 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBiao Wang
Motion and Appearance Adaptation for Cross-Domain Motion Transfer
Sep 29, 2022
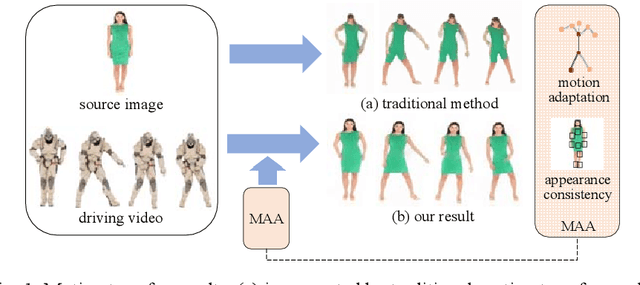
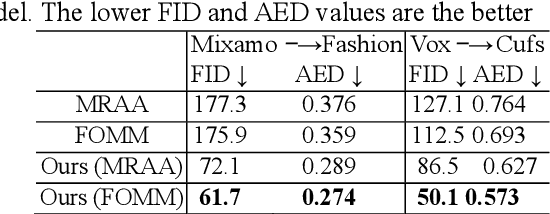
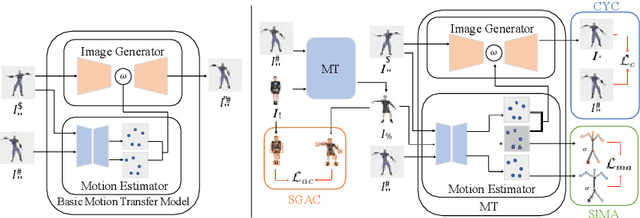
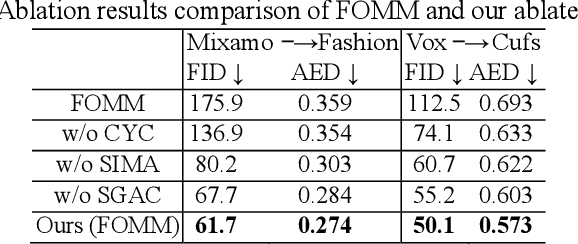
Motion transfer aims to transfer the motion of a driving video to a source image. When there are considerable differences between object in the driving video and that in the source image, traditional single domain motion transfer approaches often produce notable artifacts; for example, the synthesized image may fail to preserve the human shape of the source image (cf . Fig. 1 (a)). To address this issue, in this work, we propose a Motion and Appearance Adaptation (MAA) approach for cross-domain motion transfer, in which we regularize the object in the synthesized image to capture the motion of the object in the driving frame, while still preserving the shape and appearance of the object in the source image. On one hand, considering the object shapes of the synthesized image and the driving frame might be different, we design a shape-invariant motion adaptation module that enforces the consistency of the angles of object parts in two images to capture the motion information. On the other hand, we introduce a structure-guided appearance consistency module designed to regularize the similarity between the corresponding patches of the synthesized image and the source image without affecting the learned motion in the synthesized image. Our proposed MAA model can be trained in an end-to-end manner with a cyclic reconstruction loss, and ultimately produces a satisfactory motion transfer result (cf . Fig. 1 (b)). We conduct extensive experiments on human dancing dataset Mixamo-Video to Fashion-Video and human face dataset Vox-Celeb to Cufs; on both of these, our MAA model outperforms existing methods both quantitatively and qualitatively.
