 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCrossAD: Time Series Anomaly Detection with Cross-scale Associations and Cross-window Modeling
Oct 14, 2025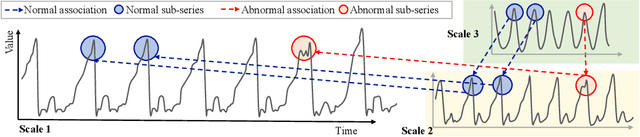

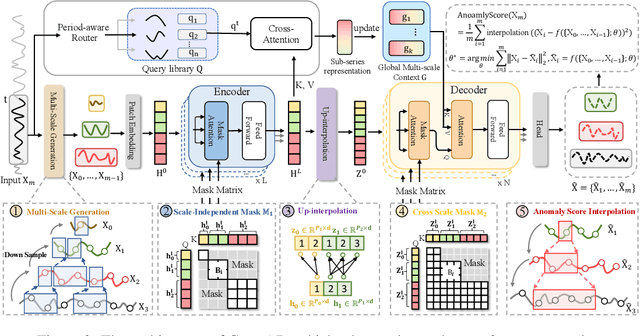

Time series anomaly detection plays a crucial role in a wide range of real-world applications. Given that time series data can exhibit different patterns at different sampling granularities, multi-scale modeling has proven beneficial for uncovering latent anomaly patterns that may not be apparent at a single scale. However, existing methods often model multi-scale information independently or rely on simple feature fusion strategies, neglecting the dynamic changes in cross-scale associations that occur during anomalies. Moreover, most approaches perform multi-scale modeling based on fixed sliding windows, which limits their ability to capture comprehensive contextual information. In this work, we propose CrossAD, a novel framework for time series Anomaly Detection that takes Cross-scale associations and Cross-window modeling into account. We propose a cross-scale reconstruction that reconstructs fine-grained series from coarser series, explicitly capturing cross-scale associations. Furthermore, we design a query library and incorporate global multi-scale context to overcome the limitations imposed by fixed window sizes. Extensive experiments conducted on multiple real-world datasets using nine evaluation metrics validate the effectiveness of CrossAD, demonstrating state-of-the-art performance in anomaly detection.
Unlocking the Power of Mixture-of-Experts for Task-Aware Time Series Analytics
Sep 26, 2025Time Series Analysis is widely used in various real-world applications such as weather forecasting, financial fraud detection, imputation for missing data in IoT systems, and classification for action recognization. Mixture-of-Experts (MoE), as a powerful architecture, though demonstrating effectiveness in NLP, still falls short in adapting to versatile tasks in time series analytics due to its task-agnostic router and the lack of capability in modeling channel correlations. In this study, we propose a novel, general MoE-based time series framework called PatchMoE to support the intricate ``knowledge'' utilization for distinct tasks, thus task-aware. Based on the observation that hierarchical representations often vary across tasks, e.g., forecasting vs. classification, we propose a Recurrent Noisy Gating to utilize the hierarchical information in routing, thus obtaining task-sepcific capability. And the routing strategy is operated on time series tokens in both temporal and channel dimensions, and encouraged by a meticulously designed Temporal \& Channel Load Balancing Loss to model the intricate temporal and channel correlations. Comprehensive experiments on five downstream tasks demonstrate the state-of-the-art performance of PatchMoE.
Aurora: Towards Universal Generative Multimodal Time Series Forecasting
Sep 26, 2025Cross-domain generalization is very important in Time Series Forecasting because similar historical information may lead to distinct future trends due to the domain-specific characteristics. Recent works focus on building unimodal time series foundation models and end-to-end multimodal supervised models. Since domain-specific knowledge is often contained in modalities like texts, the former lacks the explicit utilization of them, thus hindering the performance. The latter is tailored for end-to-end scenarios and does not support zero-shot inference for cross-domain scenarios. In this work, we introduce Aurora, a Multimodal Time Series Foundation Model, which supports multimodal inputs and zero-shot inference. Pretrained on Corss-domain Multimodal Time Series Corpus, Aurora can adaptively extract and focus on key domain knowledge contained in corrsponding text or image modalities, thus possessing strong Cross-domain generalization capability. Through tokenization, encoding, and distillation, Aurora can extract multimodal domain knowledge as guidance and then utilizes a Modality-Guided Multi-head Self-Attention to inject them into the modeling of temporal representations. In the decoding phase, the multimodal representations are used to generate the conditions and prototypes of future tokens, contributing to a novel Prototype-Guided Flow Matching for generative probabilistic forecasting. Comprehensive experiments on well-recognized benchmarks, including TimeMMD, TSFM-Bench and ProbTS, demonstrate the consistent state-of-the-art performance of Aurora on both unimodal and multimodal scenarios.
