 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTorchScale: Transformers at Scale
Nov 23, 2022Large Transformers have achieved state-of-the-art performance across many tasks. Most open-source libraries on scaling Transformers focus on improving training or inference with better parallelization. In this work, we present TorchScale, an open-source toolkit that allows researchers and developers to scale up Transformers efficiently and effectively. TorchScale has the implementation of several modeling techniques, which can improve modeling generality and capability, as well as training stability and efficiency. Experimental results on language modeling and neural machine translation demonstrate that TorchScale can successfully scale Transformers to different sizes without tears. The library is available at https://aka.ms/torchscale.
Beyond English-Centric Bitexts for Better Multilingual Language Representation Learning
Oct 26, 2022



In this paper, we elaborate upon recipes for building multilingual representation models that are not only competitive with existing state-of-the-art models but are also more parameter efficient, thereby promoting better adoption in resource-constrained scenarios and practical applications. We show that going beyond English-centric bitexts, coupled with a novel sampling strategy aimed at reducing under-utilization of training data, substantially boosts performance across model sizes for both Electra and MLM pre-training objectives. We introduce XY-LENT: X-Y bitext enhanced Language ENcodings using Transformers which not only achieves state-of-the-art performance over 5 cross-lingual tasks within all model size bands, is also competitive across bands. Our XY-LENT XL variant outperforms XLM-RXXL and exhibits competitive performance with mT5 XXL while being 5x and 6x smaller respectively. We then show that our proposed method helps ameliorate the curse of multilinguality, with the XY-LENT XL achieving 99.3% GLUE performance and 98.5% SQuAD 2.0 performance compared to a SoTA English only model in the same size band. We then analyze our models performance on extremely low resource languages and posit that scaling alone may not be sufficient for improving the performance in this scenario
Foundation Transformers
Oct 19, 2022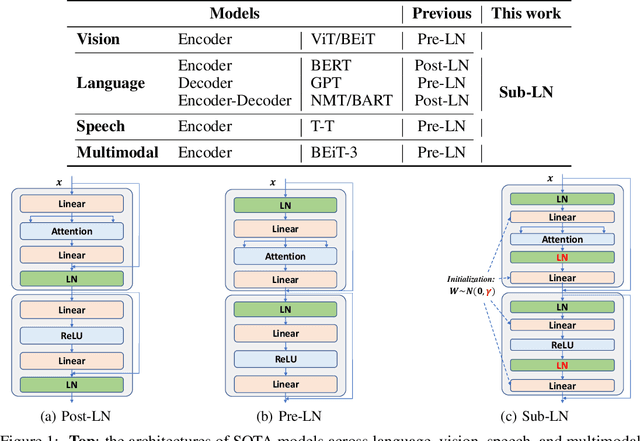
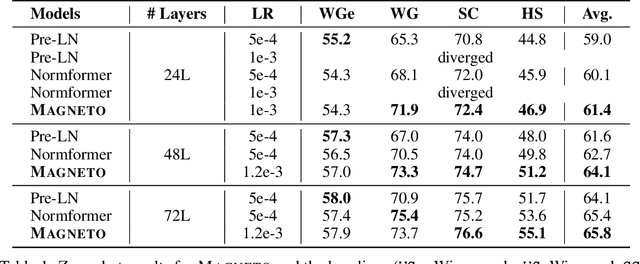
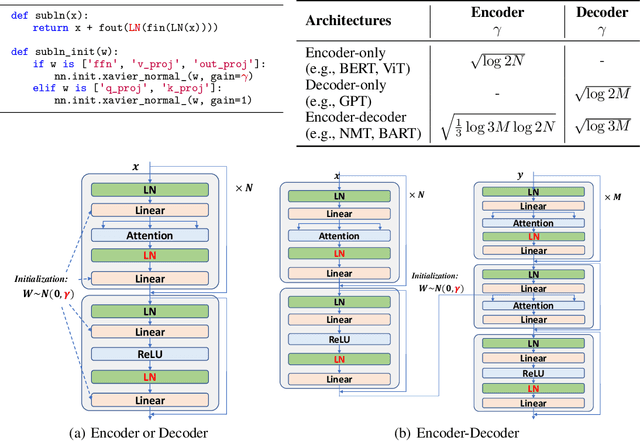
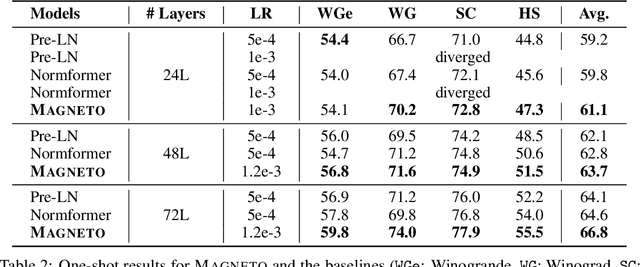
