 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNeuDep: Neural Binary Memory Dependence Analysis
Oct 04, 2022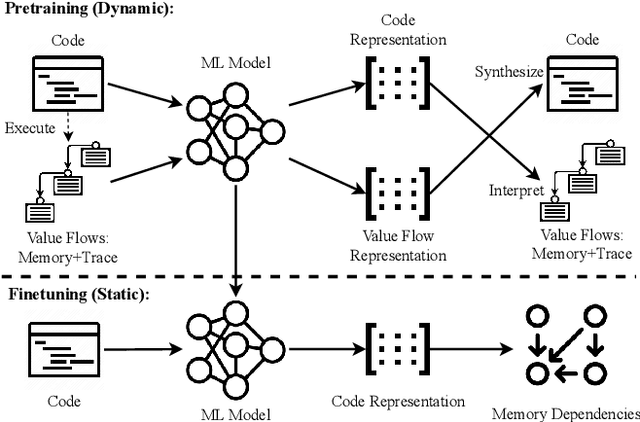

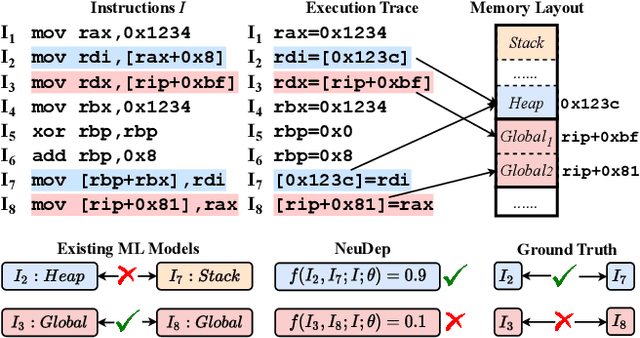
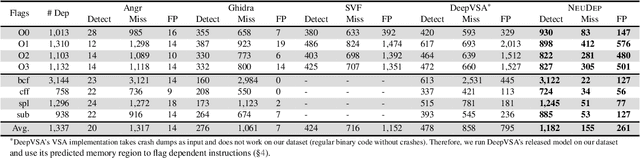
Determining whether multiple instructions can access the same memory location is a critical task in binary analysis. It is challenging as statically computing precise alias information is undecidable in theory. The problem aggravates at the binary level due to the presence of compiler optimizations and the absence of symbols and types. Existing approaches either produce significant spurious dependencies due to conservative analysis or scale poorly to complex binaries. We present a new machine-learning-based approach to predict memory dependencies by exploiting the model's learned knowledge about how binary programs execute. Our approach features (i) a self-supervised procedure that pretrains a neural net to reason over binary code and its dynamic value flows through memory addresses, followed by (ii) supervised finetuning to infer the memory dependencies statically. To facilitate efficient learning, we develop dedicated neural architectures to encode the heterogeneous inputs (i.e., code, data values, and memory addresses from traces) with specific modules and fuse them with a composition learning strategy. We implement our approach in NeuDep and evaluate it on 41 popular software projects compiled by 2 compilers, 4 optimizations, and 4 obfuscation passes. We demonstrate that NeuDep is more precise (1.5x) and faster (3.5x) than the current state-of-the-art. Extensive probing studies on security-critical reverse engineering tasks suggest that NeuDep understands memory access patterns, learns function signatures, and is able to match indirect calls. All these tasks either assist or benefit from inferring memory dependencies. Notably, NeuDep also outperforms the current state-of-the-art on these tasks.
