 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUnsupervised Common Question Generation from Multiple Documents using Reinforced Contrastive Coordinator
Nov 08, 2019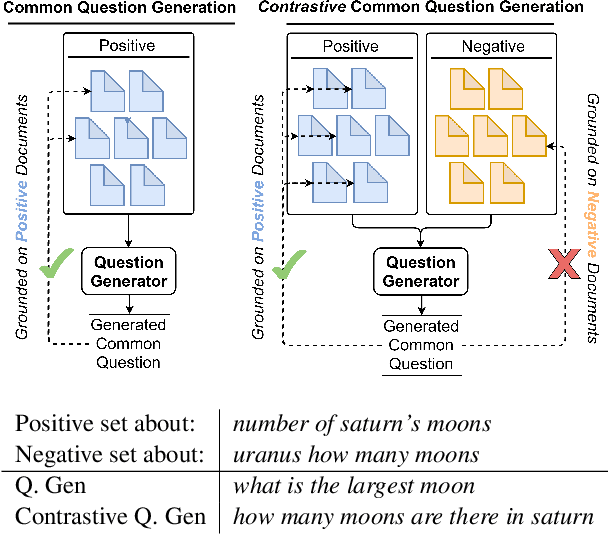
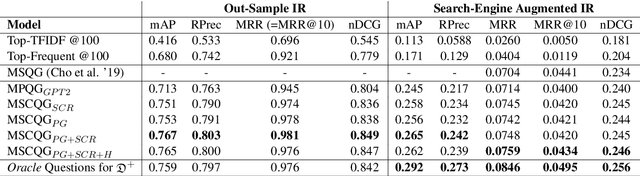
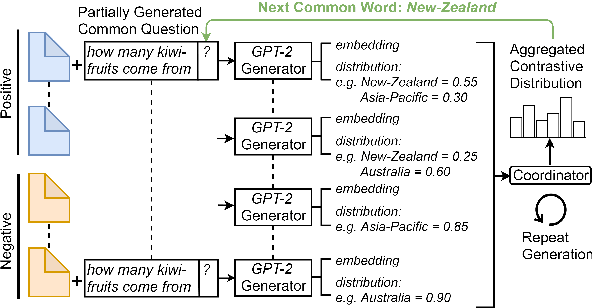
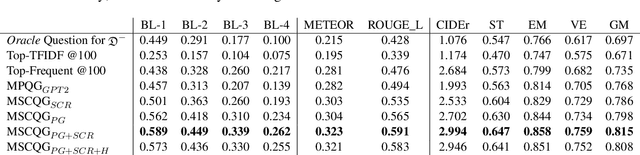
Web search engines today return a ranked list of document links in response to a user's query. However, when a user query is vague, the resultant documents span multiple subtopics. In such a scenario, it would be helpful if the search engine provided clarification options to the user's initial query in a way that each clarification option is closely related to the documents in one subtopic and is far away from the documents in all other subtopics. Motivated by this scenario, we address the task of contrastive common question generation where given a "positive" set of documents and a "negative" set of documents, we generate a question that is closely related to the "positive" set and is far away from the "negative" set. We propose Multi-Source Coordinated Question Generator (MSCQG), a novel coordinator model trained using reinforcement learning to optimize a reward based on document-question ranker score. We also develop an effective auxiliary objective, named Set-induced Contrastive Regularization (SCR) that draws the coordinator's generation behavior more closely toward "positive" documents and away from "negative" documents. We show that our model significantly outperforms strong retrieval baselines as well as a baseline model developed for a similar task, as measured by various metrics.
Generating a Common Question from Multiple Documents using Multi-source Encoder-Decoder Models
Oct 25, 2019
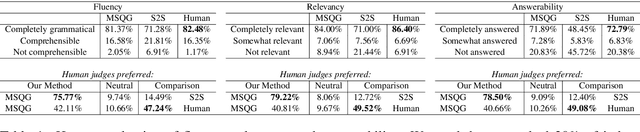
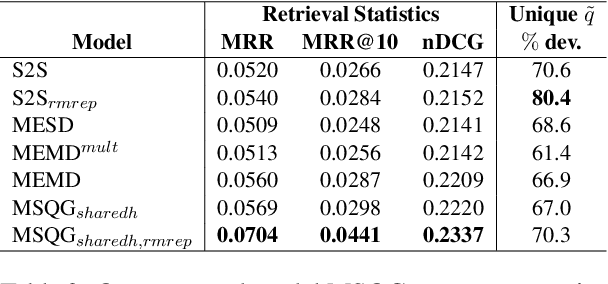
Ambiguous user queries in search engines result in the retrieval of documents that often span multiple topics. One potential solution is for the search engine to generate multiple refined queries, each of which relates to a subset of the documents spanning the same topic. A preliminary step towards this goal is to generate a question that captures common concepts of multiple documents. We propose a new task of generating common question from multiple documents and present simple variant of an existing multi-source encoder-decoder framework, called the Multi-Source Question Generator (MSQG). We first train an RNN-based single encoder-decoder generator from (single document, question) pairs. At test time, given multiple documents, the 'Distribute' step of our MSQG model predicts target word distributions for each document using the trained model. The 'Aggregate' step aggregates these distributions to generate a common question. This simple yet effective strategy significantly outperforms several existing baseline models applied to the new task when evaluated using automated metrics and human judgments on the MS-MARCO-QA dataset.
