 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDisentangling Dense Multi-Cable Knots
Jun 04, 2021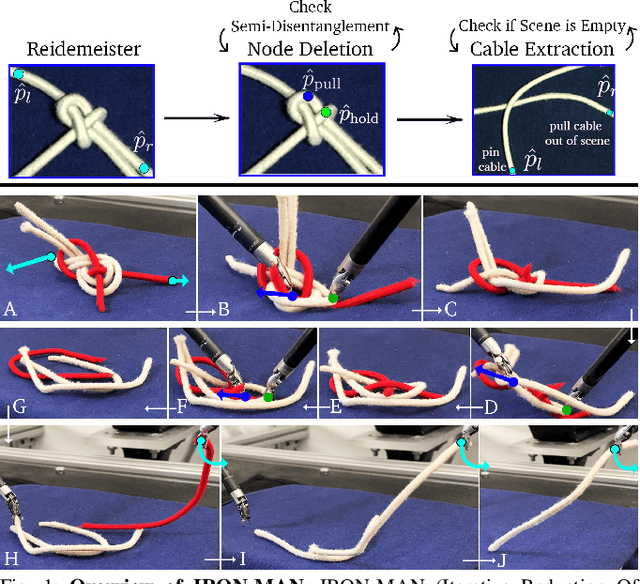
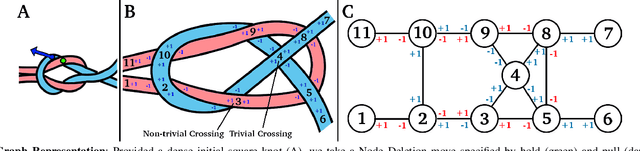
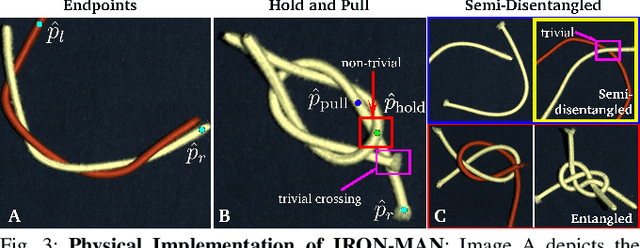

Disentangling two or more cables requires many steps to remove crossings between and within cables. We formalize the problem of disentangling multiple cables and present an algorithm, Iterative Reduction Of Non-planar Multiple cAble kNots (IRON-MAN), that outputs robot actions to remove crossings from multi-cable knotted structures. We instantiate this algorithm with a learned perception system, inspired by prior work in single-cable untying that given an image input, can disentangle two-cable twists, three-cable braids, and knots of two or three cables, such as overhand, square, carrick bend, sheet bend, crown, and fisherman's knots. IRON-MAN keeps track of task-relevant keypoints corresponding to target cable endpoints and crossings and iteratively disentangles the cables by identifying and undoing crossings that are critical to knot structure. Using a da Vinci surgical robot, we experimentally evaluate the effectiveness of IRON-MAN on untangling multi-cable knots of types that appear in the training data, as well as generalizing to novel classes of multi-cable knots. Results suggest that IRON-MAN is effective in disentangling knots involving up to three cables with 80.5% success and generalizing to knot types that are not present during training, with cables of both distinct or identical colors.
