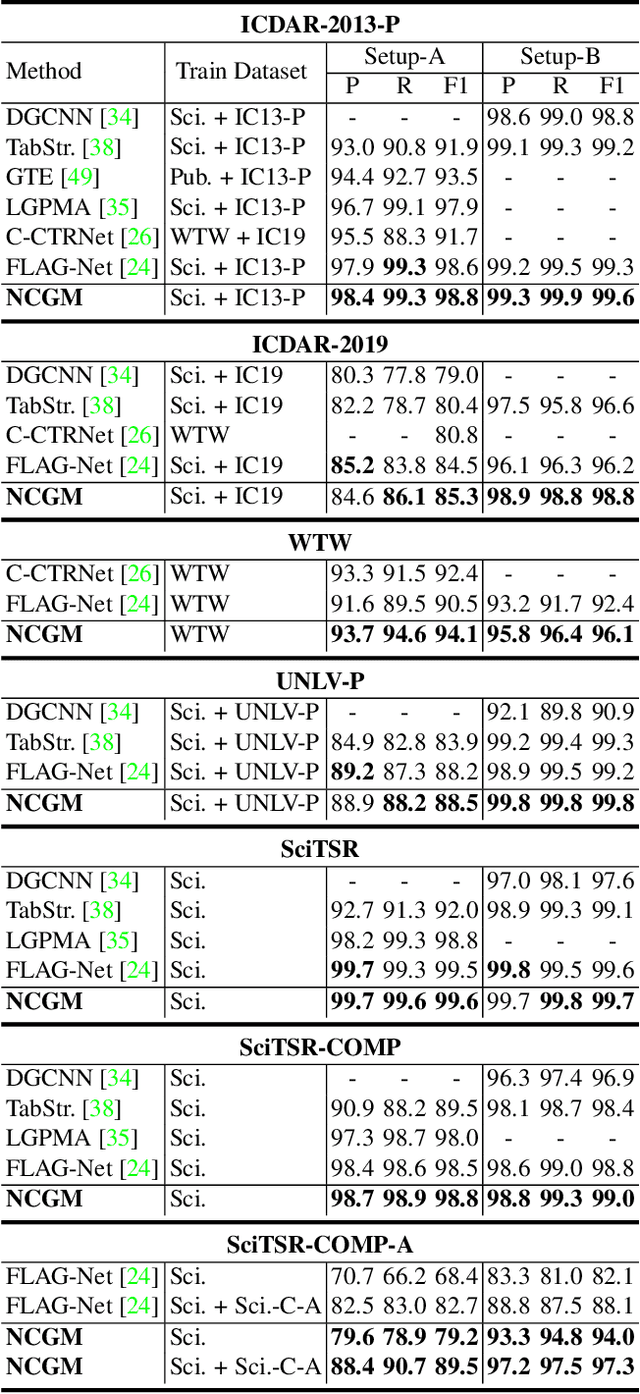
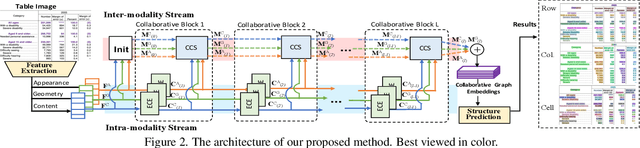
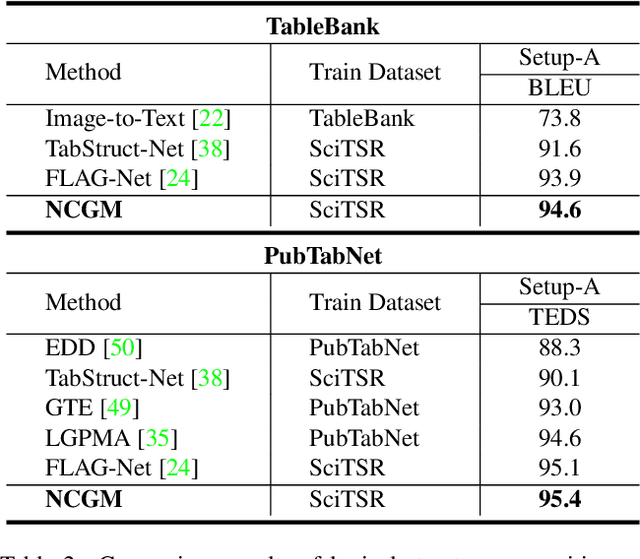
Recently, table structure recognition has achieved impressive progress with the help of deep graph models. Most of them exploit single visual cues of tabular elements or simply combine visual cues with other modalities via early fusion to reason their graph relationships. However, neither early fusion nor individually reasoning in terms of multiple modalities can be appropriate for all varieties of table structures with great diversity. Instead, different modalities are expected to collaborate with each other in different patterns for different table cases. In the community, the importance of intra-inter modality interactions for table structure reasoning is still unexplored. In this paper, we define it as heterogeneous table structure recognition (Hetero-TSR) problem. With the aim of filling this gap, we present a novel Neural Collaborative Graph Machines (NCGM) equipped with stacked collaborative blocks, which alternatively extracts intra-modality context and models inter-modality interactions in a hierarchical way. It can represent the intra-inter modality relationships of tabular elements more robustly, which significantly improves the recognition performance. We also show that the proposed NCGM can modulate collaborative pattern of different modalities conditioned on the context of intra-modality cues, which is vital for diversified table cases. Experimental results on benchmarks demonstrate our proposed NCGM achieves state-of-the-art performance and beats other contemporary methods by a large margin especially under challenging scenarios.
