 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePPT-Eval: A Benchmark for Computer-Use Agents on PowerPoint Tasks
Jun 30, 2026Creating and editing slides is a rich, multimodal activity that is ubiquitous in professional and educational settings, making it an ideal testbed for real-world computer-use agents. Microsoft PowerPoint is among the most widely adopted and feature-rich environments for presentation creation. We introduce PPT-Eval, a benchmark of 120 PowerPoint tasks across 12 files that cover both content creation and presentation editing scenarios, organized by difficulty. A central challenge in this domain is evaluation: tasks are complex, multimodal, and often admit many valid solutions. Moreover, today's agents frequently make only partial progress, which binary success metrics fail to capture. To address this, we design a robust evaluation framework to help create task-specific rubrics for PowerPoint tasks, taking inspiration from and building on past works for rubric-based evaluation. These rubrics award partial credit for intermediate steps, penalize unnecessary changes and poor aesthetics, and provide natural language feedback. This nuanced approach proves highly effective, achieving a Kendall's τ-b correlation of 0.77 with human judgments. We find that existing frontier agents still struggle with solving PowerPoint tasks, with strong models like Claude-4.5-Opus achieving only a 45% success rate and an average partial score of 57%. The benchmark is located at: https://microsoft.github.io/ppteval.
TheMCPCompany: Creating General-purpose Agents with Task-specific Tools
Oct 22, 2025Since the introduction of the Model Context Protocol (MCP), the number of available tools for Large Language Models (LLMs) has increased significantly. These task-specific tool sets offer an alternative to general-purpose tools such as web browsers, while being easier to develop and maintain than GUIs. However, current general-purpose agents predominantly rely on web browsers for interacting with the environment. Here, we introduce TheMCPCompany, a benchmark for evaluating tool-calling agents on tasks that involve interacting with various real-world services. We use the REST APIs of these services to create MCP servers, which include over 18,000 tools. We also provide manually annotated ground-truth tools for each task. In our experiments, we use the ground truth tools to show the potential of tool-calling agents for both improving performance and reducing costs assuming perfect tool retrieval. Next, we explore agent performance using tool retrieval to study the real-world practicality of tool-based agents. While all models with tool retrieval perform similarly or better than browser-based agents, smaller models cannot take full advantage of the available tools through retrieval. On the other hand, GPT-5's performance with tool retrieval is very close to its performance with ground-truth tools. Overall, our work shows that the most advanced reasoning models are effective at discovering tools in simpler environments, but seriously struggle with navigating complex enterprise environments. TheMCPCompany reveals that navigating tens of thousands of tools and combining them in non-trivial ways to solve complex problems is still a challenging task for current models and requires both better reasoning and better retrieval models.
Hummingbird: High Fidelity Image Generation via Multimodal Context Alignment
Feb 07, 2025



While diffusion models are powerful in generating high-quality, diverse synthetic data for object-centric tasks, existing methods struggle with scene-aware tasks such as Visual Question Answering (VQA) and Human-Object Interaction (HOI) Reasoning, where it is critical to preserve scene attributes in generated images consistent with a multimodal context, i.e. a reference image with accompanying text guidance query. To address this, we introduce Hummingbird, the first diffusion-based image generator which, given a multimodal context, generates highly diverse images w.r.t. the reference image while ensuring high fidelity by accurately preserving scene attributes, such as object interactions and spatial relationships from the text guidance. Hummingbird employs a novel Multimodal Context Evaluator that simultaneously optimizes our formulated Global Semantic and Fine-grained Consistency Rewards to ensure generated images preserve the scene attributes of reference images in relation to the text guidance while maintaining diversity. As the first model to address the task of maintaining both diversity and fidelity given a multimodal context, we introduce a new benchmark formulation incorporating MME Perception and Bongard HOI datasets. Benchmark experiments show Hummingbird outperforms all existing methods by achieving superior fidelity while maintaining diversity, validating Hummingbird's potential as a robust multimodal context-aligned image generator in complex visual tasks.
