 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBridging the Domain Gaps in Context Representations for k-Nearest Neighbor Neural Machine Translation
May 26, 2023



$k$-Nearest neighbor machine translation ($k$NN-MT) has attracted increasing attention due to its ability to non-parametrically adapt to new translation domains. By using an upstream NMT model to traverse the downstream training corpus, it is equipped with a datastore containing vectorized key-value pairs, which are retrieved during inference to benefit translation. However, there often exists a significant gap between upstream and downstream domains, which hurts the retrieval accuracy and the final translation quality. To deal with this issue, we propose a novel approach to boost the datastore retrieval of $k$NN-MT by reconstructing the original datastore. Concretely, we design a reviser to revise the key representations, making them better fit for the downstream domain. The reviser is trained using the collected semantically-related key-queries pairs, and optimized by two proposed losses: one is the key-queries semantic distance ensuring each revised key representation is semantically related to its corresponding queries, and the other is an L2-norm loss encouraging revised key representations to effectively retain the knowledge learned by the upstream NMT model. Extensive experiments on domain adaptation tasks demonstrate that our method can effectively boost the datastore retrieval and translation quality of $k$NN-MT.\footnote{Our code is available at \url{https://github.com/DeepLearnXMU/RevisedKey-knn-mt}.}
From Statistical Methods to Deep Learning, Automatic Keyphrase Prediction: A Survey
May 04, 2023



Keyphrase prediction aims to generate phrases (keyphrases) that highly summarizes a given document. Recently, researchers have conducted in-depth studies on this task from various perspectives. In this paper, we comprehensively summarize representative studies from the perspectives of dominant models, datasets and evaluation metrics. Our work analyzes up to 167 previous works, achieving greater coverage of this task than previous surveys. Particularly, we focus highly on deep learning-based keyphrase prediction, which attracts increasing attention of this task in recent years. Afterwards, we conduct several groups of experiments to carefully compare representative models. To the best of our knowledge, our work is the first attempt to compare these models using the identical commonly-used datasets and evaluation metric, facilitating in-depth analyses of their disadvantages and advantages. Finally, we discuss the possible research directions of this task in the future.
Towards Fine-Grained Information: Identifying the Type and Location of Translation Errors
Feb 17, 2023Fine-grained information on translation errors is helpful for the translation evaluation community. Existing approaches can not synchronously consider error position and type, failing to integrate the error information of both. In this paper, we propose Fine-Grained Translation Error Detection (FG-TED) task, aiming at identifying both the position and the type of translation errors on given source-hypothesis sentence pairs. Besides, we build an FG-TED model to predict the \textbf{addition} and \textbf{omission} errors -- two typical translation accuracy errors. First, we use a word-level classification paradigm to form our model and use the shortcut learning reduction to relieve the influence of monolingual features. Besides, we construct synthetic datasets for model training, and relieve the disagreement of data labeling in authoritative datasets, making the experimental benchmark concordant. Experiments show that our model can identify both error type and position concurrently, and gives state-of-the-art results on the restored dataset. Our model also delivers more reliable predictions on low-resource and transfer scenarios than existing baselines. The related datasets and the source code will be released in the future.
Competency-Aware Neural Machine Translation: Can Machine Translation Know its Own Translation Quality?
Nov 25, 2022



Neural machine translation (NMT) is often criticized for failures that happen without awareness. The lack of competency awareness makes NMT untrustworthy. This is in sharp contrast to human translators who give feedback or conduct further investigations whenever they are in doubt about predictions. To fill this gap, we propose a novel competency-aware NMT by extending conventional NMT with a self-estimator, offering abilities to translate a source sentence and estimate its competency. The self-estimator encodes the information of the decoding procedure and then examines whether it can reconstruct the original semantics of the source sentence. Experimental results on four translation tasks demonstrate that the proposed method not only carries out translation tasks intact but also delivers outstanding performance on quality estimation. Without depending on any reference or annotated data typically required by state-of-the-art metric and quality estimation methods, our model yields an even higher correlation with human quality judgments than a variety of aforementioned methods, such as BLEURT, COMET, and BERTScore. Quantitative and qualitative analyses show better robustness of competency awareness in our model.
WR-ONE2SET: Towards Well-Calibrated Keyphrase Generation
Nov 13, 2022