Orienting Novel 3D Objects Using Self-Supervised Learning of Rotation Transforms
May 29, 2021
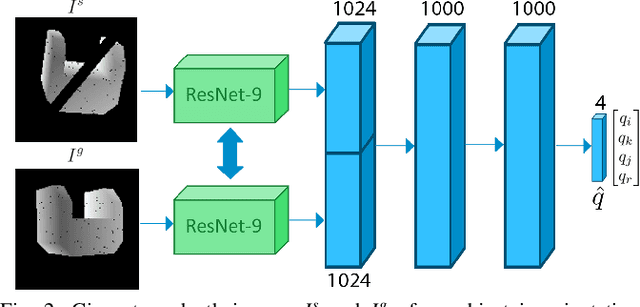
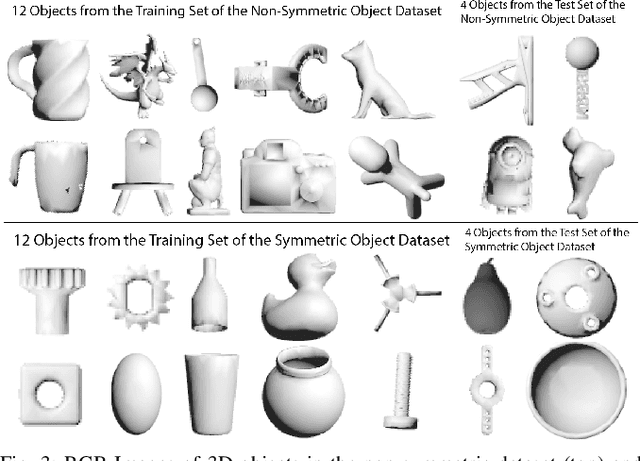
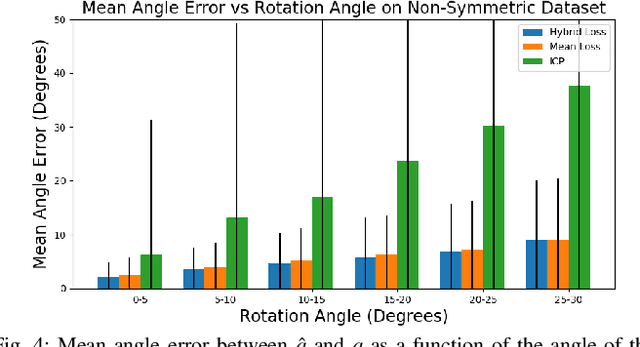
Orienting objects is a critical component in the automation of many packing and assembly tasks. We present an algorithm to orient novel objects given a depth image of the object in its current and desired orientation. We formulate a self-supervised objective for this problem and train a deep neural network to estimate the 3D rotation as parameterized by a quaternion, between these current and desired depth images. We then use the trained network in a proportional controller to re-orient objects based on the estimated rotation between the two depth images. Results suggest that in simulation we can rotate unseen objects with unknown geometries by up to 30{\deg} with a median angle error of 1.47{\deg} over 100 random initial/desired orientations each for 22 novel objects. Experiments on physical objects suggest that the controller can achieve a median angle error of 4.2{\deg} over 10 random initial/desired orientations each for 5 objects.
LazyDAgger: Reducing Context Switching in Interactive Imitation Learning
Mar 31, 2021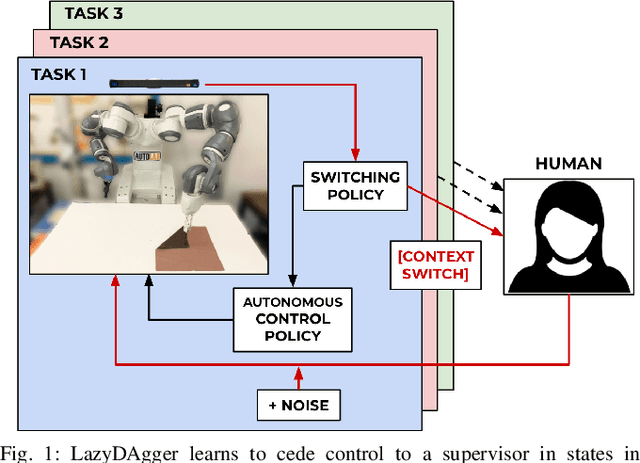
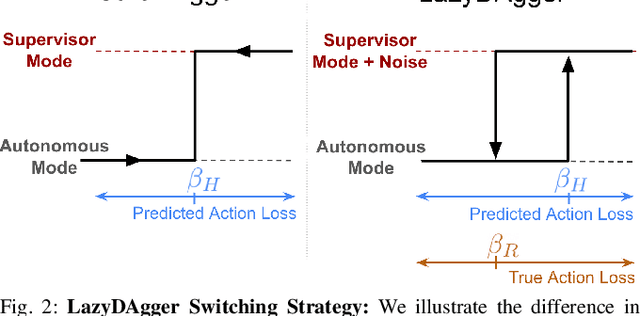
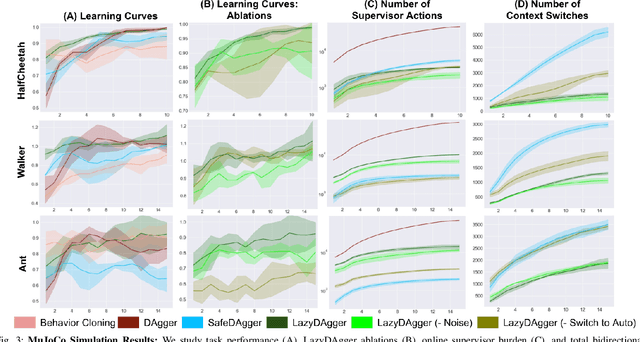
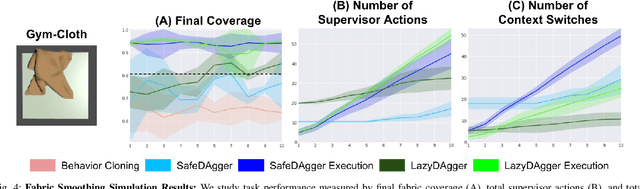
Corrective interventions while a robot is learning to automate a task provide an intuitive method for a human supervisor to assist the robot and convey information about desired behavior. However, these interventions can impose significant burden on a human supervisor, as each intervention interrupts other work the human is doing, incurs latency with each context switch between supervisor and autonomous control, and requires time to perform. We present LazyDAgger, which extends the interactive imitation learning (IL) algorithm SafeDAgger to reduce context switches between supervisor and autonomous control. We find that LazyDAgger improves the performance and robustness of the learned policy during both learning and