 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearning Energy-Based Models by Diffusion Recovery Likelihood
Dec 15, 2020
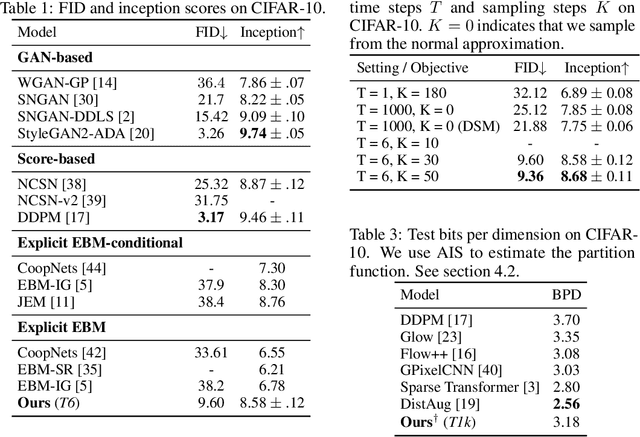

While energy-based models (EBMs) exhibit a number of desirable properties, training and sampling on high-dimensional datasets remains challenging. Inspired by recent progress on diffusion probabilistic models, we present a diffusion recovery likelihood method to tractably learn and sample from a sequence of EBMs trained on increasingly noisy versions of a dataset. Each EBM is trained by maximizing the recovery likelihood: the conditional probability of the data at a certain noise level given their noisy versions at a higher noise level. The recovery likelihood objective is more tractable than the marginal likelihood objective, since it only requires MCMC sampling from a relatively concentrated conditional distribution. Moreover, we show that this estimation method is theoretically consistent: it learns the correct conditional and marginal distributions at each noise level, given sufficient data. After training, synthesized images can be generated efficiently by a sampling process that initializes from a spherical Gaussian distribution and progressively samples the conditional distributions at decreasingly lower noise levels. Our method generates high fidelity samples on various image datasets. On unconditional CIFAR-10 our method achieves FID 9.60 and inception score 8.58, superior to the majority of GANs. Moreover, we demonstrate that unlike previous work on EBMs, our long-run MCMC samples from the conditional distributions do not diverge and still represent realistic images, allowing us to accurately estimate the normalized density of data even for high-dimensional datasets.
Score-Based Generative Modeling through Stochastic Differential Equations
Nov 26, 2020
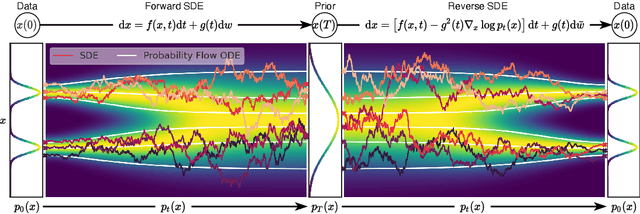

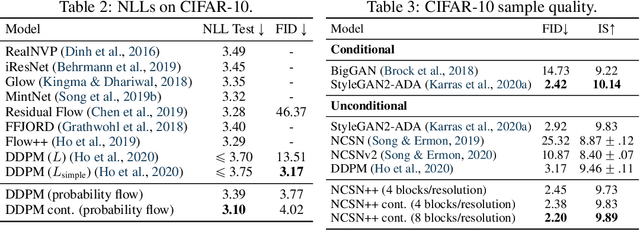
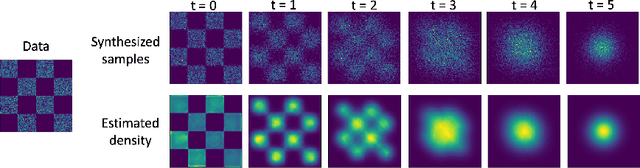
