 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAcme: A Research Framework for Distributed Reinforcement Learning
Jun 01, 2020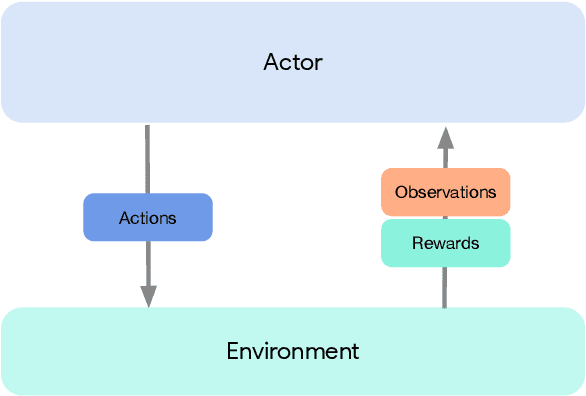
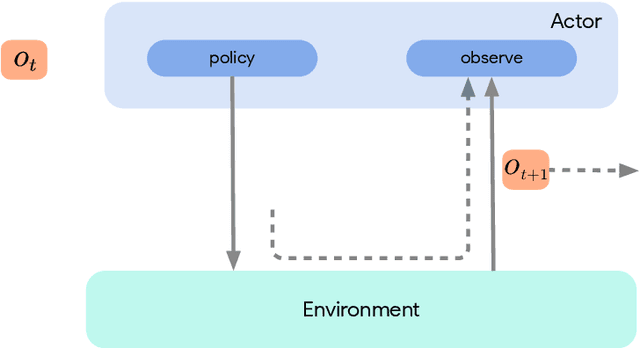
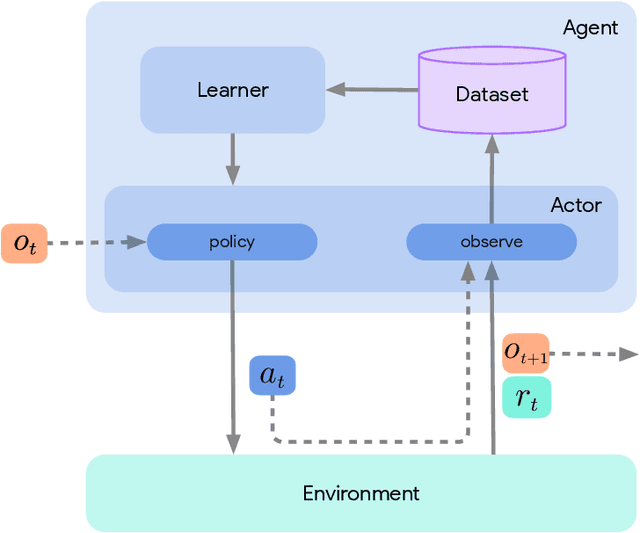
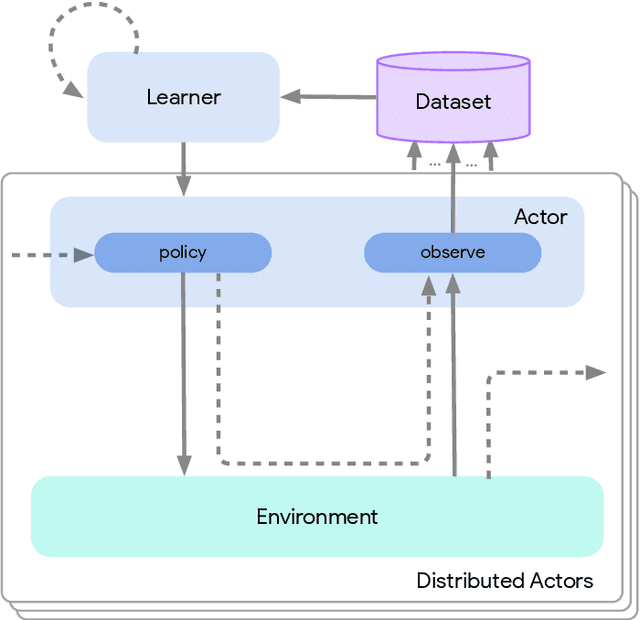
Deep reinforcement learning has led to many recent-and groundbreaking-advancements. However, these advances have often come at the cost of both the scale and complexity of the underlying RL algorithms. Increases in complexity have in turn made it more difficult for researchers to reproduce published RL algorithms or rapidly prototype ideas. To address this, we introduce Acme, a tool to simplify the development of novel RL algorithms that is specifically designed to enable simple agent implementations that can be run at various scales of execution. Our aim is also to make the results of various RL algorithms developed in academia and industrial labs easier to reproduce and extend. To this end we are releasing baseline implementations of various algorithms, created using our framework. In this work we introduce the major design decisions behind Acme and show how these are used to construct these baselines. We also experiment with these agents at different scales of both complexity and computation-including distributed versions. Ultimately, we show that the design decisions behind Acme lead to agents that can be scaled both up and down and that, for the most part, greater levels of parallelization result in agents with equivalent performance, just faster.