Motion Transformer for Unsupervised Image Animation
Sep 28, 2022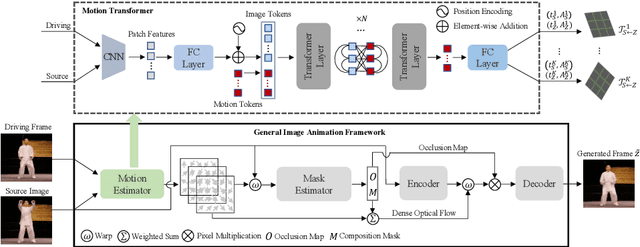
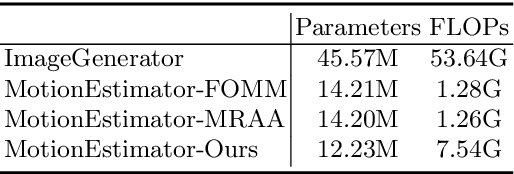


Image animation aims to animate a source image by using motion learned from a driving video. Current state-of-the-art methods typically use convolutional neural networks (CNNs) to predict motion information, such as motion keypoints and corresponding local transformations. However, these CNN based methods do not explicitly model the interactions between motions; as a result, the important underlying motion relationship may be neglected, which can potentially lead to noticeable artifacts being produced in the generated animation video. To this end, we propose a new method, the motion transformer, which is the first attempt to build a motion estimator based on a vision transformer. More specifically, we introduce two types of tokens in our proposed method: i) image tokens formed from patch features and corresponding position encoding; and ii) motion tokens encoded with motion information. Both types of tokens are sent into vision transformers to promote underlying interactions between them through multi-head self attention blocks. By adopting this process, the motion information can be better learned to boost the model performance. The final embedded motion tokens are then used to predict the corresponding motion keypoints and local transformations. Extensive experiments on benchmark datasets show that our proposed method achieves promising results to the state-of-the-art baselines. Our source code will be public available.
Spatio-Temporal Relation Learning for Video Anomaly Detection
Sep 27, 2022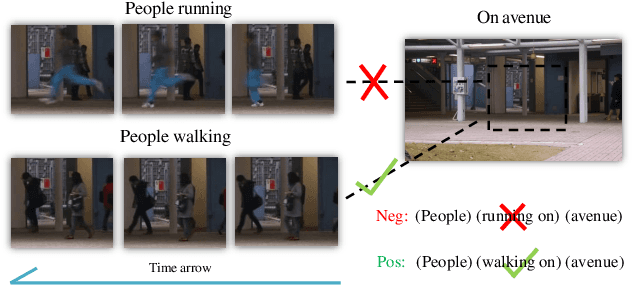
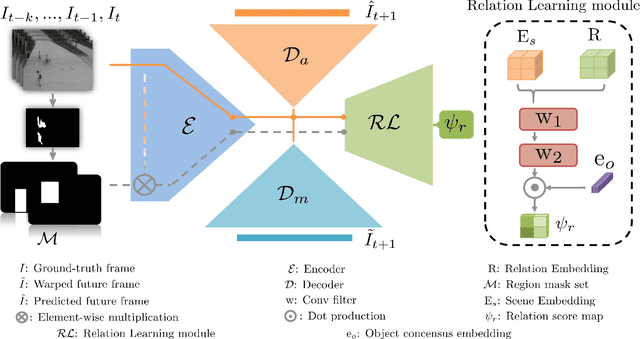
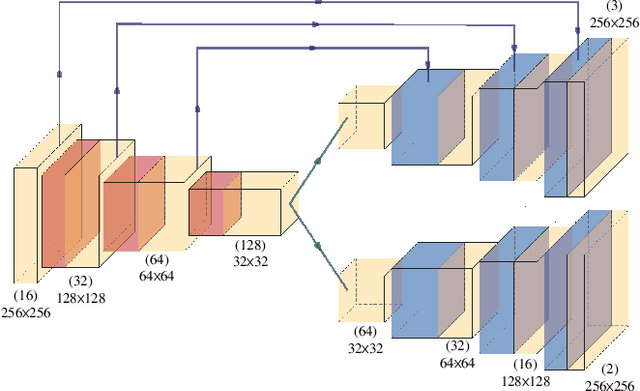
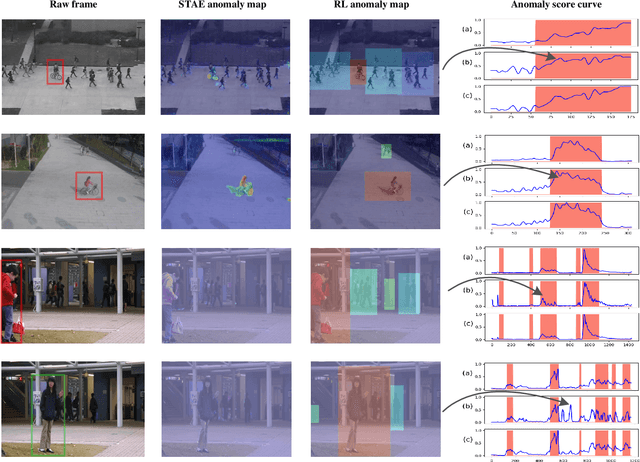
Anomaly identification is highly dependent on the relationship between the object and the scene, as different/same object actions in same/different scenes may lead to various degrees of normality and anomaly. Therefore, object-scene relation actually plays a crucial role in anomaly detection but is inadequately explored in previous works. In this paper, we propose a Spatial-Temporal Relation Learning (STRL) framework to tackle the video anomaly detection task. First, considering dynamic characteristics of the objects as well as scene areas, we construct a Spatio-Temporal Auto-Encoder (STAE) to jointly exploit spatial and temporal evolution patterns for representation learning. For better pattern extraction, two decoding branches are designed in the STAE module, i.e. an appearance branch capturing spatial cues by directly predicting the next frame, and a motion branch focusing on modeling the dynamics via optical flow prediction. Then, to well concretize the object-scene relation, a Relation Learning (RL) module is devised to analyze and summarize the normal relations by introducing the Knowledge Graph Embedding methodology. Specifically in this process, the plausibility of object-scene relation is measured by jointly modeling object/scene features and optimizable object-scene relation maps. Extensive experiments are conducted on three public datasets, and the superior performance over the state-of-the-art methods demonstrates the effectiveness of our method.
