 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Convolutional Approach to Vertebrae Detection and Labelling in Whole Spine MRI
Jul 13, 2020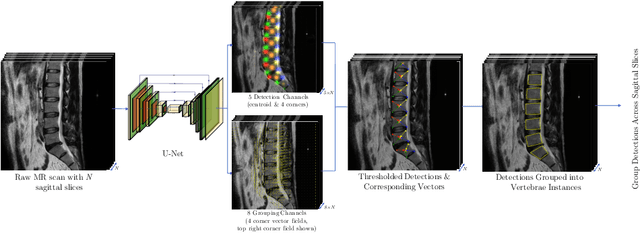
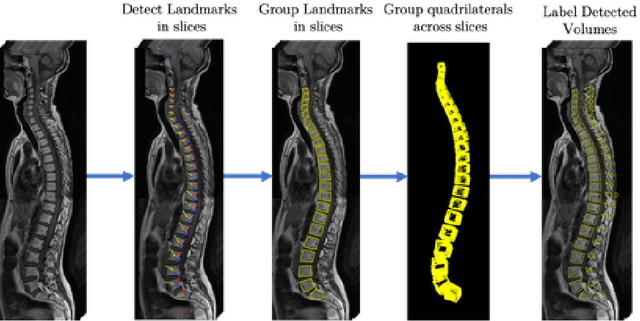

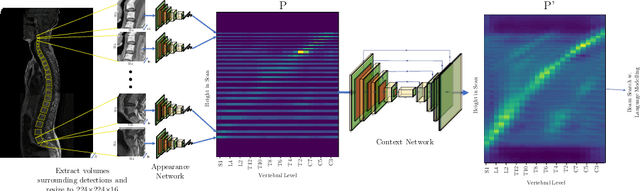
We propose a novel convolutional method for the detection and identification of vertebrae in whole spine MRIs. This involves using a learnt vector field to group detected vertebrae corners together into individual vertebral bodies and convolutional image-to-image translation followed by beam search to label vertebral levels in a self-consistent manner. The method can be applied without modification to lumbar, cervical and thoracic-only scans across a range of different MR sequences. The resulting system achieves 98.1% detection rate and 96.5% identification rate on a challenging clinical dataset of whole spine scans and matches or exceeds the performance of previous systems on lumbar-only scans. Finally, we demonstrate the clinical applicability of this method, using it for automated scoliosis detection in both lumbar and whole spine MR scans.
Spot the conversation: speaker diarisation in the wild
Jul 02, 2020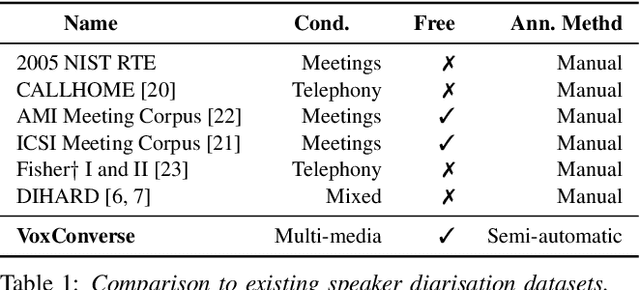
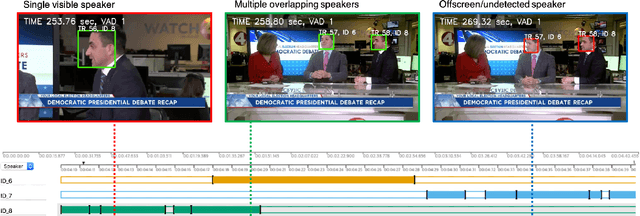

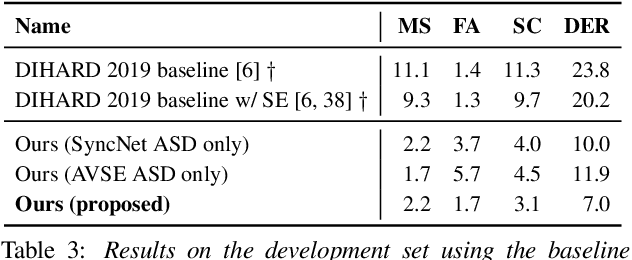
The goal of this paper is speaker diarisation of videos collected 'in the wild'. We make three key contributions. First, we propose an automatic audio-visual diarisation method for YouTube videos. Our method consists of active speaker detection using audio-visual methods and speaker verification using self-enrolled speaker models. Second, we integrate our method into a semi-automatic dataset creation pipeline which significantly reduces the number of hours required to annotate videos with diarisation labels. Finally, we use this pipeline to create a large-scale diarisation dataset called VoxConverse, collected from 'in the wild' videos, which we will release publicly to the research community. Our dataset consists of overlapping speech, a large and diverse speaker pool, and challenging background conditions.
