 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSP-ViT: Learning 2D Spatial Priors for Vision Transformers
Paper and Code
Jun 15, 2022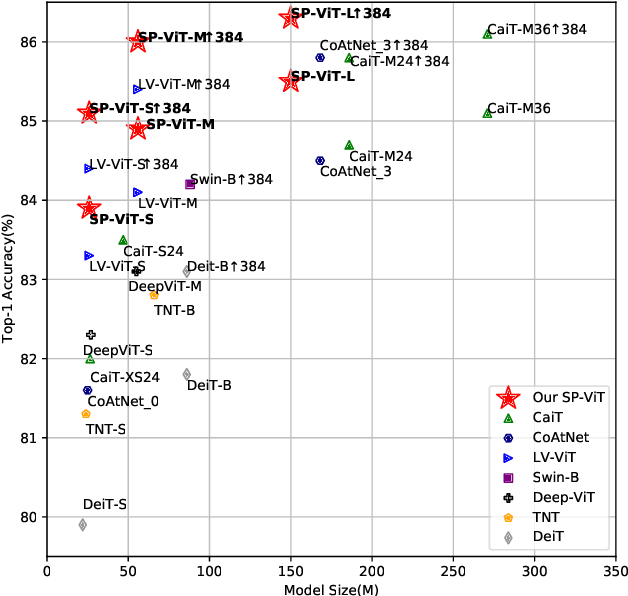
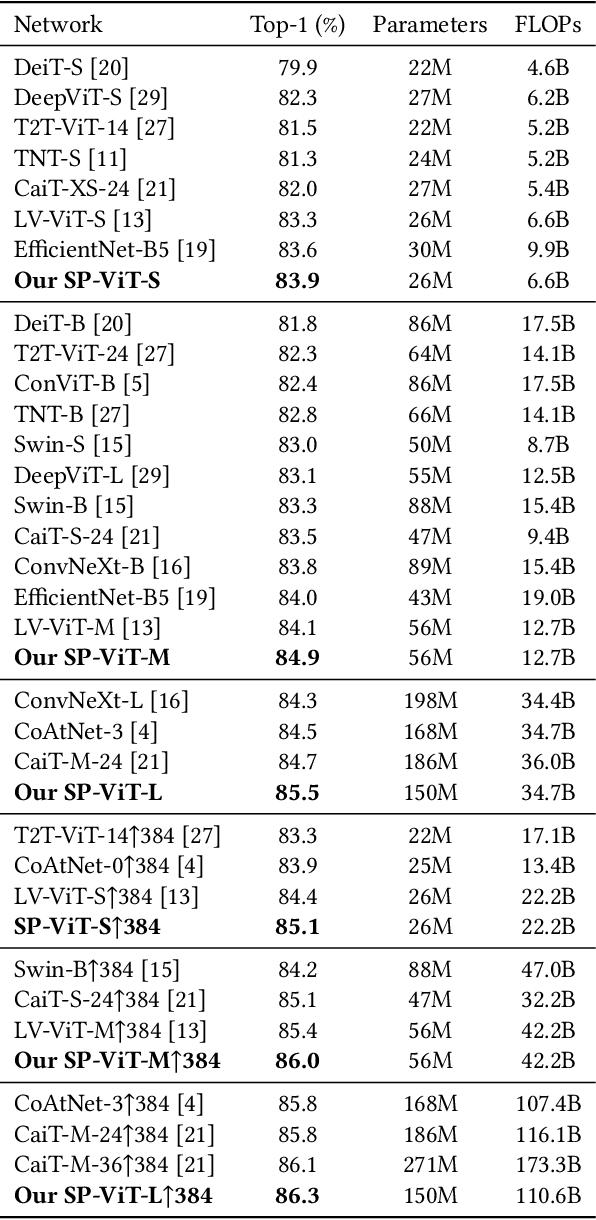
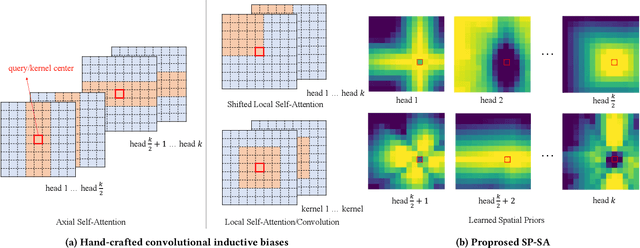

Recently, transformers have shown great potential in image classification and established state-of-the-art results on the ImageNet benchmark. However, compared to CNNs, transformers converge slowly and are prone to overfitting in low-data regimes due to the lack of spatial inductive biases. Such spatial inductive biases can be especially beneficial since the 2D structure of an input image is not well preserved in transformers. In this work, we present Spatial Prior-enhanced Self-Attention (SP-SA), a novel variant of vanilla Self-Attention (SA) tailored for vision transformers. Spatial Priors (SPs) are our proposed family of inductive biases that highlight certain groups of spatial relations. Unlike convolutional inductive biases, which are forced to focus exclusively on hard-coded local regions, our proposed SPs are learned by the model itself and take a variety of spatial relations into account. Specifically, the attention score is calculated with emphasis on certain kinds of spatial relations at each head, and such learned spatial foci can be complementary to each other. Based on SP-SA we propose the SP-ViT family, which consistently outperforms other ViT models with similar GFlops or parameters. Our largest model SP-ViT-L achieves a record-breaking 86.3% Top-1 accuracy with a reduction in the number of parameters by almost 50% compared to previous state-of-the-art model (150M for SP-ViT-L vs 271M for CaiT-M-36) among all ImageNet-1K models trained on 224x224 and fine-tuned on 384x384 resolution w/o extra data.