 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEvaluating the Utility of Grounding Documents with Reference-Free LLM-based Metrics
Jan 30, 2026Retrieval Augmented Generation (RAG)'s success depends on the utility the LLM derives from the content used for grounding. Quantifying content utility does not have a definitive specification and existing metrics ignore model-specific capabilities and/or rely on costly annotations. In this paper, we propose Grounding Generation Utility (GroGU), a model-specific and reference-free metric that defines utility as a function of the downstream LLM's generation confidence based on entropy. Despite having no annotation requirements, GroGU is largely faithful in distinguishing ground-truth documents while capturing nuances ignored by LLM-agnostic metrics. We apply GroGU to train a query-rewriter for RAG by identifying high-utility preference data for Direct Preference Optimization. Experiments show improvements by up to 18.2 points in Mean Reciprocal Rank and up to 9.4 points in answer accuracy.
Generative Product Recommendations for Implicit Superlative Queries
Apr 26, 2025In Recommender Systems, users often seek the best products through indirect, vague, or under-specified queries, such as "best shoes for trail running". Such queries, also referred to as implicit superlative queries, pose a significant challenge for standard retrieval and ranking systems as they lack an explicit mention of attributes and require identifying and reasoning over complex factors. We investigate how Large Language Models (LLMs) can generate implicit attributes for ranking as well as reason over them to improve product recommendations for such queries. As a first step, we propose a novel four-point schema for annotating the best product candidates for superlative queries called SUPERB, paired with LLM-based product annotations. We then empirically evaluate several existing retrieval and ranking approaches on our new dataset, providing insights and discussing their integration into real-world e-commerce production systems.
Generative Explore-Exploit: Training-free Optimization of Generative Recommender Systems using LLM Optimizers
Jun 07, 2024



Recommender systems are widely used to suggest engaging content, and Large Language Models (LLMs) have given rise to generative recommenders. Such systems can directly generate items, including for open-set tasks like question suggestion. While the world knowledge of LLMs enable good recommendations, improving the generated content through user feedback is challenging as continuously fine-tuning LLMs is prohibitively expensive. We present a training-free approach for optimizing generative recommenders by connecting user feedback loops to LLM-based optimizers. We propose a generative explore-exploit method that can not only exploit generated items with known high engagement, but also actively explore and discover hidden population preferences to improve recommendation quality. We evaluate our approach on question generation in two domains (e-commerce and general knowledge), and model user feedback with Click Through Rate (CTR). Experiments show our LLM-based explore-exploit approach can iteratively improve recommendations, and consistently increase CTR. Ablation analysis shows that generative exploration is key to learning user preferences, avoiding the pitfalls of greedy exploit-only approaches. A human evaluation strongly supports our quantitative findings.
Leveraging Interesting Facts to Enhance User Engagement with Conversational Interfaces
Apr 09, 2024



