 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDeepABM: Scalable, efficient and differentiable agent-based simulations via graph neural networks
Oct 09, 2021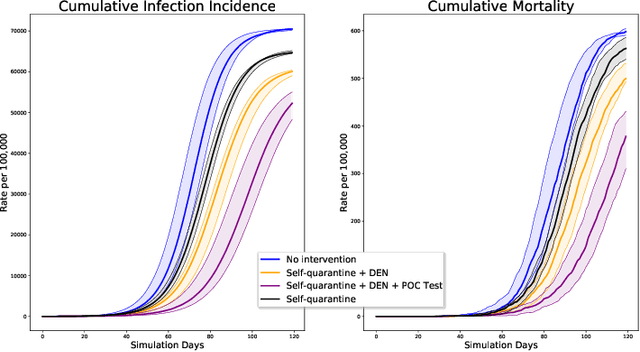

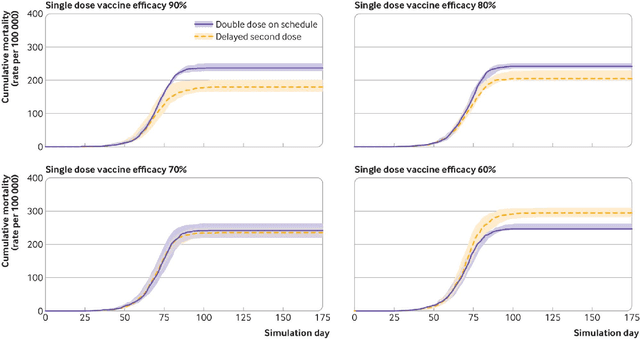
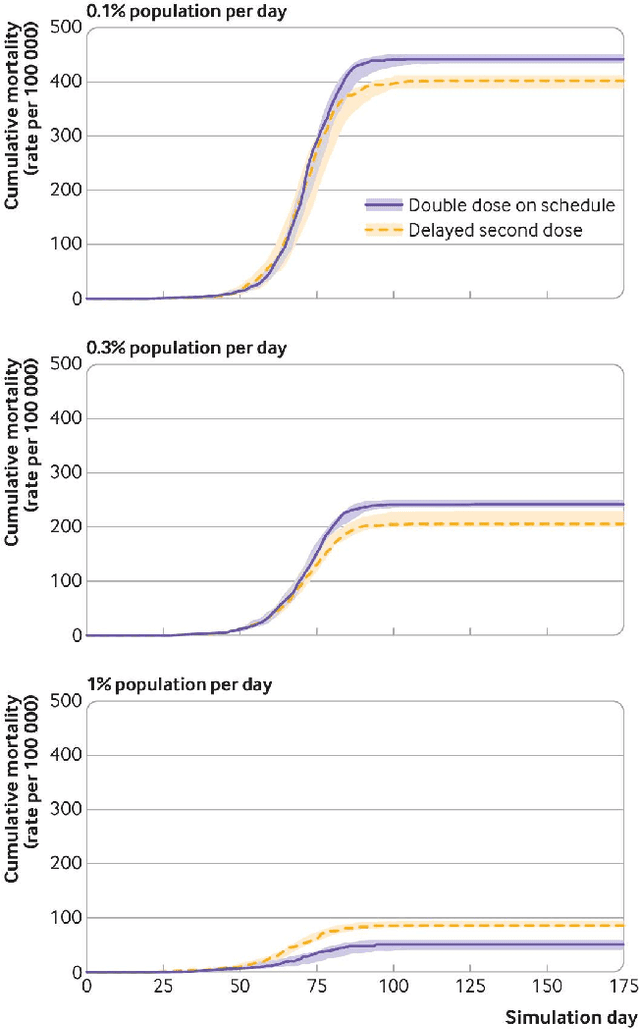
We introduce DeepABM, a framework for agent-based modeling that leverages geometric message passing of graph neural networks for simulating action and interactions over large agent populations. Using DeepABM allows scaling simulations to large agent populations in real-time and running them efficiently on GPU architectures. To demonstrate the effectiveness of DeepABM, we build DeepABM-COVID simulator to provide support for various non-pharmaceutical interventions (quarantine, exposure notification, vaccination, testing) for the COVID-19 pandemic, and can scale to populations of representative size in real-time on a GPU. Specifically, DeepABM-COVID can model 200 million interactions (over 100,000 agents across 180 time-steps) in 90 seconds, and is made available online to help researchers with modeling and analysis of various interventions. We explain various components of the framework and discuss results from one research study to evaluate the impact of delaying the second dose of the COVID-19 vaccine in collaboration with clinical and public health experts. While we simulate COVID-19 spread, the ideas introduced in the paper are generic and can be easily extend to other forms of agent-based simulations. Furthermore, while beyond scope of this document, DeepABM enables inverse agent-based simulations which can be used to learn physical parameters in the (micro) simulations using gradient-based optimization with large-scale real-world (macro) data. We are optimistic that the current work can have interesting implications for bringing ABM and AI communities closer.