Creating noise from data is easy; creating data from noise is generative modeling. We present a stochastic differential equation (SDE) that smoothly transforms a complex data distribution to a known prior distribution by slowly injecting noise, and a corresponding reverse-time SDE that transforms the prior distribution back into the data distribution by slowly removing the noise. Crucially, the reverse-time SDE depends only on the time-dependent gradient field (a.k.a., score) of the perturbed data distribution. By leveraging advances in score-based generative modeling, we can accurately estimate these scores with neural networks, and use numerical SDE solvers to generate samples. We show that this framework encapsulates previous approaches in diffusion probabilistic modeling and score-based generative modeling, and allows for new sampling procedures. In particular, we introduce a predictor-corrector framework to correct errors in the evolution of the discretized reverse-time SDE. We also derive an equivalent neural ODE that samples from the same distribution as the SDE, which enables exact likelihood computation, and improved sampling efficiency. In addition, our framework enables conditional generation with an unconditional model, as we demonstrate with experiments on class-conditional generation, image inpainting, and colorization. Combined with multiple architectural improvements, we achieve record-breaking performance for unconditional image generation on CIFAR-10 with an Inception score of 9.89 and FID of 2.20, a competitive likelihood of 3.10 bits/dim, and demonstrate high fidelity generation of $1024 \times 1024$ images for the first time from a score-based generative model.
VIB is Half Bayes
Nov 17, 2020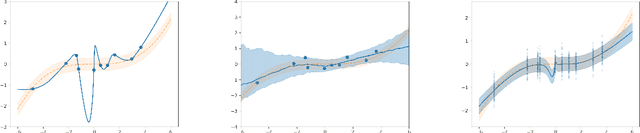
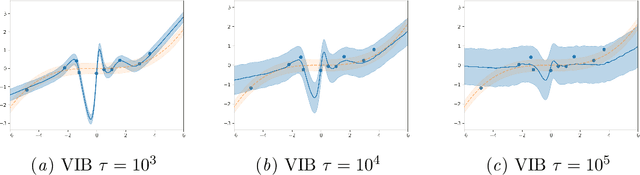

In discriminative settings such as regression and classification there are two random variables at play, the inputs X and the targets Y. Here, we demonstrate that the Variational Information Bottleneck can be viewed as a compromise between fully empirical and fully Bayesian objectives, attempting to minimize the risks due to finite sampling of Y only. We argue that this approach provides some of the benefits of Bayes while requiring only some of the work.
Non-saturating GAN training as divergence minimization
Oct 15, 2020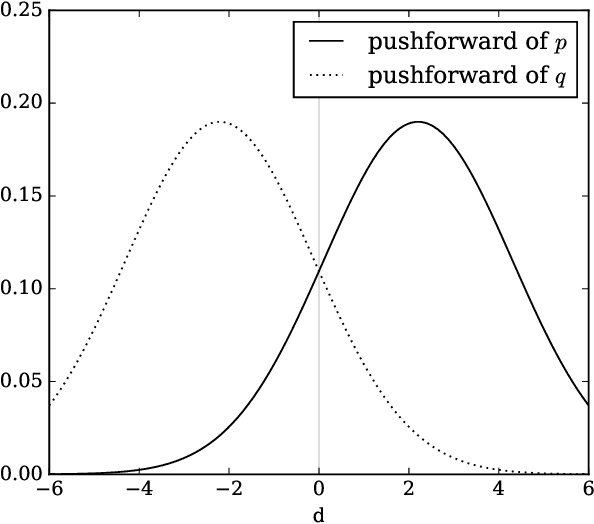

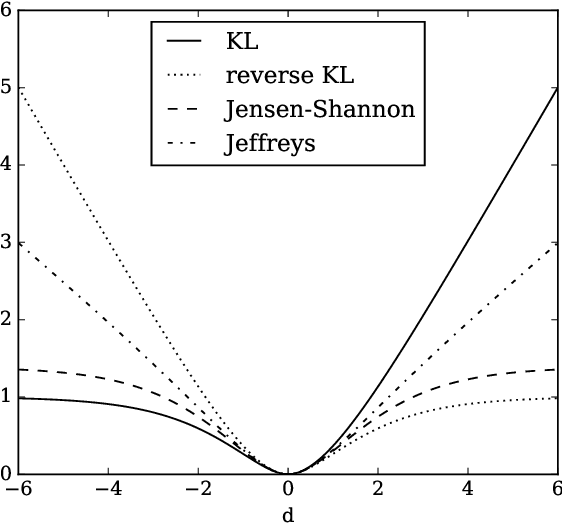