ContraGen: Effective Contrastive Learning For Causal Language Model
Oct 03, 2022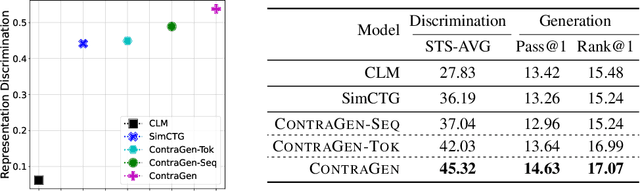
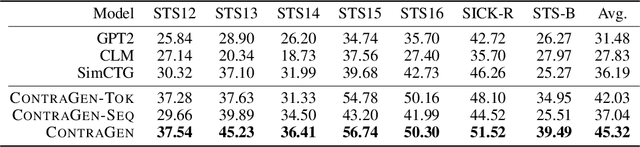
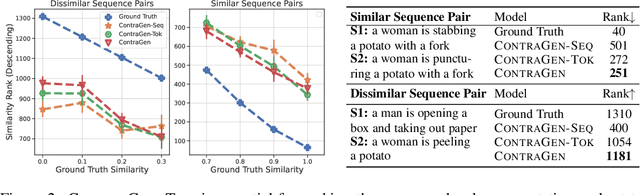
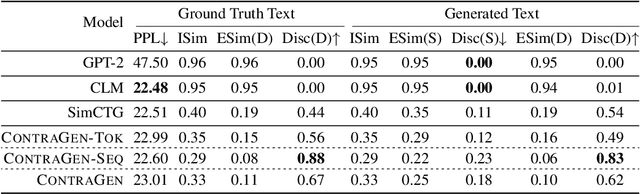
Despite exciting progress in large-scale language generation, the expressiveness of its representations is severely limited by the \textit{anisotropy} issue where the hidden representations are distributed into a narrow cone in the vector space. To address this issue, we present ContraGen, a novel contrastive learning framework to improve the representation with better uniformity and discrimination. We assess ContraGen on a wide range of downstream tasks in natural and programming languages. We show that ContraGen can effectively enhance both uniformity and discrimination of the representations and lead to the desired improvement on various language understanding tasks where discriminative representations are crucial for attaining good performance. Specifically, we attain $44\%$ relative improvement on the Semantic Textual Similarity tasks and $34\%$ on Code-to-Code Search tasks. Furthermore, by improving the expressiveness of the representations, ContraGen also boosts the source code generation capability with $9\%$ relative improvement on execution accuracy on the HumanEval benchmark.
NatGen: Generative pre-training by "Naturalizing" source code
Jun 15, 2022

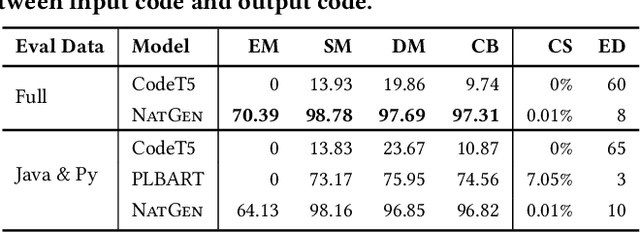
Pre-trained Generative Language models (e.g. PLBART, CodeT5, SPT-Code) for source code yielded strong results on several tasks in the past few years, including code generation and translation. These models have adopted varying pre-training objectives to learn statistics of code construction from very large-scale corpora in a self-supervised fashion; the success of pre-trained models largely hinges on these pre-training objectives. This paper proposes a new pre-training objective, "Naturalizing" of source code, exploiting code's bimodal, dual-channel (formal & natural channels) nature. Unlike natural language, code's bimodal, dual-channel nature allows us to generate semantically equivalent code at scale. We introduce six classes of semantic preserving transformations to introduce un-natural forms of code, and then force our model to produce more natural original programs written by developers. Learning to generate equivalent, but more natural code, at scale, over large corpora of open-source code, without explicit manual supervision, helps the model learn to both ingest & generate code. We fine-tune our model in three generative Software Engineering tasks: code generation, code translation, and code refinement with limited human-curated labeled data and achieve state-of-the-art performance rivaling CodeT5. We show that our pre-trained model is especially competitive at zero-shot and few-shot learning, and better at learning code properties (e.g., syntax, data flow).
