 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAn Introduction to Electrocatalyst Design using Machine Learning for Renewable Energy Storage
Oct 14, 2020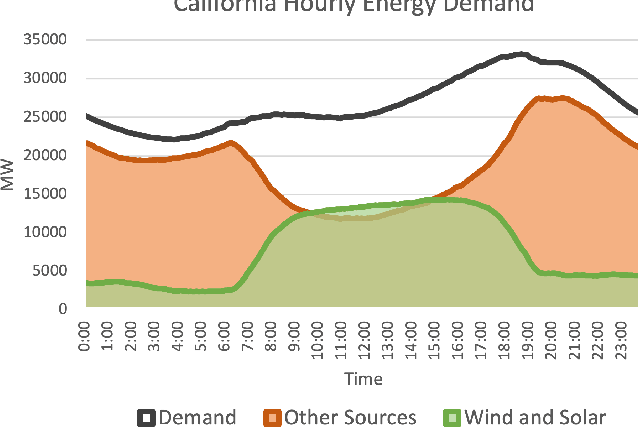
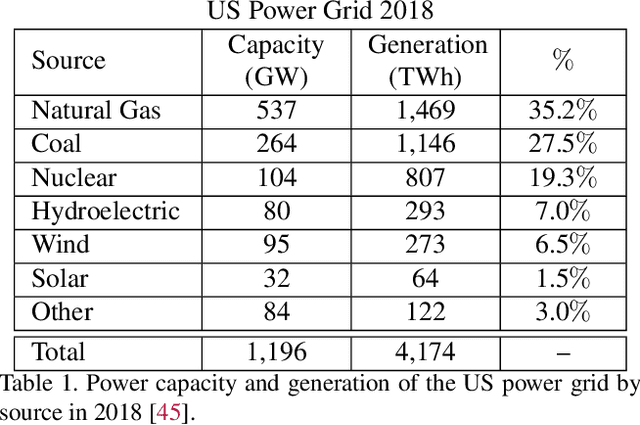
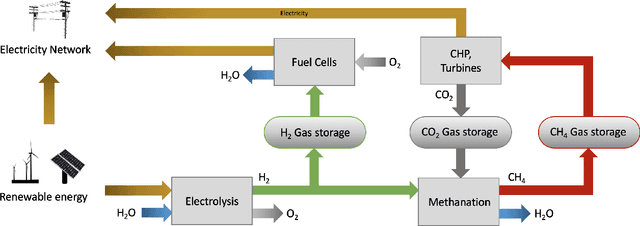
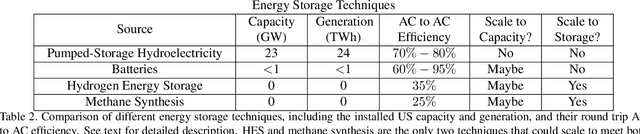
Scalable and cost-effective solutions to renewable energy storage are essential to addressing the world's rising energy needs while reducing climate change. As we increase our reliance on renewable energy sources such as wind and solar, which produce intermittent power, storage is needed to transfer power from times of peak generation to peak demand. This may require the storage of power for hours, days, or months. One solution that offers the potential of scaling to nation-sized grids is the conversion of renewable energy to other fuels, such as hydrogen or methane. To be widely adopted, this process requires cost-effective solutions to running electrochemical reactions. An open challenge is finding low-cost electrocatalysts to drive these reactions at high rates. Through the use of quantum mechanical simulations (density functional theory), new catalyst structures can be tested and evaluated. Unfortunately, the high computational cost of these simulations limits the number of structures that may be tested. The use of machine learning may provide a method to efficiently approximate these calculations, leading to new approaches in finding effective electrocatalysts. In this paper, we provide an introduction to the challenges in finding suitable electrocatalysts, how machine learning may be applied to the problem, and the use of the Open Catalyst Project OC20 dataset for model training.