execution while limiting burden on the supervisor. Simulation experiments suggest that LazyDAgger can reduce context switches by an average of 60% over SafeDAgger on 3 continuous control tasks while maintaining state-of-the-art policy performance. In physical fabric manipulation experiments with an ABB YuMi robot, LazyDAgger reduces context switches by 60% while achieving a 60% higher success rate than SafeDAgger at execution time.
VisuoSpatial Foresight for Physical Sequential Fabric Manipulation
Feb 19, 2021
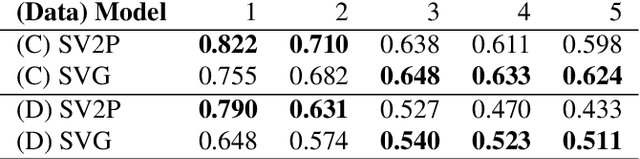
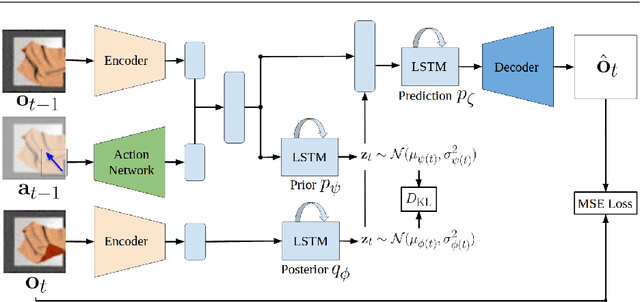
Robotic fabric manipulation has applications in home robotics, textiles, senior care and surgery. Existing fabric manipulation techniques, however, are designed for specific tasks, making it difficult to generalize across different but related tasks. We build upon the Visual Foresight framework to learn fabric dynamics that can be efficiently reused to accomplish different sequential fabric manipulation tasks with a single goal-conditioned policy. We extend our earlier work on VisuoSpatial Foresight (VSF), which learns visual dynamics on domain randomized RGB images and depth maps simultaneously and completely in simulation. In this earlier work, we evaluated VSF on multi-step fabric smoothing and folding tasks against 5 baseline methods in simulation and on the da Vinci Research Kit (dVRK) surgical robot without any demonstrations at train or test time. A key finding was that depth sensing significantly improves performance: RGBD data yields an 80% improvement in fabric folding success rate in simulation over pure RGB data. In this work, we vary 4 components of VSF, including data generation, the choice of visual dynamics model, cost function, and optimization procedure. Results suggest that training visual dynamics models using longer, corner-based actions can improve the efficiency of fabric folding by 76% and enable a physical sequential fabric folding task that VSF could not previously perform with 90% reliability. Code, data, videos, and supplementary material are available at https://sites.google.com/view/fabric-vsf/.