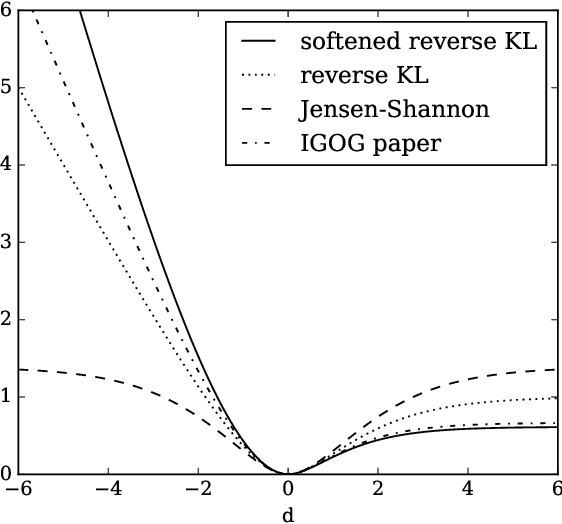
Non-saturating generative adversarial network (GAN) training is widely used and has continued to obtain groundbreaking results. However so far this approach has lacked strong theoretical justification, in contrast to alternatives such as f-GANs and Wasserstein GANs which are motivated in terms of approximate divergence minimization. In this paper we show that non-saturating GAN training does in fact approximately minimize a particular f-divergence. We develop general theoretical tools to compare and classify f-divergences and use these to show that the new f-divergence is qualitatively similar to reverse KL. These results help to explain the high sample quality but poor diversity often observed empirically when using this scheme.
Tasks, stability, architecture, and compute: Training more effective learned optimizers, and using them to train themselves
Sep 23, 2020
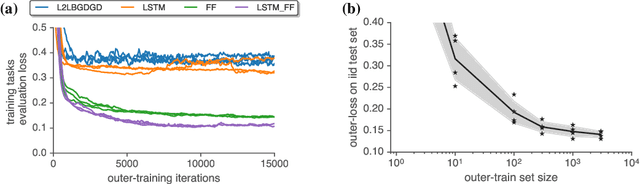
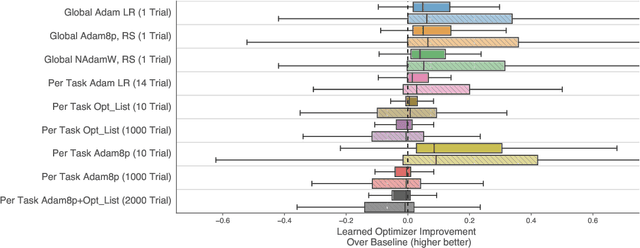
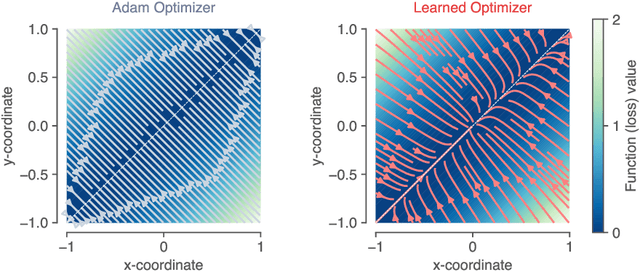
Much as replacing hand-designed features with learned functions has revolutionized how we solve perceptual tasks, we believe learned algorithms will transform how we train models. In this work we focus on general-purpose learned optimizers capable of training a wide variety of problems with no user-specified hyperparameters. We introduce a new, neural network parameterized, hierarchical optimizer with access to additional features such as validation loss to enable automatic regularization. Most learned optimizers have been trained on only a single task, or a small number of tasks. We train our optimizers on thousands of tasks, making use of orders of magnitude more compute, resulting in optimizers that generalize better to unseen tasks. The learned optimizers not only perform well, but learn behaviors that are distinct from existing first order optimizers. For instance, they generate update steps that have implicit regularization and adapt as the problem hyperparameters (e.g. batch size) or architecture (e.g. neural network width) change. Finally, these learned optimizers show evidence of being useful for out of distribution tasks such as training themselves from scratch.