Massively Multilingual ASR: 50 Languages, 1 Model, 1 Billion Parameters
Jul 08, 2020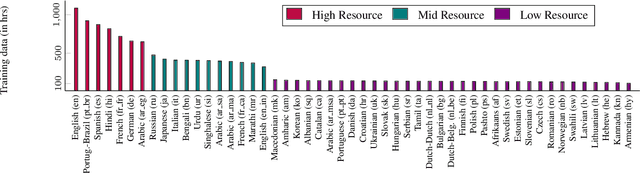
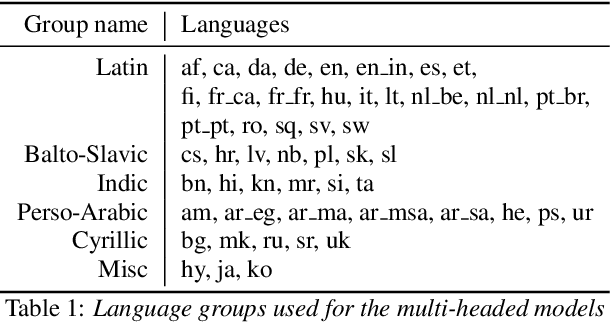
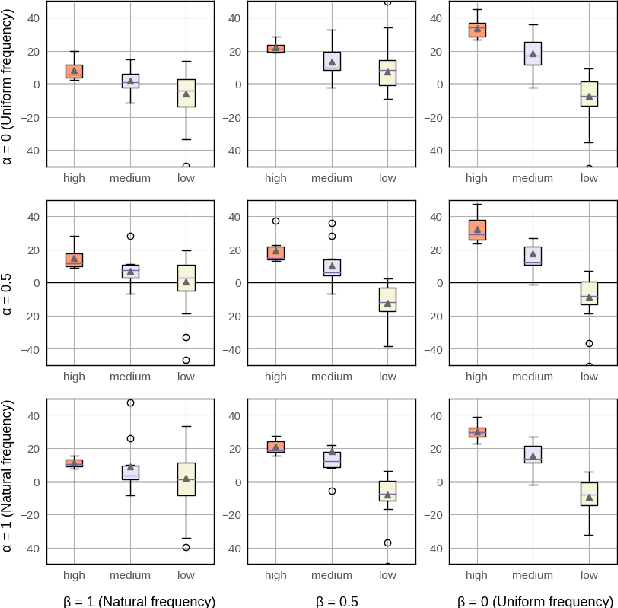
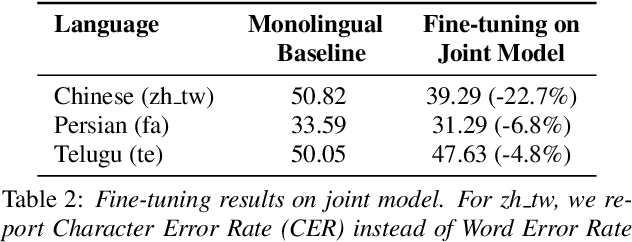
We study training a single acoustic model for multiple languages with the aim of improving automatic speech recognition (ASR) performance on low-resource languages, and over-all simplifying deployment of ASR systems that support diverse languages. We perform an extensive benchmark on 51 languages, with varying amount of training data by language(from 100 hours to 1100 hours). We compare three variants of multilingual training from a single joint model without knowing the input language, to using this information, to multiple heads (one per language cluster). We show that multilingual training of ASR models on several languages can improve recognition performance, in particular, on low resource languages. We see 20.9%, 23% and 28.8% average WER relative reduction compared to monolingual baselines on joint model, joint model with language input and multi head model respectively. To our knowledge, this is the first work studying multilingual ASR at massive scale, with more than 50 languages and more than 16,000 hours of audio across them.