Language Supervised Training for Skeleton-based Action Recognition
Aug 10, 2022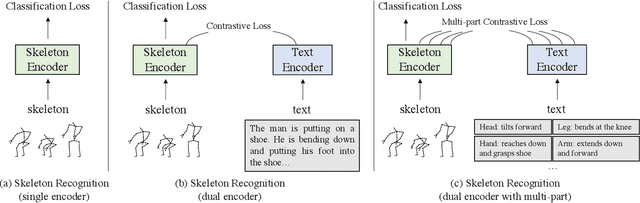
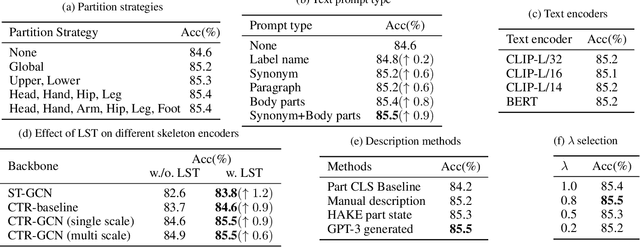
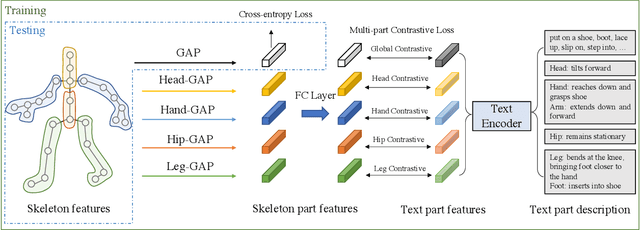
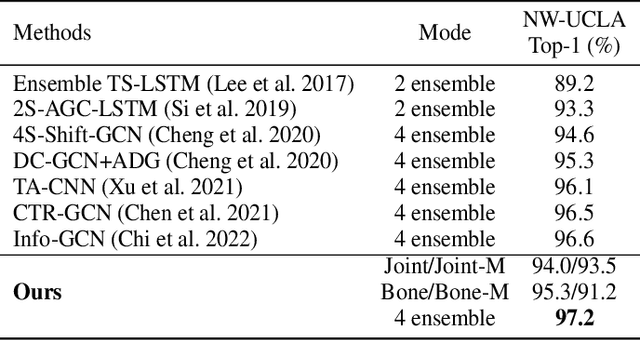
Skeleton-based action recognition has drawn a lot of attention for its computation efficiency and robustness to lighting conditions. Existing skeleton-based action recognition methods are typically formulated as a one-hot classification task without fully utilizing the semantic relations between actions. For example, "make victory sign" and "thumb up" are two actions of hand gestures, whose major difference lies in the movement of hands. This information is agnostic from the categorical one-hot encoding of action classes but could be unveiled in the language description of actions. Therefore, utilizing action language descriptions in training could potentially benefit representation learning. In this work, we propose a Language Supervised Training (LST) approach for skeleton-based action recognition. More specifically, we employ a large-scale language model as the knowledge engine to provide text descriptions for body parts movements of actions, and propose a multi-modal training scheme by utilizing the text encoder to generate feature vectors for different body parts and supervise the skeleton encoder for action representation learning. Experiments show that our proposed LST method achieves noticeable improvements over various baseline models without extra computation cost at inference. LST achieves new state-of-the-arts on popular skeleton-based action recognition benchmarks, including NTU RGB+D, NTU RGB+D 120 and NW-UCLA. The code can be found at https://github.com/MartinXM/LST.