Hybrid Baseband Simulation for Single-Channel Radar-Based Indoor Localization System
Sep 19, 2025Indoor localization with chirp sequence radar at millimeter wavelength offers high localization accuracy at low system cost. We propose a hybrid radar baseband signal simulator for our novel single-channel radar-based indoor localization system consisting of an active radar and passive reflectors as references. By combining ray tracing channel simulations with real measurements of the two-way antenna gain of the radar and accurate simulation of the radar cross section of chosen reflectors, realistic modeling of the baseband receive signal in complex scenarios is achieved.
DAG: A Dual Causal Network for Time Series Forecasting with Exogenous Variables
Sep 18, 2025Time series forecasting is crucial in various fields such as economics, traffic, and AIOps. However, in real-world applications, focusing solely on the endogenous variables (i.e., target variables), is often insufficient to ensure accurate predictions. Considering exogenous variables (i.e., covariates) provides additional predictive information, thereby improving forecasting accuracy. However, existing methods for time series forecasting with exogenous variables (TSF-X) have the following shortcomings: 1) they do not leverage future exogenous variables, 2) they fail to account for the causal relationships between endogenous and exogenous variables. As a result, their performance is suboptimal. In this study, to better leverage exogenous variables, especially future exogenous variable, we propose a general framework DAG, which utilizes dual causal network along both the temporal and channel dimensions for time series forecasting with exogenous variables. Specifically, we first introduce the Temporal Causal Module, which includes a causal discovery module to capture how historical exogenous variables affect future exogenous variables. Following this, we construct a causal injection module that incorporates the discovered causal relationships into the process of forecasting future endogenous variables based on historical endogenous variables. Next, we propose the Channel Causal Module, which follows a similar design principle. It features a causal discovery module models how historical exogenous variables influence historical endogenous variables, and a causal injection module incorporates the discovered relationships to enhance the prediction of future endogenous variables based on future exogenous variables.
Test-Time Adaptation for Speech Enhancement via Domain Invariant Embedding Transformation
Sep 04, 2025Deep learning-based speech enhancement models achieve remarkable performance when test distributions match training conditions, but often degrade when deployed in unpredictable real-world environments with domain shifts. To address this challenge, we present LaDen (latent denoising), the first test-time adaptation method specifically designed for speech enhancement. Our approach leverages powerful pre-trained speech representations to perform latent denoising, approximating clean speech representations through a linear transformation of noisy embeddings. We show that this transformation generalizes well across domains, enabling effective pseudo-labeling for target domains without labeled target data. The resulting pseudo-labels enable effective test-time adaptation of speech enhancement models across diverse acoustic environments. We propose a comprehensive benchmark spanning multiple datasets with various domain shifts, including changes in noise types, speaker characteristics, and languages. Our extensive experiments demonstrate that LaDen consistently outperforms baseline methods across perceptual metrics, particularly for speaker and language domain shifts.
CC-Time: Cross-Model and Cross-Modality Time Series Forecasting
Aug 17, 2025



With the success of pre-trained language models (PLMs) in various application fields beyond natural language processing, language models have raised emerging attention in the field of time series forecasting (TSF) and have shown great prospects. However, current PLM-based TSF methods still fail to achieve satisfactory prediction accuracy matching the strong sequential modeling power of language models. To address this issue, we propose Cross-Model and Cross-Modality Learning with PLMs for time series forecasting (CC-Time). We explore the potential of PLMs for time series forecasting from two aspects: 1) what time series features could be modeled by PLMs, and 2) whether relying solely on PLMs is sufficient for building time series models. In the first aspect, CC-Time incorporates cross-modality learning to model temporal dependency and channel correlations in the language model from both time series sequences and their corresponding text descriptions. In the second aspect, CC-Time further proposes the cross-model fusion block to adaptively integrate knowledge from the PLMs and time series model to form a more comprehensive modeling of time series patterns. Extensive experiments on nine real-world datasets demonstrate that CC-Time achieves state-of-the-art prediction accuracy in both full-data training and few-shot learning situations.
Tailoring deep learning for real-time brain-computer interfaces: From offline models to calibration-free online decoding
Jul 09, 2025



Despite the growing success of deep learning (DL) in offline brain-computer interfaces (BCIs), its adoption in real-time applications remains limited due to three primary challenges. First, most DL solutions are designed for offline decoding, making the transition to online decoding unclear. Second, the use of sliding windows in online decoding substantially increases computational complexity. Third, DL models typically require large amounts of training data, which are often scarce in BCI applications. To address these challenges and enable real-time, cross-subject decoding without subject-specific calibration, we introduce realtime adaptive pooling (RAP), a novel parameter-free method. RAP seamlessly modifies the pooling layers of existing offline DL models to meet online decoding requirements. It also reduces computational complexity during training by jointly decoding consecutive sliding windows. To further alleviate data requirements, our method leverages source-free domain adaptation, enabling privacy-preserving adaptation across varying amounts of target data. Our results demonstrate that RAP provides a robust and efficient framework for real-time BCI applications. It preserves privacy, reduces calibration demands, and supports co-adaptive BCI systems, paving the way for broader adoption of DL in online BCIs. These findings lay a strong foundation for developing user-centered, high-performance BCIs that facilitate immediate feedback and user learning.