End-to-End Variational Networks for Accelerated MRI Reconstruction
Apr 15, 2020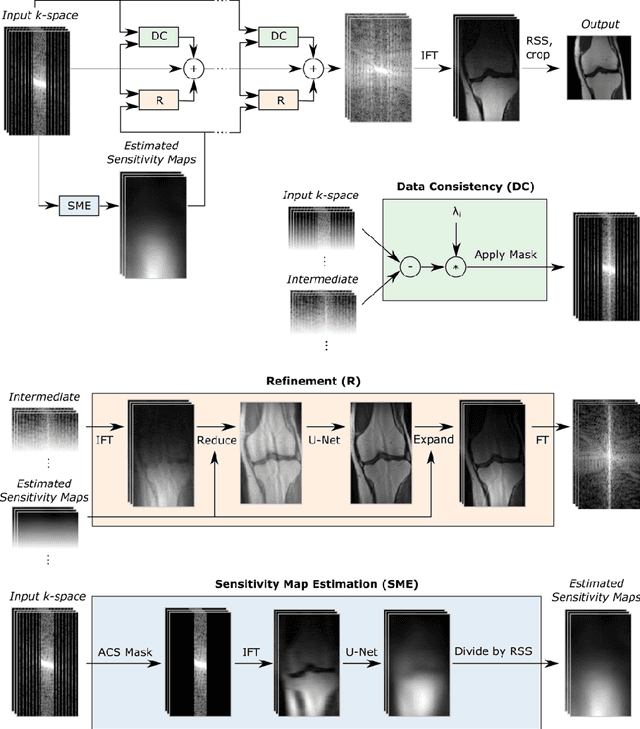
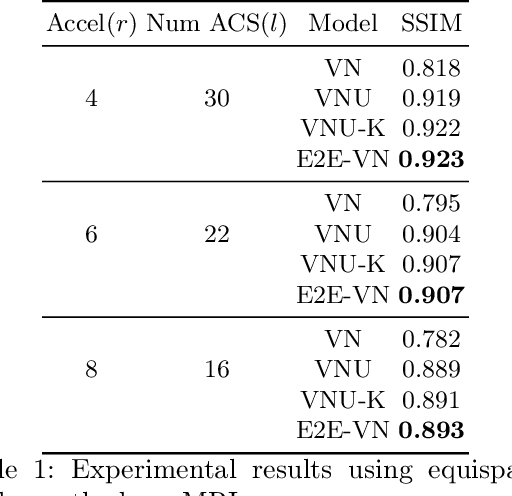
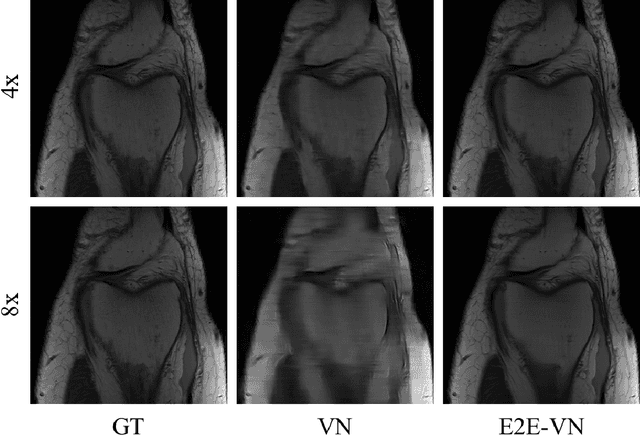
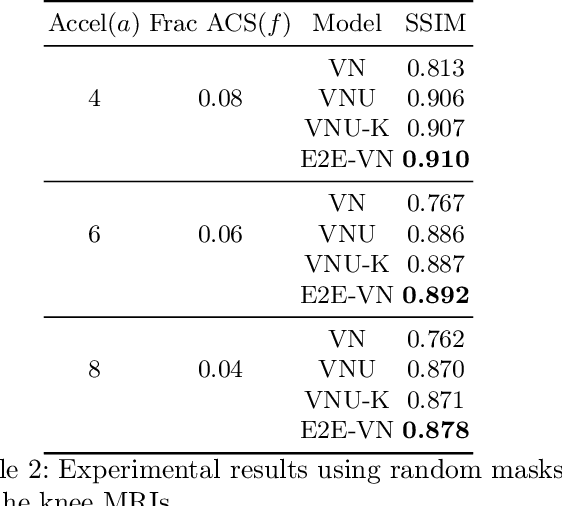
The slow acquisition speed of magnetic resonance imaging (MRI) has led to the development of two complementary methods: acquiring multiple views of the anatomy simultaneously (parallel imaging) and acquiring fewer samples than necessary for traditional signal processing methods (compressed sensing). While the combination of these methods has the potential to allow much faster scan times, reconstruction from such undersampled multi-coil data has remained an open problem. In this paper, we present a new approach to this problem that extends previously proposed variational methods by learning fully end-to-end. Our method obtains new state-of-the-art results on the fastMRI dataset for both brain and knee MRIs.