What makes for good views for contrastive learning
May 20, 2020
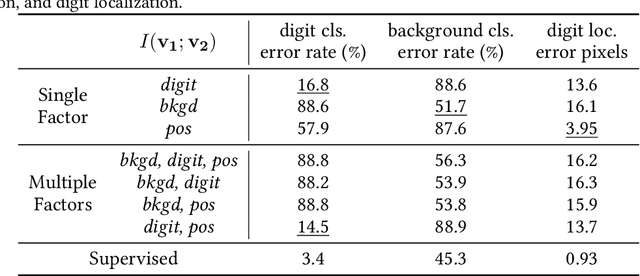
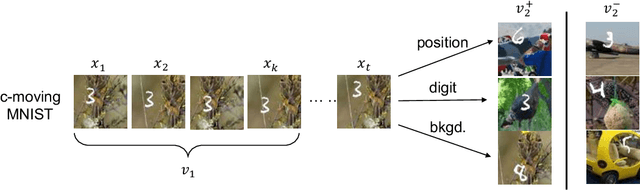
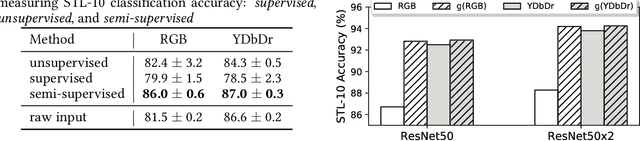
Contrastive learning between multiple views of the data has recently achieved state of the art performance in the field of self-supervised representation learning. Despite its success, the influence of different view choices has been less studied. In this paper, we use empirical analysis to better understand the importance of view selection, and argue that we should reduce the mutual information (MI) between views while keeping task-relevant information intact. To verify this hypothesis, we devise unsupervised and semi-supervised frameworks that learn effective views by aiming to reduce their MI. We also consider data augmentation as a way to reduce MI, and show that increasing data augmentation indeed leads to decreasing MI and improves downstream classification accuracy. As a by-product, we also achieve a new state-of-the-art accuracy on unsupervised pre-training for ImageNet classification ($73\%$ top-1 linear readoff with a ResNet-50). In addition, transferring our models to PASCAL VOC object detection and COCO instance segmentation consistently outperforms supervised pre-training. Code:http://github.com/HobbitLong/PyContrast
Using a thousand optimization tasks to learn hyperparameter search strategies
Mar 11, 2020
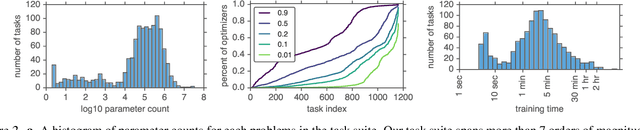
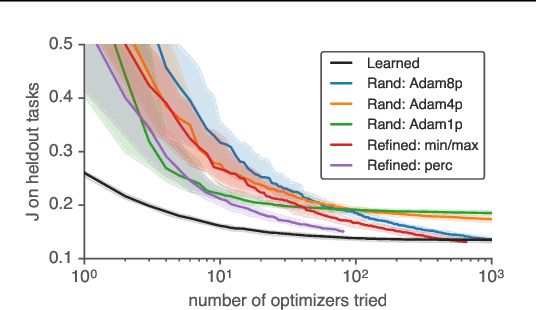
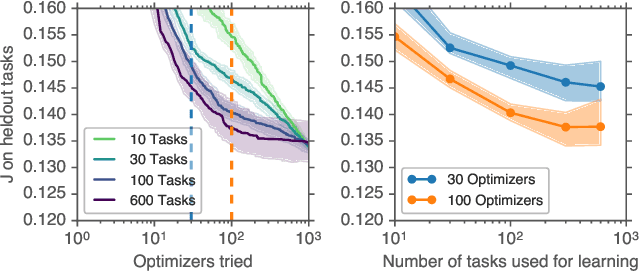
We present TaskSet, a dataset of tasks for use in training and evaluating optimizers. TaskSet is unique in its size and diversity, containing over a thousand tasks ranging from image classification with fully connected or convolutional neural networks, to variational autoencoders, to