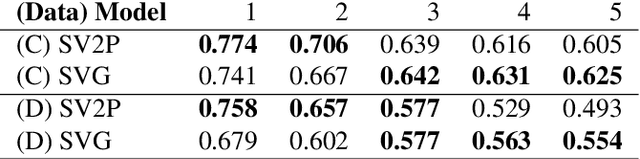
Exploratory Grasping: Asymptotically Optimal Algorithms for Grasping Challenging Polyhedral Objects
Nov 12, 2020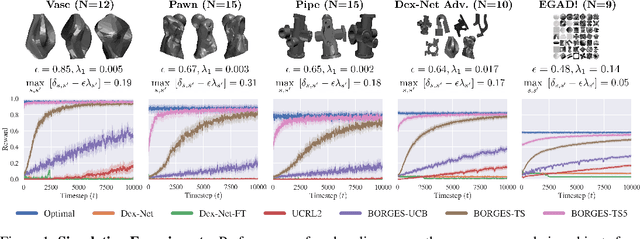
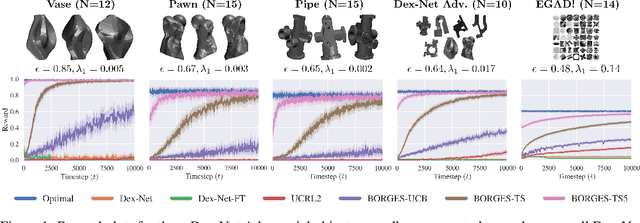
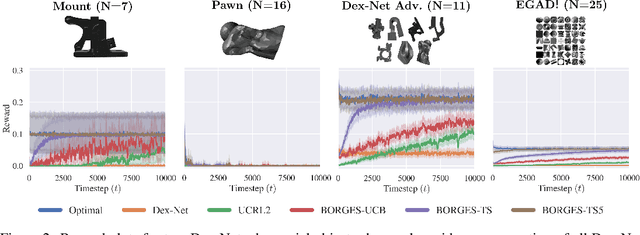
There has been significant recent work on data-driven algorithms for learning general-purpose grasping policies. However, these policies can consistently fail to grasp challenging objects which are significantly out of the distribution of objects in the training data or which have very few high quality grasps. Motivated by such objects, we propose a novel problem setting, Exploratory Grasping, for efficiently discovering reliable grasps on an unknown polyhedral object via sequential grasping, releasing, and toppling. We formalize Exploratory Grasping as a Markov Decision Process, study the theoretical complexity of Exploratory Grasping in the context of reinforcement learning and present an efficient bandit-style algorithm, Bandits for Online Rapid Grasp Exploration Strategy (BORGES), which leverages the structure of the problem to efficiently discover high performing grasps for each object stable pose. BORGES can be used to complement any general-purpose grasping algorithm with any grasp modality (parallel-jaw, suction, multi-fingered, etc) to learn policies for objects in which they exhibit persistent failures. Simulation experiments suggest that BORGES can significantly outperform both general-purpose grasping pipelines and two other online learning algorithms and achieves performance within 5% of the optimal policy within 1000 and 8000 timesteps on average across 46 challenging objects from the Dex-Net adversarial and EGAD! object datasets, respectively. Initial physical experiments suggest that BORGES can improve grasp success rate by 45% over a Dex-Net baseline with just 200 grasp attempts in the real world. See https://tinyurl.com/exp-grasping for supplementary material and videos.