Advancing machine learning for MR image reconstruction with an open competition: Overview of the 2019 fastMRI challenge
Jan 06, 2020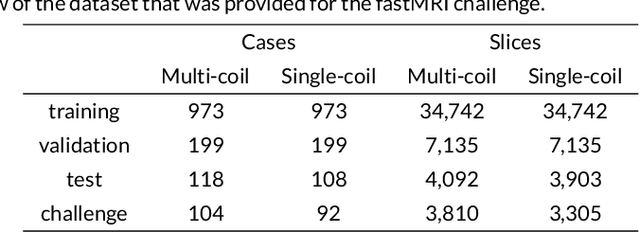
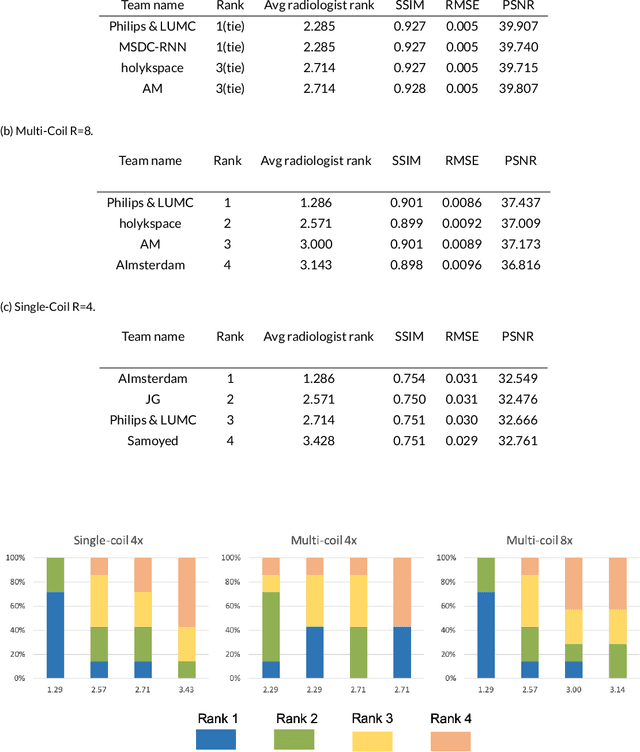

Purpose: To advance research in the field of machine learning for MR image reconstruction with an open challenge. Methods: We provided participants with a dataset of raw k-space data from 1,594 consecutive clinical exams of the knee. The goal of the challenge was to reconstruct images from these data. In order to strike a balance between realistic data and a shallow learning curve for those not already familiar with MR image reconstruction, we ran multiple tracks for multi-coil and single-coil data. We performed a two-stage evaluation based on quantitative image metrics followed by evaluation by a panel of radiologists. The challenge ran from June to December of 2019. Results: We received a total of 33 challenge submissions. All participants chose to submit results from supervised machine learning approaches. Conclusion: The challenge led to new developments in machine learning for image reconstruction, provided insight into the current state of the art in the field, and highlighted remaining hurdles for clinical adoption.
