 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMulti-task Code LLMs: Data Mix or Model Merge?
Jan 28, 2026Recent research advocates deploying smaller, specialized code LLMs in agentic frameworks alongside frontier models, sparking interest in efficient strategies for multi-task learning that balance performance, constraints, and costs. We compare two approaches for creating small, multi-task code LLMs: data mixing versus model merging. We conduct extensive experiments across two model families (Qwen Coder and DeepSeek Coder) at two scales (2B and 7B parameters), fine-tuning them for code generation and code summarization tasks. Our evaluation on HumanEval, MBPP, and CodeXGlue benchmarks reveals that model merging achieves the best overall performance at larger scale across model families, retaining 96% of specialized model performance on code generation tasks while maintaining summarization capabilities. Notably, merged models can even surpass individually fine-tuned models, with our best configuration of Qwen Coder 2.5 7B model achieving 92.7% Pass@1 on HumanEval compared to 90.9% for its task-specific fine-tuned equivalent. At a smaller scale we find instead data mixing to be a preferred strategy. We further introduce a weight analysis technique to understand how different tasks affect model parameters and their implications for merging strategies. The results suggest that careful merging and mixing strategies can effectively combine task-specific capabilities without significant performance degradation, making them ideal for resource-constrained deployment scenarios.
Agentic Structured Graph Traversal for Root Cause Analysis of Code-related Incidents in Cloud Applications
Dec 26, 2025Cloud incidents pose major operational challenges in production, with unresolved production cloud incidents cost on average over $2M per hour. Prior research identifies code- and configuration-related issues as the predominant category of root causes in cloud incidents. This paper introduces PRAXIS, an orchestrator that manages and deploys an agentic workflow for diagnosing code- and configuration-caused cloud