MINIMAL: Mining Models for Data Free Universal Adversarial Triggers
Sep 25, 2021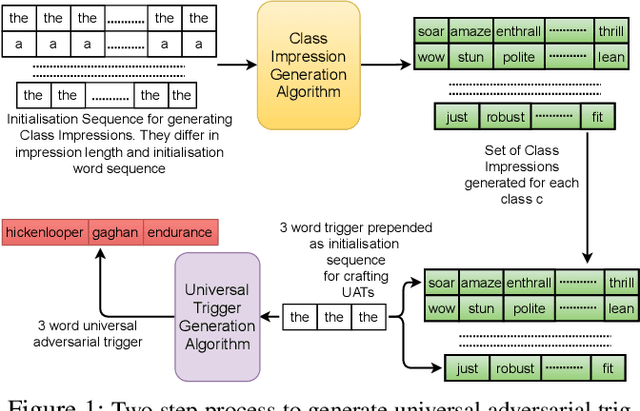
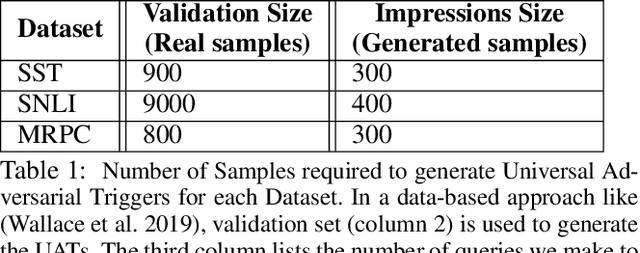
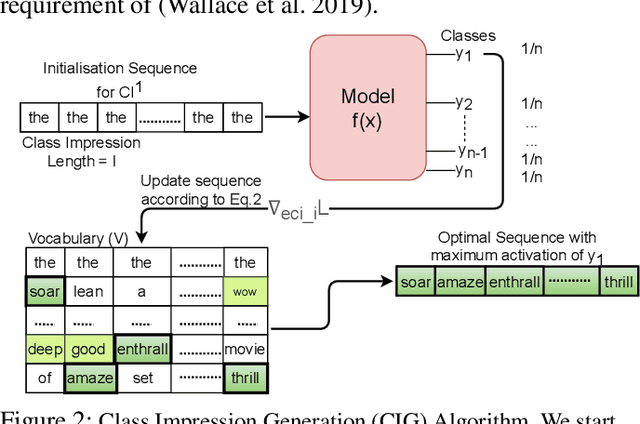
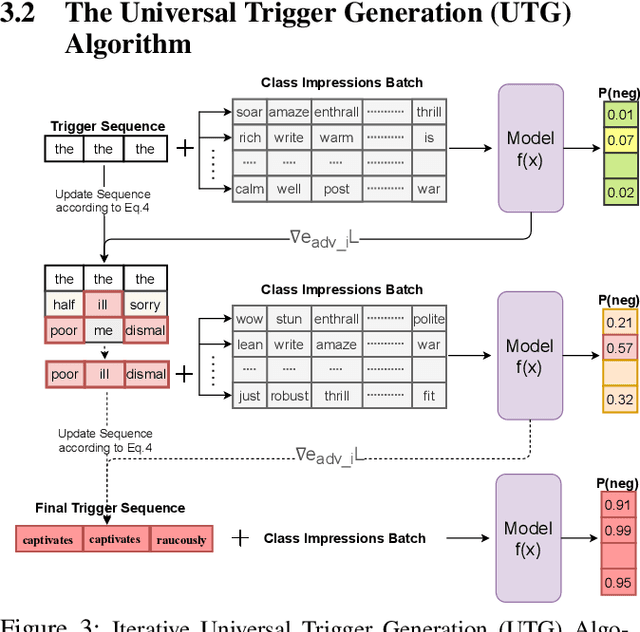
It is well known that natural language models are vulnerable to adversarial attacks, which are mostly input-specific in nature. Recently, it has been shown that there also exist input-agnostic attacks in NLP models, called universal adversarial triggers. However, existing methods to craft universal triggers are data intensive. They require large amounts of data samples to generate adversarial triggers, which are typically inaccessible by attackers. For instance, previous works take 3000 data samples per class for the SNLI dataset to generate adversarial triggers. In this paper, we present a novel data-free approach, MINIMAL, to mine input-agnostic adversarial triggers from models. Using the triggers produced with our data-free algorithm, we reduce the accuracy of Stanford Sentiment Treebank's positive class from 93.6% to 9.6%. Similarly, for the Stanford Natural Language Inference (SNLI), our single-word trigger reduces the accuracy of the entailment class from 90.95% to less than 0.6\%. Despite being completely data-free, we get equivalent accuracy drops as data-dependent methods.
ZFlow: Gated Appearance Flow-based Virtual Try-on with 3D Priors
