 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePlaying Devil's Advocate: Off-the-Shelf Persona Vectors Rival Targeted Steering for Sycophancy
May 20, 2026We study the effect of different persona on \textbf{sycophancy}: model's agreement with users even when the user is incorrect. The standard mitigation, Contrastive Activation Addition (CAA), derives a steering direction from labelled pairs of sycophantic and honest responses. This study evaluates whether off-the-shelf persona steering vectors, originally developed for general role-playing and not trained on sycophancy data, can serve as an alternative. In two instruction-tuned models, steering toward personas characterised by doubt or scrutiny reduces sycophancy to approximately $68\%$ and $98\%$ of CAA's effect, and, unlike CAA, maintains accuracy when the user is correct. The effect is also asymmetric: steering toward agreeable personas does not produce a mirror increase in sycophancy. Geometrically, the persona vector is largely independent of the direction of sycophancy in activation space. Collectively, these findings suggest that sycophancy is better understood as a persona-level property rather than a single steerable direction. We release our code here: https://anonymous.4open.science/r/Sycophancy-Steering-9DF0/.
InversionView: A General-Purpose Method for Reading Information from Neural Activations
May 27, 2024



The inner workings of neural networks can be better understood if we can fully decipher the information encoded in neural activations. In this paper, we argue that this information is embodied by the subset of inputs that give rise to similar activations. Computing such subsets is nontrivial as the input space is exponentially large. We propose InversionView, which allows us to practically inspect this subset by sampling from a trained decoder model conditioned on activations. This helps uncover the information content of activation vectors, and facilitates understanding of the algorithms implemented by transformer models. We present three case studies where we investigate models ranging from small transformers to GPT-2. In these studies, we demonstrate the characteristics of our method, show the distinctive advantages it offers, and provide causally verified circuits.
Learning Syntax Without Planting Trees: Understanding When and Why Transformers Generalize Hierarchically
Apr 25, 2024Transformers trained on natural language data have been shown to learn its hierarchical structure and generalize to sentences with unseen syntactic structures without explicitly encoding any structural bias. In this work, we investigate sources of inductive bias in transformer models and their training that could cause such generalization behavior to emerge. We extensively experiment with transformer models trained on multiple synthetic datasets and with different training objectives and show that while other objectives e.g. sequence-to-sequence modeling, prefix language modeling, often failed to lead to hierarchical generalization, models trained with the language modeling objective consistently learned to generalize hierarchically. We then conduct pruning experiments to study how transformers trained with the language modeling objective encode hierarchical structure. When pruned, we find joint existence of subnetworks within the model with different generalization behaviors (subnetworks corresponding to hierarchical structure and linear order). Finally, we take a Bayesian perspective to further uncover transformers' preference for hierarchical generalization: We establish a correlation between whether transformers generalize hierarchically on a dataset and whether the simplest explanation of that dataset is provided by a hierarchical grammar compared to regular grammars exhibiting linear generalization.
In-Context Learning through the Bayesian Prism
Jun 08, 2023



In-context learning is one of the surprising and useful features of large language models. How it works is an active area of research. Recently, stylized meta-learning-like setups have been devised that train these models on a sequence of input-output pairs $(x, f(x))$ from a function class using the language modeling loss and observe generalization to unseen functions from the same class. One of the main discoveries in this line of research has been that for several problems such as linear regression, trained transformers learn algorithms for learning functions in context. However, the inductive biases of these models resulting in this behavior are not clearly understood. A model with unlimited training data and compute is a Bayesian predictor: it learns the pretraining distribution. It has been shown that high-capacity transformers mimic the Bayesian predictor for linear regression. In this paper, we show empirical evidence of transformers exhibiting the behavior of this ideal learner across different linear and non-linear function classes. We also extend the previous setups to work in the multitask setting and verify that transformers can do in-context learning in this setup as well and the Bayesian perspective sheds light on this setting also. Finally, via the example of learning Fourier series, we study the inductive bias for in-context learning. We find that in-context learning may or may not have simplicity bias depending on the pretraining data distribution.
TAN-NTM: Topic Attention Networks for Neural Topic Modeling
Dec 02, 2020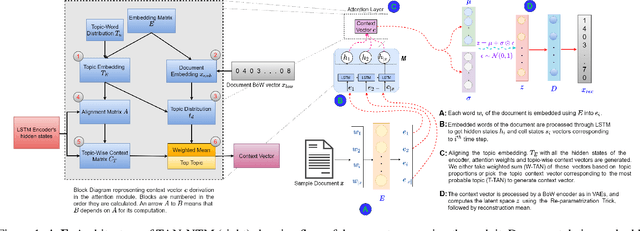
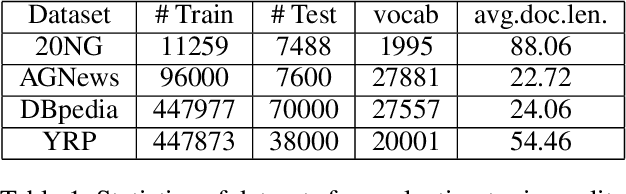
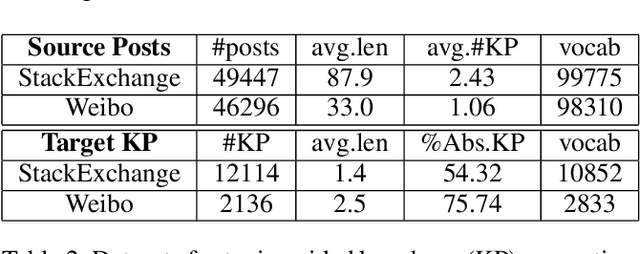

Topic models have been widely used to learn representations from text and gain insight into document corpora. To perform topic discovery, existing neural models use document bag-of-words (BoW) representation as input followed by variational inference and learn topic-word distribution through reconstructing BoW. Such methods have mainly focused on analysing the effect of enforcing suitable priors on document distribution. However, little importance has been given to encoding improved document features for capturing document semantics better. In this work, we propose a novel framework: TAN-NTM which models document as a sequence of tokens instead of BoW at the input layer and processes it through an LSTM whose output is used to perform variational inference followed by BoW decoding. We apply attention on LSTM outputs to empower the model to attend on relevant words which convey topic related cues. We hypothesise that attention can be performed effectively if done in a topic guided manner and establish this empirically through ablations. We factor in topic-word distribution to perform topic aware attention achieving state-of-the-art results with ~9-15 percentage improvement over score of existing SOTA topic models in NPMI coherence metric on four benchmark datasets - 20NewsGroup, Yelp, AGNews, DBpedia. TAN-NTM also obtains better document classification accuracy owing to learning improved document-topic features. We qualitatively discuss that attention mechanism enables unsupervised discovery of keywords. Motivated by this, we further show that our proposed framework achieves state-of-the-art performance on topic aware supervised generation of keyphrases on StackExchange and Weibo datasets.