Defeating Catastrophic Forgetting via Enhanced Orthogonal Weights Modification
Nov 19, 2021
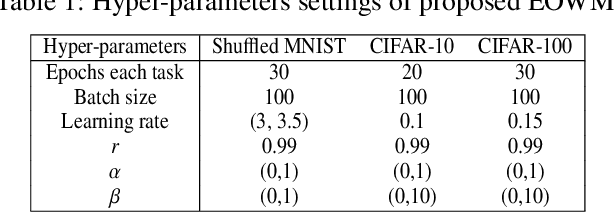
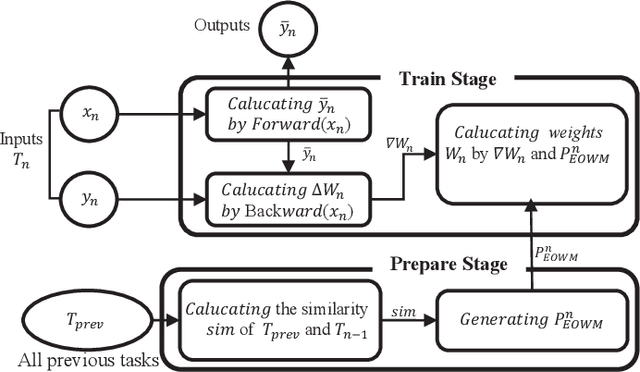
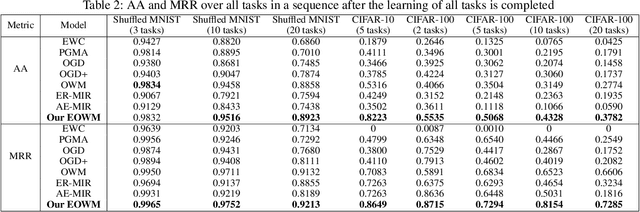
The ability of neural networks (NNs) to learn and remember multiple tasks sequentially is facing tough challenges in achieving general artificial intelligence due to their catastrophic forgetting (CF) issues. Fortunately, the latest OWM Orthogonal Weights Modification) and other several continual learning (CL) methods suggest some promising ways to overcome the CF issue. However, none of existing CL methods explores the following three crucial questions for effectively overcoming the CF issue: that is, what knowledge does it contribute to the effective weights modification of the NN during its sequential tasks learning? When the data distribution of a new learning task changes corresponding to the previous learned tasks, should a uniform/specific weight modification strategy be adopted or not? what is the upper bound of the learningable tasks sequentially for a given CL method? ect. To achieve this, in this paper, we first reveals the fact that of the weight gradient of a new learning task is determined by both the input space of the new task and the weight space of the previous learned tasks sequentially. On this observation and the recursive least square optimal method, we propose a new efficient and effective continual learning method EOWM via enhanced OWM. And we have theoretically and definitively given the upper bound of the learningable tasks sequentially of our EOWM. Extensive experiments conducted on the benchmarks demonstrate that our EOWM is effectiveness and outperform all of the state-of-the-art CL baselines.