Summarize and Generate to Back-translate: Unsupervised Translation of Programming Languages
May 23, 2022
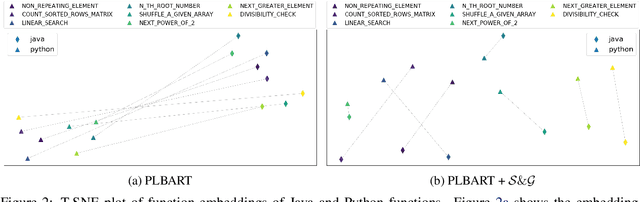
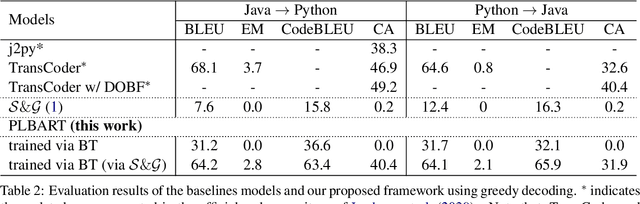
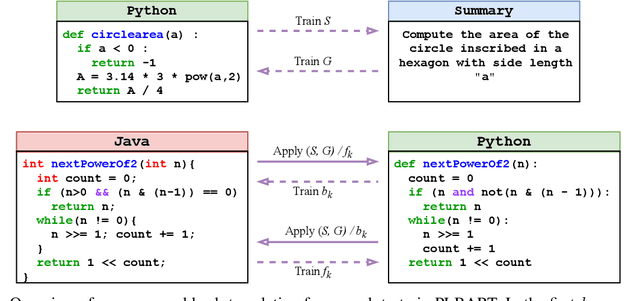
Back-translation is widely known for its effectiveness for neural machine translation when little to no parallel data is available. In this approach, a source-to-target model is coupled with a target-to-source model trained in parallel. The target-to-source model generates noisy sources, while the source-to-target model is trained to reconstruct the targets and vice versa. Recent developments of multilingual pre-trained sequence-to-sequence models for programming languages have been very effective for a broad spectrum of downstream software engineering tasks. Hence, it is compelling to train them to build programming language translation systems via back-translation. However, these models cannot be further trained via back-translation since they learn to output sequences in the same language as the inputs during pre-training. As an alternative, we propose performing back-translation via code summarization and generation. In code summarization, a model learns to generate natural language (NL) summaries given code snippets. In code generation, the model learns to do the opposite. Therefore, target-to-source generation in back-translation can be viewed as target-to-NL-to-source generation. We show that our proposed approach performs competitively with state-of-the-art methods.
Repairing Group-Level Errors for DNNs Using Weighted Regularization
Apr 04, 2022
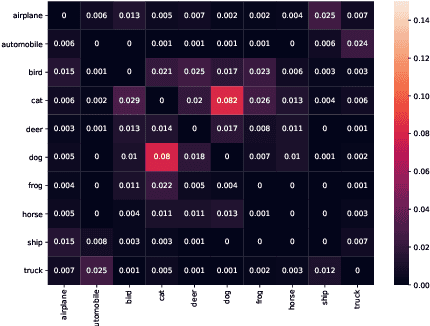
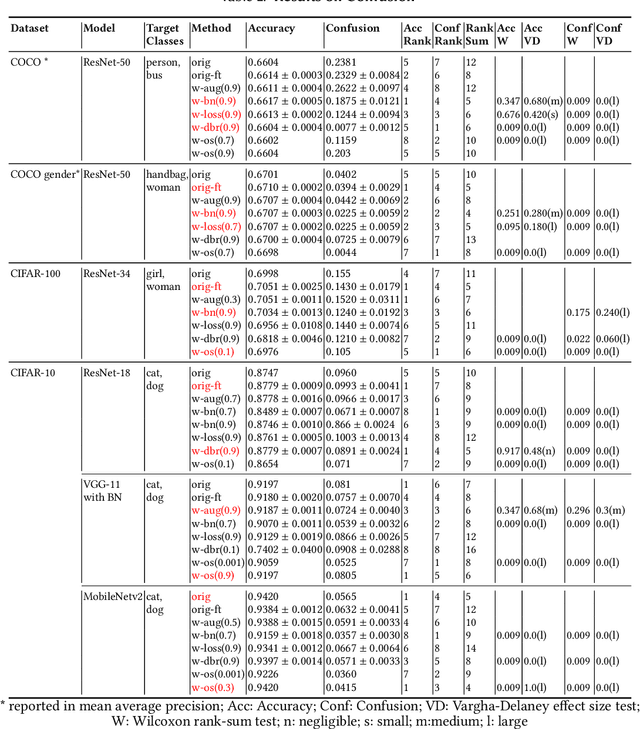