Self-Supervised MultiModal Versatile Networks
Jun 29, 2020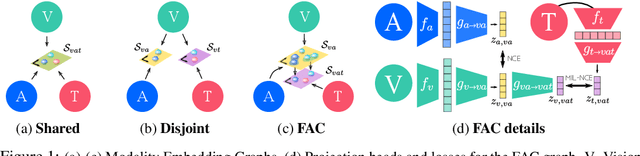
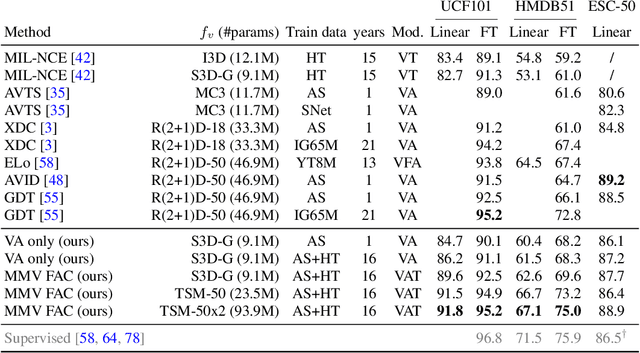
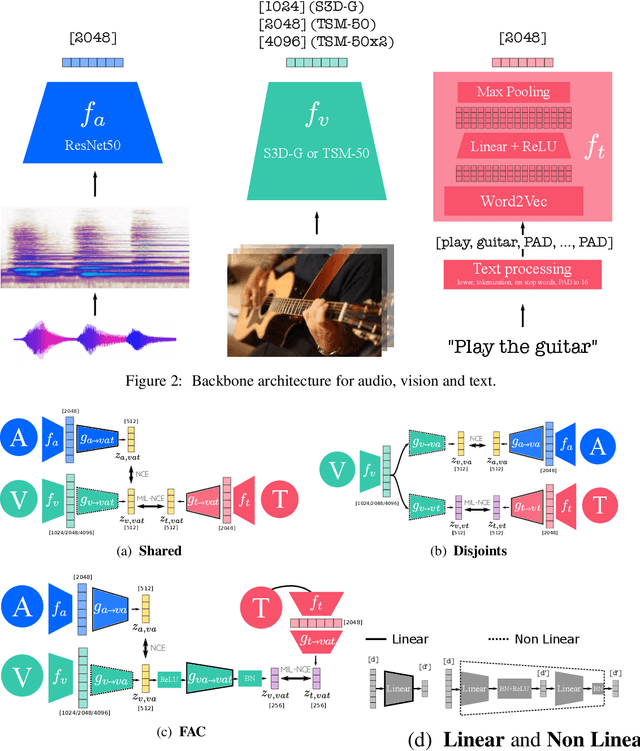
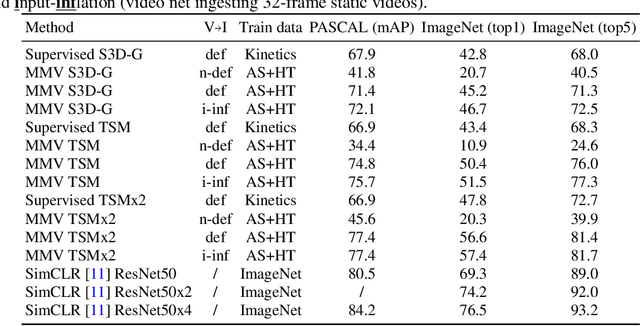
Videos are a rich source of multi-modal supervision. In this work, we learn representations using self-supervision by leveraging three modalities naturally present in videos: vision, audio and language. To this end, we introduce the notion of a multimodal versatile network -- a network that can ingest multiple modalities and whose representations enable downstream tasks in multiple modalities. In particular, we explore how best to combine the modalities, such that fine-grained representations of audio and vision can be maintained, whilst also integrating text into a common embedding. Driven by versatility, we also introduce a novel process of deflation, so that the networks can be effortlessly applied to the visual data in the form of video or a static image. We demonstrate how such networks trained on large collections of unlabelled video data can be applied on video, video-text, image and audio tasks. Equipped with these representations, we obtain state-of-the-art performance on multiple challenging benchmarks including UCF101, HMDB51 and ESC-50 when compared to previous self-supervised work.
Counting Out Time: Class Agnostic Video Repetition Counting in the Wild
Jun 27, 2020
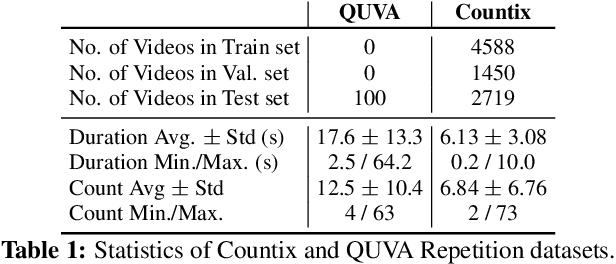


We present an approach for estimating the period with which an action is repeated in a video. The crux of the approach lies in constraining the period prediction module to use temporal self-similarity as an intermediate representation bottleneck that allows generalization to unseen repetitions in videos in the wild. We train this model, called Repnet, with a synthetic