 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Regret Minimization Framework on Preference Learning in Large Language Models
Jun 08, 2026Reinforcement learning with verifiable rewards (RLVR) has enabled progress on reasoning-intensive tasks by relying on task-specific verifiers that provide automated correctness signals. However, many realistic language tasks are difficult to equip with reliable verifiers, motivating a growing reliance on reinforcement learning from human feedback (RLHF). In this setting, we argue that a closer examination of how human feedback should be interpreted is essential. We introduce Regret-based Preference Optimization $(\textbf{RePO})$, which reframes RLHF through $\textit{regret minimization}$ rather than reward maximization. Human preferences are often shaped by $\textit{prospective}$ anticipation of outcomes and $\textit{counterfactual}$ comparisons to alternative behaviors, rather than by immediate, outcome-independent utility. $\textbf{RePO}$ captures this structure by modeling preferences as behavior-conditioned assessments of relative suboptimality. Experiments on mathematical reasoning benchmarks and human preference datasets demonstrate consistent performance gains, indicating that $\textbf{RePO}$ is an effective and human-aligned approach for training large language models.
DuET: Dual Execution for Test Output Prediction with Generated Code and Pseudocode
Apr 13, 2026This work addresses test output prediction, a key challenge in test case generation. To improve the reliability of predicted outputs by LLMs, prior approaches generate code first to ground predictions. One grounding strategy is direct execution of generated code, but even minor errors can cause failures. To address this, we introduce LLM-based pseudocode execution, which grounds prediction on more error-resilient pseudocode and simulates execution via LLM reasoning. We further propose DuET, a dual-execution framework that combines both approaches by functional majority voting. Our analysis shows the two approaches are complementary in overcoming the limitations of direct execution suffering from code errors, and pseudocode reasoning from hallucination. On LiveCodeBench, DuET achieves the state-of-the-art performance, improving Pass@1 by 13.6 pp.
Adaptive Retrieval for Reasoning-Intensive Retrieval
Jan 08, 2026We study leveraging adaptive retrieval to ensure sufficient "bridge" documents are retrieved for reasoning-intensive retrieval. Bridge documents are those that contribute to the reasoning process yet are not directly relevant to the initial query. While existing reasoning-based reranker pipelines attempt to surface these documents in ranking, they suffer from bounded recall. Naive solution with adaptive retrieval into these pipelines often leads to planning error propagation. To address this, we propose REPAIR, a framework that bridges this gap by repurposing reasoning plans as dense feedback signals for adaptive retrieval. Our key distinction is enabling mid-course correction during reranking through selective adaptive retrieval, retrieving documents that support the pivotal plan. Experimental results on reasoning-intensive retrieval and complex QA tasks demonstrate that our method outperforms existing baselines by 5.6%pt.
SafeDPO: A Simple Approach to Direct Preference Optimization with Enhanced Safety
May 26, 2025As Large Language Models (LLMs) continue to advance and find applications across a growing number of fields, ensuring the safety of LLMs has become increasingly critical. To address safety concerns, recent studies have proposed integrating safety constraints into Reinforcement Learning from Human Feedback (RLHF). However, these approaches tend to be complex, as they encompass complicated procedures in RLHF along with additional steps required by the safety constraints. Inspired by Direct Preference Optimization (DPO), we introduce a new algorithm called SafeDPO, which is designed to directly optimize the safety alignment objective in a single stage of policy learning, without requiring relaxation. SafeDPO introduces only one additional hyperparameter to further enhance safety and requires only minor modifications to standard DPO. As a result, it eliminates the need to fit separate reward and cost models or to sample from the language model during fine-tuning, while still enhancing the safety of LLMs. Finally, we demonstrate that SafeDPO achieves competitive performance compared to state-of-the-art safety alignment algorithms, both in terms of aligning with human preferences and improving safety.