Bootstrap Latent-Predictive Representations for Multitask Reinforcement Learning
Apr 30, 2020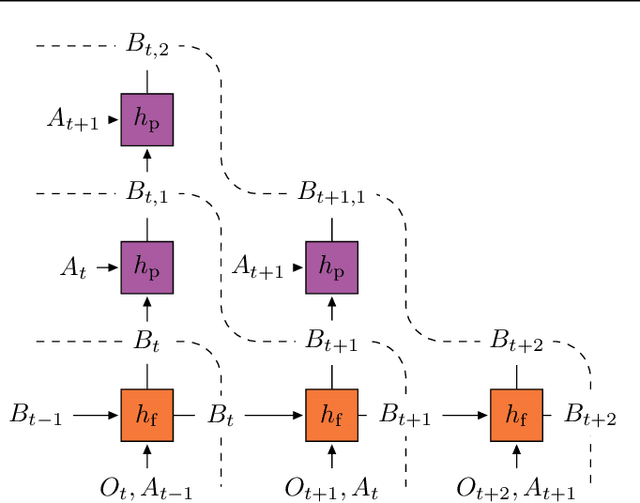
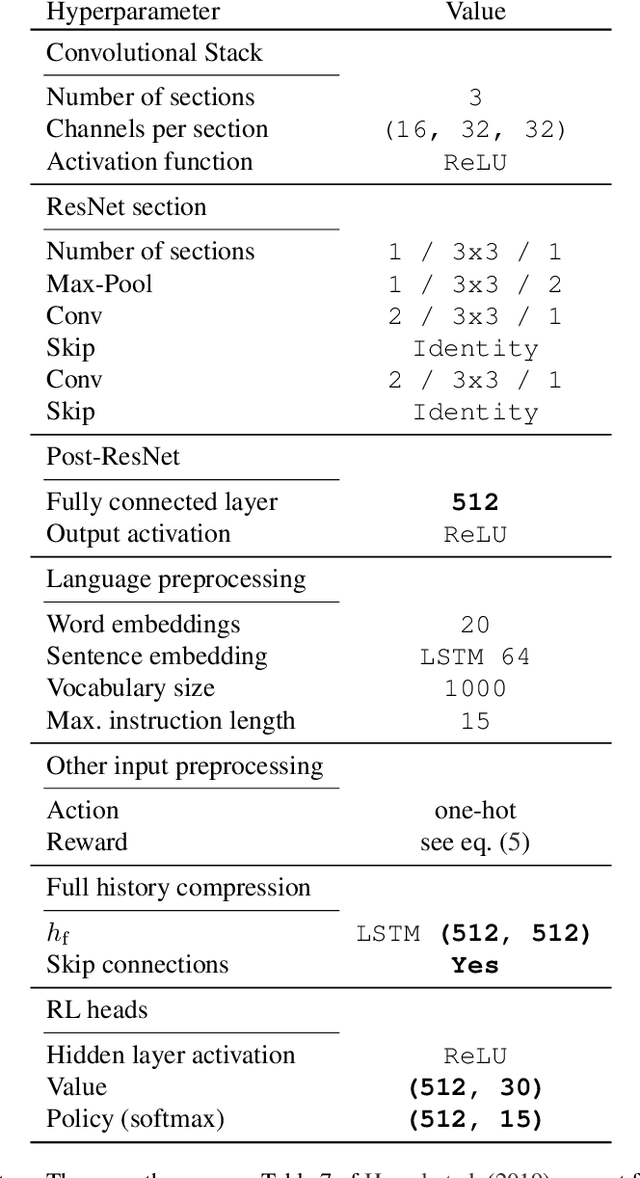
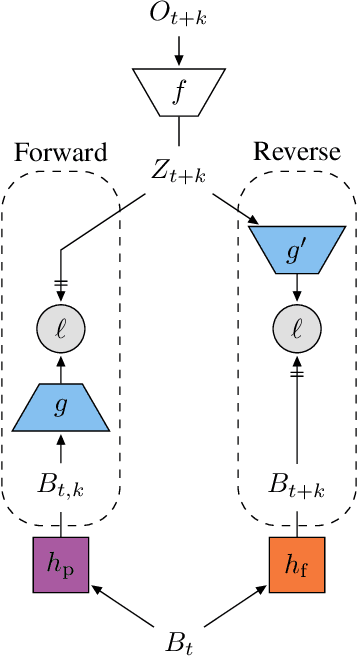

Learning a good representation is an essential component for deep reinforcement learning (RL). Representation learning is especially important in multitask and partially observable settings where building a representation of the unknown environment is crucial to solve the tasks. Here we introduce Prediction of Bootstrap Latents (PBL), a simple and flexible self-supervised representation learning algorithm for multitask deep RL. PBL builds on multistep predictive representations of future observations, and focuses on capturing structured information about environment dynamics. Specifically, PBL trains its representation by predicting latent embeddings of future observations. These latent embeddings are themselves trained to be predictive of the aforementioned representations. These predictions form a bootstrapping effect, allowing the agent to learn more about the key aspects of the environment dynamics. In addition, by defining prediction tasks completely in latent space, PBL provides the flexibility of