incidents. PRAXIS employs an LLM-driven structured traversal over two types of graph: (1) a service dependency graph (SDG) that captures microservice-level dependencies; and (2) a hammock-block program dependence graph (PDG) that captures code-level dependencies for each microservice. Together, these graphs encode microservice- and code-level dependencies and the LLM acts as a traversal policy over these graphs, moving between services and code dependencies to localize and explain failures. Compared to state-of-the-art ReAct baselines, PRAXIS improves RCA accuracy by up to 3.1x while reducing token consumption by 3.8x. PRAXIS is demonstrated on a set of 30 comprehensive real-world incidents that is being compiled into an RCA benchmark.
Unicorn: Reasoning about Configurable System Performance through the lens of Causality
Jan 20, 2022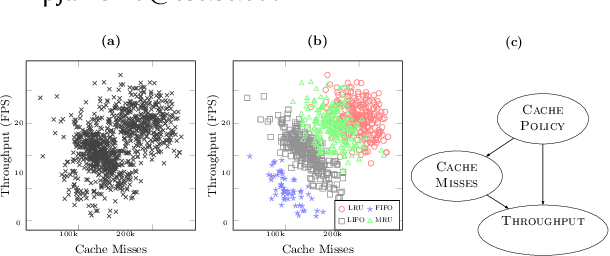
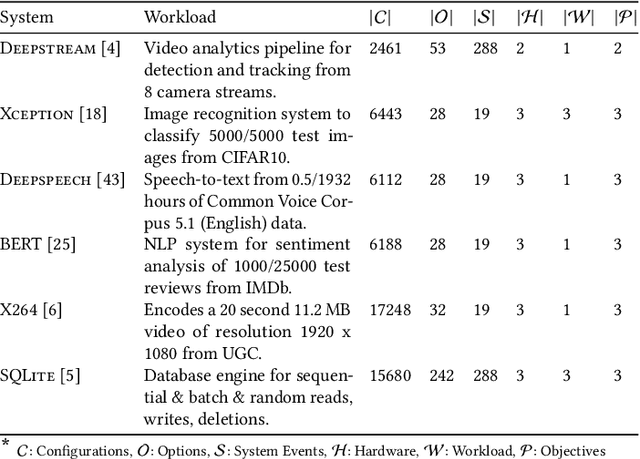
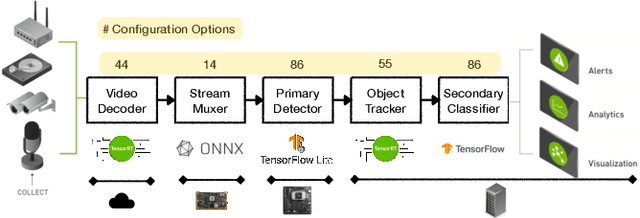
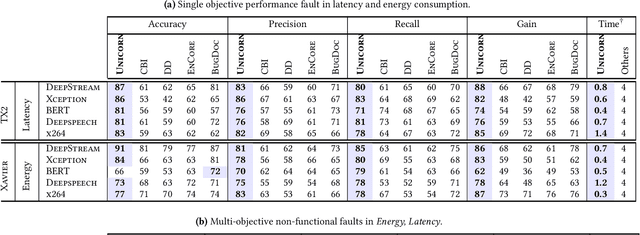
Modern computer systems are highly configurable, with the variability space sometimes larger than the number of atoms in the universe. Understanding and reasoning about the performance behavior of highly configurable systems, due to a vast variability space, is challenging. State-of-the-art methods for performance modeling and analyses rely on predictive machine learning models, therefore, they become (i) unreliable in unseen environments (e.g., different hardware, workloads), and (ii) produce incorrect explanations. To this end, we propose a new method, called Unicorn, which (a) captures intricate interactions between configuration options across the software-hardware stack and (b) describes how such interactions impact performance variations via causal inference. We evaluated Unicorn on six highly configurable systems, including three on-device machine learning systems, a video encoder, a database management system, and a data analytics pipeline. The experimental results indicate that Unicorn outperforms state-of-the-art performance optimization and debugging methods. Furthermore, unlike the existing methods, the learned causal performance models reliably predict performance for new environments.