A big convergence of model architectures across language, vision, speech, and multimodal is emerging. However, under the same name "Transformers", the above areas use different implementations for better performance, e.g., Post-LayerNorm for BERT, and Pre-LayerNorm for GPT and vision Transformers. We call for the development of Foundation Transformer for true general-purpose modeling, which serves as a go-to architecture for various tasks and modalities with guaranteed training stability. In this work, we introduce a Transformer variant, named Magneto, to fulfill the goal. Specifically, we propose Sub-LayerNorm for good expressivity, and the initialization strategy theoretically derived from DeepNet for stable scaling up. Extensive experiments demonstrate its superior performance and better stability than the de facto Transformer variants designed for various applications, including language modeling (i.e., BERT, and GPT), machine translation, vision pretraining (i.e., BEiT), speech recognition, and multimodal pretraining (i.e., BEiT-3).
Language Model Decoding as Likelihood-Utility Alignment
Oct 13, 2022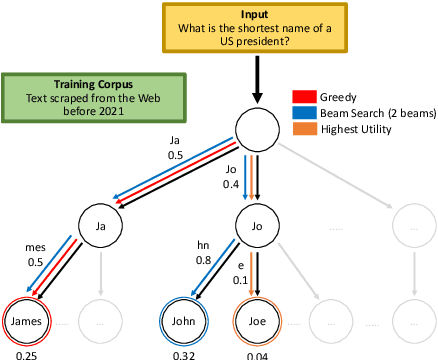

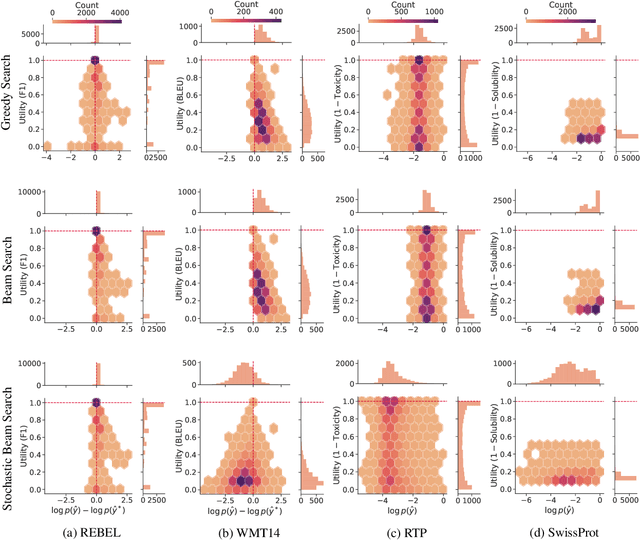
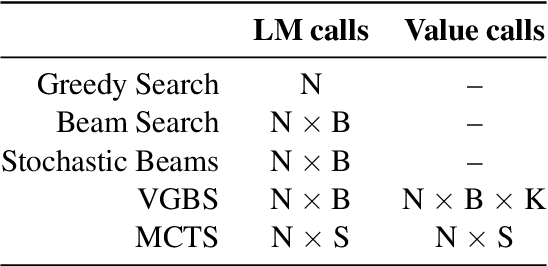
A critical component of a successful language generation pipeline is the decoding algorithm. However, the general principles that should guide the choice of decoding algorithm remain unclear. Previous works only compare decoding algorithms in narrow scenarios and their findings do not generalize across tasks. To better structure the discussion, we introduce a taxonomy that groups decoding strategies based on their implicit assumptions about how well the model's likelihood is aligned with the task-specific notion of utility. We argue that this taxonomy allows a broader view of the decoding problem and can lead to generalizable statements because it is grounded on the interplay between the decoding algorithms and the likelihood-utility misalignment. Specifically, by analyzing the correlation between the likelihood and the utility of predictions across a diverse set of tasks, we provide the first empirical evidence supporting the proposed taxonomy, and a set of principles to structure reasoning when choosing a decoding algorithm. Crucially, our analysis is the first one to relate likelihood-based decoding strategies with strategies that rely on external information such as value-guided methods and prompting, and covers the most diverse set of tasks up-to-date.
