 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeContextualized Perturbation for Textual Adversarial Attack
Sep 16, 2020
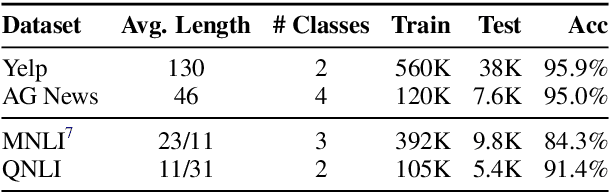
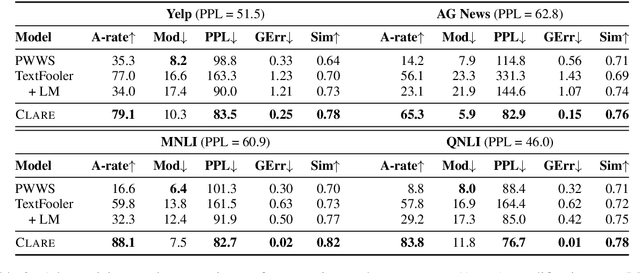
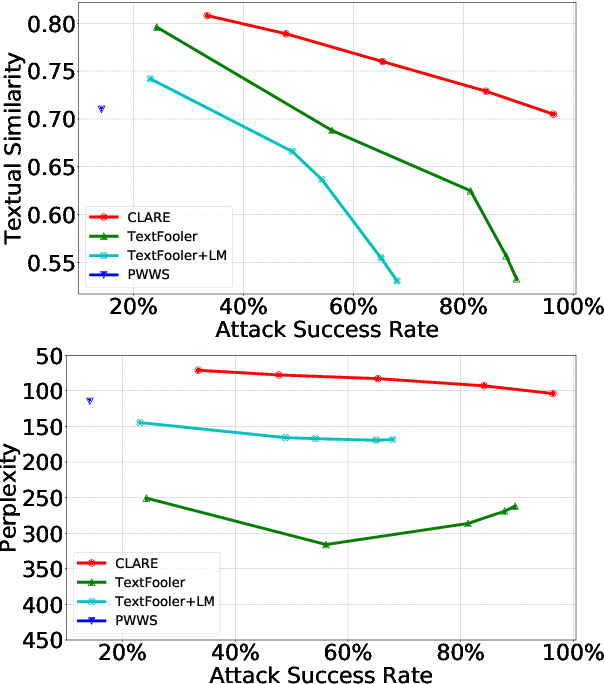
Adversarial examples expose the vulnerabilities of natural language processing (NLP) models, and can be used to evaluate and improve their robustness. Existing techniques of generating such examples are typically driven by local heuristic rules that are agnostic to the context, often resulting in unnatural and ungrammatical outputs. This paper presents CLARE, a ContextuaLized AdversaRial Example generation model that produces fluent and grammatical outputs through a mask-then-infill procedure. CLARE builds on a pre-trained masked language model and modifies the inputs in a context-aware manner. We propose three contextualized perturbations, Replace, Insert and Merge, allowing for generating outputs of varied lengths. With a richer range of available strategies, CLARE is able to attack a victim model more efficiently with fewer edits. Extensive experiments and human evaluation demonstrate that CLARE outperforms the baselines in terms of attack success rate, textual similarity, fluency and grammaticality.
