 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeConverse: A Tree-Based Modular Task-Oriented Dialogue System
Mar 30, 2022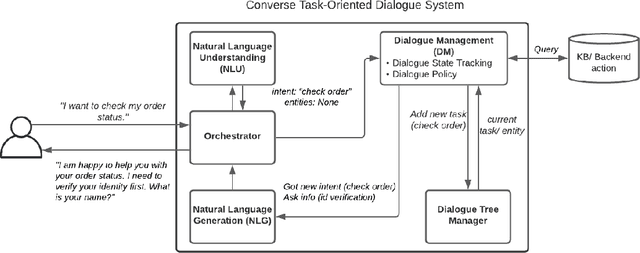

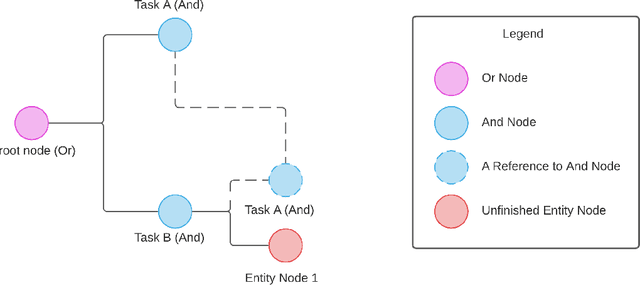
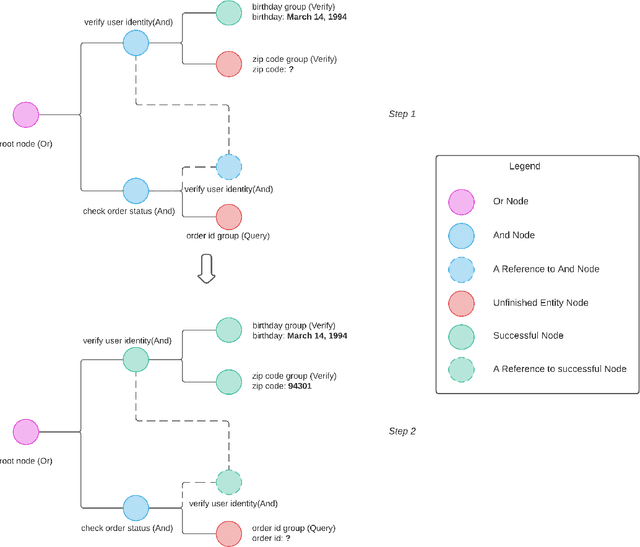
Creating a system that can have meaningful conversations with humans to help accomplish tasks is one of the ultimate goals of Artificial Intelligence (AI). It has defined the meaning of AI since the beginning. A lot has been accomplished in this area recently, with voice assistant products entering our daily lives and chat bot systems becoming commonplace in customer service. At first glance there seems to be no shortage of options for dialogue systems. However, the frequently deployed dialogue systems today seem to all struggle with a critical weakness - they are hard to build and harder to maintain. At the core of the struggle is the need to script every single turn of interactions between the bot and the human user. This makes the dialogue systems more difficult to maintain as the tasks become more complex and more tasks are added to the system. In this paper, we propose Converse, a flexible tree-based modular task-oriented dialogue system. Converse uses an and-or tree structure to represent tasks and offers powerful multi-task dialogue management. Converse supports task dependency and task switching, which are unique features compared to other open-source dialogue frameworks. At the same time, Converse aims to make the bot building process easy and simple, for both professional and non-professional software developers. The code is available at https://github.com/salesforce/Converse.