End-to-end ASR: from Supervised to Semi-Supervised Learning with Modern Architectures
Nov 19, 2019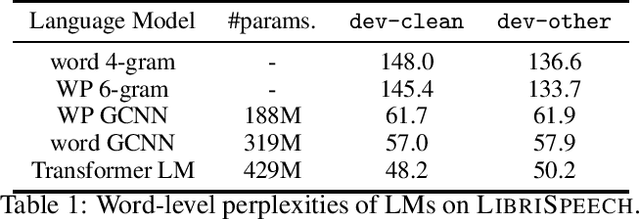
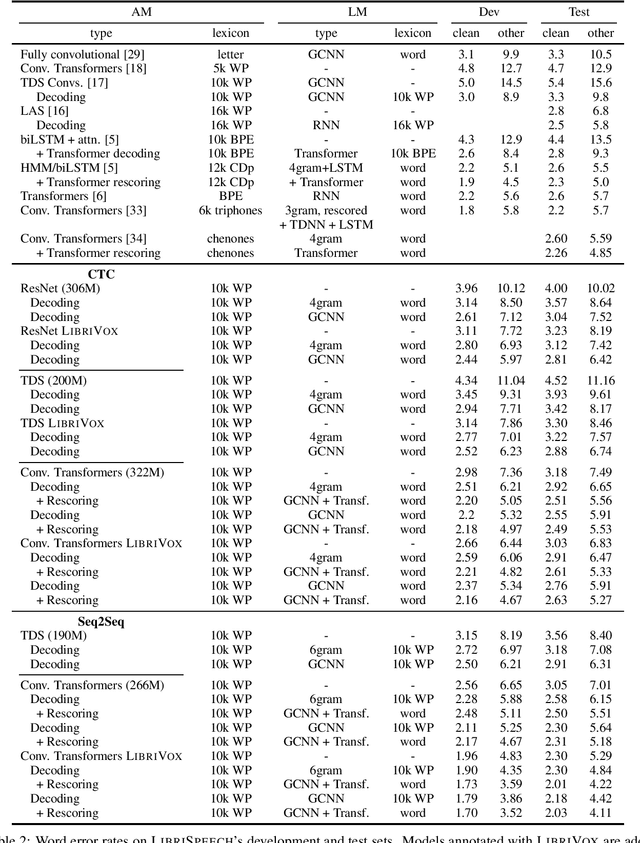
We study ResNet-, Time-Depth Separable ConvNets-, and Transformer-based acoustic models, trained with CTC or Seq2Seq criterions. We perform experiments on the LibriSpeech dataset, with and without LM decoding, optionally with beam rescoring. We reach 5.18% WER with external language models for decoding and rescoring. Additionally, we leverage the unlabeled data from LibriVox by doing semi-supervised training and show that it is possible to reach 5.29% WER on test-other without decoding, and 4.11% WER with decoding and rescoring, with only the standard 960 hours from LibriSpeech as labeled data.
RNN-T For Latency Controlled ASR With Improved Beam Search
Nov 05, 2019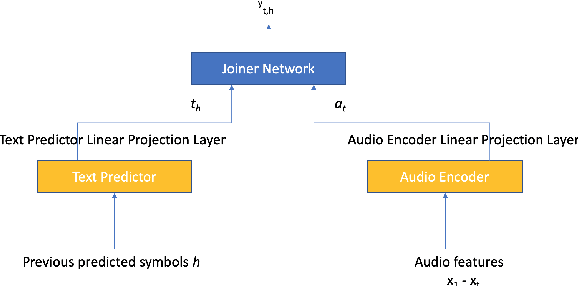

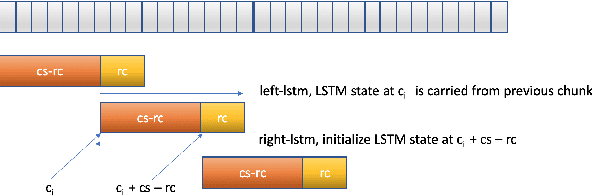
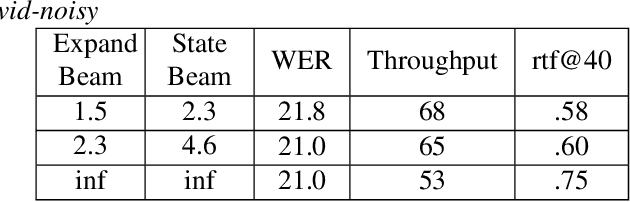
Neural transducer-based systems such as RNN Transducers (RNN-T) for automatic speech recognition (ASR) blend the individual components of a traditional hybrid ASR systems (acoustic model, language model, punctuation model, inverse text normalization) into one single model. This greatly simplifies training and inference and hence makes RNN-T a desirable choice for ASR systems. In this work, we investigate use of RNN-T in applications that require a tune-able latency budget during inference time. We also improved the decoding speed of the originally proposed RNN-T beam search algorithm. We evaluated our proposed system on English videos ASR dataset and show that neural RNN-T models can achieve comparable WER and better computational efficiency compared to a well tuned hybrid ASR baseline.