A bird's-eye view on coherence, and a worm's-eye view on cohesion
Nov 01, 2018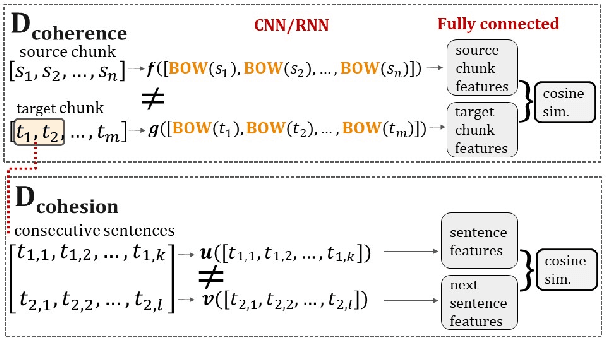
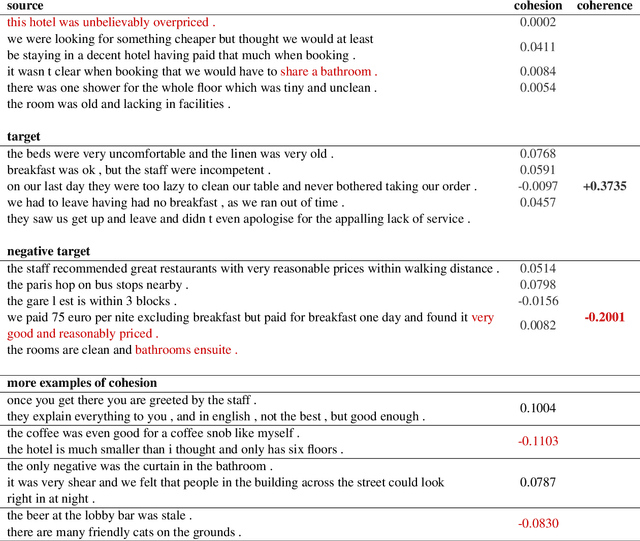


Generating coherent and cohesive long-form texts is a challenging problem in natural language generation. Previous works relied on a large amount of human-generated texts to train language models, however, few attempted to explicitly model the desired linguistic properties of natural language text, such as coherence and cohesion. In this work, we train two expert discriminators for coherence and cohesion, respectively, to provide hierarchical feedback for text generation. We also propose a simple variant of policy gradient, called 'negative-critical sequence training', using margin rewards, in which the 'baseline' is constructed from randomly generated negative samples. We demonstrate the effectiveness of our approach through empirical studies, showing significant improvements over the strong baseline -- attention-based bidirectional MLE-trained neural language model -- in a number of automated metrics. The proposed discriminators can serve as baseline architectures to promote further research to better extract, encode essential linguistic qualities, such as coherence and cohesion.
Deep Primal-Dual Reinforcement Learning: Accelerating Actor-Critic using Bellman Duality
Dec 07, 2017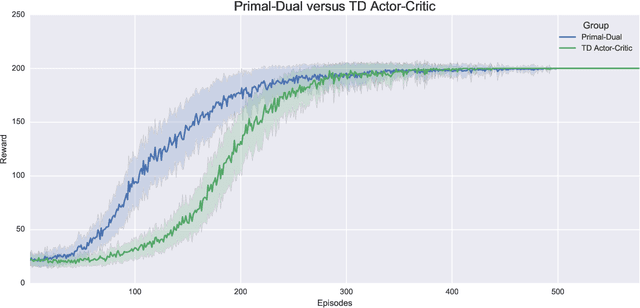
We develop a parameterized Primal-Dual $\pi$ Learning method based on deep neural networks for Markov decision process with large state space and off-policy reinforcement learning. In contrast to the popular Q-learning and actor-critic methods that are based on successive approximations to the nonlinear Bellman equation, our method makes primal-dual updates to the policy and value functions utilizing the fundamental linear Bellman duality. Naive parametrization of the primal-dual $\pi$ learning method using deep neural networks would encounter two major challenges: (1) each update requires computing a probability distribution over the state space and is intractable; (2) the iterates are unstable since the parameterized Lagrangian function is no longer linear. We address these challenges by proposing a relaxed Lagrangian formulation with a regularization penalty using the advantage function. We show that the dual policy update step in our method is equivalent to the policy gradient update in the actor-critic method in some special case, while the value updates differ substantially. The main advantage of the primal-dual $\pi$ learning method lies in that the value and policy updates are closely coupled together using the Bellman duality and therefore more informative. Experiments on a simple cart-pole problem show that the algorithm significantly outperforms the one-step temporal-difference actor-critic method, which is the most relevant benchmark method to compare with. We believe that the primal-dual updates to the value and policy functions would expedite the learning process. The proposed methods might open a door to more efficient algorithms and sharper theoretical analysis.