On the Representation Collapse of Sparse Mixture of Experts
Apr 20, 2022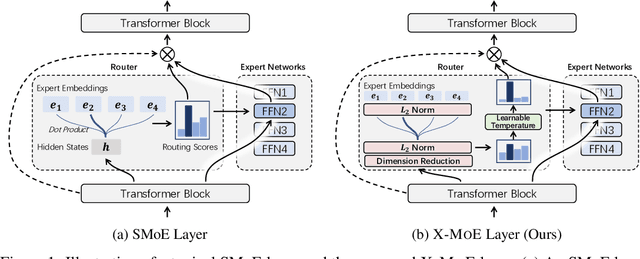
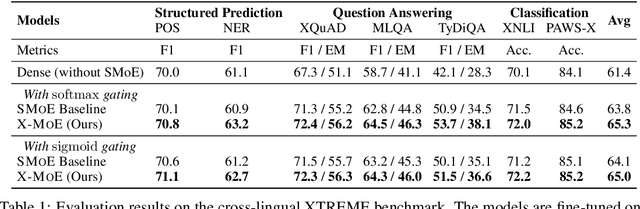
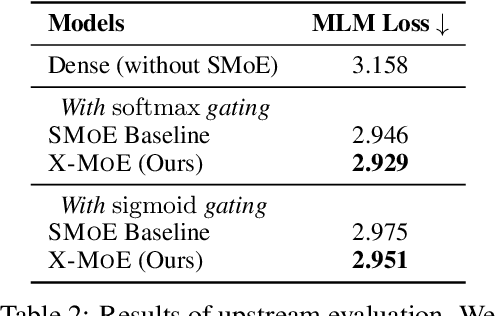
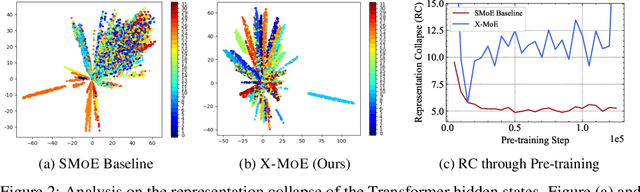
Sparse mixture of experts provides larger model capacity while requiring a constant computational overhead. It employs the routing mechanism to distribute input tokens to the best-matched experts according to their hidden representations. However, learning such a routing mechanism encourages token clustering around expert centroids, implying a trend toward representation collapse. In this work, we propose to estimate the routing scores between tokens and experts on a low-dimensional hypersphere. We conduct extensive experiments on cross-lingual language model pre-training and fine-tuning on downstream tasks. Experimental results across seven multilingual benchmarks show that our method achieves consistent gains. We also present a comprehensive analysis on the representation and routing behaviors of our models. Our method alleviates the representation collapse issue and achieves more consistent routing than the baseline mixture-of-experts methods.