GrappaNet: Combining Parallel Imaging with Deep Learning for Multi-Coil MRI Reconstruction
Nov 04, 2019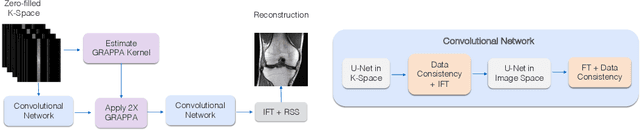
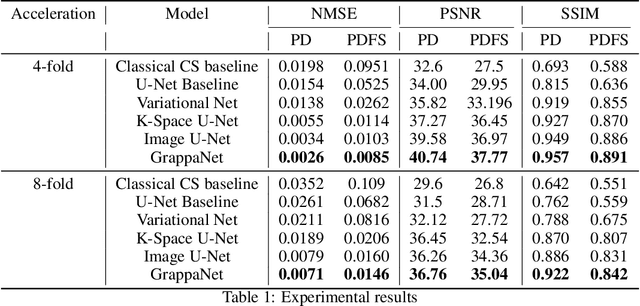
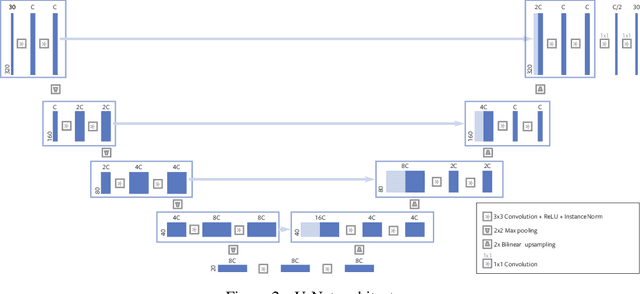
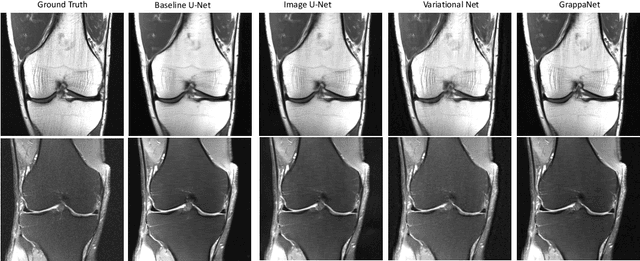
Magnetic Resonance Image (MRI) acquisition is an inherently slow process which has spurred the development of two different acceleration methods: acquiring multiple correlated samples simultaneously (parallel imaging) and acquiring fewer samples than necessary for traditional signal processing methods (compressed sensing). Both methods provide complementary approaches to accelerating the speed of MRI acquisition. In this paper, we present a novel method to integrate traditional parallel imaging methods into deep neural networks that is able to generate high quality reconstructions even for high acceleration factors. The proposed method, called GrappaNet, performs progressive reconstruction by first mapping the reconstruction problem to a simpler one that can be solved by a traditional parallel imaging methods using a neural network, followed by an application of a parallel imaging method, and finally fine-tuning the output with another neural network. The entire network can be trained end-to-end. We present experimental results on the recently released fastMRI dataset and show that GrappaNet can generate higher quality reconstructions than competing methods for both $4\times$ and $8\times$ acceleration.