Dialogue Response Ranking Training with Large-Scale Human Feedback Data
Sep 15, 2020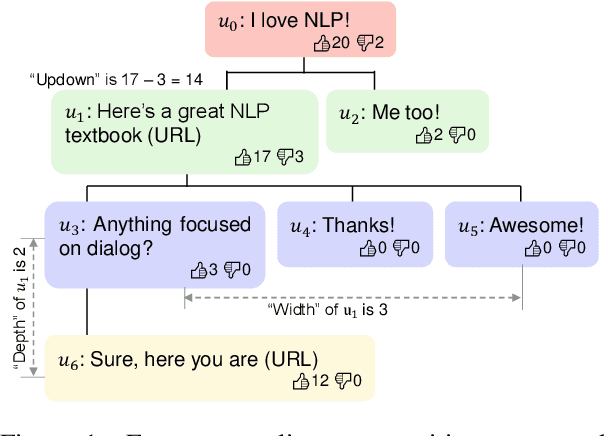
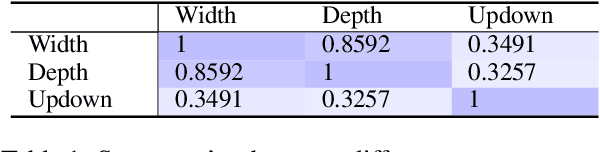
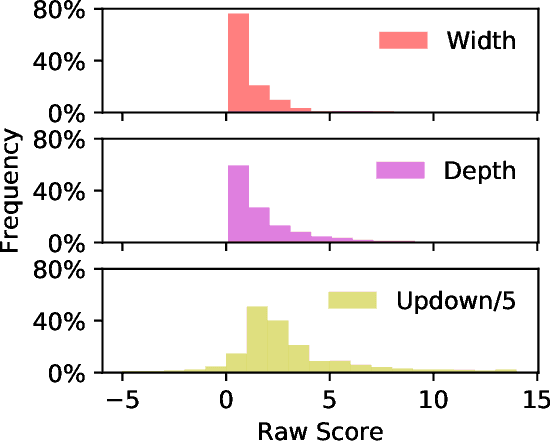
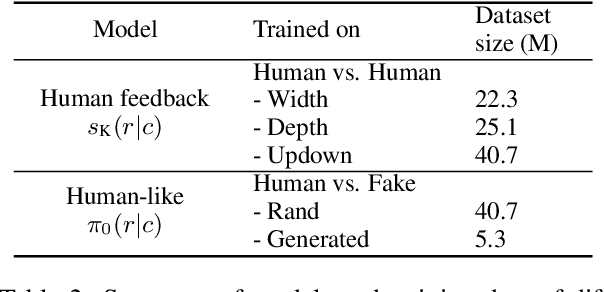
Existing open-domain dialog models are generally trained to minimize the perplexity of target human responses. However, some human replies are more engaging than others, spawning more followup interactions. Current conversational models are increasingly capable of producing turns that are context-relevant, but in order to produce compelling agents, these models need to be able to predict and optimize for turns that are genuinely engaging. We leverage social media feedback data (number of replies and upvotes) to build a large-scale training dataset for feedback prediction. To alleviate possible distortion between the feedback and engagingness, we convert the ranking problem to a comparison of response pairs which involve few confounding factors. We trained DialogRPT, a set of GPT-2 based models on 133M pairs of human feedback data and the resulting ranker outperformed several baselines. Particularly, our ranker outperforms the conventional dialog perplexity baseline with a large margin on predicting Reddit feedback. We finally combine the feedback prediction models and a human-like scoring model to rank the machine-generated dialog responses. Crowd-sourced human evaluation shows that our ranking method correlates better with real human preferences than baseline models.