Keyphrase generation aims to automatically generate short phrases summarizing an input document. The recently emerged ONE2SET paradigm (Ye et al., 2021) generates keyphrases as a set and has achieved competitive performance. Nevertheless, we observe serious calibration errors outputted by ONE2SET, especially in the over-estimation of $\varnothing$ token (means "no corresponding keyphrase"). In this paper, we deeply analyze this limitation and identify two main reasons behind: 1) the parallel generation has to introduce excessive $\varnothing$ as padding tokens into training instances; and 2) the training mechanism assigning target to each slot is unstable and further aggravates the $\varnothing$ token over-estimation. To make the model well-calibrated, we propose WR-ONE2SET which extends ONE2SET with an adaptive instance-level cost Weighting strategy and a target Re-assignment mechanism. The former dynamically penalizes the over-estimated slots for different instances thus smoothing the uneven training distribution. The latter refines the original inappropriate assignment and reduces the supervisory signals of over-estimated slots. Experimental results on commonly-used datasets demonstrate the effectiveness and generality of our proposed paradigm.
Alibaba-Translate China's Submission for WMT 2022 Quality Estimation Shared Task
Oct 18, 2022


In this paper, we present our submission to the sentence-level MQM benchmark at Quality Estimation Shared Task, named UniTE (Unified Translation Evaluation). Specifically, our systems employ the framework of UniTE, which combined three types of input formats during training with a pre-trained language model. First, we apply the pseudo-labeled data examples for the continuously pre-training phase. Notably, to reduce the gap between pre-training and fine-tuning, we use data pruning and a ranking-based score normalization strategy. For the fine-tuning phase, we use both Direct Assessment (DA) and Multidimensional Quality Metrics (MQM) data from past years' WMT competitions. Finally, we collect the source-only evaluation results, and ensemble the predictions generated by two UniTE models, whose backbones are XLM-R and InfoXLM, respectively. Results show that our models reach 1st overall ranking in the Multilingual and English-Russian settings, and 2nd overall ranking in English-German and Chinese-English settings, showing relatively strong performances in this year's quality estimation competition.
Alibaba-Translate China's Submission for WMT 2022 Metrics Shared Task
Oct 18, 2022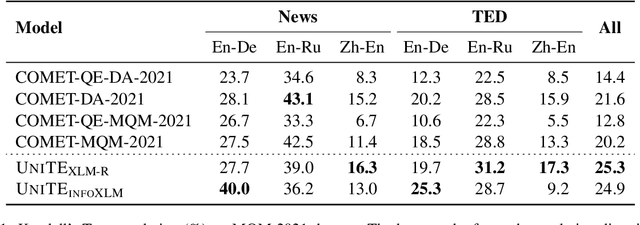
In this report, we present our submission to the WMT 2022 Metrics Shared Task. We build our system based on the core idea of UNITE (Unified Translation Evaluation), which unifies source-only, reference-only, and source-reference-combined evaluation scenarios into one single model. Specifically, during the model pre-training phase, we first apply the pseudo-labeled data examples to continuously pre-train UNITE. Notably, to reduce the gap between pre-training and fine-tuning, we use data cropping and a ranking-based score normalization strategy. During the fine-tuning phase, we use both Direct Assessment (DA) and Multidimensional Quality Metrics (MQM) data from past years' WMT competitions. Specially, we collect the results from models with different pre-trained language model backbones, and use different ensembling strategies for involved translation directions.