Accelerating Grasp Exploration by Leveraging Learned Priors
Nov 11, 2020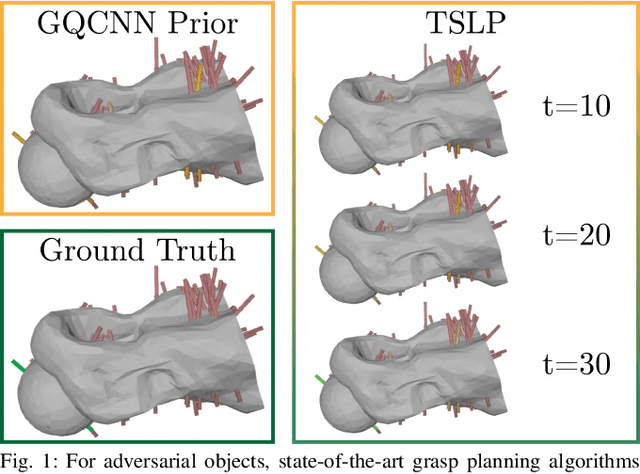
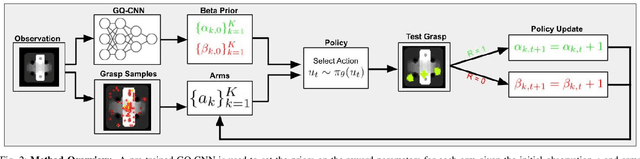
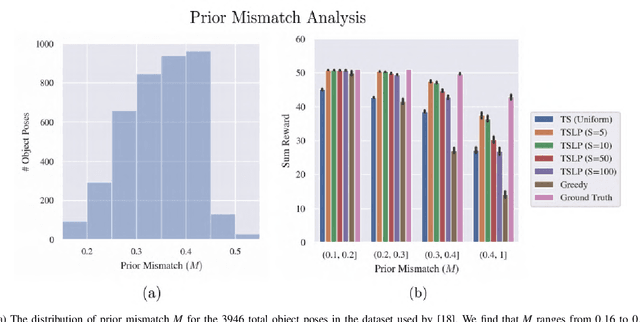
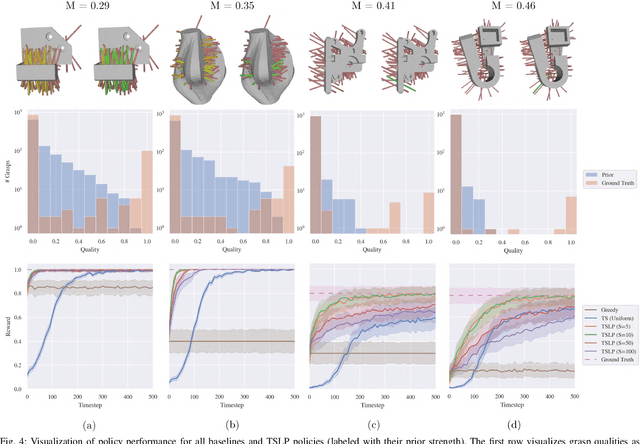
The ability of robots to grasp novel objects has industry applications in e-commerce order fulfillment and home service. Data-driven grasping policies have achieved success in learning general strategies for grasping arbitrary objects. However, these approaches can fail to grasp objects which have complex geometry or are significantly outside of the training distribution. We present a Thompson sampling algorithm that learns to grasp a given object with unknown geometry using online experience. The algorithm leverages learned priors from the Dexterity Network robot grasp planner to guide grasp exploration and provide probabilistic estimates of grasp success for each stable pose of the novel object. We find that seeding the policy with the Dex-Net prior allows it to more efficiently find robust grasps on these objects. Experiments suggest that the best learned policy attains an average total reward 64.5% higher than a greedy baseline and achieves within 5.7% of an oracle baseline when evaluated over 300,000 training runs across a set of 3000 object poses.