using multimodal observations involving pixel images, language instructions, rewards and more. We show in our experiments that PBL delivers across-the-board improved performance over state of the art deep RL agents in the DMLab-30 and Atari-57 multitask setting.
Agent57: Outperforming the Atari Human Benchmark
Mar 30, 2020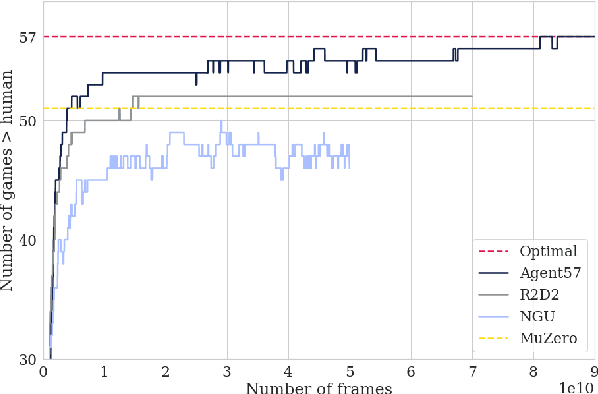
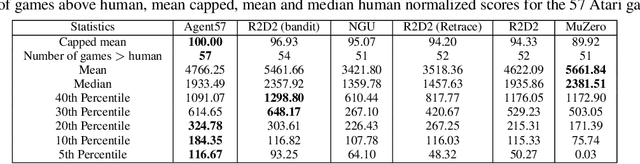

Atari games have been a long-standing benchmark in the reinforcement learning (RL) community for the past decade. This benchmark was proposed to test general competency of RL algorithms. Previous work has achieved good average performance by doing outstandingly well on many games of the set, but very poorly in several of the most challenging games. We propose Agent57, the first deep RL agent that outperforms the standard human benchmark on all 57 Atari games. To achieve this result, we train a neural network which parameterizes a family of policies ranging from very exploratory to purely exploitative. We propose an adaptive mechanism to choose which policy to prioritize throughout the training process. Additionally, we utilize a novel parameterization of the architecture that allows for more consistent and stable learning.