Draft, Command, and Edit: Controllable Text Editing in E-Commerce
Aug 11, 2022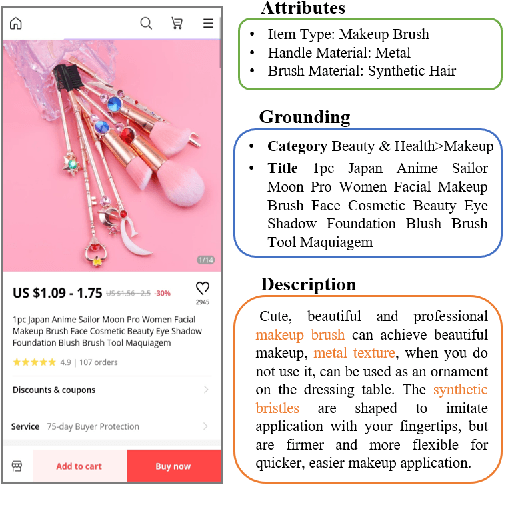
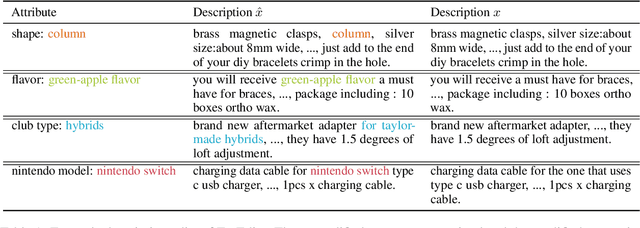
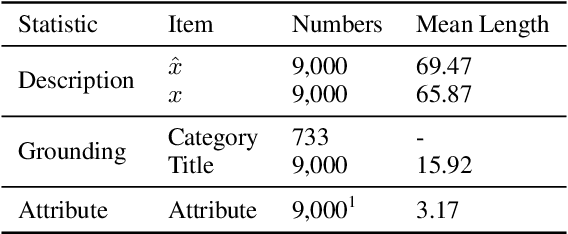
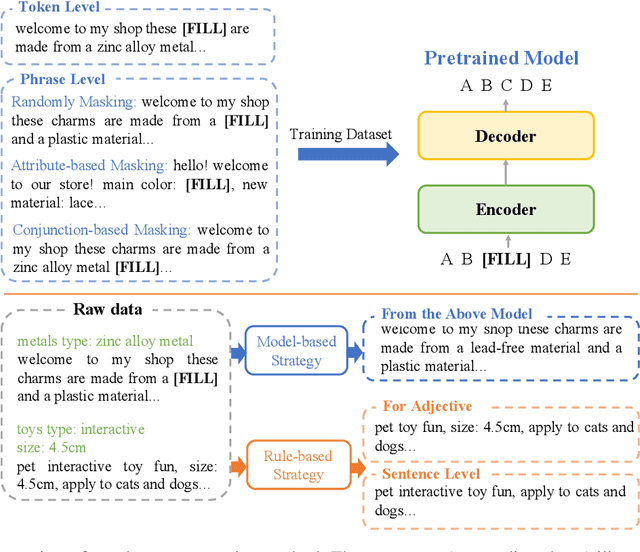
Product description generation is a challenging and under-explored task. Most such work takes a set of product attributes as inputs then generates a description from scratch in a single pass. However, this widespread paradigm might be limited when facing the dynamic wishes of users on constraining the description, such as deleting or adding the content of a user-specified attribute based on the previous version. To address this challenge, we explore a new draft-command-edit manner in description generation, leading to the proposed new task-controllable text editing in E-commerce. More specifically, we allow systems to receive a command (deleting or adding) from the user and then generate a description by flexibly modifying the content based on the previous version. It is easier and more practical to meet the new needs by modifying previous versions than generating from scratch. Furthermore, we design a data augmentation method to remedy the low resource challenge in this task, which contains a model-based and a rule-based strategy to imitate the edit by humans. To accompany this new task, we present a human-written draft-command-edit dataset called E-cEdits and a new metric "Attribute Edit". Our experimental results show that using the new data augmentation method outperforms baselines to a greater extent in both automatic and human evaluations.
Should We Rely on Entity Mentions for Relation Extraction? Debiasing Relation Extraction with Counterfactual Analysis
May 08, 2022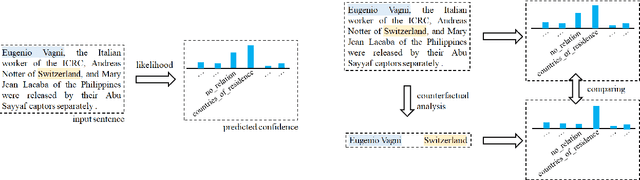
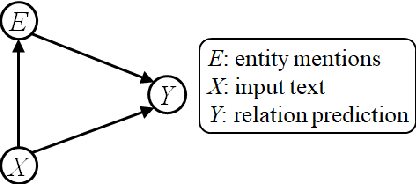
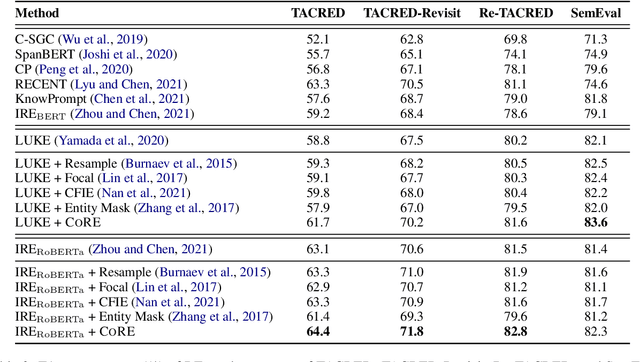
Recent literature focuses on utilizing the entity information in the sentence-level relation extraction (RE), but this risks leaking superficial and spurious clues of relations. As a result, RE still suffers from unintended entity bias, i.e., the spurious correlation between entity mentions (names) and relations. Entity bias can mislead the RE models to extract the relations that do not exist in the text. To combat this issue, some previous work masks the entity mentions to prevent the RE models from overfitting entity mentions. However, this strategy degrades the RE performance because it loses the semantic information of entities. In this paper, we propose the CORE (Counterfactual Analysis based Relation Extraction) debiasing method that guides the RE models to focus on the main effects of textual context without losing the entity information. We first construct a causal graph for RE, which models the dependencies between variables in RE models. Then, we propose to conduct counterfactual analysis on our causal graph to distill and mitigate the entity bias, that captures the causal effects of specific entity mentions in each instance. Note that our CORE method is model-agnostic to debias existing RE systems during inference without changing their training processes. Extensive experimental results demonstrate that our CORE yields significant gains on both effectiveness and generalization for RE. The source code is provided at: https://github.com/vanoracai/CoRE.
Dangling-Aware Entity Alignment with Mixed High-Order Proximities
May 05, 2022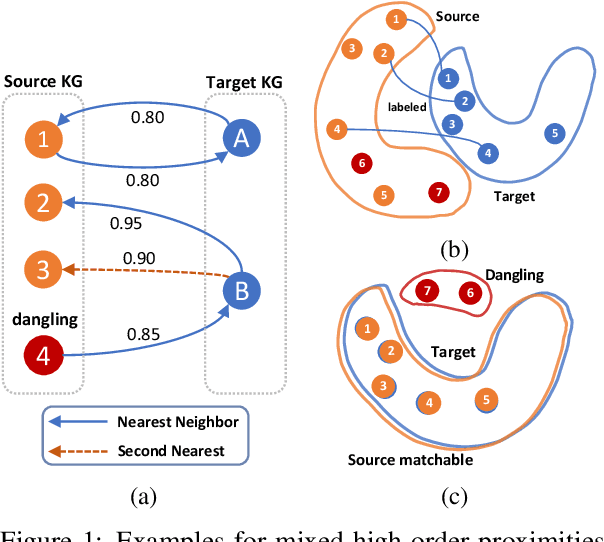