dataset that is generated from a large unlabeled video collection by sampling short clips of varying lengths and repeating them with different periods and counts. This combination of synthetic data and a powerful yet constrained model, allows us to predict periods in a class-agnostic fashion. Our model substantially exceeds the state of the art performance on existing periodicity (PERTUBE) and repetition counting (QUVA) benchmarks. We also collect a new challenging dataset called Countix (~90 times larger than existing datasets) which captures the challenges of repetition counting in real-world videos. Project webpage: https://sites.google.com/view/repnet .
LSD-C: Linearly Separable Deep Clusters
Jun 17, 2020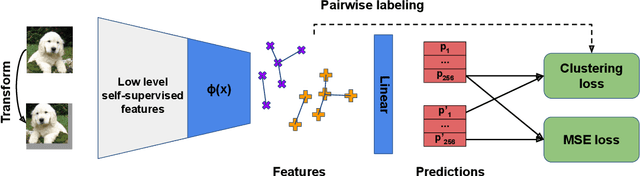



We present LSD-C, a novel method to identify clusters in an unlabeled dataset. Our algorithm first establishes pairwise connections in the feature space between the samples of the minibatch based on a similarity metric. Then it regroups in clusters the connected samples and enforces a linear separation between clusters. This is achieved by using the pairwise connections as targets together with a binary cross-entropy loss on the predictions that the associated pairs of samples belong to the same cluster. This way, the feature representation of the network will evolve such that similar samples in this feature space will belong to the same linearly separated cluster. Our method draws inspiration from recent semi-supervised learning practice and proposes to combine our clustering algorithm with self-supervised pretraining and strong data augmentation. We show that our approach significantly outperforms competitors on popular public image benchmarks including CIFAR 10/100, STL 10 and MNIST, as well as the document classification dataset Reuters 10K.