Reparameterized Variational Divergence Minimization for Stable Imitation
Jun 18, 2020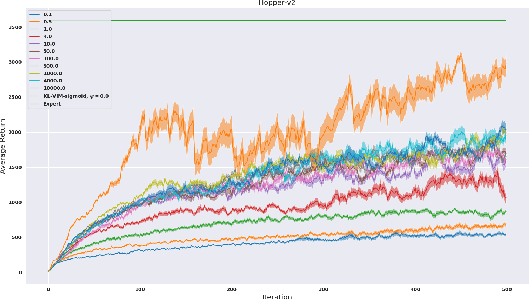

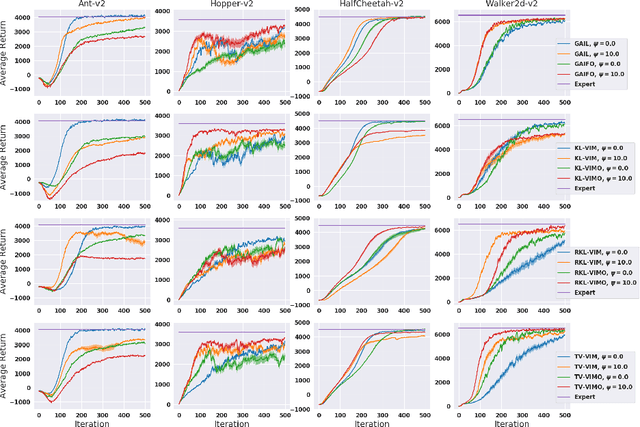
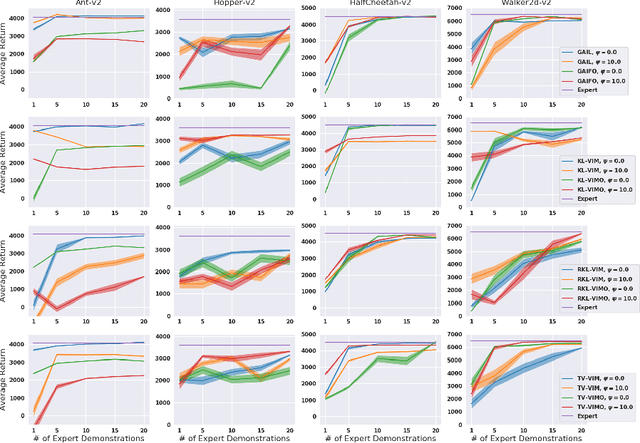
While recent state-of-the-art results for adversarial imitation-learning algorithms are encouraging, recent works exploring the imitation learning from observation (ILO) setting, where trajectories \textit{only} contain expert observations, have not been met with the same success. Inspired by recent investigations of $f$-divergence manipulation for the standard imitation learning setting(Ke et al., 2019; Ghasemipour et al., 2019), we here examine the extent to which variations in the choice of probabilistic divergence may yield more performant ILO algorithms. We unfortunately find that $f$-divergence minimization through reinforcement learning is susceptible to numerical instabilities. We contribute a reparameterization trick for adversarial imitation learning to alleviate the optimization challenges of the promising $f$-divergence minimization framework. Empirically, we demonstrate that our design choices allow for ILO algorithms that outperform baseline approaches and more closely match expert performance in low-dimensional continuous-control tasks.
A Recipe for Creating Multimodal Aligned Datasets for Sequential Tasks
May 19, 2020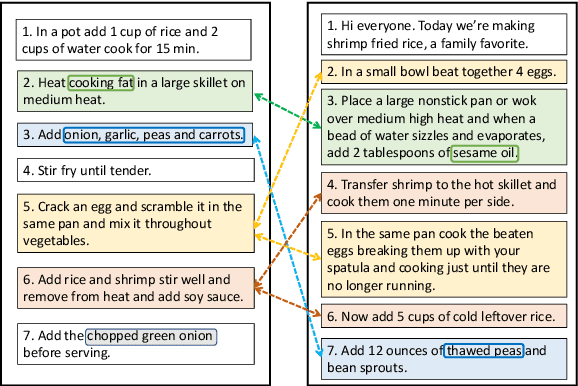
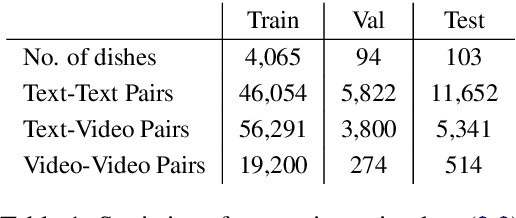
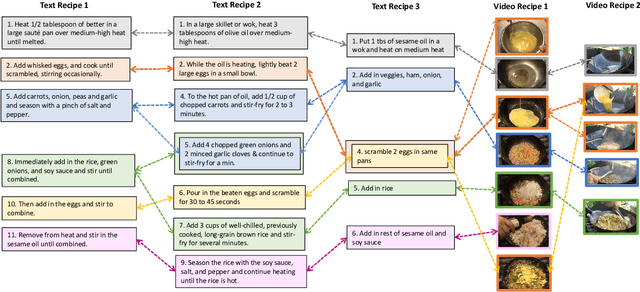
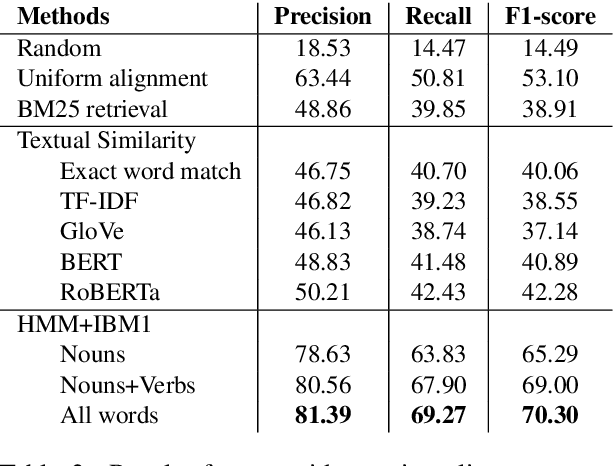
Many high-level procedural tasks can be decomposed into sequences of instructions that vary in their order and choice of tools. In the cooking domain, the web offers many partially-overlapping text and video recipes (i.e. procedures) that describe how to make the same dish (i.e. high-level task). Aligning instructions for the same dish across different sources can yield