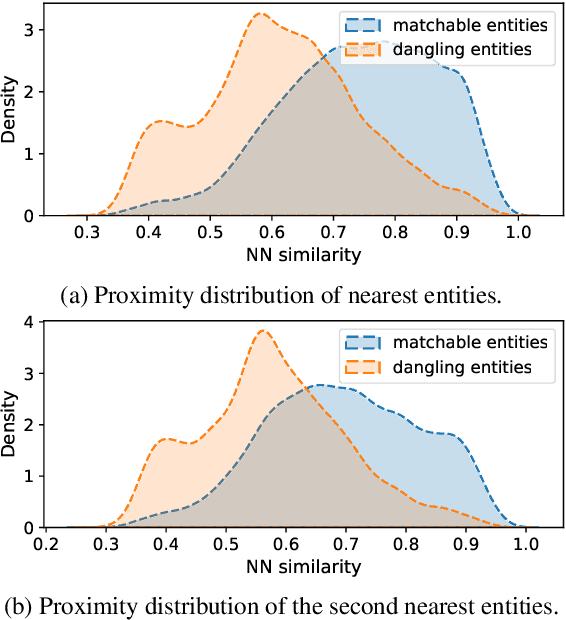

We study dangling-aware entity alignment in knowledge graphs (KGs), which is an underexplored but important problem. As different KGs are naturally constructed by different sets of entities, a KG commonly contains some dangling entities that cannot find counterparts in other KGs. Therefore, dangling-aware entity alignment is more realistic than the conventional entity alignment where prior studies simply ignore dangling entities. We propose a framework using mixed high-order proximities on dangling-aware entity alignment. Our framework utilizes both the local high-order proximity in a nearest neighbor subgraph and the global high-order proximity in an embedding space for both dangling detection and entity alignment. Extensive experiments with two evaluation settings shows that our framework more precisely detects dangling entities, and better aligns matchable entities. Further investigations demonstrate that our framework can mitigate the hubness problem on dangling-aware entity alignment.