fastMRI: An Open Dataset and Benchmarks for Accelerated MRI
Nov 21, 2018
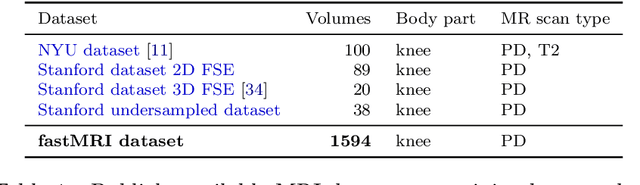
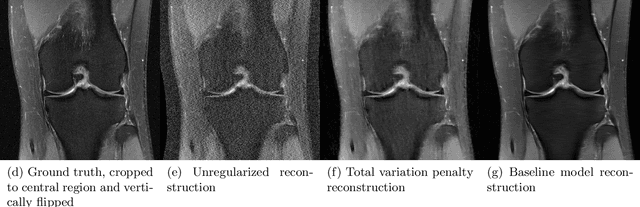
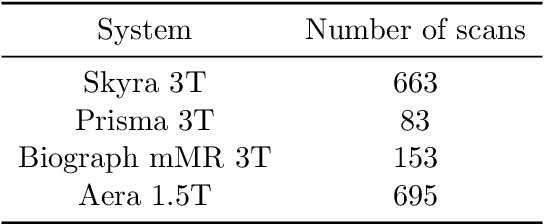
Accelerating Magnetic Resonance Imaging (MRI) by taking fewer measurements has the potential to reduce medical costs, minimize stress to patients and make MRI possible in applications where it is currently prohibitively slow or expensive. We introduce the fastMRI dataset, a large-scale collection of both raw MR measurements and clinical MR images, that can be used for training and evaluation of machine-learning approaches to MR image reconstruction. By introducing standardized evaluation criteria and a freely-accessible dataset, our goal is to help the community make rapid advances in the state of the art for MR image reconstruction. We also provide a self-contained introduction to MRI for machine learning researchers with no medical imaging background.
Robust Speech Recognition Using Generative Adversarial Networks
Nov 05, 2017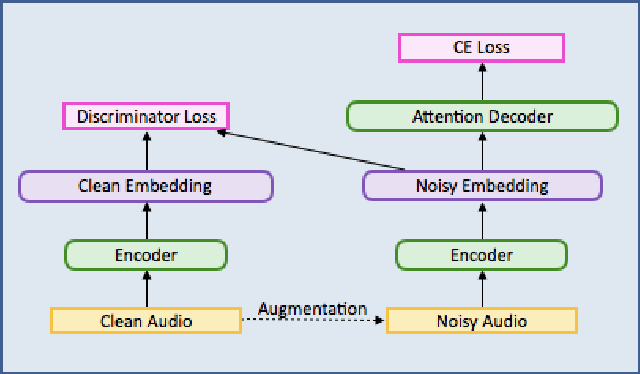
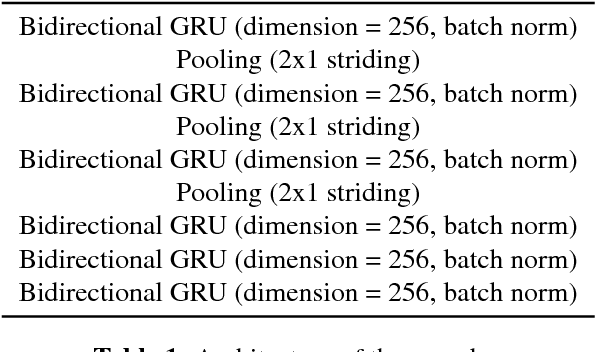

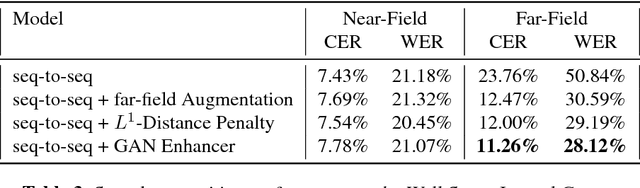
This paper describes a general, scalable, end-to-end framework that uses the generative adversarial network (GAN) objective to enable robust speech recognition. Encoders trained with the proposed approach enjoy improved invariance by learning to map noisy audio to the same embedding space as that of clean audio. Unlike previous methods, the new framework does not rely on domain expertise or simplifying assumptions as are often needed in signal processing, and directly encourages robustness in a data-driven way. We show the new approach improves simulated far-field speech recognition of vanilla sequence-to-sequence models without specialized front-ends or preprocessing.