Untangling Dense Knots by Learning Task-Relevant Keypoints
Nov 10, 2020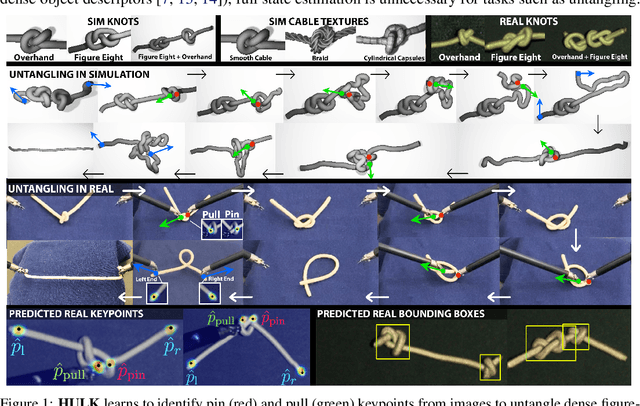
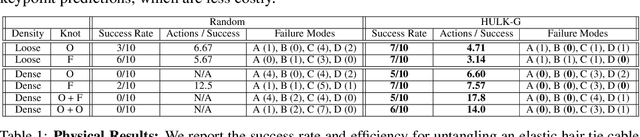
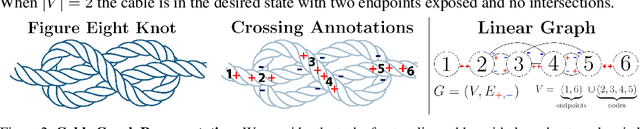

Untangling ropes, wires, and cables is a challenging task for robots due to the high-dimensional configuration space, visual homogeneity, self-occlusions, and complex dynamics. We consider dense (tight) knots that lack space between self-intersections and present an iterative approach that uses learned geometric structure in configurations. We instantiate this into an algorithm, HULK: Hierarchical Untangling from Learned Keypoints, which combines learning-based perception with a geometric planner into a policy that guides a bilateral robot to untangle knots. To evaluate the policy, we perform experiments both in a novel simulation environment modelling cables with varied knot types and textures and in a physical system using the da Vinci surgical robot. We find that HULK is able to untangle cables with dense figure-eight and overhand knots and generalize to varied textures and appearances. We compare two variants of HULK to three baselines and observe that HULK achieves 43.3% higher success rates on a physical system compared to the next best baseline. HULK successfully untangles a cable from a dense initial configuration containing up to two overhand and figure-eight knots in 97.9% of 378 simulation experiments with an average of 12.1 actions per trial. In physical experiments, HULK achieves 61.7% untangling success, averaging 8.48 actions per trial. Supplementary material, code, and videos can be found at https://tinyurl.com/y3a88ycu.