Deep Neural Networks (DNNs) have been widely used in software making decisions impacting people's lives. However, they have been found to exhibit severe erroneous behaviors that may lead to unfortunate outcomes. Previous work shows that such misbehaviors often occur due to class property violations rather than errors on a single image. Although methods for detecting such errors have been proposed, fixing them has not been studied so far. Here, we propose a generic method called Weighted Regularization (WR) consisting of five concrete methods targeting the error-producing classes to fix the DNNs. In particular, it can repair confusion error and bias error of DNN models for both single-label and multi-label image classifications. A confusion error happens when a given DNN model tends to confuse between two classes. Each method in WR assigns more weights at a stage of DNN retraining or inference to mitigate the confusion between target pair. A bias error can be fixed similarly. We evaluate and compare the proposed methods along with baselines on six widely-used datasets and architecture combinations. The results suggest that WR methods have different trade-offs but under each setting at least one WR method can greatly reduce confusion/bias errors at a very limited cost of the overall performance.
Unicorn: Reasoning about Configurable System Performance through the lens of Causality
Jan 20, 2022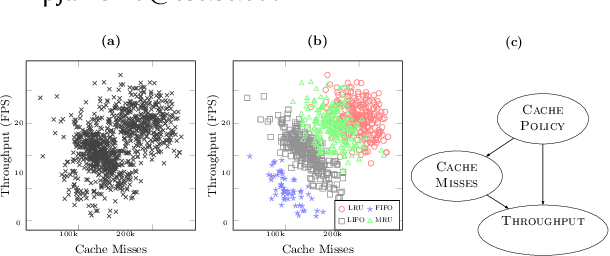
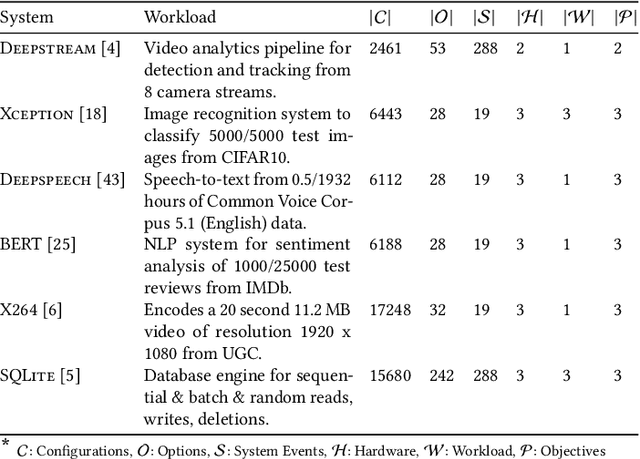
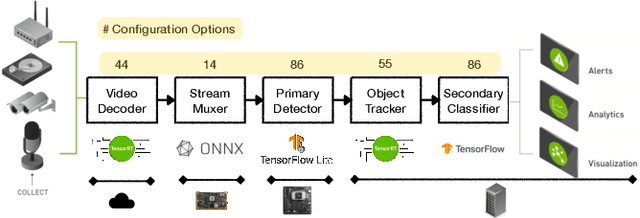
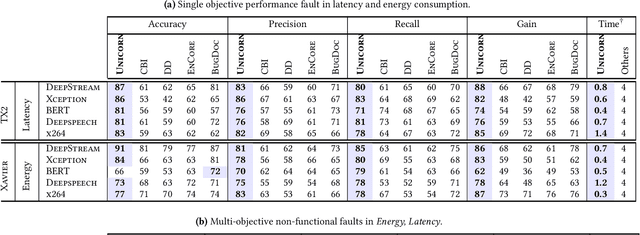
Modern computer systems are highly configurable, with the variability space sometimes larger than the number of atoms in the universe. Understanding and reasoning about the performance behavior of highly configurable systems, due to a vast variability space, is challenging. State-of-the-art methods for performance modeling and analyses rely on predictive machine learning models, therefore, they become (i) unreliable in unseen environments (e.g., different hardware, workloads), and (ii) produce incorrect explanations. To this end, we propose a new method, called Unicorn, which (a) captures intricate interactions between configuration