The AVA-Kinetics Localized Human Actions Video Dataset
May 20, 2020
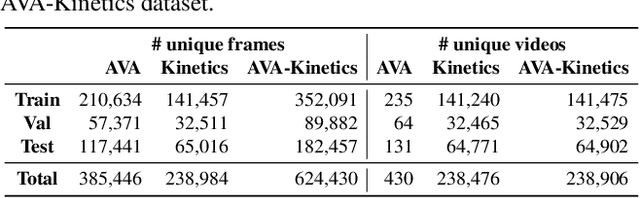
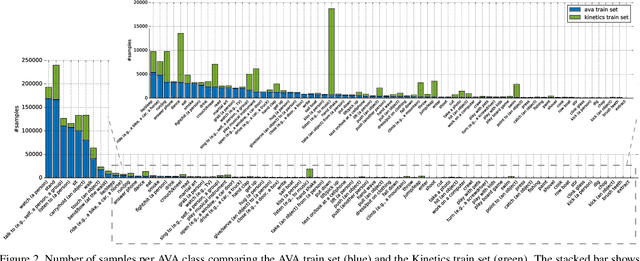
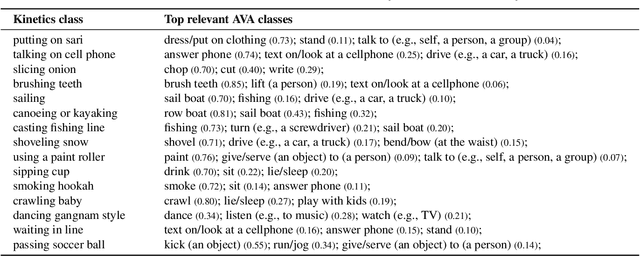
This paper describes the AVA-Kinetics localized human actions video dataset. The dataset is collected by annotating videos from the Kinetics-700 dataset using the AVA annotation protocol, and extending the original AVA dataset with these new AVA annotated Kinetics clips. The dataset contains over 230k clips annotated with the 80 AVA action classes for each of the humans in key-frames. We describe the annotation process and provide statistics about the new dataset. We also include a baseline evaluation using the Video Action Transformer Network on the AVA-Kinetics dataset, demonstrating improved performance for action classification on the AVA test set. The dataset can be downloaded from https://research.google.com/ava/
Condensed Movies: Story Based Retrieval with Contextual Embeddings
May 08, 2020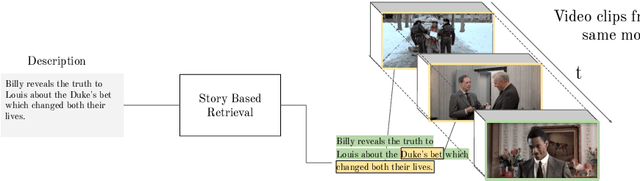
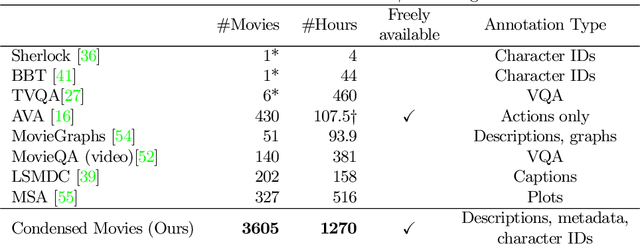
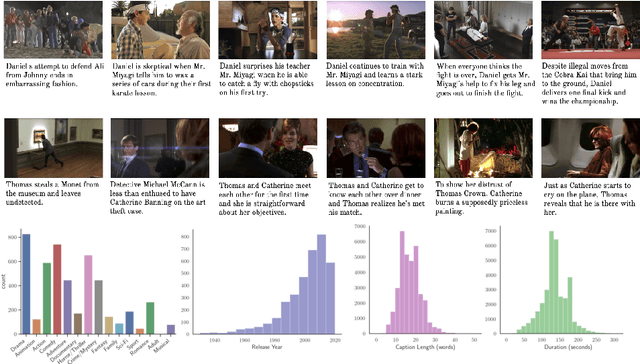

Our objective in this work is the long range understanding of the narrative structure of movies. Instead of considering the entire movie, we propose to learn from the key scenes of the movie, providing a condensed look at the full storyline. To this end, we make the following four contributions: (i) We create the Condensed Movie Dataset (CMD) consisting of the key scenes from over 3K movies: each key scene is accompanied by a high level semantic description of the scene, character face tracks, and metadata about the movie. Our dataset is scalable, obtained automatically from YouTube, and is freely available for anybody to download and use. It is also an