Sep 14, 2021
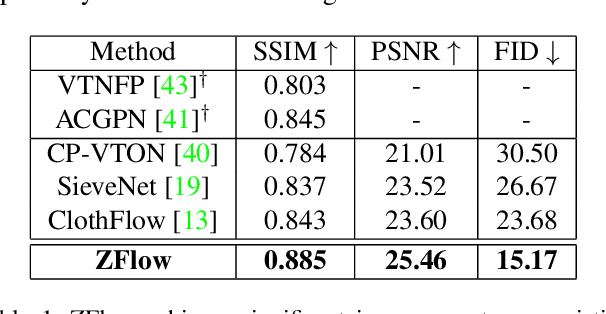
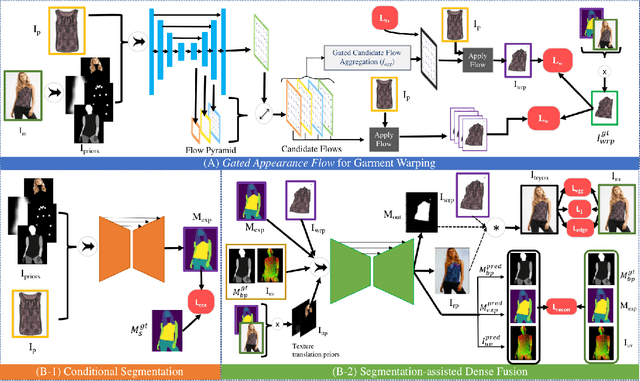
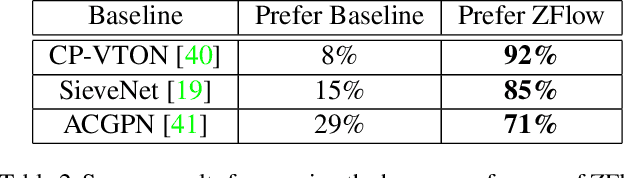
Image-based virtual try-on involves synthesizing perceptually convincing images of a model wearing a particular garment and has garnered significant research interest due to its immense practical applicability. Recent methods involve a two stage process: i) warping of the garment to align with the model ii) texture fusion of the warped garment and target model to generate the try-on output. Issues arise due to the non-rigid nature of garments and the lack of geometric information about the model or the garment. It often results in improper rendering of granular details. We propose ZFlow, an end-to-end framework, which seeks to alleviate these concerns regarding geometric and textural integrity (such as pose, depth-ordering, skin and neckline reproduction) through a combination of gated aggregation of hierarchical flow estimates termed Gated Appearance Flow, and dense structural priors at various stage of the network. ZFlow achieves state-of-the-art results as observed qualitatively, and on quantitative benchmarks of image quality (PSNR, SSIM, and FID). The paper presents extensive comparisons with other existing solutions including a detailed user study and ablation studies to gauge the effect of each of our contributions on multiple datasets.