options across the software-hardware stack and (b) describes how such interactions impact performance variations via causal inference. We evaluated Unicorn on six highly configurable systems, including three on-device machine learning systems, a video encoder, a database management system, and a data analytics pipeline. The experimental results indicate that Unicorn outperforms state-of-the-art performance optimization and debugging methods. Furthermore, unlike the existing methods, the learned causal performance models reliably predict performance for new environments.
VELVET: a noVel Ensemble Learning approach to automatically locate VulnErable sTatements
Jan 13, 2022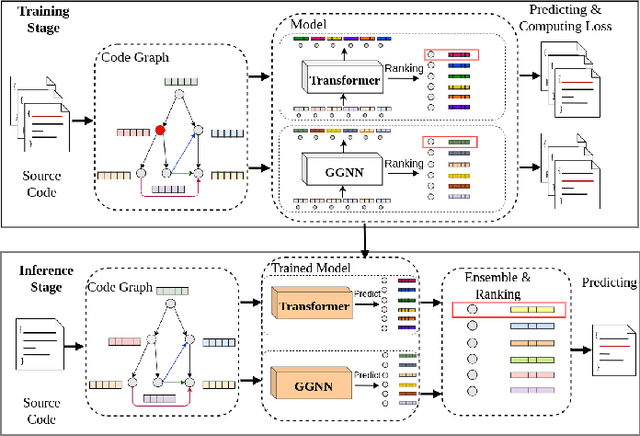
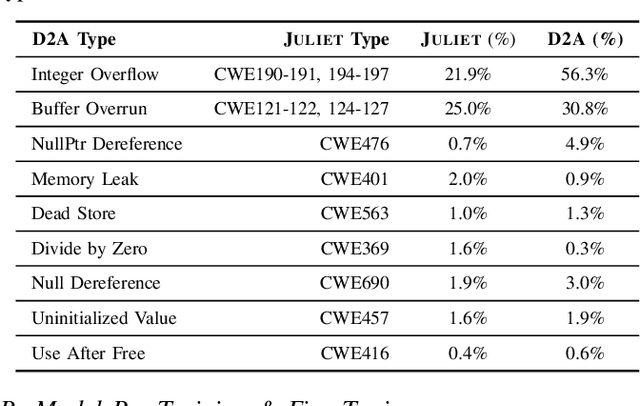
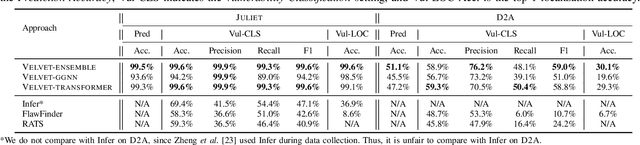
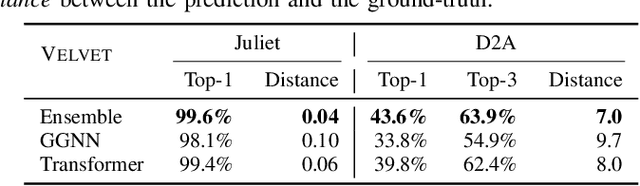
Automatically locating vulnerable statements in source code is crucial to assure software security and alleviate developers' debugging efforts. This becomes even more important in today's software ecosystem, where vulnerable code can flow easily and unwittingly within and across software repositories like GitHub. Across such millions of lines of code, traditional static and dynamic approaches struggle to scale. Although existing machine-learning-based approaches look promising in such a setting, most work detects vulnerable code at a higher granularity -- at the method or file level. Thus, developers still need to inspect a significant amount of code to locate the vulnerable statement(s) that need to be fixed. This paper presents VELVET, a novel ensemble learning approach to locate vulnerable statements. Our model combines graph-based and sequence-based neural networks to successfully capture the local and global context of a program graph and effectively understand code semantics and vulnerable patterns. To study VELVET's effectiveness, we use an off-the-shelf synthetic dataset and a recently