Spatiotemporal Self-attention Modeling with Temporal Patch Shift for Action Recognition
Jul 27, 2022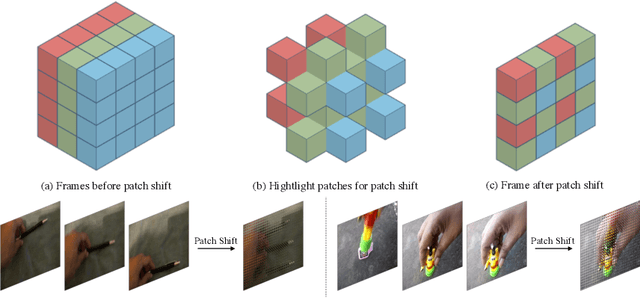
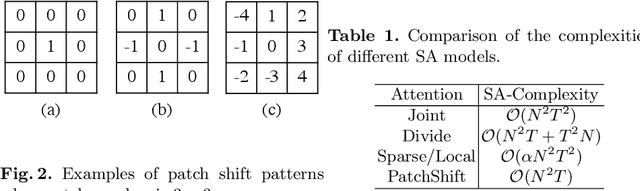
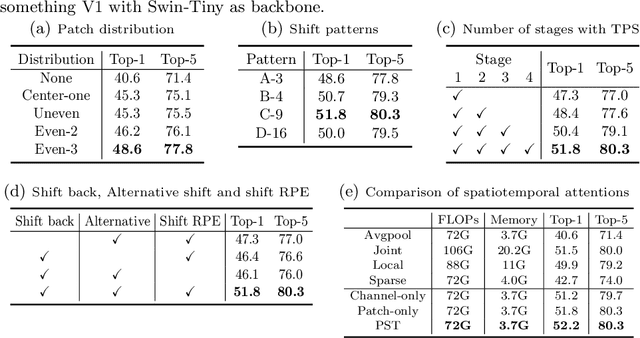

Transformer-based methods have recently achieved great advancement on 2D image-based vision tasks. For 3D video-based tasks such as action recognition, however, directly applying spatiotemporal transformers on video data will bring heavy computation and memory burdens due to the largely increased number of patches and the quadratic complexity of self-attention computation. How to efficiently and effectively model the 3D self-attention of video data has been a great challenge for transformers. In this paper, we propose a Temporal Patch Shift (TPS) method for efficient 3D self-attention modeling in transformers for video-based action recognition. TPS shifts part of patches with a specific mosaic pattern in the temporal dimension, thus converting a vanilla spatial self-attention operation to a spatiotemporal one with little additional cost. As a result, we can compute 3D self-attention using nearly the same computation and memory cost as 2D self-attention. TPS is a plug-and-play module and can be inserted into existing 2D transformer models to enhance spatiotemporal feature learning. The proposed method achieves competitive performance with state-of-the-arts on Something-something V1 & V2, Diving-48, and Kinetics400 while being much more efficient on computation and memory cost. The source code of TPS can be found at https://github.com/MartinXM/TPS.