descriptive visual explanations that are far richer semantically than conventional textual instructions, providing commonsense insight into how real-world procedures are structured. Learning to align these different instruction sets is challenging because: a) different recipes vary in their order of instructions and use of ingredients; and b) video instructions can be noisy and tend to contain far more information than text instructions. To address these challenges, we first use an unsupervised alignment algorithm that learns pairwise alignments between instructions of different recipes for the same dish. We then use a graph algorithm to derive a joint alignment between multiple text and multiple video recipes for the same dish. We release the Microsoft Research Multimodal Aligned Recipe Corpus containing 150K pairwise alignments between recipes across 4,262 dishes with rich commonsense information.
* This paper has been accepted to be published at ACL 2020
MixingBoard: a Knowledgeable Stylized Integrated Text Generation Platform
May 17, 2020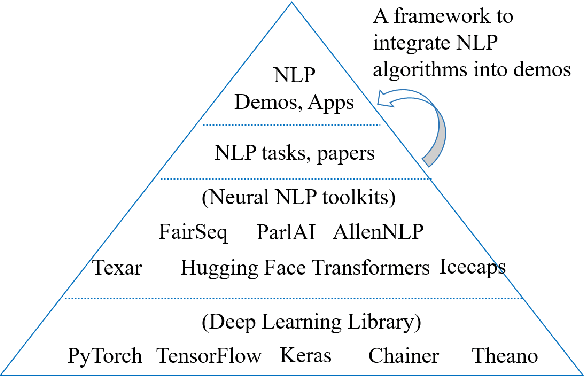
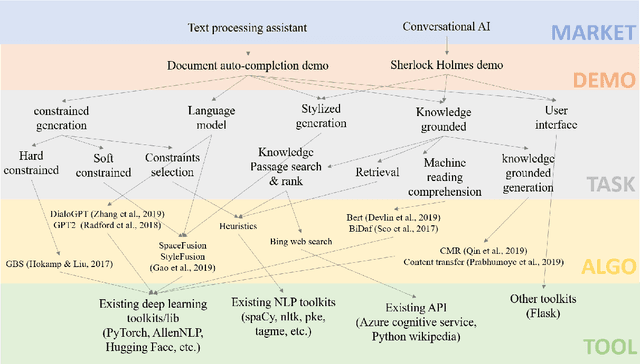
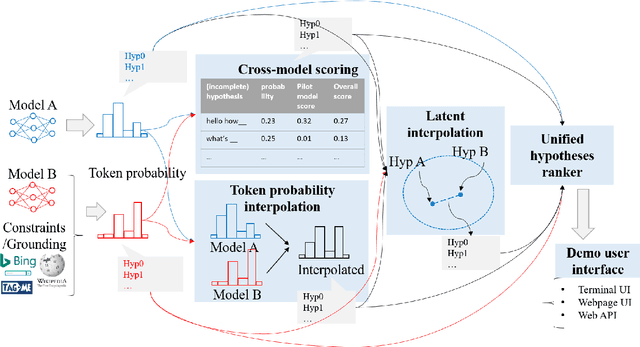
We present MixingBoard, a platform for quickly building demos with a focus on knowledge grounded stylized text generation. We unify existing text generation algorithms in a shared codebase and further adapt earlier algorithms for constrained generation. To borrow advantages from different models, we implement strategies for cross-model integration, from the token probability level to the latent space level. An interface to external knowledge is provided via a module that retrieves on-the-fly relevant knowledge from passages on the web or any document collection. A user interface for local development, remote webpage access, and a RESTful API are provided to make it simple for users to build their own demos.