Conversational Task Assistants (CTAs) guide users in performing a multitude of activities, such as making recipes. However, ensuring that interactions remain engaging, interesting, and enjoyable for CTA users is not trivial, especially for time-consuming or challenging tasks. Grounded in psychological theories of human interest, we propose to engage users with contextual and interesting statements or facts during interactions with a multi-modal CTA, to reduce fatigue and task abandonment before a task is complete. To operationalize this idea, we train a high-performing classifier (82% F1-score) to automatically identify relevant and interesting facts for users. We use it to create an annotated dataset of task-specific interesting facts for the domain of cooking. Finally, we design and validate a dialogue policy to incorporate the identified relevant and interesting facts into a conversation, to improve user engagement and task completion. Live testing on a leading multi-modal voice assistant shows that 66% of the presented facts were received positively, leading to a 40% gain in the user satisfaction rating, and a 37% increase in conversation length. These findings emphasize that strategically incorporating interesting facts into the CTA experience can promote real-world user participation for guided task interactions.
Enhancing Low-Resource LLMs Classification with PEFT and Synthetic Data
Apr 03, 2024Large Language Models (LLMs) operating in 0-shot or few-shot settings achieve competitive results in Text Classification tasks. In-Context Learning (ICL) typically achieves better accuracy than the 0-shot setting, but it pays in terms of efficiency, due to the longer input prompt. In this paper, we propose a strategy to make LLMs as efficient as 0-shot text classifiers, while getting comparable or better accuracy than ICL. Our solution targets the low resource setting, i.e., when only 4 examples per class are available. Using a single LLM and few-shot real data we perform a sequence of generation, filtering and Parameter-Efficient Fine-Tuning steps to create a robust and efficient classifier. Experimental results show that our approach leads to competitive results on multiple text classification datasets.
Evaluation Metrics of Language Generation Models for Synthetic Traffic Generation Tasks
Nov 21, 2023Many Natural Language Generation (NLG) tasks aim to generate a single output text given an input prompt. Other settings require the generation of multiple texts, e.g., for Synthetic Traffic Generation (STG). This generation task is crucial for training and evaluating QA systems as well as conversational agents, where the goal is to generate multiple questions or utterances resembling the linguistic variability of real users. In this paper, we show that common NLG metrics, like BLEU, are not suitable for evaluating STG. We propose and evaluate several metrics designed to compare the generated traffic to the distribution of real user texts. We validate our metrics with an automatic procedure to verify whether they capture different types of quality issues of generated data; we also run human annotations to verify the correlation with human judgements. Experiments on three tasks, i.e., Shopping Utterance Generation, Product Question Generation and Query Auto Completion, demonstrate that our metrics are effective for evaluating STG tasks, and improve the agreement with human judgement up to 20% with respect to common NLG metrics. We believe these findings can pave the way towards better solutions for estimating the representativeness of synthetic text data.
Follow-on Question Suggestion via Voice Hints for Voice Assistants
Oct 25, 2023The adoption of voice assistants like Alexa or Siri has grown rapidly, allowing users to instantly access information via voice search. Query suggestion is a standard feature of screen-based search experiences, allowing users to explore additional topics. However, this is not trivial to implement in voice-based settings. To enable this, we tackle the novel task of suggesting questions with compact and natural voice hints to allow users to ask follow-up questions. We define the task, ground it in syntactic theory and outline linguistic desiderata for spoken hints. We propose baselines and an approach using sequence-to-sequence Transformers to generate spoken hints from a list of questions. Using a new dataset of 6681 input questions and human written hints, we evaluated the models with automatic metrics and human evaluation. Results show that a naive approach of concatenating suggested questions creates poor voice hints. Our approach, which applies a linguistically-motivated pretraining task was strongly preferred by humans for producing the most natural hints.
Preventing Catastrophic Forgetting in Continual Learning of New Natural Language Tasks
Feb 22, 2023



Multi-Task Learning (MTL) is widely-accepted in Natural Language Processing as a standard technique for learning multiple related tasks in one model. Training an MTL model requires having the training data for all tasks available at the same time. As systems usually evolve over time, (e.g., to support new functionalities), adding a new task to an existing MTL model usually requires retraining the model from scratch on all the tasks and this can be time-consuming and computationally expensive. Moreover, in some scenarios, the data used to train the original training may be no longer available, for example, due to storage or privacy concerns. In this paper, we approach the problem of incrementally expanding MTL models' capability to solve new tasks over time by distilling the knowledge of an already trained model on n tasks into a new one for solving n+1 tasks. To avoid catastrophic forgetting, we propose to exploit unlabeled data from the same distributions of the old tasks. Our experiments on publicly available benchmarks show that such a technique dramatically benefits the distillation by preserving the already acquired knowledge (i.e., preventing up to 20% performance drops on old tasks) while obtaining good performance on the incrementally added tasks. Further, we also show that our approach is beneficial in practical settings by using data from a leading voice assistant.
Alexa, Let's Work Together: Introducing the First Alexa Prize TaskBot Challenge on Conversational Task Assistance
Sep 13, 2022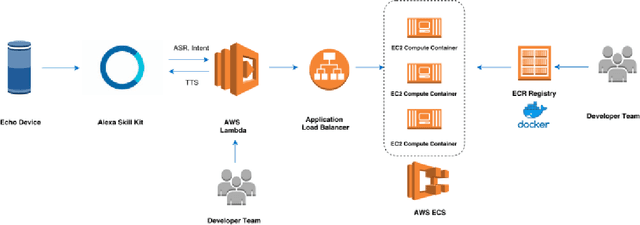
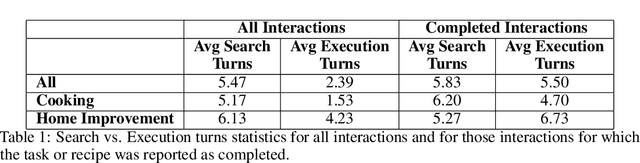
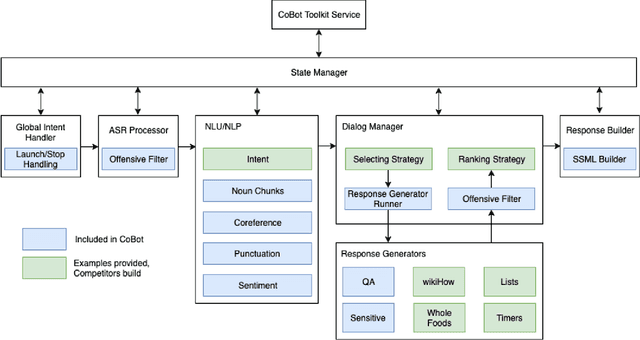