SP-ViT: Learning 2D Spatial Priors for Vision Transformers
Jun 15, 2022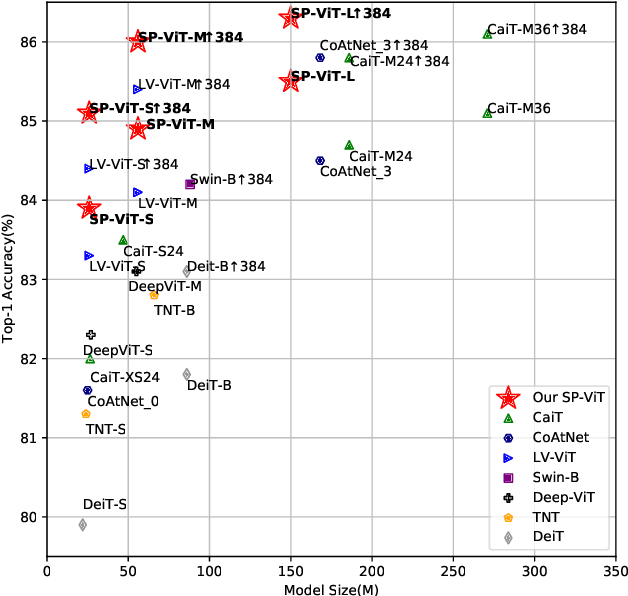
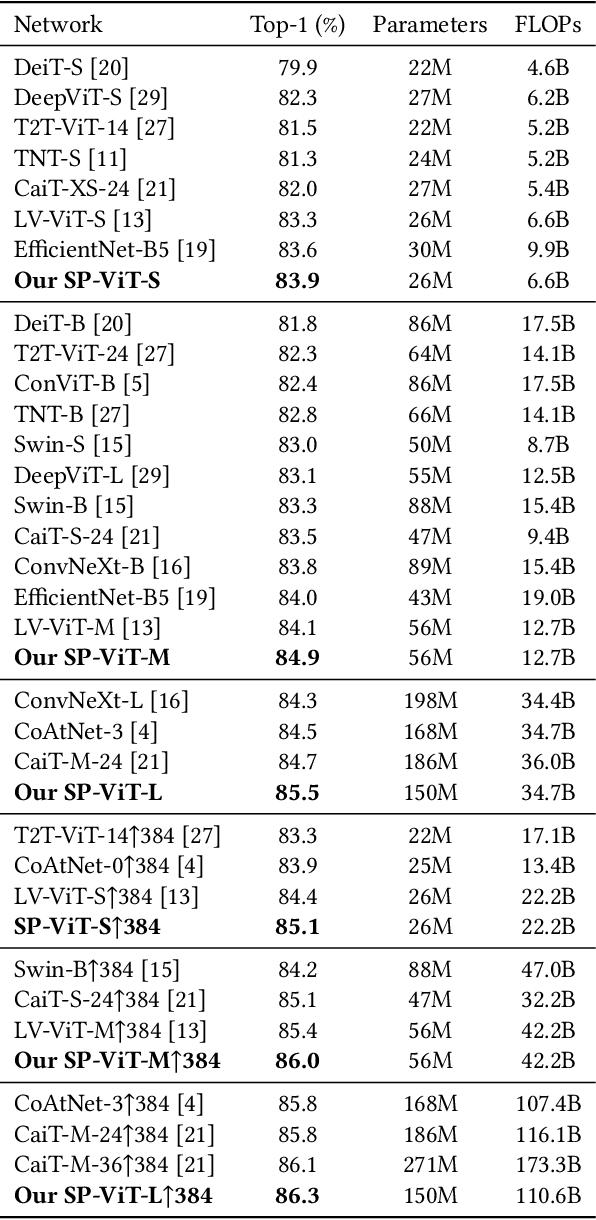
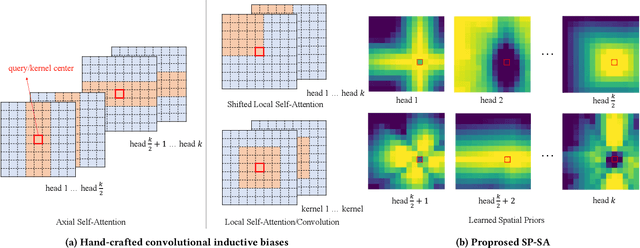

Recently, transformers have shown great potential in image classification and established state-of-the-art results on the ImageNet benchmark. However, compared to CNNs, transformers converge slowly and are prone to overfitting in low-data regimes due to the lack of spatial inductive biases. Such spatial inductive biases can be especially beneficial since the 2D structure of an input image is not well preserved in transformers. In this work, we present Spatial Prior-enhanced Self-Attention (SP-SA), a novel variant of vanilla Self-Attention (SA) tailored for vision transformers. Spatial Priors (SPs) are our proposed family of inductive biases that highlight certain groups of spatial relations. Unlike convolutional inductive biases, which are forced to focus exclusively on hard-coded local regions, our proposed SPs are learned by the model itself and take a variety of spatial relations into account. Specifically, the attention score is calculated with emphasis on certain kinds of spatial relations at each head, and such learned spatial foci can be complementary to each other. Based on SP-SA we propose the SP-ViT family, which consistently outperforms other ViT models with similar GFlops or parameters. Our largest model SP-ViT-L achieves a record-breaking 86.3% Top-1 accuracy with a reduction in the number of parameters by almost 50% compared to previous state-of-the-art model (150M for SP-ViT-L vs 271M for CaiT-M-36) among all ImageNet-1K models trained on 224x224 and fine-tuned on 384x384 resolution w/o extra data.