Video2Skill: Adapting Events in Demonstration Videos to Skills in an Environment using Cyclic MDP Homomorphisms
Sep 09, 2021
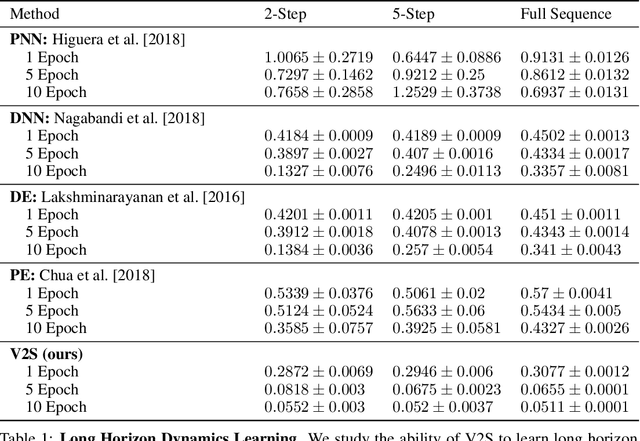
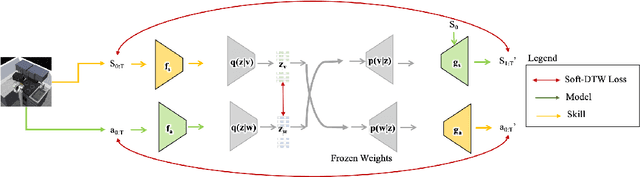
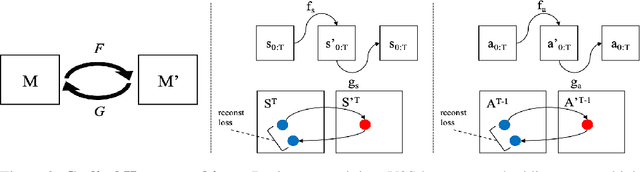
Humans excel at learning long-horizon tasks from demonstrations augmented with textual commentary, as evidenced by the burgeoning popularity of tutorial videos online. Intuitively, this capability can be separated into 2 distinct subtasks - first, dividing a long-horizon demonstration sequence into semantically meaningful events; second, adapting such events into meaningful behaviors in one's own environment. Here, we present Video2Skill (V2S), which attempts to extend this capability to artificial agents by allowing a robot arm to learn from human cooking videos. We first use sequence-to-sequence Auto-Encoder style architectures to learn a temporal latent space for events in long-horizon demonstrations. We then transfer these representations to the robotic target domain, using a small amount of offline and unrelated interaction data (sequences of state-action pairs of the robot arm controlled by an expert) to adapt these events into actionable representations, i.e., skills. Through experiments, we demonstrate that our approach results in self-supervised analogy learning, where the agent learns to draw analogies between motions in human demonstration data and behaviors in the robotic environment. We also demonstrate the efficacy of our approach on model learning - demonstrating how Video2Skill utilizes prior knowledge from human demonstration to outperform traditional model learning of long-horizon dynamics. Finally, we demonstrate the utility of our approach for non-tabula rasa decision-making, i.e, utilizing video demonstration for zero-shot skill generation.