non-volume preserving flows on a variety of datasets. As an example application of such a dataset we explore meta-learning an ordered list of hyperparameters to try sequentially. By learning this hyperparameter list from data generated using TaskSet we achieve large speedups in sample efficiency over random search. Next we use the diversity of the TaskSet and our method for learning hyperparameter lists to empirically explore the generalization of these lists to new optimization tasks in a variety of settings including ImageNet classification with Resnet50 and LM1B language modeling with transformers. As part of this work we have opensourced code for all tasks, as well as ~29 million training curves for these problems and the corresponding hyperparameters.
Regularized Autoencoders via Relaxed Injective Probability Flow
Feb 20, 2020
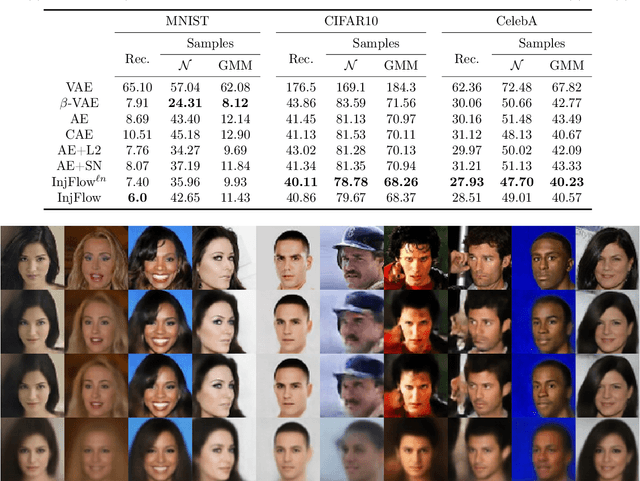


Invertible flow-based generative models are an effective method for learning to generate samples, while allowing for tractable likelihood computation and inference. However, the invertibility requirement restricts models to have the same latent dimensionality as the inputs. This imposes significant architectural, memory, and computational costs, making them more challenging to scale than other classes of generative models such as Variational Autoencoders (VAEs). We propose a generative model based on probability flows that does away with the bijectivity requirement on the model and only assumes injectivity. This also provides another perspective on regularized autoencoders (RAEs), with our final objectives resembling RAEs with specific regularizers that are derived by lower bounding the probability flow objective. We empirically demonstrate the promise of the proposed model, improving over VAEs and AEs in terms of sample quality.
