 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSoK: AI-Augmented Binary Reversing
Jun 16, 2026Binary reversing is fundamental to software understanding, vulnerability discovery, malware investigation, and firmware auditing. However, it remains inherently challenging due to the irreversible loss of semantic information during compilation. Recent advances in machine learning, large language models (LLMs), and agentic AI systems have accelerated the adoption of AI-augmented binary reversing. Yet, the resulting body of work has become increasingly fragmented across reversing domains, artifact representations, learning approaches, and evaluation practices. This paper presents the first comprehensive systematization of knowledge on AI-augmented binary reversing. We analyze 144 research papers published since 2015, and organize them into 22 binary reversing domains according to the inference tasks. We further introduce a unified taxonomy spanning conventional and AI-augmented reversing pipelines. Our taxonomy connects traditional analysis techniques, binary-derived artifacts, representation strategies, learning paradigms, and downstream inference tasks, while clarifying the emerging roles of LLMs and agentic AI systems. By establishing a common vocabulary and structured framework, we provide a holistic view of the field's evolution over the past decade. Our study reveals common structures underlying seemingly disparate approaches, highlights persistent technical challenges and evaluation gaps, and identifies promising opportunities for future research. Collectively, these insights clarify the current state of the field and provide a foundation for the next generation of reliable and scalable AI-augmented binary reversing systems.
R-C2: Cycle-Consistent Reinforcement Learning Improves Multimodal Reasoning
Mar 26, 2026Robust perception and reasoning require consistency across sensory modalities. Yet current multimodal models often violate this principle, yielding contradictory predictions for visual and textual representations of the same concept. Rather than masking these failures with standard voting mechanisms, which can amplify systematic biases, we show that cross-modal inconsistency provides a rich and natural signal for learning. We introduce RC2, a reinforcement learning framework that resolves internal conflicts by enforcing cross-modal cycle consistency. By requiring a model to perform backward inference, switch modalities, and reliably reconstruct the answer through forward inference, we obtain a dense, label-free reward. This cyclic constraint encourages the model to align its internal representations autonomously. Optimizing for this structure mitigates modality-specific errors and improves reasoning accuracy by up to 7.6 points. Our results suggest that advanced reasoning emerges not only from scaling data, but also from enforcing a structurally consistent understanding of the world.
ExVerus: Verus Proof Repair via Counterexample Reasoning
Mar 26, 2026Large Language Models (LLMs) have shown promising results in automating formal verification. However, existing approaches treat proof generation as a static, end-to-end prediction over source code, relying on limited verifier feedback and lacking access to concrete program behaviors. We present EXVERUS, a counterexample-guided framework that enables LLMs to reason about proofs using behavioral feedback via counterexamples. When a proof fails, EXVERUS automatically generates and validates counterexamples, and then guides the LLM to generalize them into inductive invariants to block these failures. Our evaluation shows that EXVERUS significantly improves proof accuracy, robustness, and token efficiency over the state-of-the-art prompting-based Verus proof generator.
SemRep: Generative Code Representation Learning with Code Transformations
Mar 13, 2026Code transformation is a foundational capability in the software development process, where its effectiveness relies on constructing a high-quality code representation to characterize the input code semantics and guide the transformation. Existing approaches treat code transformation as an end-to-end learning task, leaving the construction of the representation needed for semantic reasoning implicit in model weights or relying on rigid compiler-level abstractions. We present SemRep, a framework that improves code transformation through generative code representation learning. Our key insight is to employ the semantics-preserving transformations as the intermediate representation, which serves as both a generative mid-training task and the guidance for subsequent instruction-specific code transformations. Across general code editing and optimization tasks (e.g., GPU kernel optimization), SemRep outperforms the extensively finetuned baselines with strictly the same training budget by 6.9% in correctness, 1.1x in performance, 13.9% in generalization, and 6.7% in robustness. With the improved exploration of diverse code transformations, SemRep is particularly amenable to evolutionary search. Combined with an evolutionary coding agent, SemRep finds optimizations that 685B larger-weight baselines fail to discover while achieving the same performance with 25% less inference compute.
The Hitchhiker's Guide to Program Analysis, Part II: Deep Thoughts by LLMs
Apr 16, 2025Static analysis is a cornerstone for software vulnerability detection, yet it often struggles with the classic precision-scalability trade-off. In practice, such tools often produce high false positive rates, particularly in large codebases like the Linux kernel. This imprecision can arise from simplified vulnerability modeling and over-approximation of path and data constraints. While large language models (LLMs) show promise in code understanding, their naive application to program analysis yields unreliable results due to inherent reasoning limitations. We introduce BugLens, a post-refinement framework that significantly improves static analysis precision. BugLens guides an LLM to follow traditional analysis steps by assessing buggy code patterns for security impact and validating the constraints associated with static warnings. Evaluated on real-world Linux kernel bugs, BugLens raises precision from 0.10 (raw) and 0.50 (semi-automated refinement) to 0.72, substantially reducing false positives and revealing four previously unreported vulnerabilities. Our results suggest that a structured LLM-based workflow can meaningfully enhance the effectiveness of static analysis tools.
Detecting Buggy Contracts via Smart Testing
Sep 06, 2024