published real-world dataset. In the static analysis setting, where vulnerable functions are not detected in advance, VELVET achieves 4.5x better performance than the baseline static analyzers on the real-world data. For the isolated vulnerability localization task, where we assume the vulnerability of a function is known while the specific vulnerable statement is unknown, we compare VELVET with several neural networks that also attend to local and global context of code. VELVET achieves 99.6% and 43.6% top-1 accuracy over synthetic data and real-world data, respectively, outperforming the baseline deep-learning models by 5.3-29.0%.
A Survey on Scenario-Based Testing for Automated Driving Systems in High-Fidelity Simulation
Dec 02, 2021
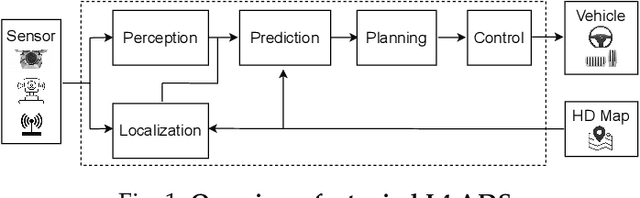

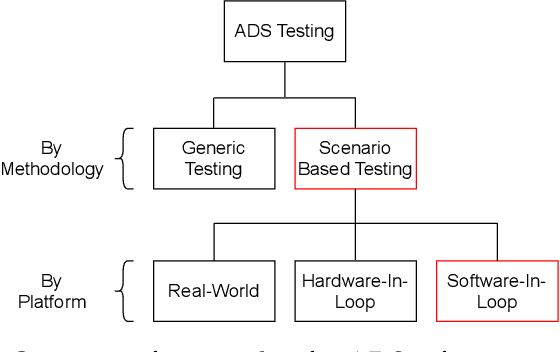
Automated Driving Systems (ADSs) have seen rapid progress in recent years. To ensure the safety and reliability of these systems, extensive testings are being conducted before their future mass deployment. Testing the system on the road is the closest to real-world and desirable approach, but it is incredibly costly. Also, it is infeasible to cover rare corner cases using such real-world testing. Thus, a popular alternative is to evaluate an ADS's performance in some well-designed challenging scenarios, a.k.a. scenario-based testing. High-fidelity simulators have been widely used in this setting to maximize flexibility and convenience in testing what-if scenarios. Although many works have been proposed offering diverse frameworks/methods for testing specific systems, the comparisons and connections among these works are still missing. To bridge this gap, in this work, we provide a generic formulation of scenario-based testing in high-fidelity simulation and conduct a literature review on the existing works. We further compare them and present the open challenges as well as potential future research directions.