Estimation of Reliable Proposal Quality for Temporal Action Detection
Apr 25, 2022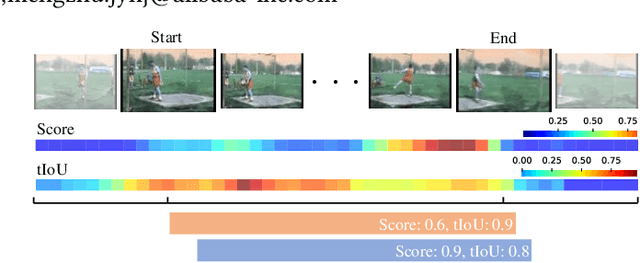
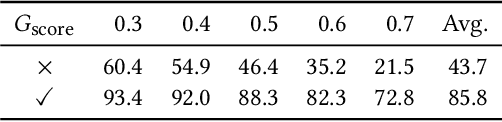
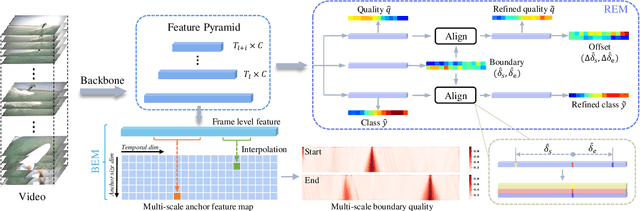
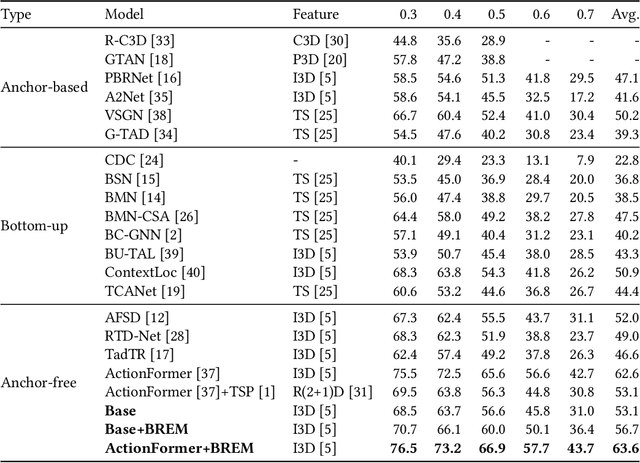
Temporal action detection (TAD) aims to locate and recognize the actions in an untrimmed video. Anchor-free methods have made remarkable progress which mainly formulate TAD into two tasks: classification and localization using two separate branches. This paper reveals the temporal misalignment between the two tasks hindering further progress. To address this, we propose a new method that gives insights into moment and region perspectives simultaneously to align the two tasks by acquiring reliable proposal quality. For the moment perspective, Boundary Evaluate Module (BEM) is designed which focuses on local appearance and motion evolvement to estimate boundary quality and adopts a multi-scale manner to deal with varied action durations. For the region perspective, we introduce Region Evaluate Module (REM) which uses a new and efficient sampling method for proposal feature representation containing more contextual information compared with point feature to refine category score and proposal boundary. The proposed Boundary Evaluate Module and Region Evaluate Module (BREM) are generic, and they can be easily integrated with other anchor-free TAD methods to achieve superior performance. In our experiments, BREM is combined with two different frameworks and improves the performance on THUMOS14 by 3.6$\%$ and 1.0$\%$ respectively, reaching a new state-of-the-art (63.6$\%$ average $m$AP). Meanwhile, a competitive result of 36.2\% average $m$AP is achieved on ActivityNet-1.3 with the consistent improvement of BREM.