Smart contracts are susceptible to critical vulnerabilities. Hybrid dynamic analyses, such as concolic execution assisted fuzzing and foundation model assisted fuzzing, have emerged as highly effective testing techniques for smart contract bug detection recently. This hybrid approach has shown initial promise in real-world benchmarks, but it still suffers from low scalability to find deep bugs buried in complex code patterns. We observe that performance bottlenecks of existing dynamic analyses and model hallucination are two main factors limiting the scalability of this hybrid approach in finding deep bugs. To overcome the challenges, we design an interactive, self-deciding foundation model based system, called SmartSys, to support hybrid smart contract dynamic analyses. The key idea is to teach foundation models about performance bottlenecks of different dynamic analysis techniques, making it possible to forecast the right technique and generates effective fuzz targets that can reach deep, hidden bugs. To prune hallucinated, incorrect fuzz targets, SmartSys feeds foundation models with feedback from dynamic analysis during compilation and at runtime. The interesting results of SmartSys include: i) discovering a smart contract protocol vulnerability that has escaped eleven tools and survived multiple audits for over a year; ii) improving coverage by up to 14.3\% on real-world benchmarks compared to the baselines.
SWE-bench: Can Language Models Resolve Real-World GitHub Issues?
Oct 10, 2023



Language models have outpaced our ability to evaluate them effectively, but for their future development it is essential to study the frontier of their capabilities. We consider real-world software engineering to be a rich, sustainable, and challenging testbed for evaluating the next generation of language models. We therefore introduce SWE-bench, an evaluation framework including $2,294$ software engineering problems drawn from real GitHub issues and corresponding pull requests across $12$ popular Python repositories. Given a codebase along with a description of an issue to be resolved, a language model is tasked with editing the codebase to address the issue. Resolving issues in SWE-bench frequently requires understanding and coordinating changes across multiple functions, classes, and even files simultaneously, calling for models to interact with execution environments, process extremely long contexts and perform complex reasoning that goes far beyond traditional code generation. Our evaluations show that both state-of-the-art proprietary models and our fine-tuned model SWE-Llama can resolve only the simplest issues. Claude 2 and GPT-4 solve a mere $4.8$% and $1.7$% of instances respectively, even when provided with an oracle retriever. Advances on SWE-bench represent steps towards LMs that are more practical, intelligent, and autonomous.
Symmetry-Preserving Program Representations for Learning Code Semantics
Aug 07, 2023



Large Language Models (LLMs) have shown promise in automated program reasoning, a crucial aspect of many security tasks. However, existing LLM architectures for code are often borrowed from other domains like natural language processing, raising concerns about their generalization and robustness to unseen code. A key generalization challenge is to incorporate the knowledge of code semantics, including control and data flow, into the LLM architectures. Drawing inspiration from examples of convolution layers exploiting translation symmetry, we explore how code symmetries can enhance LLM architectures for program analysis and modeling. We present a rigorous group-theoretic framework that formally defines code symmetries as semantics-preserving transformations and provides techniques for precisely reasoning about symmetry preservation within LLM architectures. Using this framework, we introduce a novel variant of self-attention that preserves program symmetries, demonstrating its effectiveness in generalization and robustness through detailed experimental evaluations across different binary and source code analysis tasks. Overall, our code symmetry framework offers rigorous and powerful reasoning techniques that can guide the future development of specialized LLMs for code and advance LLM-guided program reasoning tasks.
NeuDep: Neural Binary Memory Dependence Analysis
Oct 04, 2022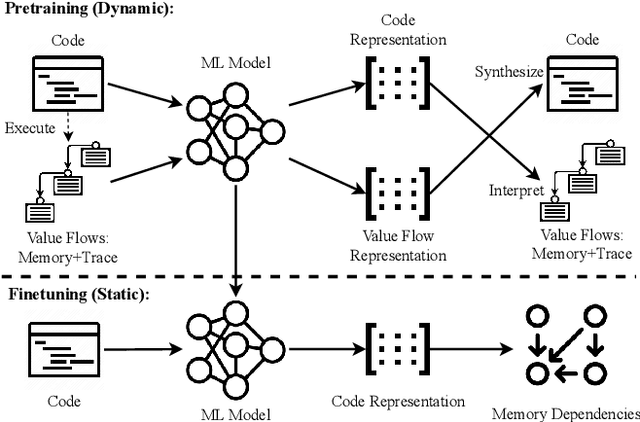