A Controllable Model of Grounded Response Generation
May 01, 2020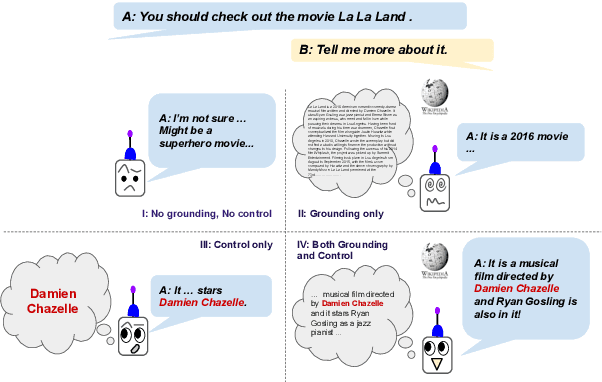
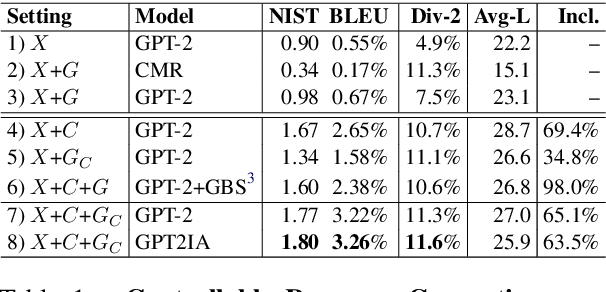
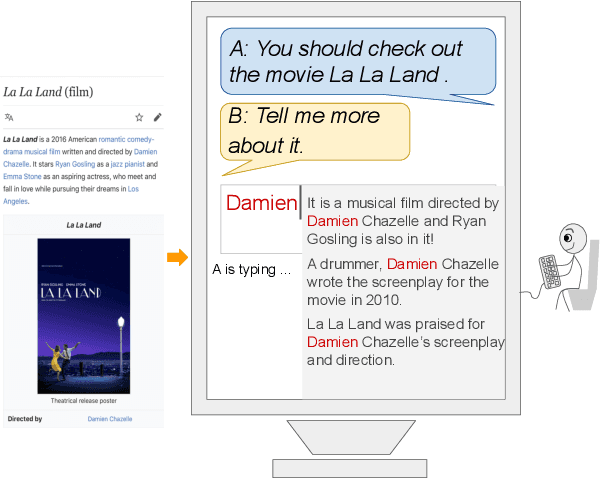
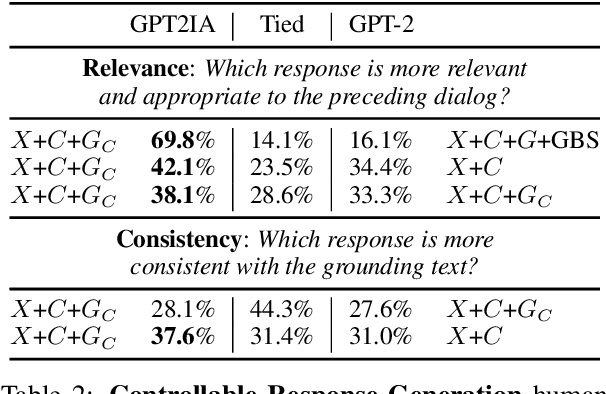
Current end-to-end neural conversation models inherently lack the flexibility to impose semantic control in the response generation process. This control is essential to ensure that users' semantic intents are satisfied and to impose a degree of specificity on generated outputs. Attempts to boost informativeness alone come at the expense of factual accuracy, as attested by GPT-2's propensity to "hallucinate" facts. While this may be mitigated by access to background knowledge, there is scant guarantee of relevance and informativeness in generated responses. We propose a framework that we call controllable grounded response generation (CGRG), in which lexical control phrases are either provided by an user or automatically extracted by a content planner from dialogue context and grounding knowledge. Quantitative and qualitative results show that, using this framework, a GPT-2 based model trained on a conversation-like Reddit dataset outperforms strong generation baselines.