On Efficiently Acquiring Annotations for Multilingual Models
Apr 03, 2022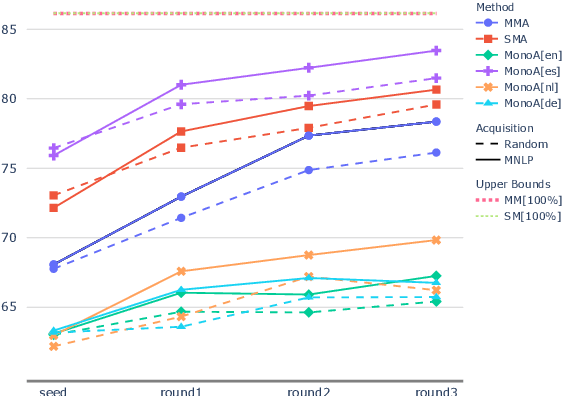
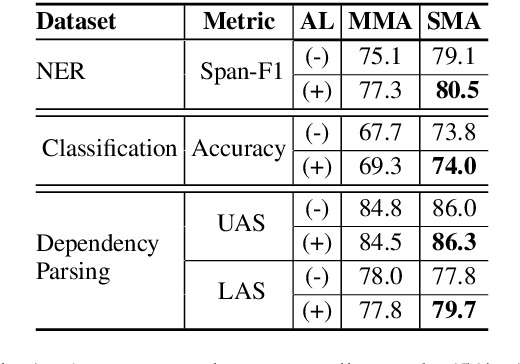
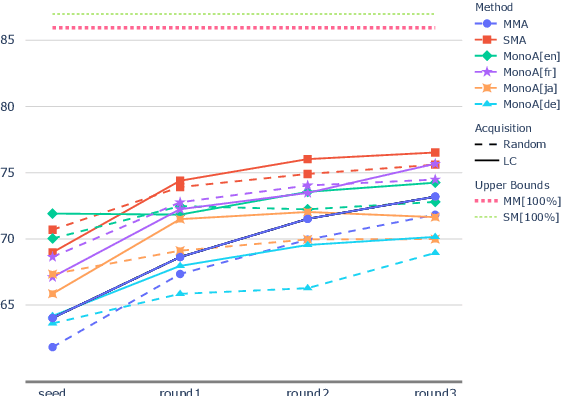
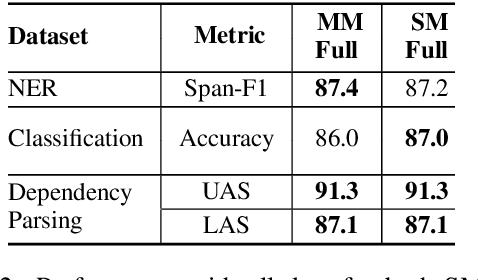
When tasked with supporting multiple languages for a given problem, two approaches have arisen: training a model for each language with the annotation budget divided equally among them, and training on a high-resource language followed by zero-shot transfer to the remaining languages. In this work, we show that the strategy of joint learning across multiple languages using a single model performs substantially better than the aforementioned alternatives. We also demonstrate that active learning provides additional, complementary benefits. We show that this simple approach enables the model to be data efficient by allowing it to arbitrate its annotation budget to query languages it is less certain on. We illustrate the effectiveness of our proposed method on a diverse set of tasks: a classification task with 4 languages, a sequence tagging task with 4 languages and a dependency parsing task with 5 languages. Our proposed method, whilst simple, substantially outperforms the other viable alternatives for building a model in a multilingual setting under constrained budgets.