Self-Initiated Open World Learning for Autonomous AI Agents
Oct 21, 2021As more and more AI agents are used in practice, it is time to think about how to make these agents fully autonomous so that they can learn by themselves in a self-motivated and self-supervised manner rather than being retrained periodically on the initiation of human engineers using expanded training data. As the real-world is an open environment with unknowns or novelties, detecting novelties or unknowns, gathering ground-truth training data, and incrementally learning the unknowns make the agent more and more knowledgeable and powerful over time. The key challenge is how to automate the process so that it is carried out on the agent's own initiative and through its own interactions with humans and the environment. Since an AI agent usually has a performance task, characterizing each novelty becomes necessary so that the agent can formulate an appropriate response to adapt its behavior to cope with the novelty and to learn from it to improve its future responses and task performance. This paper proposes a theoretic framework for this learning paradigm to promote the research of building self-initiated open world learning agents.
ActiveEA: Active Learning for Neural Entity Alignment
Oct 13, 2021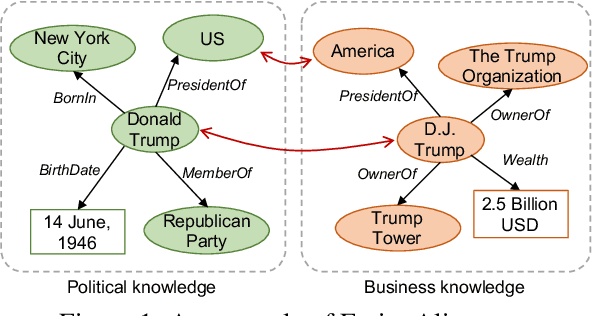
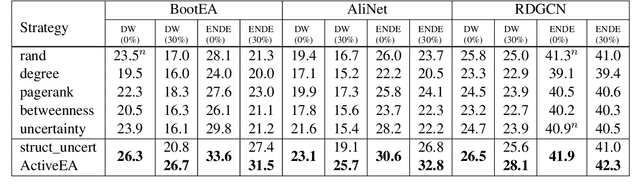
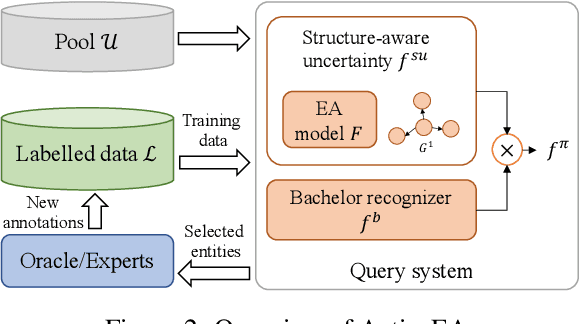
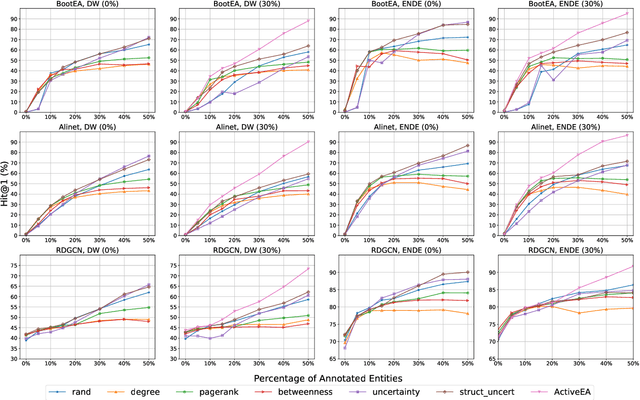
Entity Alignment (EA) aims to match equivalent entities across different Knowledge Graphs (KGs) and is an essential step of KG fusion. Current mainstream methods -- neural EA models -- rely on training with seed alignment, i.e., a set of pre-aligned entity pairs which are very costly to annotate. In this paper, we devise a novel Active Learning (AL) framework for neural EA, aiming to create highly informative seed alignment to obtain more effective EA models with less annotation cost. Our framework tackles two main challenges encountered when applying AL to EA: (1) How to exploit dependencies between entities within the AL strategy. Most AL strategies assume that the data instances to sample are independent and identically distributed. However, entities in KGs are related. To address this challenge, we propose a structure-aware uncertainty sampling strategy that can measure the uncertainty of each entity as well as its impact on its neighbour entities in the KG. (2) How to recognise entities that appear in one KG but not in the other KG (i.e., bachelors). Identifying bachelors would likely save annotation budget. To address this challenge, we devise a bachelor recognizer paying attention to alleviate the effect of sampling bias. Empirical results show that our proposed AL strategy can significantly improve sampling quality with good generality across different datasets, EA models and amount of bachelors.