Never Give Up: Learning Directed Exploration Strategies
Feb 14, 2020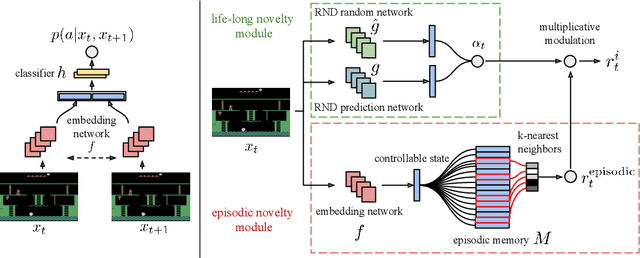
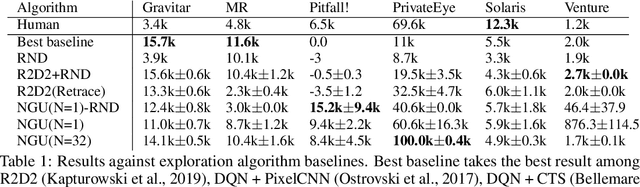
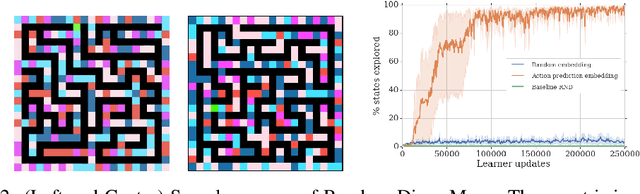
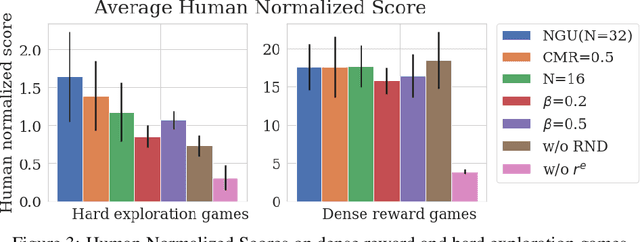
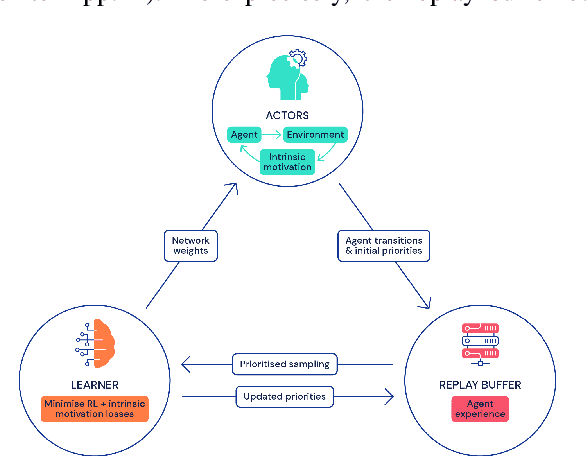
We propose a reinforcement learning agent to solve hard exploration games by learning a range of directed exploratory policies. We construct an episodic memory-based intrinsic reward using k-nearest neighbors over the agent's recent experience to train the directed exploratory policies, thereby encouraging the agent to repeatedly revisit all states in its environment. A self-supervised inverse dynamics model is used to train the embeddings of the nearest neighbour lookup, biasing the novelty signal towards what the agent can control. We employ the framework of Universal Value Function Approximators (UVFA) to simultaneously learn many directed exploration policies with the same neural network, with different trade-offs between exploration and exploitation. By using the same neural network for different degrees of exploration/exploitation, transfer is demonstrated from predominantly exploratory policies yielding effective exploitative policies. The proposed method can be incorporated to run with modern distributed RL agents that collect large amounts of experience from many actors running in parallel on separate environment instances. Our method doubles the performance of the base agent in all hard exploration in the Atari-57 suite while maintaining a very high score across the remaining games, obtaining a median human normalised score of 1344.0%. Notably, the proposed method is the first algorithm to achieve non-zero rewards (with a mean score of 8,400) in the game of Pitfall! without using demonstrations or hand-crafted features.