On Implicit Regularization in $β$-VAEs
Feb 09, 2020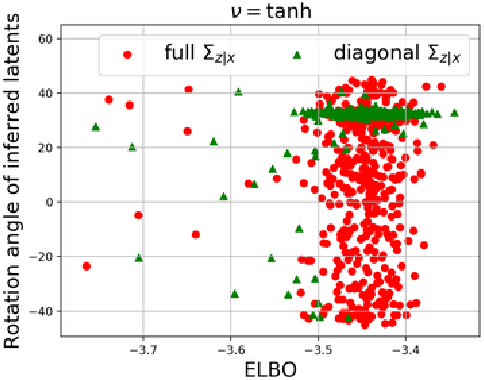



While the impact of variational inference (VI) on posterior inference in a fixed generative model is well-characterized, its role in regularizing a learned generative model when used in variational autoencoders (VAEs) is poorly understood. We study the regularizing effects of variational distributions on learning in generative models from two perspectives. First, we analyze the role that the choice of variational family plays in imparting uniqueness to the learned model by restricting the set of optimal generative models. Second, we study the regularization effect of the variational family on the local geometry of the decoding model. This analysis uncovers the regularizer implicit in the $\beta$-VAE objective, and leads to an approximation consisting of a deterministic autoencoding objective plus analytic regularizers that depend on the Hessian or Jacobian of the decoding model, unifying VAEs with recent heuristics proposed for training regularized autoencoders. We empirically verify these findings, observing that the proposed deterministic objective exhibits similar behavior to the $\beta$-VAE in terms of objective value and sample quality.
Weakly-Supervised Disentanglement Without Compromises
Feb 07, 2020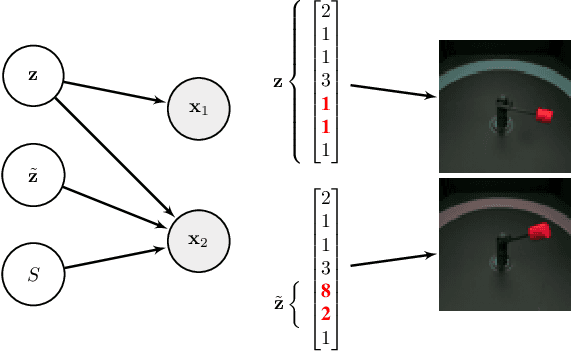

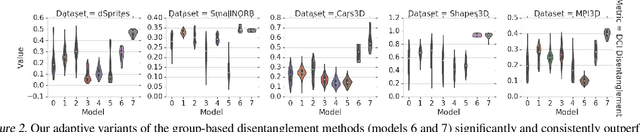
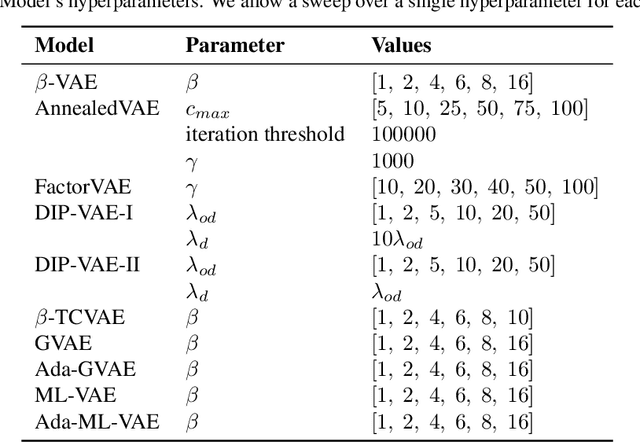
Intelligent agents should be able to learn useful representations by observing changes in their environment. We model such observations as pairs of non-i.i.d. images sharing at least one of the underlying factors of variation. First, we theoretically show that only knowing how many factors have changed, but not which ones, is sufficient to learn disentangled representations. Second, we provide practical algorithms that learn disentangled representations from pairs of images without requiring annotation of groups, individual factors, or the number of factors that have changed. Third, we perform a large-scale empirical study and show that such pairs of observations are sufficient to reliably learn disentangled representations on several benchmark data sets. Finally, we evaluate our learned representations and find that they are simultaneously useful on a diverse suite of tasks, including generalization under covariate shifts, fairness, and abstract reasoning. Overall, our results demonstrate that weak supervision enables learning of useful disentangled representations in realistic scenarios.