Zero-Shot Open Set Detection by Extending CLIP
Sep 10, 2021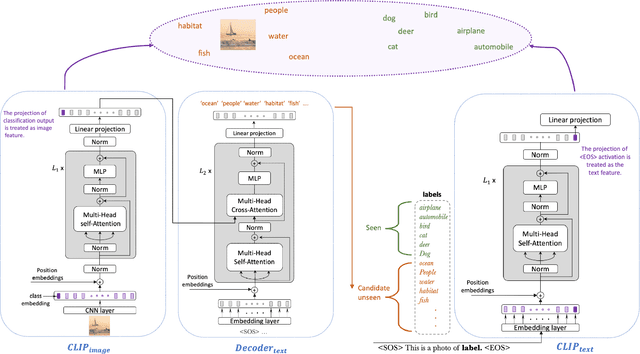
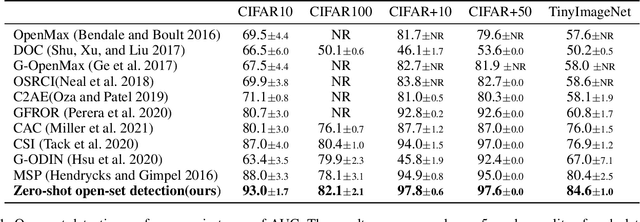
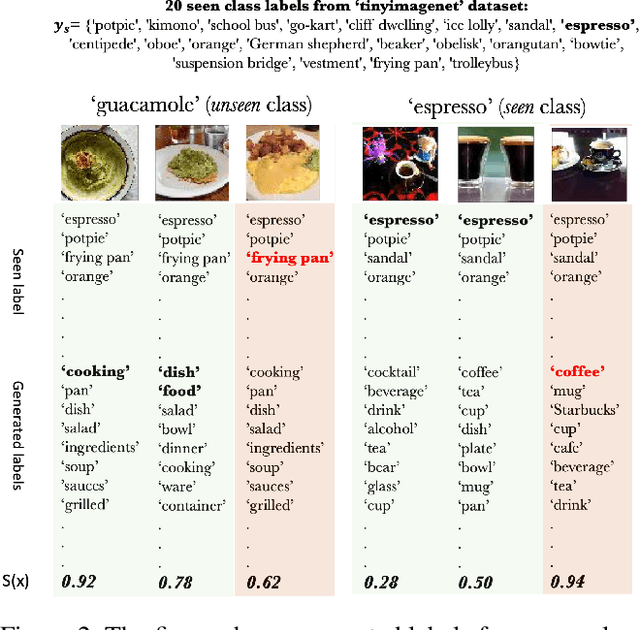
In a regular open set detection problem, samples of known classes (also called closed set classes) are used to train a special classifier. In testing, the classifier can (1) classify the test samples of known classes to their respective classes and (2) also detect samples that do not belong to any of the known classes (we say they belong to some unknown or open set classes). This paper studies the problem of zero-shot open-set detection, which still performs the same two tasks in testing but has no training except using the given known class names. This paper proposes a novel and yet simple method (called ZO-CLIP) to solve the problem. ZO-CLIP builds on top of the recent advances in zero-shot classification through multi-modal representation learning. It first extends the pre-trained multi-modal model CLIP by training a text-based image description generator on top of CLIP. In testing, it uses the extended model to generate some candidate unknown class names for each test sample and computes a confidence score based on both the known class names and candidate unknown class names for zero-shot open set detection. Experimental results on 5 benchmark datasets for open set detection confirm that ZO-CLIP outperforms the baselines by a large margin.