Speaker-Conditioned Hierarchical Modeling for Automated Speech Scoring
Aug 30, 2021
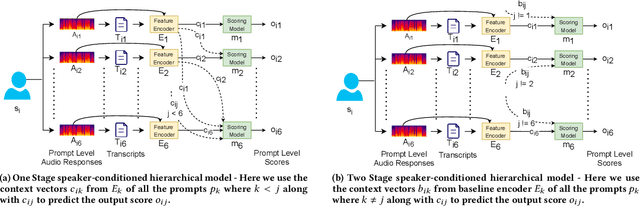

Automatic Speech Scoring (ASS) is the computer-assisted evaluation of a candidate's speaking proficiency in a language. ASS systems face many challenges like open grammar, variable pronunciations, and unstructured or semi-structured content. Recent deep learning approaches have shown some promise in this domain. However, most of these approaches focus on extracting features from a single audio, making them suffer from the lack of speaker-specific context required to model such a complex task. We propose a novel deep learning technique for non-native ASS, called speaker-conditioned hierarchical modeling. In our technique, we take advantage of the fact that oral proficiency tests rate multiple responses for a candidate. We extract context vectors from these responses and feed them as additional speaker-specific context to our network to score a particular response. We compare our technique with strong baselines and find that such modeling improves the model's average performance by 6.92% (maximum = 12.86%, minimum = 4.51%). We further show both quantitative and qualitative insights into the importance of this additional context in solving the problem of ASS.
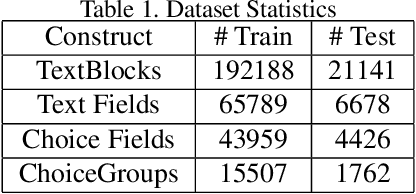
Form2Seq : A Framework for Higher-Order Form Structure Extraction
Jul 09, 2021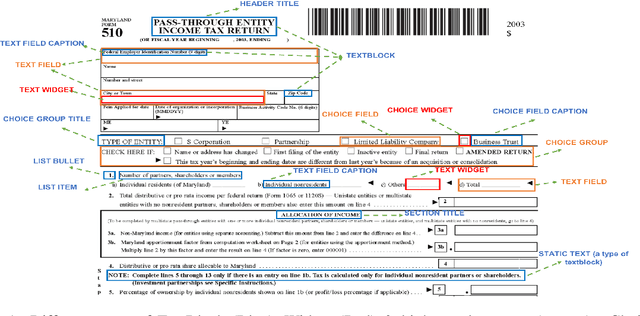
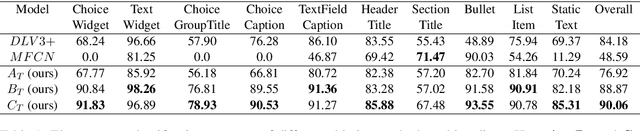
Document structure extraction has been a widely researched area for decades with recent works performing it as a semantic segmentation task over document images using fully-convolution networks. Such methods are limited by image resolution due to which they fail to disambiguate structures in dense regions which appear commonly in forms. To mitigate this, we propose Form2Seq, a novel sequence-to-sequence (Seq2Seq) inspired framework for structure extraction using text, with a specific focus on forms, which leverages relative spatial arrangement of structures. We discuss two tasks; 1) Classification of low-level constituent elements (TextBlock and empty fillable Widget) into ten types such as field captions, list items, and others; 2) Grouping lower-level elements into higher-order constructs, such as Text Fields, ChoiceFields and ChoiceGroups, used as information collection mechanism in forms. To achieve this, we arrange the constituent elements linearly in natural reading order, feed their spatial and textual representations to Seq2Seq framework, which sequentially outputs prediction of each element depending on the final task. We modify Seq2Seq for grouping task and discuss improvements obtained through cascaded end-to-end training of two tasks versus training in isolation. Experimental results show the effectiveness of our text-based approach achieving an accuracy of 90% on classification task and an F1 of 75.82, 86.01, 61.63 on groups discussed above respectively, outperforming segmentation baselines. Further we show our framework achieves state of the results for table structure recognition on ICDAR 2013 dataset.