Hindsight Credit Assignment
Dec 05, 2019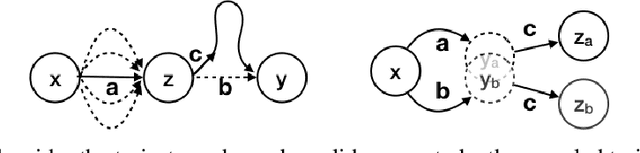

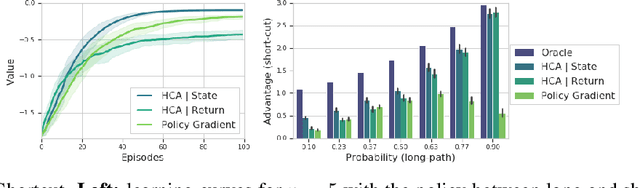
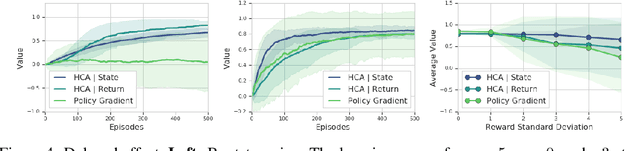
We consider the problem of efficient credit assignment in reinforcement learning. In order to efficiently and meaningfully utilize new data, we propose to explicitly assign credit to past decisions based on the likelihood of them having led to the observed outcome. This approach uses new information in hindsight, rather than employing foresight. Somewhat surprisingly, we show that value functions can be rewritten through this lens, yielding a new family of algorithms. We study the properties of these algorithms, and empirically show that they successfully address important credit assignment challenges, through a set of illustrative tasks.
World Discovery Models
Mar 01, 2019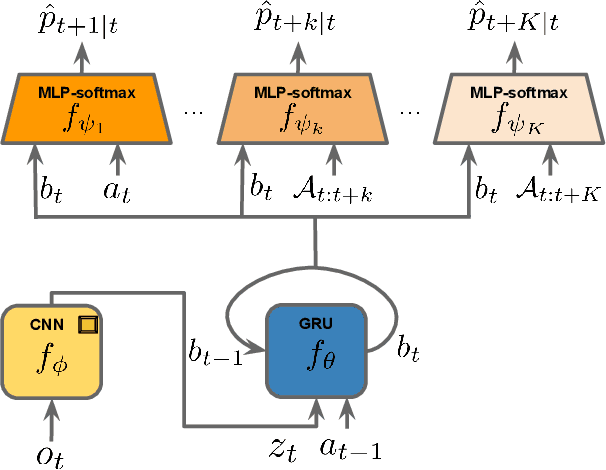
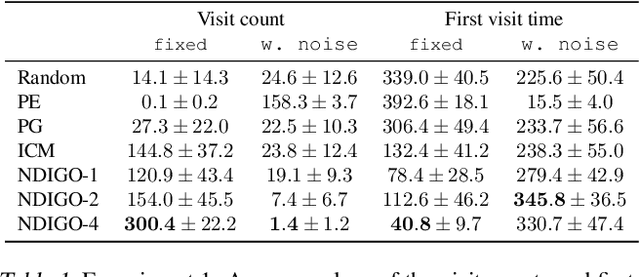

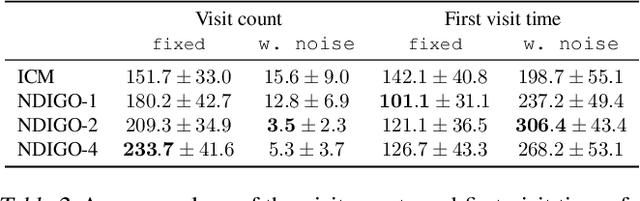
As humans we are driven by a strong desire for seeking novelty in our world. Also upon observing a novel pattern we are capable of refining our understanding of the world based on the new information---humans can discover their world. The outstanding ability of the human mind for discovery has led to many breakthroughs in science, art and technology. Here we investigate the possibility of building an agent capable of discovering its world using the modern AI technology. In particular we introduce NDIGO, Neural Differential Information Gain Optimisation, a self-supervised discovery model that aims at seeking new information to construct a global view of its world from partial and noisy observations. Our experiments on some controlled 2-D navigation tasks show that NDIGO outperforms state-of-the-art information-seeking methods in terms of the quality of the learned representation. The improvement in performance is particularly significant in the presence of white or structured noise where other information-seeking methods follow the noise instead of discovering their world.