* Conference on Robot Learning (CoRL) 2020 Oral. First two authors contributed equally
Recovery RL: Safe Reinforcement Learning with Learned Recovery Zones
Oct 29, 2020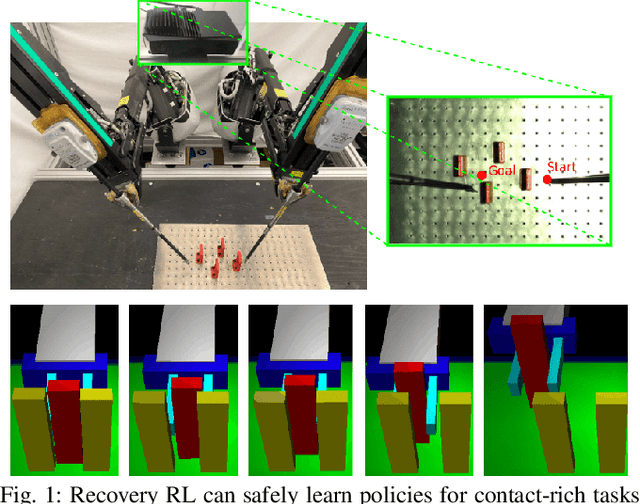
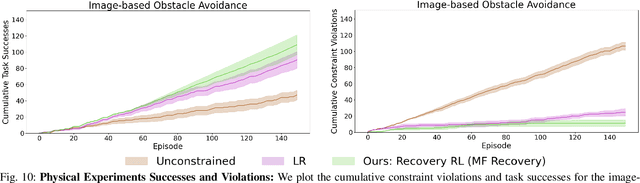
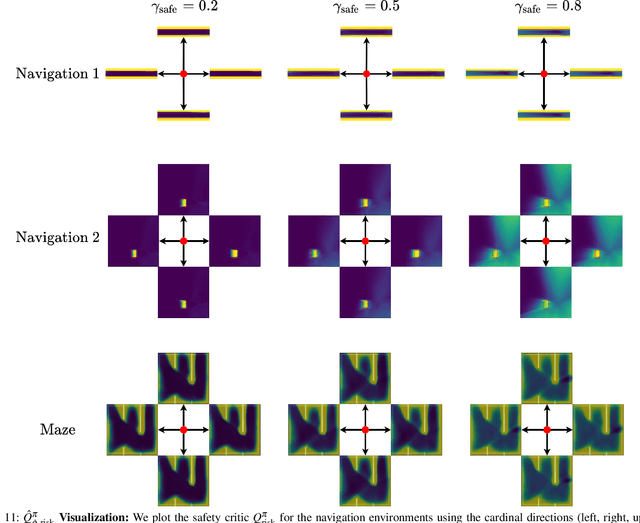
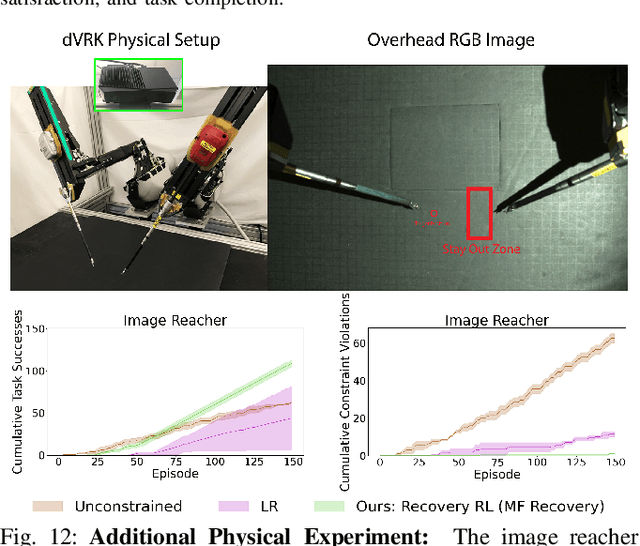
Safety remains a central obstacle preventing widespread use of RL in the real world: learning new tasks in uncertain environments requires extensive exploration, but safety requires limiting exploration. We propose Recovery RL, an algorithm which navigates this tradeoff by (1) leveraging offline data to learn about constraint violating zones before policy learning and (2) separating the goals of improving task performance and constraint satisfaction across two policies: a task policy that only optimizes the task reward and a recovery policy that guides the agent to safety when constraint violation is likely. We evaluate Recovery RL on 6 simulation domains, including two contact-rich manipulation tasks and an image-based navigation task, and an image-based obstacle avoidance task on a physical robot. We compare Recovery RL to 5 prior safe RL methods which jointly optimize for task performance and safety via constrained optimization or reward shaping and find that Recovery RL outperforms the next best prior method across all domains. Results suggest that Recovery RL trades off constraint violations and task successes 2 - 80 times more efficiently in simulation domains and 3 times more efficiently in physical experiments. See https://tinyurl.com/rl-recovery for videos and supplementary material.