Invariant Language Modeling
Oct 16, 2021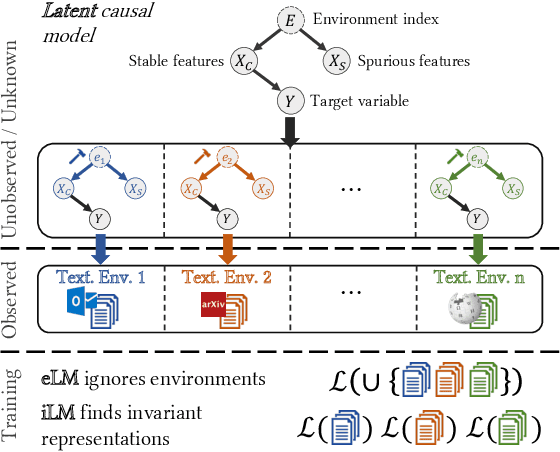
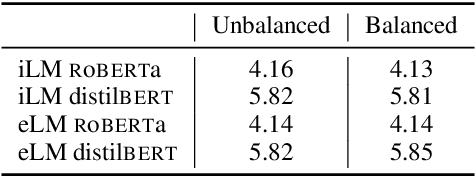
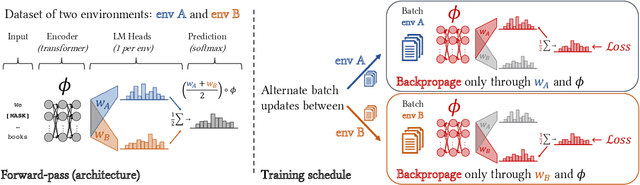
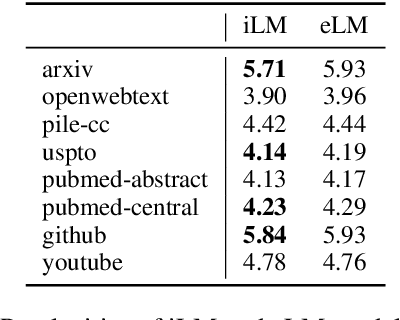
Modern pretrained language models are critical components of NLP pipelines. Yet, they suffer from spurious correlations, poor out-of-domain generalization, and biases. Inspired by recent progress in causal machine learning, in particular the invariant risk minimization (IRM) paradigm, we propose invariant language modeling, a framework for learning invariant representations that generalize better across multiple environments. In particular, we adapt a game-theoretic implementation of IRM (IRM-games) to language models, where the invariance emerges from a specific training schedule in which all the environments compete to optimize their own environment-specific loss by updating subsets of the model in a round-robin fashion. In a series of controlled experiments, we demonstrate the ability of our method to (i) remove structured noise, (ii) ignore specific spurious correlations without affecting global performance, and (iii) achieve better out-of-domain generalization. These benefits come with a negligible computational overhead compared to standard training, do not require changing the local loss, and can be applied to any language model architecture. We believe this framework is promising to help mitigate spurious correlations and biases in language models.
To Schedule or not to Schedule: Extracting Task Specific Temporal Entities and Associated Negation Constraints
Nov 15, 2020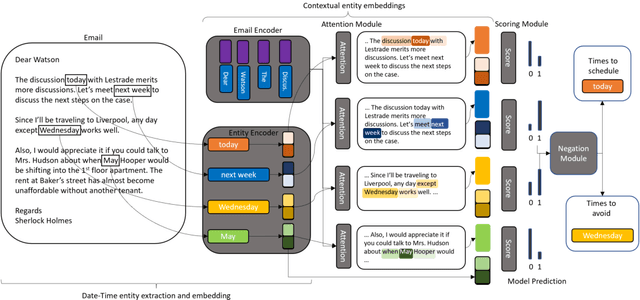
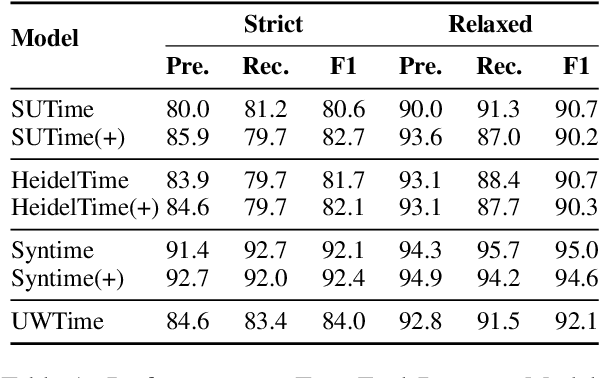
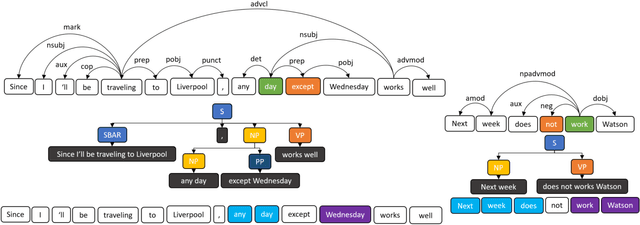
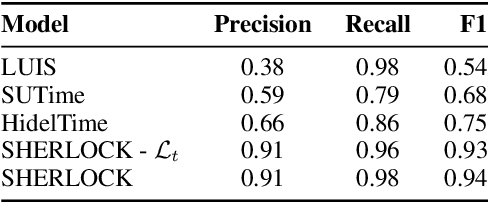