Cold Fusion: Training Seq2Seq Models Together with Language Models
Aug 21, 2017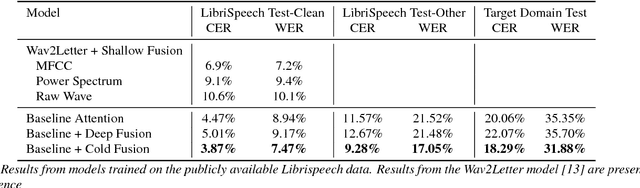
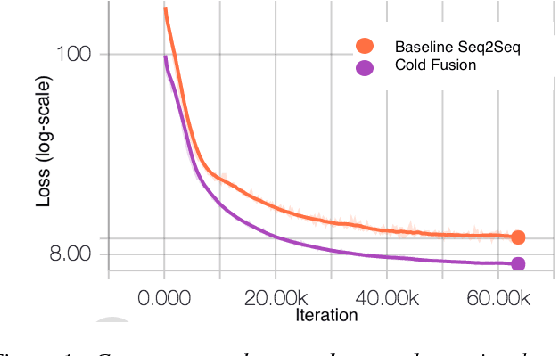
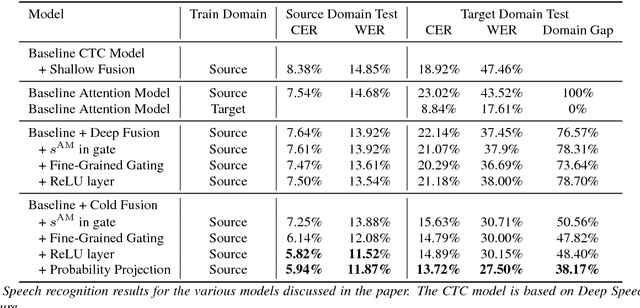
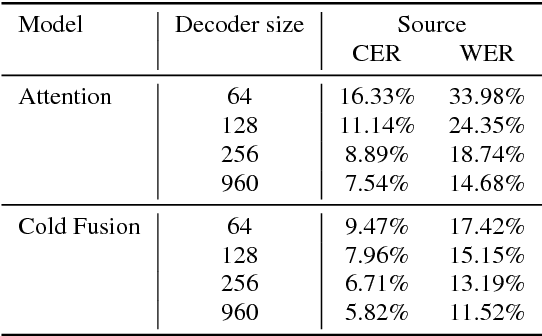
Sequence-to-sequence (Seq2Seq) models with attention have excelled at tasks which involve generating natural language sentences such as machine translation, image captioning and speech recognition. Performance has further been improved by leveraging unlabeled data, often in the form of a language model. In this work, we present the Cold Fusion method, which leverages a pre-trained language model during training, and show its effectiveness on the speech recognition task. We show that Seq2Seq models with Cold Fusion are able to better utilize language information enjoying i) faster convergence and better generalization, and ii) almost complete transfer to a new domain while using less than 10% of the labeled training data.