POINTER: Constrained Text Generation via Insertion-based Generative Pre-training
May 01, 2020

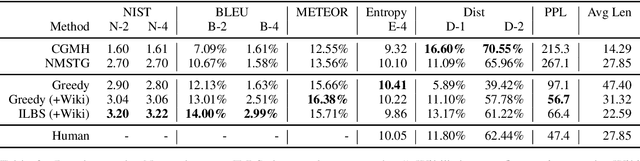
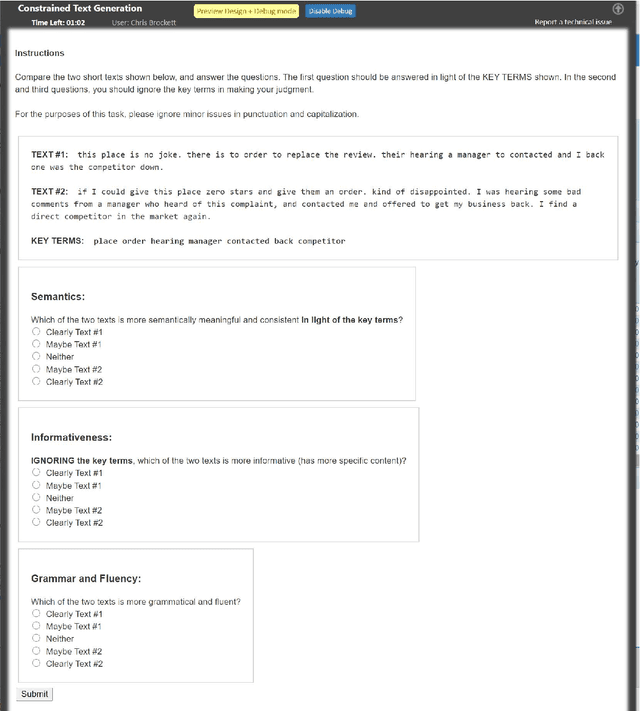
Large-scale pre-trained language models, such as BERT and GPT-2, have achieved excellent performance in language representation learning and free-form text generation. However, these models cannot be directly employed to generate text under specified lexical constraints. To address this challenge, we present POINTER, a simple yet novel insertion-based approach for hard-constrained text generation. The proposed method operates by progressively inserting new tokens between existing tokens in a parallel manner. This procedure is recursively applied until a sequence is completed. The resulting coarse-to-fine hierarchy makes the generation process intuitive and interpretable. Since our training objective resembles the objective of masked language modeling, BERT can be naturally utilized for initialization. We pre-train our model with the proposed progressive insertion-based objective on a 12GB Wikipedia dataset, and fine-tune it on downstream hard-constrained generation tasks. Non-autoregressive decoding yields a logarithmic time complexity during inference time. Experimental results on both News and Yelp datasets demonstrate that POINTER achieves state-of-the-art performance on constrained text generation. We intend to release the pre-trained model to facilitate future research.