Neural Predictive Belief Representations
Nov 15, 2018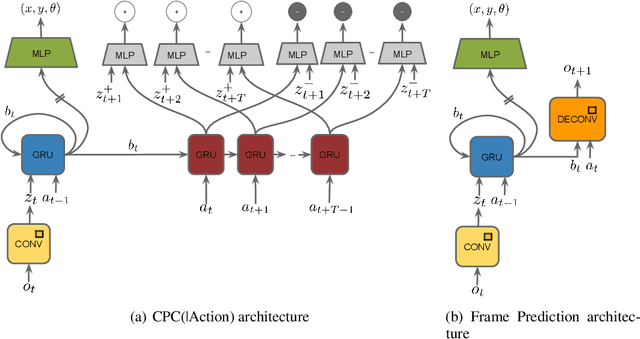
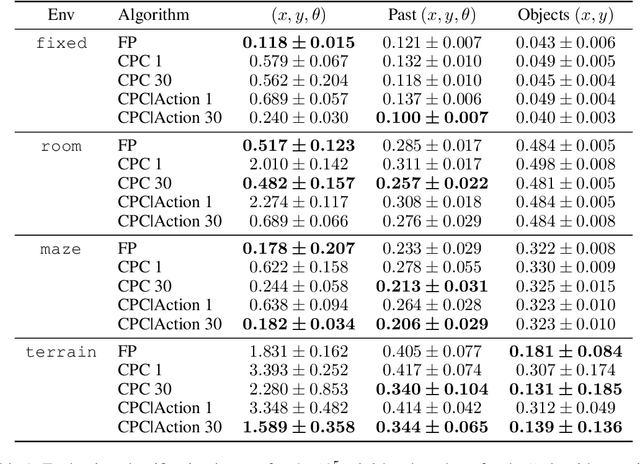
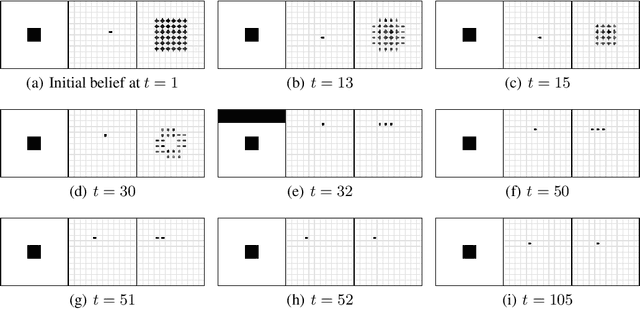
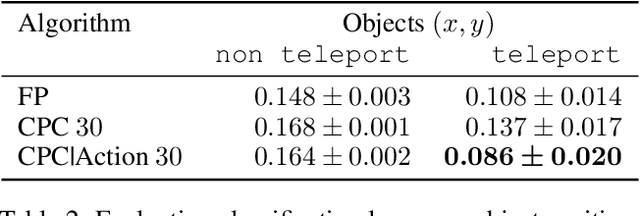
Unsupervised representation learning has succeeded with excellent results in many applications. It is an especially powerful tool to learn a good representation of environments with partial or noisy observations. In partially observable domains it is important for the representation to encode a belief state, a sufficient statistic of the observations seen so far. In this paper, we investigate whether it is possible to learn such a belief representation using modern neural architectures. Specifically, we focus on one-step frame prediction and two variants of contrastive predictive coding (CPC) as the objective functions to learn the representations. To evaluate these learned representations, we test how well they can predict various pieces of information about the underlying state of the environment, e.g., position of the agent in a 3D maze. We show that all three methods are able to learn belief representations of the environment, they encode not only the state information, but also its uncertainty, a crucial aspect of belief states. We also find that for CPC multi-step predictions and action-conditioning are critical for accurate belief representations in visually complex environments. The ability of neural representations to capture the belief information has the potential to spur new advances for learning and planning in partially observable domains, where leveraging uncertainty is essential for optimal decision making.