Multi-Modal Association based Grouping for Form Structure Extraction
Jul 09, 2021

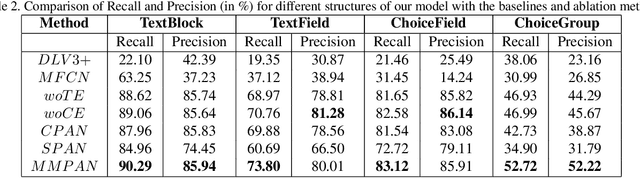
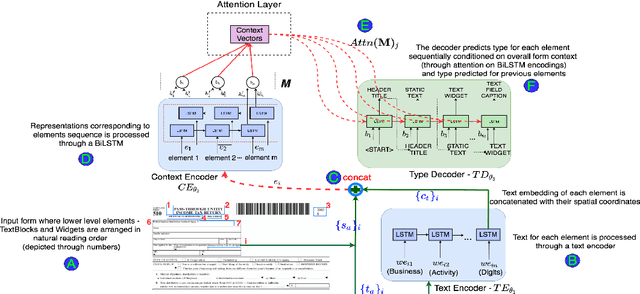
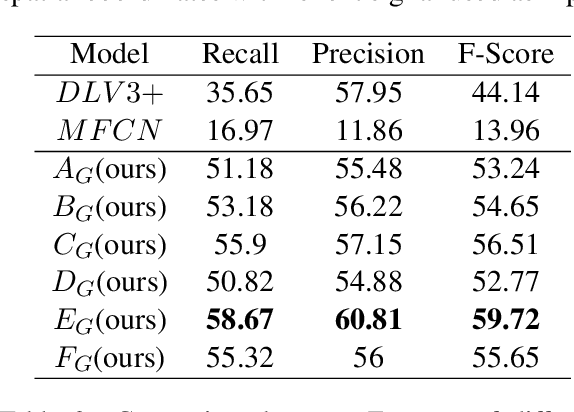
Document structure extraction has been a widely researched area for decades. Recent work in this direction has been deep learning-based, mostly focusing on extracting structure using fully convolution NN through semantic segmentation. In this work, we present a novel multi-modal approach for form structure extraction. Given simple elements such as textruns and widgets, we extract higher-order structures such as TextBlocks, Text Fields, Choice Fields, and Choice Groups, which are essential for information collection in forms. To achieve this, we obtain a local image patch around each low-level element (reference) by identifying candidate elements closest to it. We process textual and spatial representation of candidates sequentially through a BiLSTM to obtain context-aware representations and fuse them with image patch features obtained by processing it through a CNN. Subsequently, the sequential decoder takes this fused feature vector to predict the association type between reference and candidates. These predicted associations are utilized to determine larger structures through connected components analysis. Experimental results show the effectiveness of our approach achieving a recall of 90.29%, 73.80%, 83.12%, and 52.72% for the above structures, respectively, outperforming semantic segmentation baselines significantly. We show the efficacy of our method through ablations, comparing it against using individual modalities. We also introduce our new rich human-annotated Forms Dataset.
Information-theoretic Evolution of Model Agnostic Global Explanations
May 14, 2021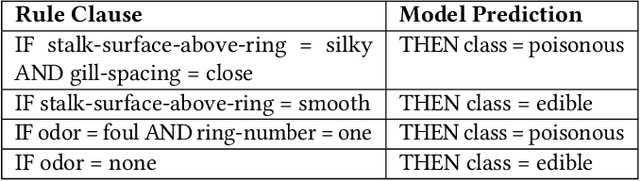
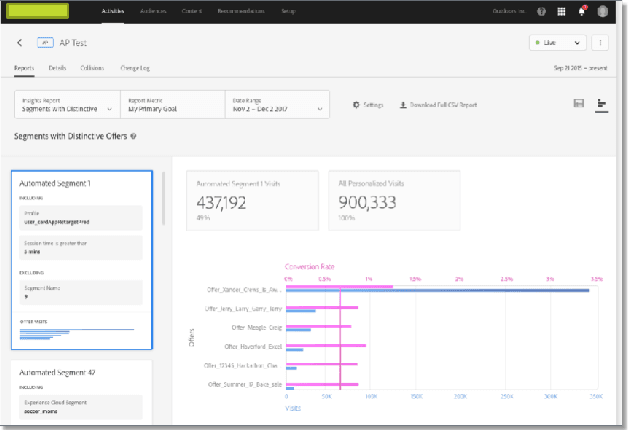
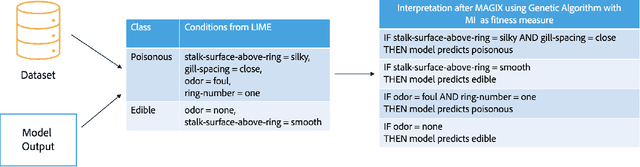
Explaining the behavior of black box machine learning models through human interpretable rules is an important research area. Recent work has focused on explaining model behavior locally i.e. for specific predictions as well as globally across the fields of vision, natural language, reinforcement learning and data science. We present a novel model-agnostic approach that derives rules to globally explain the behavior of classification models trained on numerical and/or categorical data. Our approach builds on top