Dense Learning based Semi-Supervised Object Detection
Apr 15, 2022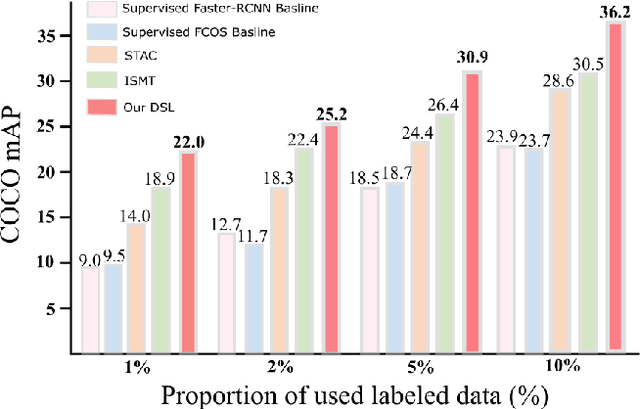
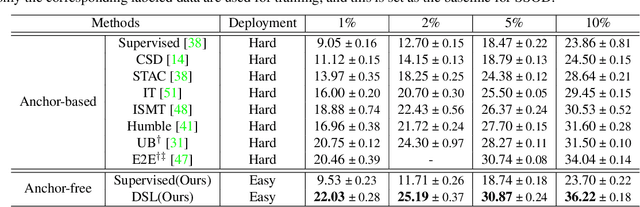
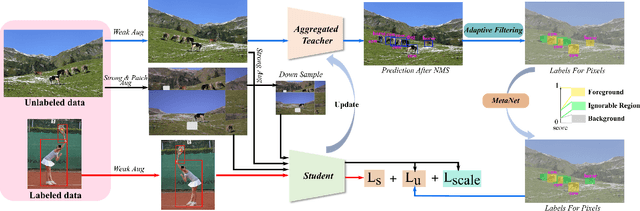
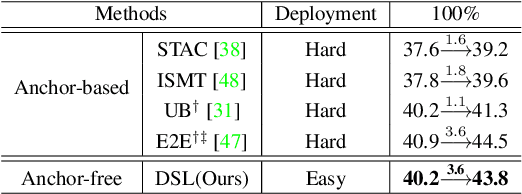
Semi-supervised object detection (SSOD) aims to facilitate the training and deployment of object detectors with the help of a large amount of unlabeled data. Though various self-training based and consistency-regularization based SSOD methods have been proposed, most of them are anchor-based detectors, ignoring the fact that in many real-world applications anchor-free detectors are more demanded. In this paper, we intend to bridge this gap and propose a DenSe Learning (DSL) based anchor-free SSOD algorithm. Specifically, we achieve this goal by introducing several novel techniques, including an Adaptive Filtering strategy for assigning multi-level and accurate dense pixel-wise pseudo-labels, an Aggregated Teacher for producing stable and precise pseudo-labels, and an uncertainty-consistency-regularization term among scales and shuffled patches for improving the generalization capability of the detector. Extensive experiments are conducted on MS-COCO and PASCAL-VOC, and the results show that our proposed DSL method records new state-of-the-art SSOD performance, surpassing existing methods by a large margin. Codes can be found at \textcolor{blue}{https://github.com/chenbinghui1/DSL}.
Structure-Aware Motion Transfer with Deformable Anchor Model
Apr 11, 2022
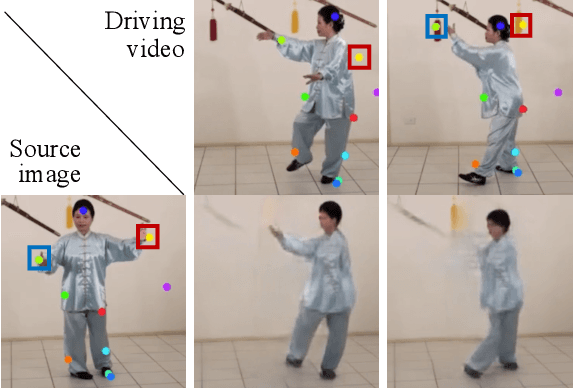

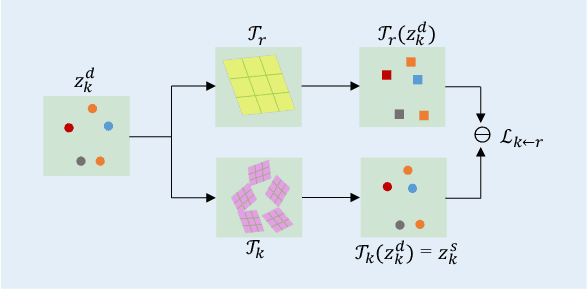
Given a source image and a driving video depicting the same object type, the motion transfer task aims to generate a video by learning the motion from the driving video while preserving the appearance from the source image. In this paper, we propose a novel structure-aware motion modeling approach, the deformable anchor model (DAM), which can automatically discover the motion structure of arbitrary objects without leveraging their prior structure information. Specifically, inspired by the known deformable part model (DPM), our DAM introduces two types of anchors or keypoints: i) a number of motion anchors that capture both appearance and motion information from the source image and driving video; ii) a latent root anchor, which is linked to the motion anchors to facilitate better learning of the representations of the object structure information. Moreover, DAM can be further extended to a hierarchical version through the introduction of additional latent anchors to model more complicated structures. By regularizing motion anchors with latent anchor(s), DAM enforces the correspondences between them to ensure the structural information is well captured and preserved. Moreover, DAM can be learned effectively in an unsupervised manner. We validate our proposed DAM for motion transfer on different benchmark datasets. Extensive experiments clearly demonstrate that DAM achieves superior performance relative to existing state-of-the-art methods.