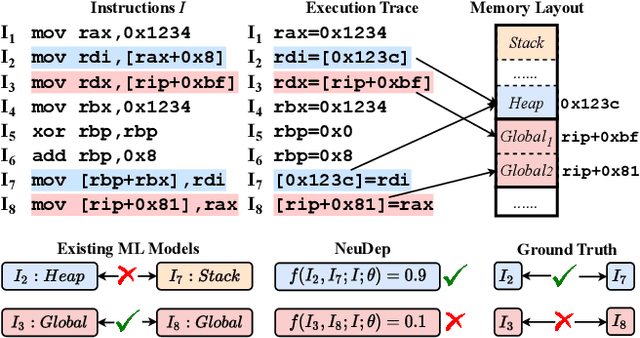
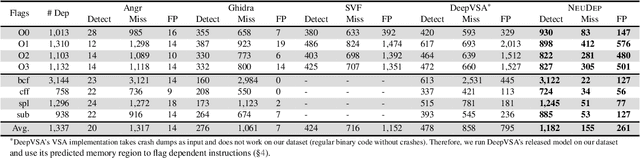
Determining whether multiple instructions can access the same memory location is a critical task in binary analysis. It is challenging as statically computing precise alias information is undecidable in theory. The problem aggravates at the binary level due to the presence of compiler optimizations and the absence of symbols and types. Existing approaches either produce significant spurious dependencies due to conservative analysis or scale poorly to complex binaries. We present a new machine-learning-based approach to predict memory dependencies by exploiting the model's learned knowledge about how binary programs execute. Our approach features (i) a self-supervised procedure that pretrains a neural net to reason over binary code and its dynamic value flows through memory addresses, followed by (ii) supervised finetuning to infer the memory dependencies statically. To facilitate efficient learning, we develop dedicated neural architectures to encode the heterogeneous inputs (i.e., code, data values, and memory addresses from traces) with specific modules and fuse them with a composition learning strategy. We implement our approach in NeuDep and evaluate it on 41 popular software projects compiled by 2 compilers, 4 optimizations, and 4 obfuscation passes. We demonstrate that NeuDep is more precise (1.5x) and faster (3.5x) than the current state-of-the-art. Extensive probing studies on security-critical reverse engineering tasks suggest that NeuDep understands memory access patterns, learns function signatures, and is able to match indirect calls. All these tasks either assist or benefit from inferring memory dependencies. Notably, NeuDep also outperforms the current state-of-the-art on these tasks.
Trex: Learning Execution Semantics from Micro-Traces for Binary Similarity
Dec 29, 2020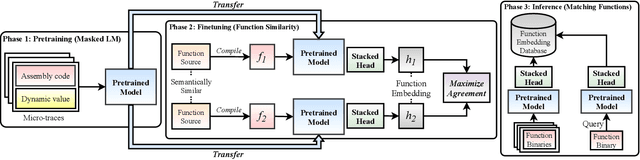

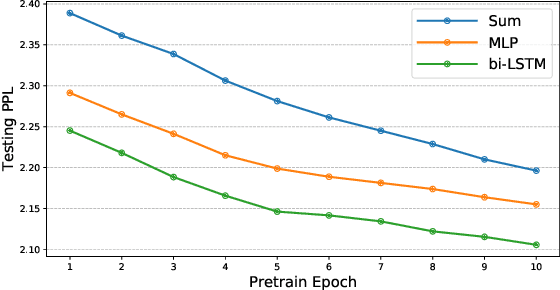
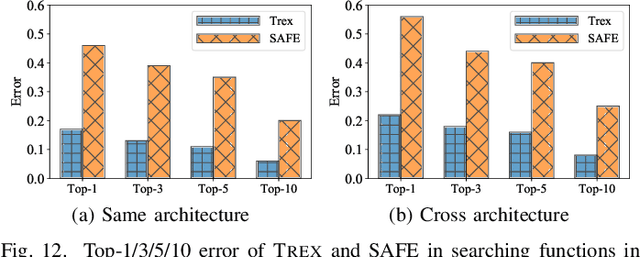
Detecting semantically similar functions -- a crucial analysis capability with broad real-world security usages including vulnerability detection, malware lineage, and forensics -- requires understanding function behaviors and intentions. This task is challenging as semantically similar functions can be implemented differently, run on different architectures, and compiled with diverse compiler optimizations or obfuscations. Most existing approaches match functions based on syntactic features without understanding the functions' execution semantics. We present Trex, a transfer-learning-based framework, to automate learning execution semantics explicitly from functions' micro-traces and transfer the learned knowledge to match semantically similar functions. Our key insight is that these traces can be used to teach an ML model the execution semantics of different sequences of instructions. We thus train the model to learn execution semantics from the functions' micro-traces, without any manual labeling effort. We then develop a novel neural architecture to learn execution semantics from micro-traces, and we finetune the pretrained model to match semantically similar functions. We evaluate Trex on 1,472,066 function binaries from 13 popular software projects. These functions are from different architectures and compiled with various optimizations and obfuscations. Trex outperforms the state-of-the-art systems by 7.8%, 7.2%, and 14.3% in cross-architecture, optimization, and obfuscation function matching, respectively. Ablation studies show that the pretraining significantly boosts the function matching performance, underscoring the importance of learning execution semantics.