of existing local model explanation methods to extract conditions important for explaining model behavior for specific instances followed by an evolutionary algorithm that optimizes an information theory based fitness function to construct rules that explain global model behavior. We show how our approach outperforms existing approaches on a variety of datasets. Further, we introduce a parameter to evaluate the quality of interpretation under the scenario of distributional shift. This parameter evaluates how well the interpretation can predict model behavior for previously unseen data distributions. We show how existing approaches for interpreting models globally lack distributional robustness. Finally, we show how the quality of the interpretation can be improved under the scenario of distributional shift by adding out of distribution samples to the dataset used to learn the interpretation and thereby, increase robustness. All of the datasets used in our paper are open and publicly available. Our approach has been deployed in a leading digital marketing suite of products.
Data Instance Prior for Transfer Learning in GANs
Dec 08, 2020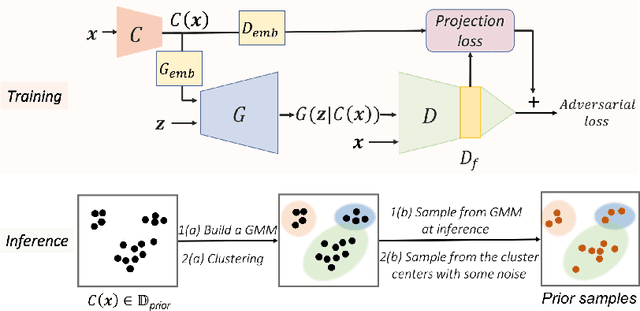
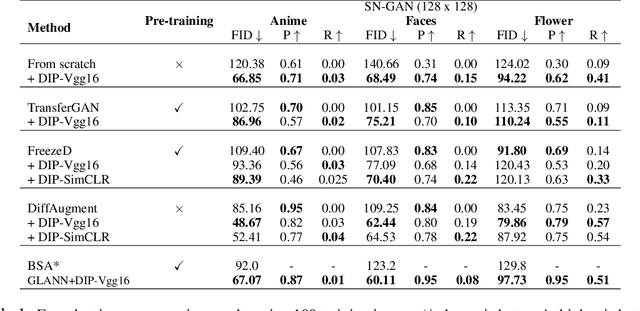
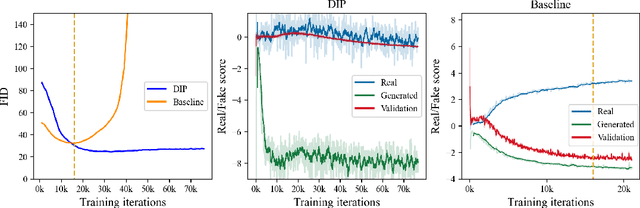
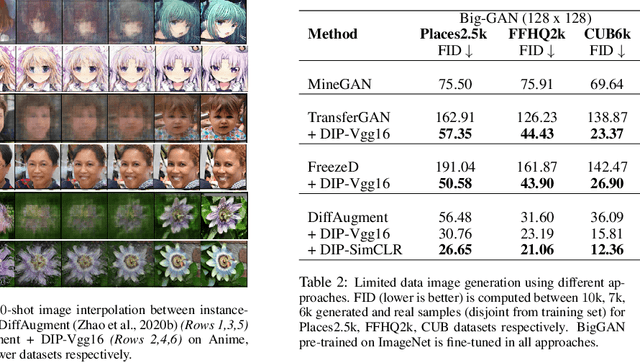
Recent advances in generative adversarial networks (GANs) have shown remarkable progress in generating high-quality images. However, this gain in performance depends on the availability of a large amount of training data. In limited data regimes, training typically diverges, and therefore the generated samples are of low quality and lack diversity. Previous works have addressed training in low data setting by leveraging transfer learning and data augmentation techniques. We propose a novel transfer learning method for GANs in the limited data domain by leveraging informative data prior derived from self-supervised/supervised pre-trained networks trained on a diverse source domain. We perform experiments on several standard vision datasets using various GAN architectures (BigGAN, SNGAN, StyleGAN2) to demonstrate that the proposed method effectively transfers knowledge to domains with few target images, outperforming existing state-of-the-art techniques in terms of image quality and diversity. We also show the utility of data instance prior in large-scale unconditional image generation and image editing tasks.