Learning Pixel-Level Distinctions for Video Highlight Detection
Apr 10, 2022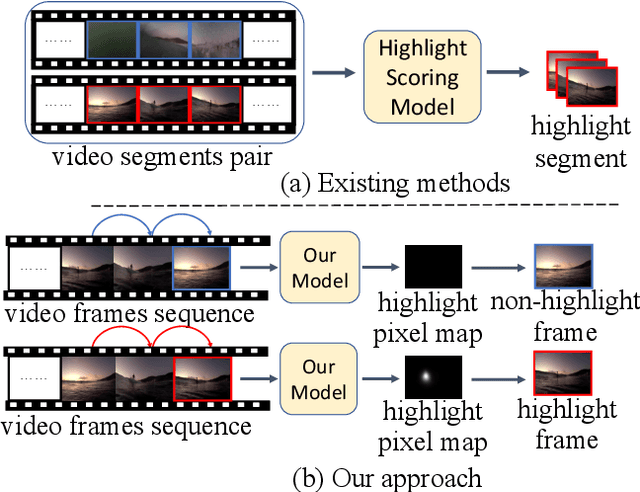

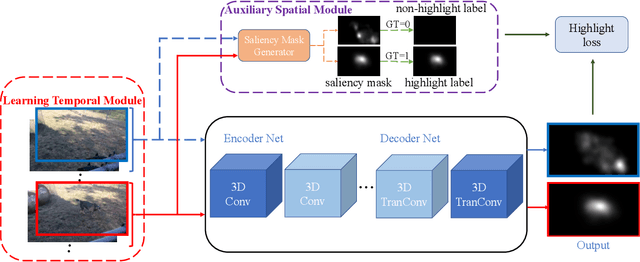
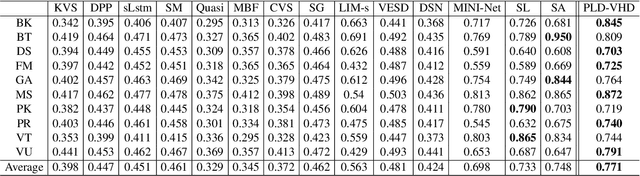
The goal of video highlight detection is to select the most attractive segments from a long video to depict the most interesting parts of the video. Existing methods typically focus on modeling relationship between different video segments in order to learning a model that can assign highlight scores to these segments; however, these approaches do not explicitly consider the contextual dependency within individual segments. To this end, we propose to learn pixel-level distinctions to improve the video highlight detection. This pixel-level distinction indicates whether or not each pixel in one video belongs to an interesting section. The advantages of modeling such fine-level distinctions are two-fold. First, it allows us to exploit the temporal and spatial relations of the content in one video, since the distinction of a pixel in one frame is highly dependent on both the content before this frame and the content around this pixel in this frame. Second, learning the pixel-level distinction also gives a good explanation to the video highlight task regarding what contents in a highlight segment will be attractive to people. We design an encoder-decoder network to estimate the pixel-level distinction, in which we leverage the 3D convolutional neural networks to exploit the temporal context information, and further take advantage of the visual saliency to model the spatial distinction. State-of-the-art performance on three public benchmarks clearly validates the effectiveness of our framework for video highlight detection.