Contrastive Learning for Source Code with Structural and Functional Properties
Oct 08, 2021
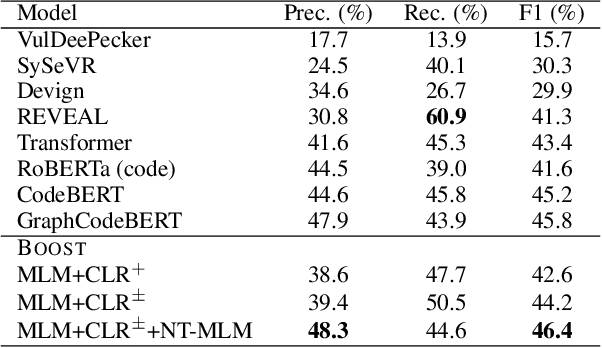
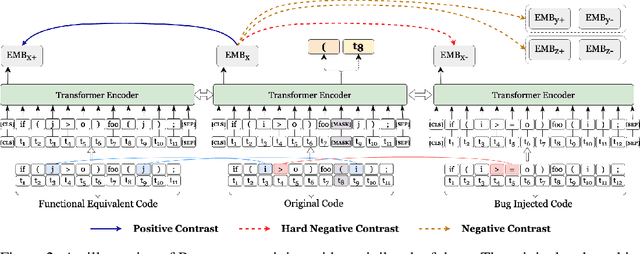

Pre-trained transformer models have recently shown promises for understanding the source code. Most existing works expect to understand code from the textual features and limited structural knowledge of code. However, the program functionalities sometimes cannot be fully revealed by the code sequence, even with structure information. Programs can contain very different tokens and structures while sharing the same functionality, but changing only one or a few code tokens can introduce unexpected or malicious program behaviors while preserving the syntax and most tokens. In this work, we present BOOST, a novel self-supervised model to focus pre-training based on the characteristics of source code. We first employ automated, structure-guided code transformation algorithms that generate (i.) functionally equivalent code that looks drastically different from the original one, and (ii.) textually and syntactically very similar code that is functionally distinct from the original. We train our model in a way that brings the functionally equivalent code closer and distinct code further through a contrastive learning objective. To encode the structure information, we introduce a new node-type masked language model objective that helps the model learn about structural context. We pre-train BOOST with a much smaller dataset than the state-of-the-art models, but our small models can still match or outperform these large models in code understanding and generation tasks.
Detecting Safety Problems of Multi-Sensor Fusion in Autonomous Driving
Sep 14, 2021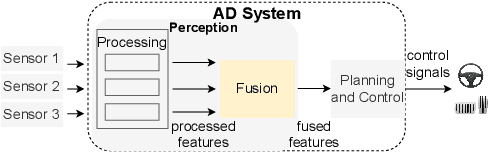

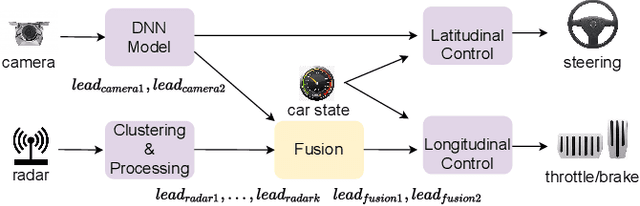

Autonomous driving (AD) systems have been thriving in recent years. In general, they receive sensor data, compute driving decisions, and output control signals to the vehicles. To smooth out the uncertainties brought by sensor inputs, AD systems usually leverage multi-sensor fusion (MSF) to fuse the sensor inputs and produce a more reliable understanding of the surroundings. However, MSF cannot completely eliminate the uncertainties since it lacks the knowledge about which sensor provides the most accurate data. As a result, critical consequences might happen unexpectedly. In this work, we observed that the popular MSF methods in an industry-grade Advanced Driver-Assistance System (ADAS) can mislead the car control and result in serious safety hazards. Misbehavior can happen regardless of the used fusion methods and the accurate data from at least one sensor. To attribute the safety hazards to a MSF method, we formally define the fusion errors and propose a way to distinguish safety violations causally induced by such errors. Further, we develop a novel evolutionary-based domain-specific search framework, FusionFuzz, for the efficient detection of fusion errors. We evaluate our framework on two widely used MSF methods. %in two driving environments. Experimental results show that FusionFuzz identifies more than 150 fusion errors. Finally, we provide several suggestions to improve the MSF methods under study.