Leveraging Demonstrations for Deep Reinforcement Learning on Robotics Problems with Sparse Rewards
Oct 08, 2018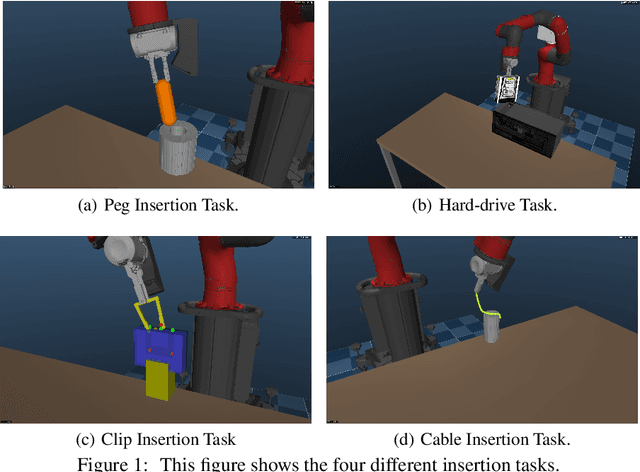

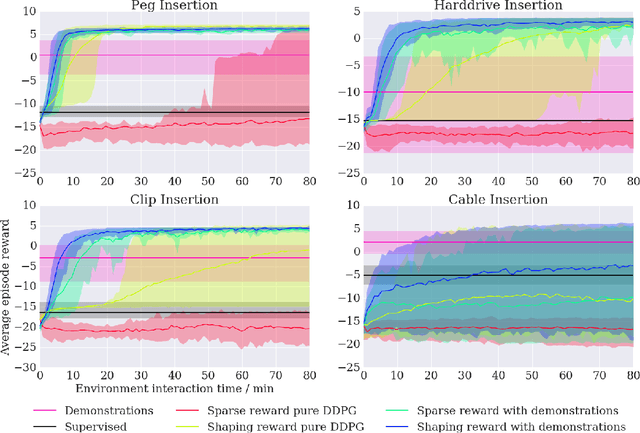
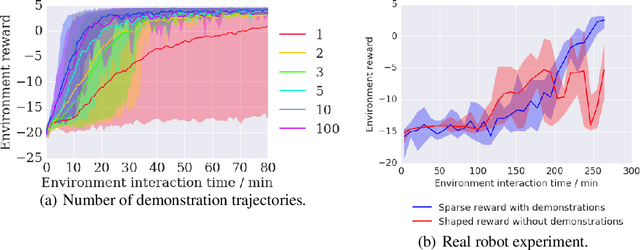
We propose a general and model-free approach for Reinforcement Learning (RL) on real robotics with sparse rewards. We build upon the Deep Deterministic Policy Gradient (DDPG) algorithm to use demonstrations. Both demonstrations and actual interactions are used to fill a replay buffer and the sampling ratio between demonstrations and transitions is automatically tuned via a prioritized replay mechanism. Typically, carefully engineered shaping rewards are required to enable the agents to efficiently explore on high dimensional control problems such as robotics. They are also required for model-based acceleration methods relying on local solvers such as iLQG (e.g. Guided Policy Search and Normalized Advantage Function). The demonstrations replace the need for carefully engineered rewards, and reduce the exploration problem encountered by classical RL approaches in these domains. Demonstrations are collected by a robot kinesthetically force-controlled by a human demonstrator. Results on four simulated insertion tasks show that DDPG from demonstrations out-performs DDPG, and does not require engineered rewards. Finally, we demonstrate the method on a real robotics task consisting of inserting a clip (flexible object) into a rigid object.