Prioritizing Alignment Paradigms over Task-Specific Model Customization in Time-Series LLMs
Jun 13, 2025Recent advances in Large Language Models (LLMs) have enabled unprecedented capabilities for time-series reasoning in diverse real-world applications, including medical, financial, and spatio-temporal domains. However, existing approaches typically focus on task-specific model customization, such as forecasting and anomaly detection, while overlooking the data itself, referred to as time-series primitives, which are essential for in-depth reasoning. This position paper advocates a fundamental shift in approaching time-series reasoning with LLMs: prioritizing alignment paradigms grounded in the intrinsic primitives of time series data over task-specific model customization. This realignment addresses the core limitations of current time-series reasoning approaches, which are often costly, inflexible, and inefficient, by systematically accounting for intrinsic structure of data before task engineering. To this end, we propose three alignment paradigms: Injective Alignment, Bridging Alignment, and Internal Alignment, which are emphasized by prioritizing different aspects of time-series primitives: domain, characteristic, and representation, respectively, to activate time-series reasoning capabilities of LLMs to enable economical, flexible, and efficient reasoning. We further recommend that practitioners adopt an alignment-oriented method to avail this instruction to select an appropriate alignment paradigm. Additionally, we categorize relevant literature into these alignment paradigms and outline promising research directions.
LightGTS: A Lightweight General Time Series Forecasting Model
Jun 06, 2025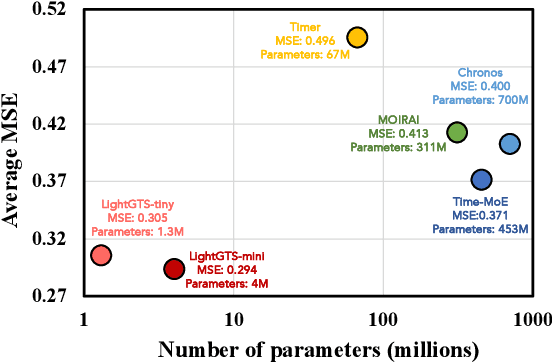
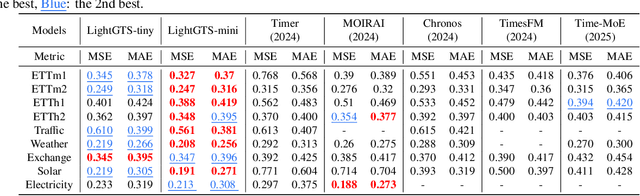
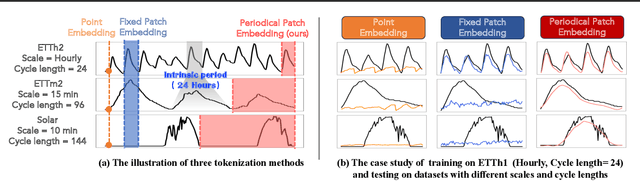
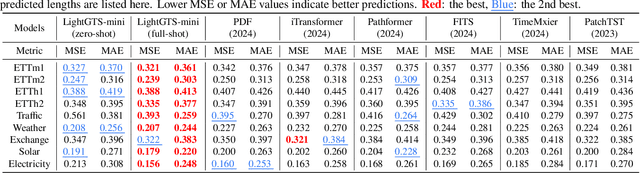
Existing works on general time series forecasting build foundation models with heavy model parameters through large-scale multi-source pre-training. These models achieve superior generalization ability across various datasets at the cost of significant computational burdens and limitations in resource-constrained scenarios. This paper introduces LightGTS, a lightweight general time series forecasting model designed from the perspective of consistent periodical modeling. To handle diverse scales and intrinsic periods in multi-source pre-training, we introduce Periodical Tokenization, which extracts consistent periodic patterns across different datasets with varying scales. To better utilize the periodicity in the decoding process, we further introduce Periodical Parallel Decoding, which leverages historical tokens to improve forecasting. Based on the two techniques above which fully leverage the inductive bias of periods inherent in time series, LightGTS uses a lightweight model to achieve outstanding performance on general time series forecasting. It achieves state-of-the-art forecasting performance on 9 real-world benchmarks in both zero-shot and full-shot settings with much better efficiency compared with existing time series foundation models.