State of the art research for date-time entity extraction from text is task agnostic. Consequently, while the methods proposed in literature perform well for generic date-time extraction from texts, they don't fare as well on task specific date-time entity extraction where only a subset of the date-time entities present in the text are pertinent to solving the task. Furthermore, some tasks require identifying negation constraints associated with the date-time entities to correctly reason over time. We showcase a novel model for extracting task-specific date-time entities along with their negation constraints. We show the efficacy of our method on the task of date-time understanding in the context of scheduling meetings for an email-based digital AI scheduling assistant. Our method achieves an absolute gain of 19\% f-score points compared to baseline methods in detecting the date-time entities relevant to scheduling meetings and a 4\% improvement over baseline methods for detecting negation constraints over date-time entities.
ScopeIt: Scoping Task Relevant Sentences in Documents
Feb 23, 2020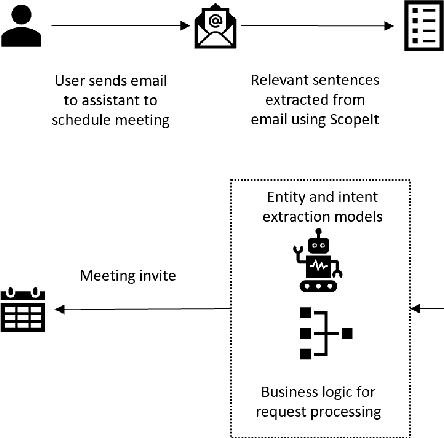

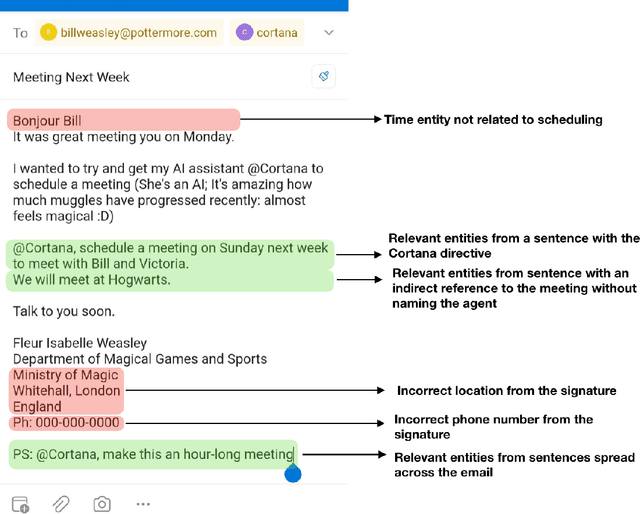
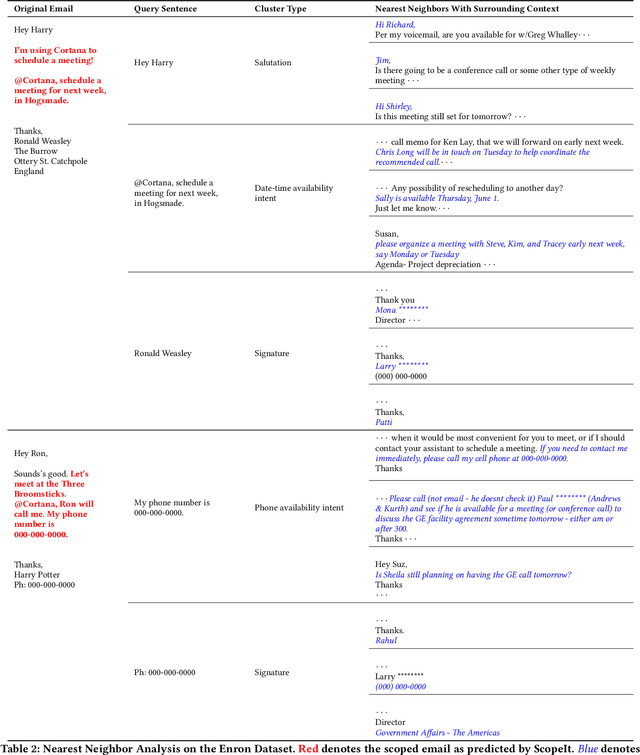
Intelligent assistants like Cortana, Siri, Alexa, and Google Assistant are trained to parse information when the conversation is synchronous and short; however, for email-based conversational agents, the communication is asynchronous, and often contains information irrelevant to the assistant. This makes it harder for the system to accurately detect intents, extract entities relevant to those intents and thereby perform the desired action. We present a neural model for scoping relevant information for the agent from a large query. We show that when used as a preprocessing step, the model improves performance of both intent detection and entity extraction tasks. We demonstrate