 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSpatiotemporal Self-attention Modeling with Temporal Patch Shift for Action Recognition
Paper and Code
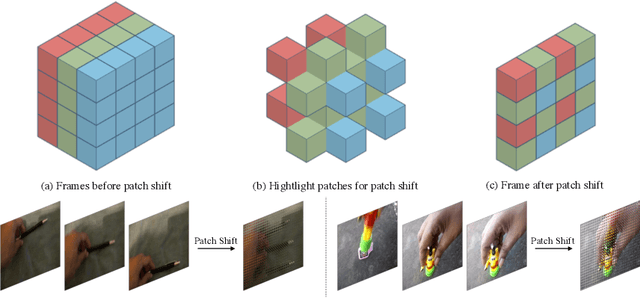
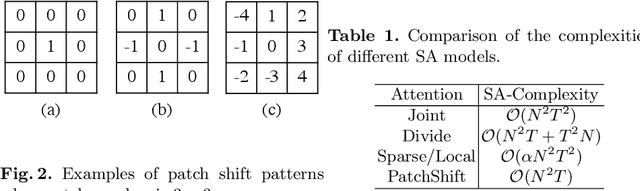
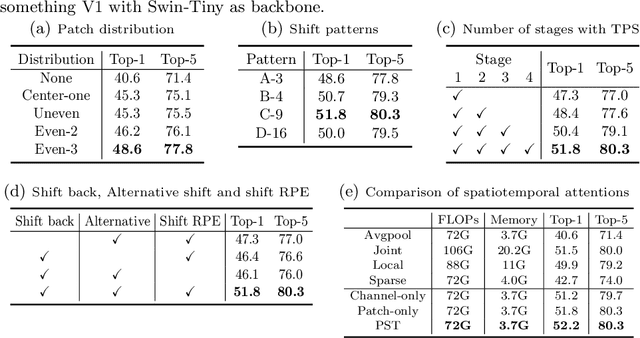

Transformer-based methods have recently achieved great advancement on 2D image-based vision tasks. For 3D video-based tasks such as action recognition, however, directly applying spatiotemporal transformers on video data will bring heavy computation and memory burdens due to the largely increased number of patches and the quadratic complexity of self-attention computation. How to efficiently and effectively model the 3D self-attention of video data has been a great challenge for transformers. In this paper, we propose a Temporal Patch Shift (TPS) method for efficient 3D self-attention modeling in transformers for video-based action recognition. TPS shifts part of patches with a specific mosaic pattern in the temporal dimension, thus converting a vanilla spatial self-attention operation to a spatiotemporal one with little additional cost. As a result, we can compute 3D self-attention using nearly the same computation and memory cost as 2D self-attention. TPS is a plug-and-play module and can be inserted into existing 2D transformer models to enhance spatiotemporal feature learning. The proposed method achieves competitive performance with state-of-the-arts on Something-something V1 & V2, Diving-48, and Kinetics400 while being much more efficient on computation and memory cost. The source code of TPS can be found at https://github.com/MartinXM/TPS.