Playing the Game of Universal Adversarial Perturbations
Sep 25, 2018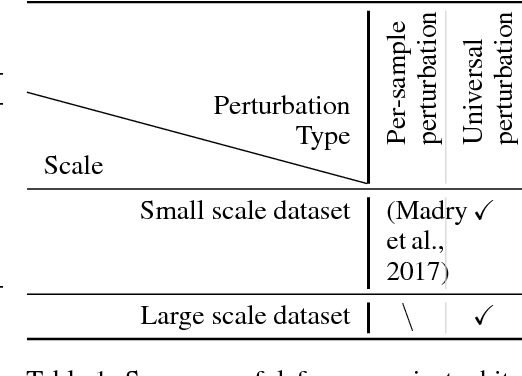

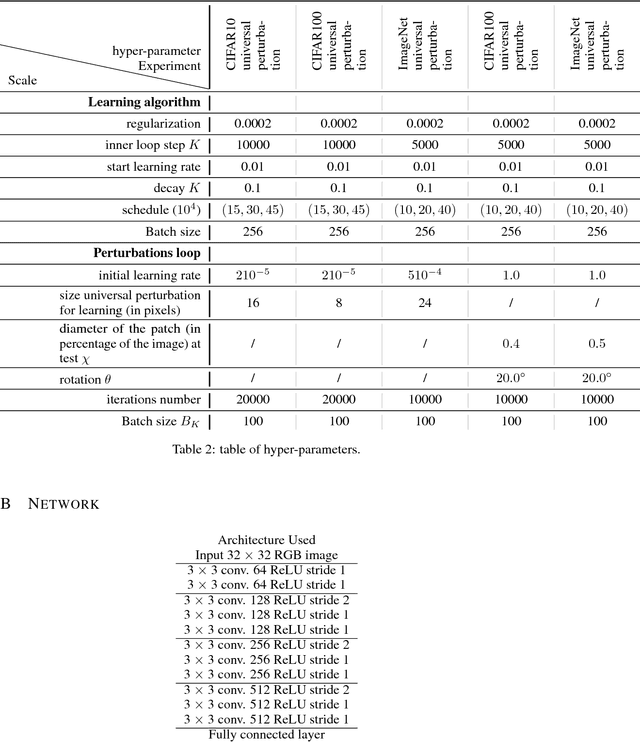
We study the problem of learning classifiers robust to universal adversarial perturbations. While prior work approaches this problem via robust optimization, adversarial training, or input transformation, we instead phrase it as a two-player zero-sum game. In this new formulation, both players simultaneously play the same game, where one player chooses a classifier that minimizes a classification loss whilst the other player creates an adversarial perturbation that increases the same loss when applied to every sample in the training set. By observing that performing a classification (respectively creating adversarial samples) is the best response to the other player, we propose a novel extension of a game-theoretic algorithm, namely fictitious play, to the domain of training robust classifiers. Finally, we empirically show the robustness and versatility of our approach in two defence scenarios where universal attacks are performed on several image classification datasets -- CIFAR10, CIFAR100 and ImageNet.
The Reactor: A fast and sample-efficient Actor-Critic agent for Reinforcement Learning
Jun 19, 2018



In this work we present a new agent architecture, called Reactor, which combines multiple algorithmic and architectural contributions to produce an agent with higher sample-efficiency than Prioritized Dueling DQN (Wang et al., 2016) and Categorical DQN (Bellemare et al., 2017), while giving better run-time performance than A3C (Mnih et al., 2016). Our first contribution is a new policy evaluation algorithm called Distributional Retrace, which brings multi-step off-policy updates to the distributional reinforcement learning setting. The same approach can be used to convert several classes of multi-step policy evaluation algorithms designed for expected value evaluation into distributional ones. Next, we introduce the \b{eta}-leave-one-out policy gradient algorithm which improves the trade-off between variance and bias by using action values as a baseline. Our final algorithmic contribution is a new prioritized replay algorithm for sequences, which exploits the temporal locality of neighboring observations for more efficient replay prioritization. Using the Atari 2600 benchmarks, we show that each of these innovations contribute to both the sample efficiency and final agent performance. Finally, we demonstrate that Reactor reaches state-of-the-art performance after 200 million frames and less than a day of training.