the model's impact on Scheduler (Cortana is the persona of the agent, while Scheduler is the name of the service. We use them interchangeably in the context of this paper.) - a virtual conversational meeting scheduling assistant that interacts asynchronously with users through email. The model helps the entity extraction and intent detection tasks requisite by Scheduler achieve an average gain of 35% in precision without any drop in recall. Additionally, we demonstrate that the same approach can be used for component level analysis in large documents, such as signature block identification.
Bilingual Lexicon Induction with Semi-supervision in Non-Isometric Embedding Spaces
Aug 19, 2019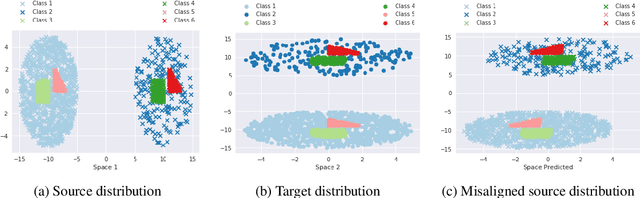

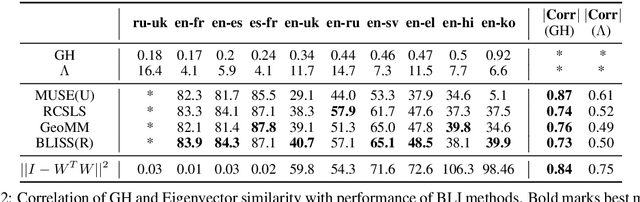

Recent work on bilingual lexicon induction (BLI) has frequently depended either on aligned bilingual lexicons or on distribution matching, often with an assumption about the isometry of the two spaces. We propose a technique to quantitatively estimate this assumption of the isometry between two embedding spaces and empirically show that this assumption weakens as the languages in question become increasingly etymologically distant. We then propose Bilingual Lexicon Induction with Semi-Supervision (BLISS) --- a semi-supervised approach that relaxes the isometric assumption while leveraging both limited aligned bilingual lexicons and a larger set of unaligned word embeddings, as well as a novel hubness filtering technique. Our proposed method obtains state of the art results on 15 of 18 language pairs on the MUSE dataset, and does particularly well when the embedding spaces don't appear to be isometric. In addition, we also show that adding supervision stabilizes the learning procedure, and is effective even with minimal supervision.
* ACL 2019