MMGSD: Multi-Modal Gaussian Shape Descriptors for Correspondence Matching in 1D and 2D Deformable Objects
Oct 09, 2020
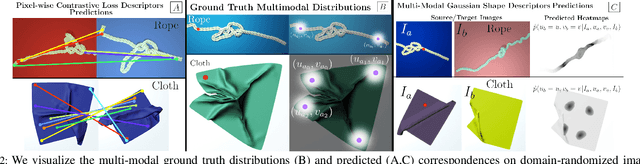
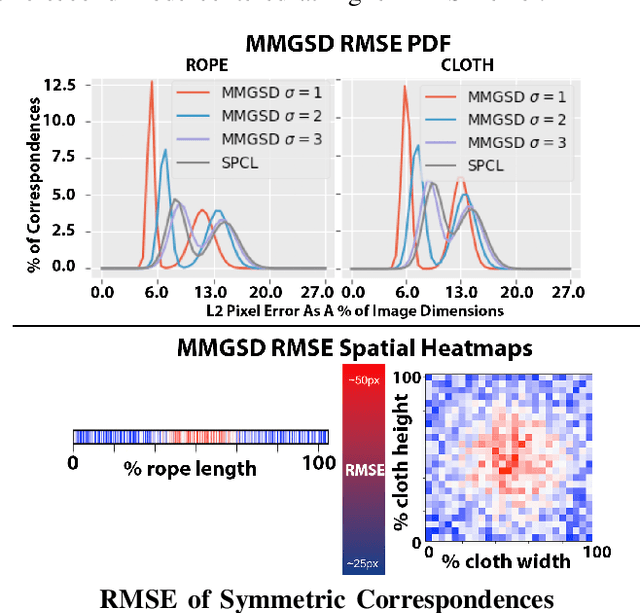
We explore learning pixelwise correspondences between images of deformable objects in different configurations. Traditional correspondence matching approaches such as SIFT, SURF, and ORB can fail to provide sufficient contextual information for fine-grained manipulation. We propose Multi-Modal Gaussian Shape Descriptor (MMGSD), a new visual representation of deformable objects which extends ideas from dense object descriptors to predict all symmetric correspondences between different object configurations. MMGSD is learned in a self-supervised manner from synthetic data and produces correspondence heatmaps with measurable uncertainty. In simulation, experiments suggest that MMGSD can achieve an RMSE of 32.4 and 31.3 for square cloth and braided synthetic nylon rope respectively. The results demonstrate an average of 47.7% improvement over a provided baseline based on contrastive learning, symmetric pixel-wise contrastive loss (SPCL), as opposed to MMGSD which enforces distributional continuity.
Learning to Smooth and Fold Real Fabric Using Dense Object Descriptors Trained on Synthetic Color Images
Mar 28, 2020
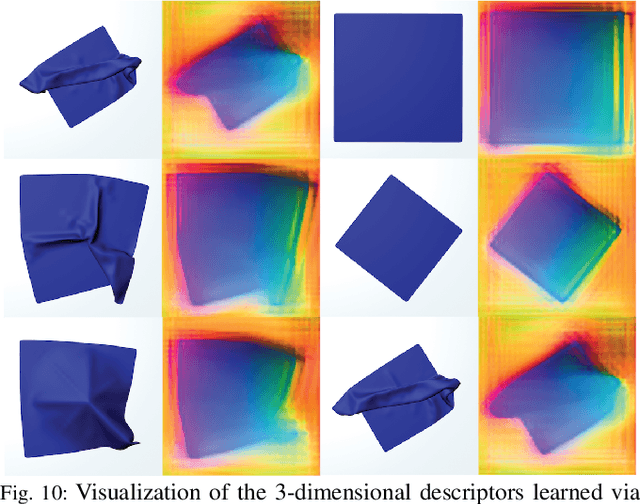


Robotic fabric manipulation is challenging due to the infinite dimensional configuration space and complex dynamics. In this paper, we learn visual representations of deformable fabric by training dense object descriptors that capture correspondences across images of fabric in various configurations. The learned descriptors capture higher level geometric structure, facilitating design of explainable policies. We demonstrate that the learned representation facilitates multistep fabric smoothing and folding tasks on two real physical systems, the da Vinci surgical robot and the ABB YuMi given high level demonstrations from a supervisor. The system achieves a 78.8% average task success rate across six fabric manipulation tasks. See https://tinyurl.com/fabric-descriptors for supplementary material and videos.