ScopeIt: Scoping Task Relevant Sentences in Documents
Feb 23, 2020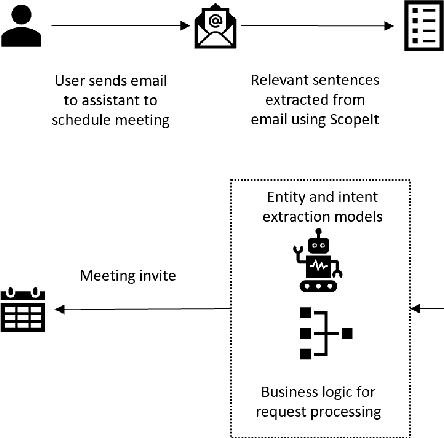

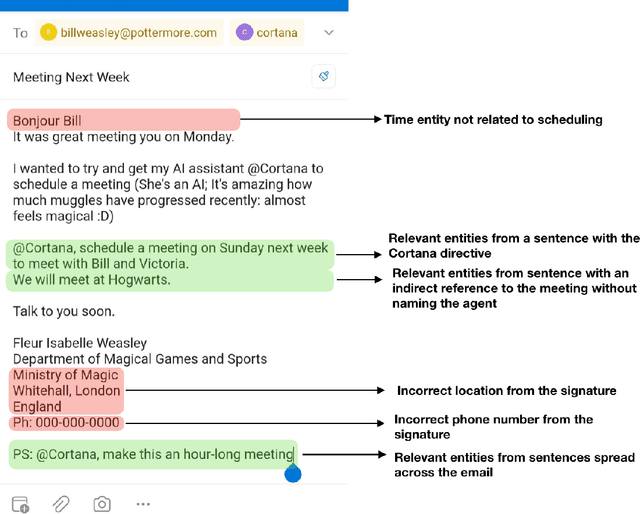
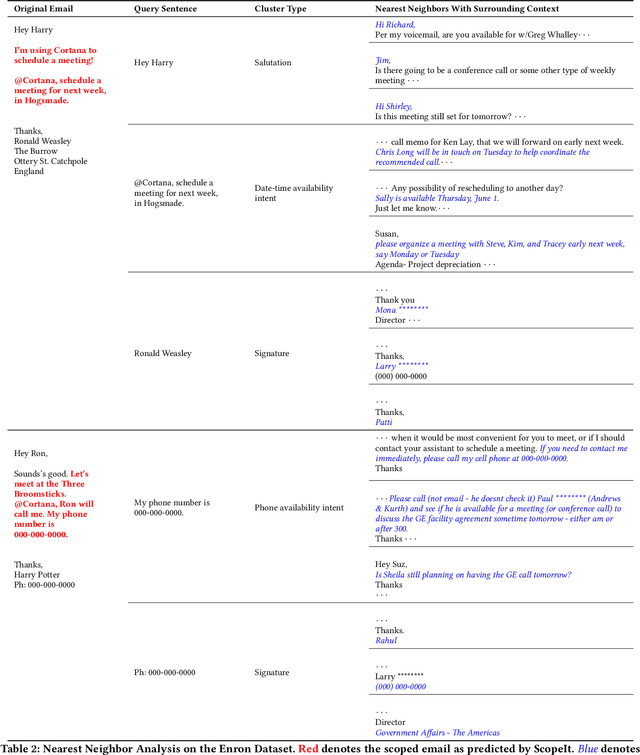
Intelligent assistants like Cortana, Siri, Alexa, and Google Assistant are trained to parse information when the conversation is synchronous and short; however, for email-based conversational agents, the communication is asynchronous, and often contains information irrelevant to the assistant. This makes it harder for the system to accurately detect intents, extract entities relevant to those intents and thereby perform the desired action. We present a neural model for scoping relevant information for the agent from a large query. We show that when used as a preprocessing step, the model improves performance of both intent detection and entity extraction tasks. We demonstrate the model's impact on Scheduler (Cortana is the persona of the agent, while Scheduler is the name of the service. We use them interchangeably in the context of this paper.) - a virtual conversational meeting scheduling assistant that interacts asynchronously with users through email. The model helps the entity extraction and intent detection tasks requisite by Scheduler achieve an average gain of 35% in precision without any drop in recall. Additionally, we demonstrate that the same approach can be used for component level analysis in large documents, such as signature block identification.