TAN-NTM: Topic Attention Networks for Neural Topic Modeling
Dec 02, 2020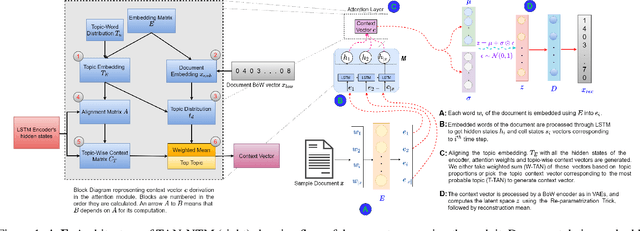
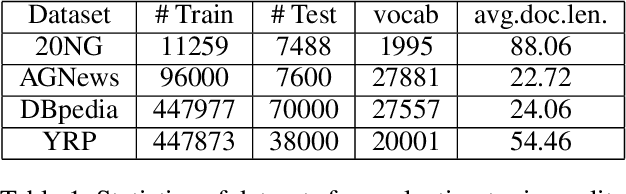
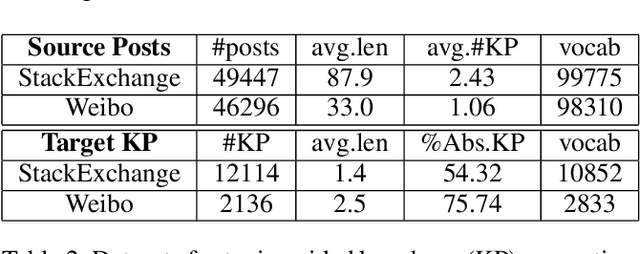

Topic models have been widely used to learn representations from text and gain insight into document corpora. To perform topic discovery, existing neural models use document bag-of-words (BoW) representation as input followed by variational inference and learn topic-word distribution through reconstructing BoW. Such methods have mainly focused on analysing the effect of enforcing suitable priors on document distribution. However, little importance has been given to encoding improved document features for capturing document semantics better. In this work, we propose a novel framework: TAN-NTM which models document as a sequence of tokens instead of BoW at the input layer and processes it through an LSTM whose output is used to perform variational inference followed by BoW decoding. We apply attention on LSTM outputs to empower the model to attend on relevant words which convey topic related cues. We hypothesise that attention can be performed effectively if done in a topic guided manner and establish this empirically through ablations. We factor in topic-word distribution to perform topic aware attention achieving state-of-the-art results with ~9-15 percentage improvement over score of existing SOTA topic models in NPMI coherence metric on four benchmark datasets - 20NewsGroup, Yelp, AGNews, DBpedia. TAN-NTM also obtains better document classification accuracy owing to learning improved document-topic features. We qualitatively discuss that attention mechanism enables unsupervised discovery of keywords. Motivated by this, we further show that our proposed framework achieves state-of-the-art performance on topic aware supervised generation of keyphrases on StackExchange and Weibo datasets.