Modularized Transfer Learning with Multiple Knowledge Graphs for Zero-shot Commonsense Reasoning
Jun 22, 2022
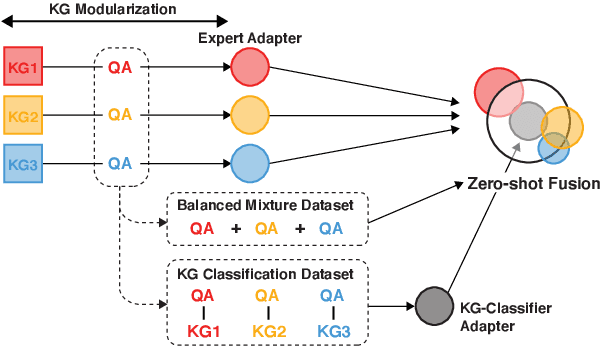
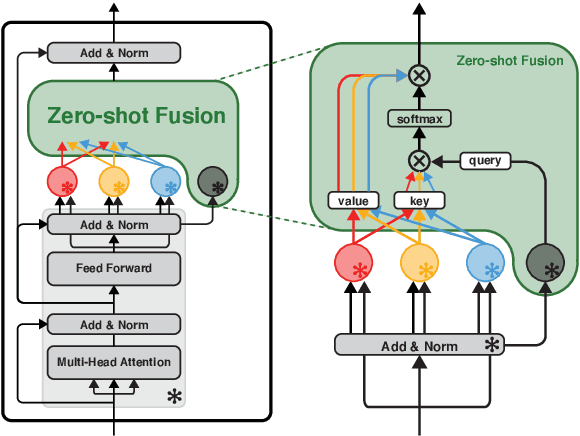
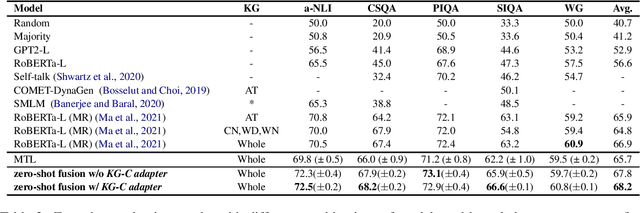
Commonsense reasoning systems should be able to generalize to diverse reasoning cases. However, most state-of-the-art approaches depend on expensive data annotations and overfit to a specific benchmark without learning how to perform general semantic reasoning. To overcome these drawbacks, zero-shot QA systems have shown promise as a robust learning scheme by transforming a commonsense knowledge graph (KG) into synthetic QA-form samples for model training. Considering the increasing type of different commonsense KGs, this paper aims to extend the zero-shot transfer learning scenario into multiple-source settings, where different KGs can be utilized synergetically. Towards this goal, we propose to mitigate the loss of knowledge from the interference among the different knowledge sources, by developing a modular variant of the knowledge aggregation as a new zero-shot commonsense reasoning framework. Results on five commonsense reasoning benchmarks demonstrate the efficacy of our framework, improving the performance with multiple KGs.
TrustAL: Trustworthy Active Learning using Knowledge Distillation
Jan 26, 2022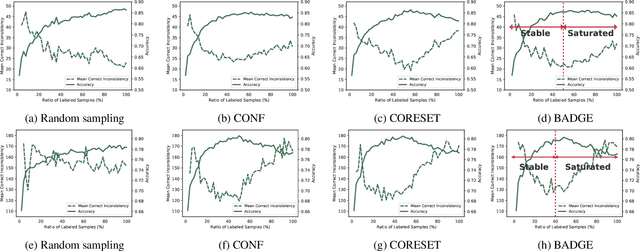
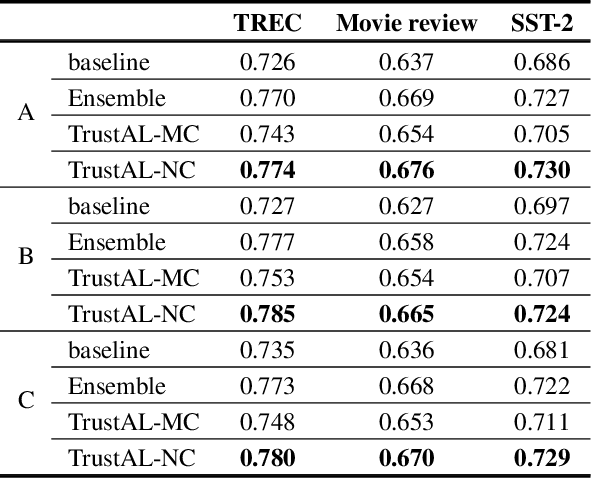
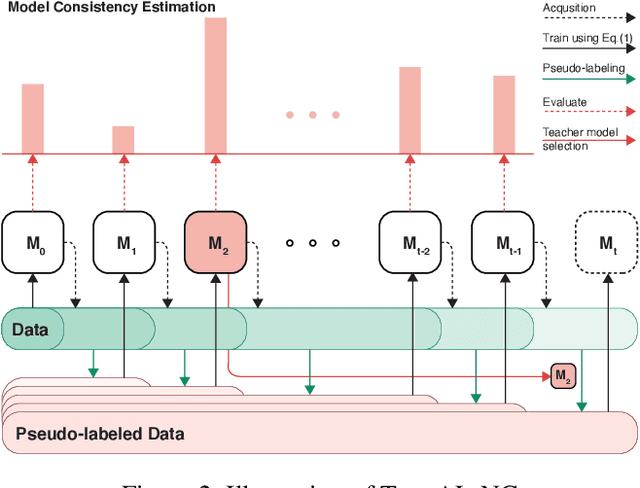
Active learning can be defined as iterations of data labeling, model training, and data acquisition, until sufficient labels are acquired. A traditional view of data acquisition is that, through iterations, knowledge from human labels and models is implicitly distilled to monotonically increase the accuracy and label consistency. Under this assumption, the most recently trained model is a good surrogate for the current labeled data, from which data acquisition is requested based on uncertainty/diversity. Our contribution is debunking this myth and proposing a new objective for distillation. First, we found example forgetting, which indicates the loss of knowledge learned across iterations. Second, for this reason, the last model is no longer the best teacher -- For mitigating such forgotten knowledge, we select one of its predecessor models as a teacher, by our proposed notion of "consistency". We show that this novel distillation is distinctive in the following three aspects; First, consistency ensures to avoid forgetting labels. Second, consistency improves both uncertainty/diversity of labeled data. Lastly, consistency redeems defective labels produced by human annotators.