Unsupervised Common Question Generation from Multiple Documents using Reinforced Contrastive Coordinator
Nov 08, 2019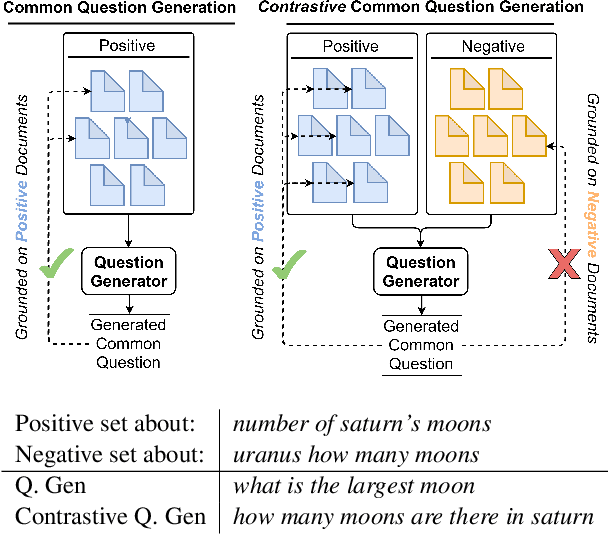
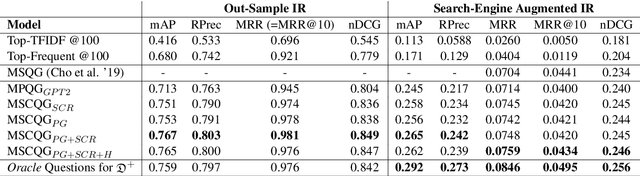
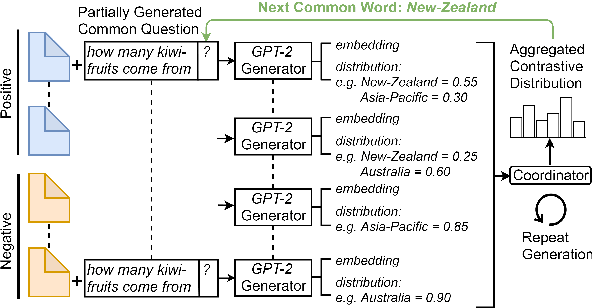
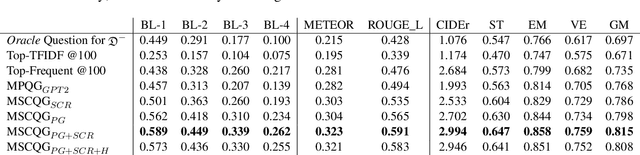
Web search engines today return a ranked list of document links in response to a user's query. However, when a user query is vague, the resultant documents span multiple subtopics. In such a scenario, it would be helpful if the search engine provided clarification options to the user's initial query in a way that each clarification option is closely related to the documents in one subtopic and is far away from the documents in all other subtopics. Motivated by this scenario, we address the task of contrastive common question generation where given a "positive" set of documents and a "negative" set of documents, we generate a question that is closely related to the "positive" set and is far away from the "negative" set. We propose Multi-Source Coordinated Question Generator (MSCQG), a novel coordinator model trained using reinforcement learning to optimize a reward based on document-question ranker score. We also develop an effective auxiliary objective, named Set-induced Contrastive Regularization (SCR) that draws the coordinator's generation behavior more closely toward "positive" documents and away from "negative" documents. We show that our model significantly outperforms strong retrieval baselines as well as a baseline model developed for a similar task, as measured by various metrics.
DialoGPT: Large-Scale Generative Pre-training for Conversational Response Generation
Nov 01, 2019
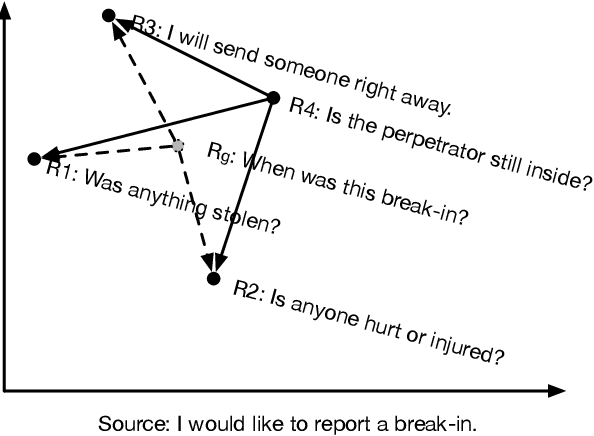
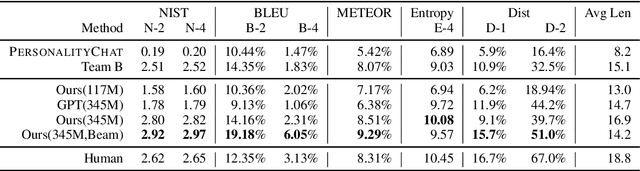

We present a large, tunable neural conversational response generation model, DialoGPT (dialogue generative pre-trained transformer). Trained on 147M conversation-like exchanges extracted from Reddit comment chains over a period spanning from 2005 through 2017, DialoGPT extends the Hugging Face PyTorch transformer to attain a performance close to human both in terms of automatic and human evaluation in single-turn dialogue settings. We show that conversational systems that leverage DialoGPT generate more relevant, contentful and context-consistent responses than strong baseline systems. The pre-trained model and training pipeline are publicly released to facilitate research into neural response generation and the development of more intelligent open-domain dialogue systems.