Partitioning Cloud-based Microservices (via Deep Learning)
Sep 29, 2021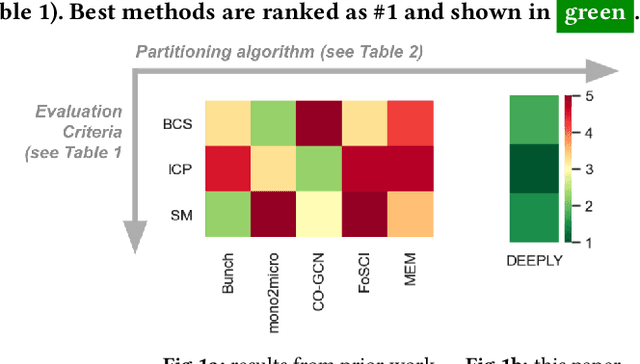

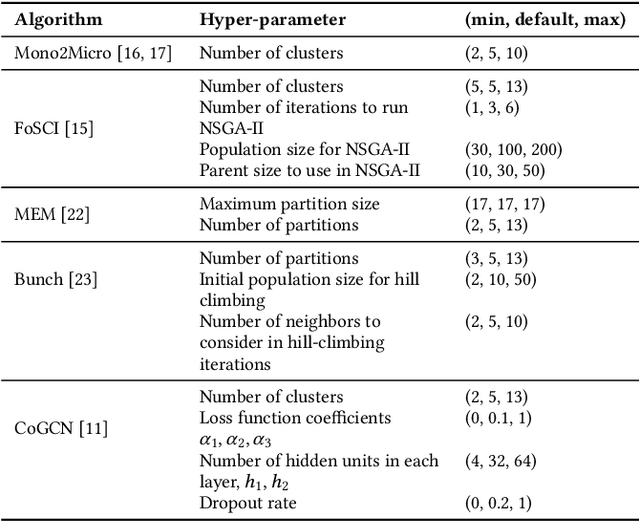
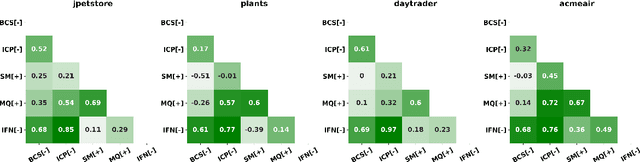
Cloud-based software has many advantages. When services are divided into many independent components, they are easier to update. Also, during peak demand, it is easier to scale cloud services (just hire more CPUs). Hence, many organizations are partitioning their monolithic enterprise applications into cloud-based microservices. Recently there has been much work using machine learning to simplify this partitioning task. Despite much research, no single partitioning method can be recommended as generally useful. More specifically, those prior solutions are "brittle''; i.e. if they work well for one kind of goal in one dataset, then they can be sub-optimal if applied to many datasets and multiple goals. In order to find a generally useful partitioning method, we propose DEEPLY. This new algorithm extends the CO-GCN deep learning partition generator with (a) a novel loss function and (b) some hyper-parameter optimization. As shown by our experiments, DEEPLY generally outperforms prior work (including CO-GCN, and others) across multiple datasets and goals. To the best of our knowledge, this is the first report in SE of such stable hyper-parameter optimization. To aid reuse of this work, DEEPLY is available on-line at https://bit.ly/2WhfFlB.
Learning GENERAL Principles from Hundreds of Software Projects
Nov 06, 2019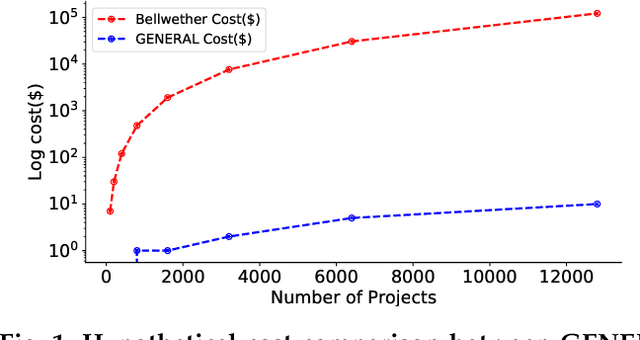
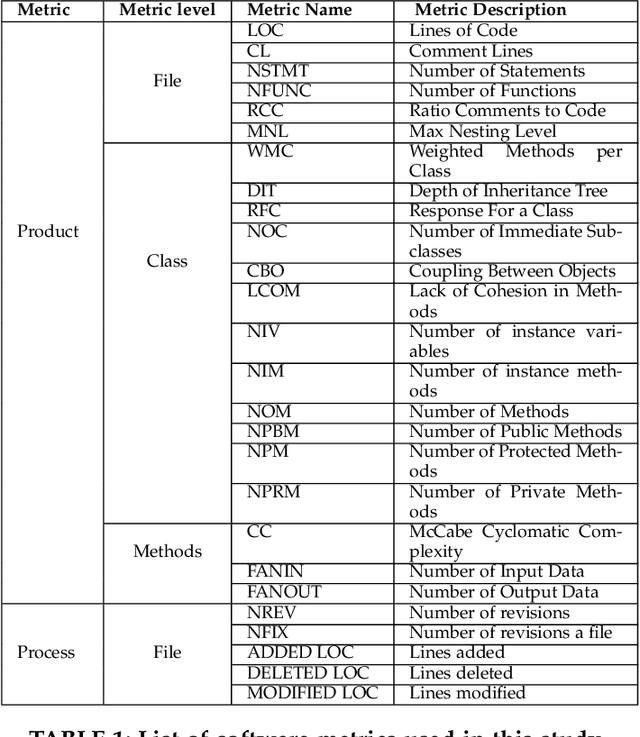
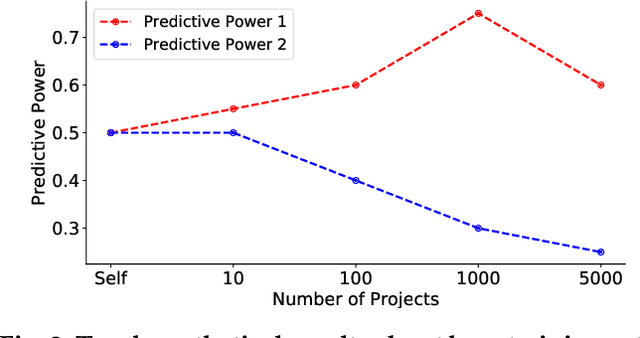

When one exemplar project, which we call the "bellwether", offers the best advice then it can be used to offer advice for many other projects. Such bellwethers can be used to make quality predictions about new projects, even before there is much experience with those new projects. But existing methods for bellwether transfer are very slow. When applied to the 697 projects studied here, they took 60 days of CPU to find