Since its inception in 2016, the Alexa Prize program has enabled hundreds of university students to explore and compete to develop conversational agents through the SocialBot Grand Challenge. The goal of the challenge is to build agents capable of conversing coherently and engagingly with humans on popular topics for 20 minutes, while achieving an average rating of at least 4.0/5.0. However, as conversational agents attempt to assist users with increasingly complex tasks, new conversational AI techniques and evaluation platforms are needed. The Alexa Prize TaskBot challenge, established in 2021, builds on the success of the SocialBot challenge by introducing the requirements of interactively assisting humans with real-world Cooking and Do-It-Yourself tasks, while making use of both voice and visual modalities. This challenge requires the TaskBots to identify and understand the user's need, identify and integrate task and domain knowledge into the interaction, and develop new ways of engaging the user without distracting them from the task at hand, among other challenges. This paper provides an overview of the TaskBot challenge, describes the infrastructure support provided to the teams with the CoBot Toolkit, and summarizes the approaches the participating teams took to overcome the research challenges. Finally, it analyzes the performance of the competing TaskBots during the first year of the competition.
Almawave-SLU: A new dataset for SLU in Italian
Jul 17, 2019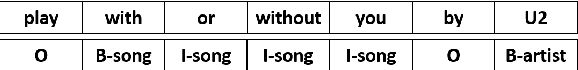

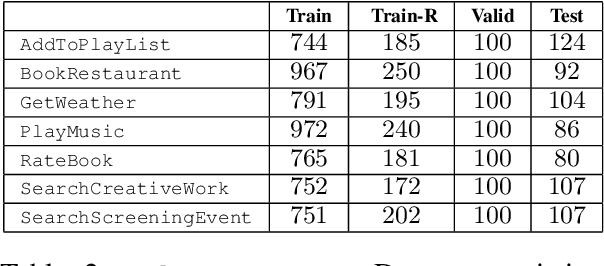
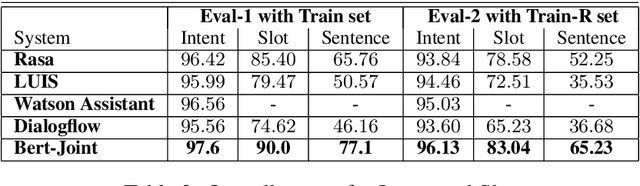
The widespread use of conversational and question answering systems made it necessary to improve the performances of speaker intent detection and understanding of related semantic slots, i.e., Spoken Language Understanding (SLU). Often, these tasks are approached with supervised learning methods, which needs considerable labeled datasets. This paper presents the first Italian dataset for SLU. It is derived through a semi-automatic procedure and is used as a benchmark of various open source and commercial systems.