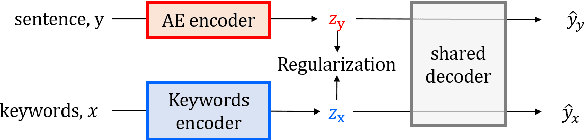
Structuring Latent Spaces for Stylized Response Generation
Sep 03, 2019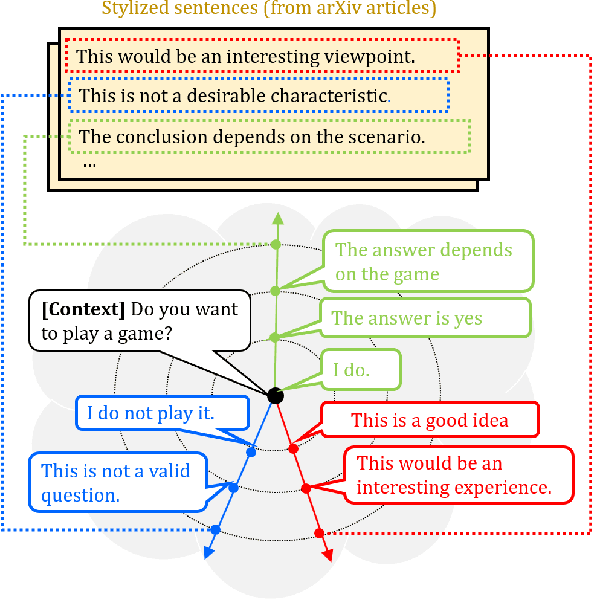
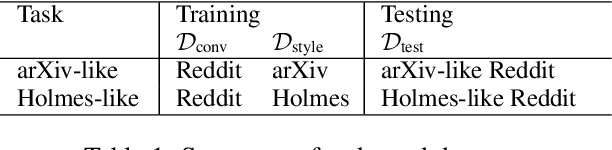
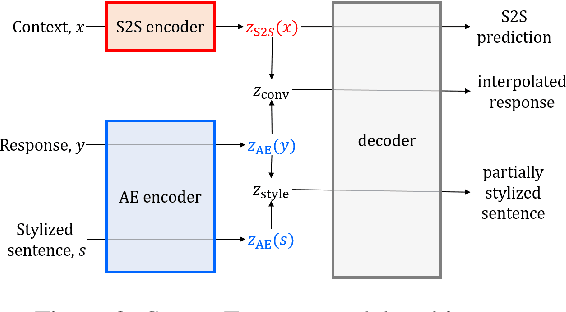

Generating responses in a targeted style is a useful yet challenging task, especially in the absence of parallel data. With limited data, existing methods tend to generate responses that are either less stylized or less context-relevant. We propose StyleFusion, which bridges conversation modeling and non-parallel style transfer by sharing a structured latent space. This structure allows the system to generate stylized relevant responses by sampling in the neighborhood of the conversation model prediction, and continuously control the style level. We demonstrate this method using dialogues from Reddit data and two sets of sentences with distinct styles (arXiv and Sherlock Holmes novels). Automatic and human evaluation show that, without sacrificing appropriateness, the system generates responses of the targeted style and outperforms competitive baselines.
* accepted to appear at EMNLP 2019 (long)