and certify the bellwethers. Hence, we propose a GENERAL: a novel bellwether detection algorithm based on hierarchical clustering. At each level within a tree of clusters, one bellwether is computed from sibling projects, then promoted up the tree. This hierarchical method is a scalable approach to learning effective models from very large data sets. For example, for nearly 700 projects, the defect prediction models generated from GENERAL's bellwether were just as good as those found via standard methods.
ConEx: Efficient Exploration of Big-Data System Configurations for Better Performance
Oct 17, 2019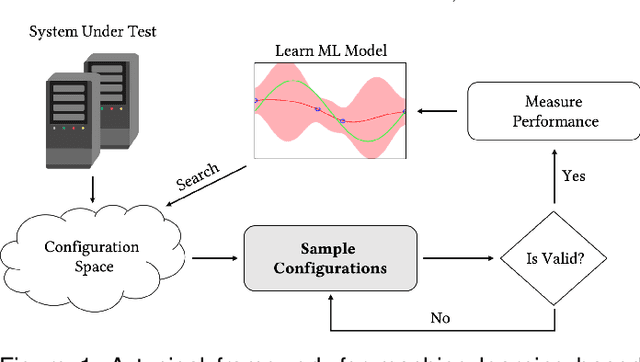
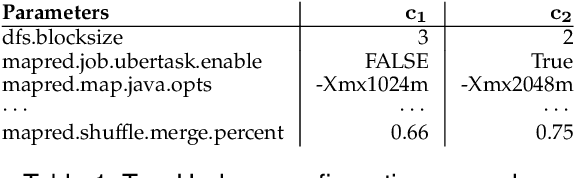
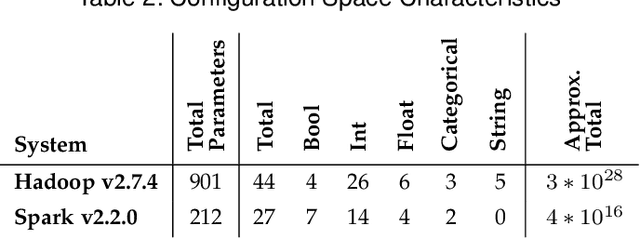
Configuration space complexity makes the big-data software systems hard to configure well. Consider Hadoop, with over nine hundred parameters, developers often just use the default configurations provided with Hadoop distributions. The opportunity costs in lost performance are significant. Popular learning-based approaches to auto-tune software does not scale well for big-data systems because of the high cost of collecting training data. We present a new method based on a combination of Evolutionary Markov Chain Monte Carlo (EMCMC) sampling and cost reduction techniques to cost-effectively find better-performing configurations for big data systems. For cost reduction, we developed and experimentally tested and validated two approaches: using scaled-up big data jobs as proxies for the objective function for larger jobs and using a dynamic job similarity measure to infer that results obtained for one kind of big data problem will work well for similar problems. Our experimental results suggest that our approach promises to significantly improve the performance of big data systems and that it outperforms competing approaches based on random sampling, basic genetic algorithms (GA), and predictive model learning. Our experimental results support the conclusion that our approach has strongly demonstrated potential to significantly and cost-effectively improve the performance of big data systems.