A Recipe for Creating Multimodal Aligned Datasets for Sequential Tasks
May 19, 2020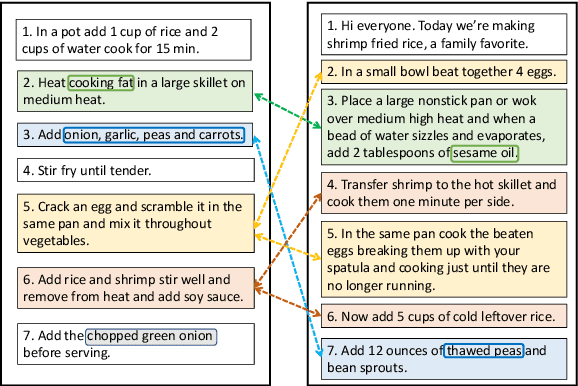
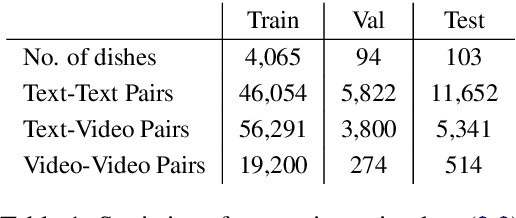
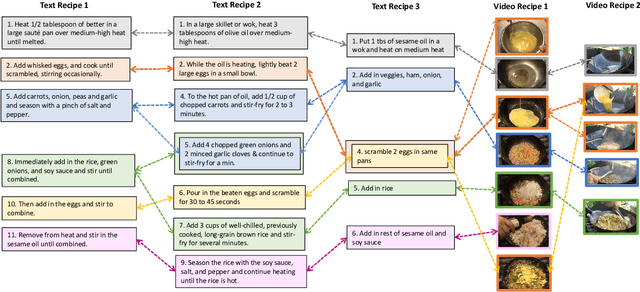
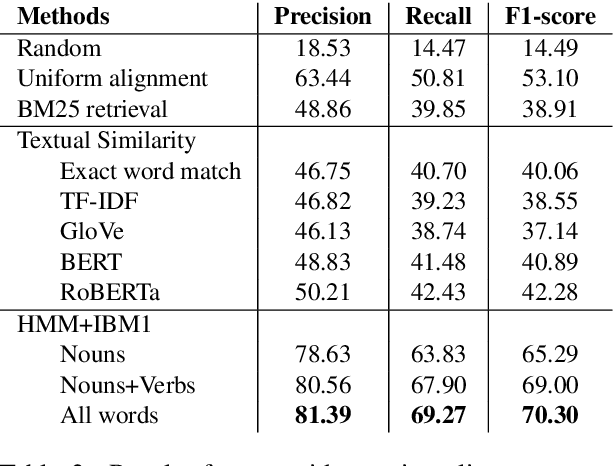
Many high-level procedural tasks can be decomposed into sequences of instructions that vary in their order and choice of tools. In the cooking domain, the web offers many partially-overlapping text and video recipes (i.e. procedures) that describe how to make the same dish (i.e. high-level task). Aligning instructions for the same dish across different sources can yield descriptive visual explanations that are far richer semantically than conventional textual instructions, providing commonsense insight into how real-world procedures are structured. Learning to align these different instruction sets is challenging because: a) different recipes vary in their order of instructions and use of ingredients; and b) video instructions can be noisy and tend to contain far more information than text instructions. To address these challenges, we first use an unsupervised alignment algorithm that learns pairwise alignments between instructions of different recipes for the same dish. We then use a graph algorithm to derive a joint alignment between multiple text and multiple video recipes for the same dish. We release the Microsoft Research Multimodal Aligned Recipe Corpus containing 150K pairwise alignments between recipes across 4,262 dishes with rich commonsense information.
* This paper has been accepted to be published at ACL 2020
Real-Time User-Guided Image Colorization with Learned Deep Priors
May 08, 2017
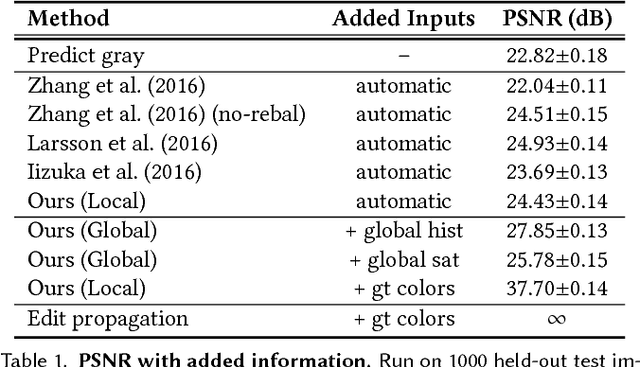
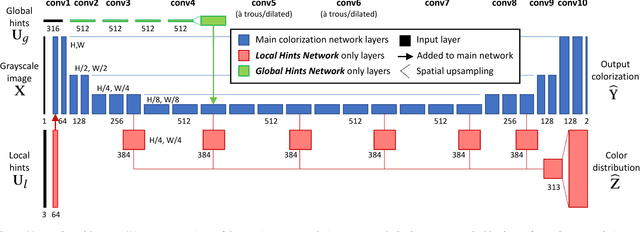

We propose a deep learning approach for user-guided image colorization. The system directly maps a grayscale image, along with sparse, local user "hints" to an output colorization with a Convolutional Neural Network (CNN). Rather than using hand-defined rules, the network propagates user edits by fusing low-level cues along with high-level semantic information, learned from large-scale data. We train on a million images, with simulated user inputs. To guide the user towards efficient input selection, the system recommends likely colors based on the input image and current user inputs. The colorization is performed in a single feed-forward pass, enabling real-time use. Even with randomly simulated user inputs, we show that the proposed system helps novice users quickly create realistic colorizations, and offers large improvements in colorization quality with just a minute of use. In addition, we demonstrate that the framework can incorporate other user "hints" to the desired colorization, showing an application to color histogram transfer. Our code and models are available at https://richzhang.github.io/ideepcolor.