order of magnitude larger than existing movie datasets in the number of movies; (ii) We introduce a new story-based text-to-video retrieval task on this dataset that requires a high level understanding of the plotline; (iii) We provide a deep network baseline for this task on our dataset, combining character, speech and visual cues into a single video embedding; and finally (iv) We demonstrate how the addition of context (both past and future) improves retrieval performance.
VGGSound: A Large-scale Audio-Visual Dataset
Apr 29, 2020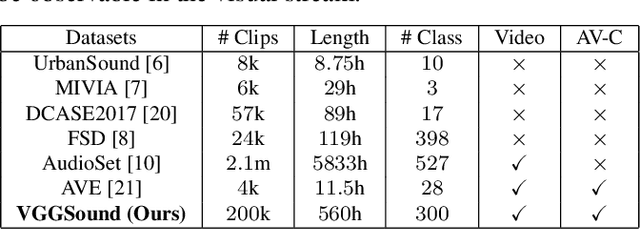
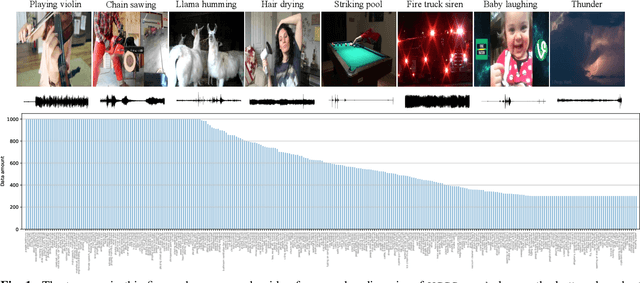

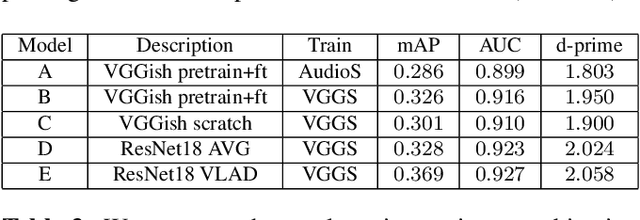
Our goal is to collect a large-scale audio-visual dataset with low label noise from videos in the wild using computer vision techniques. The resulting dataset can be used for training and evaluating audio recognition models. We make three contributions. First, we propose a scalable pipeline based on computer vision techniques to create an audio dataset from open-source media. Our pipeline involves obtaining videos from YouTube; using image classification algorithms to localize audio-visual correspondence; and filtering out ambient noise using audio verification. Second, we use this pipeline to curate the VGGSound dataset consisting of more than 210k videos for 310 audio classes. Third, we investigate various Convolutional Neural Network~(CNN) architectures and aggregation approaches to establish audio recognition baselines for our new dataset. Compared to existing audio datasets, VGGSound ensures audio-visual correspondence and is collected under unconstrained conditions. Code and the dataset are available at http://www.robots.ox.ac.uk/~vgg/data/vggsound/
Monocular Depth Estimation with Self-supervised Instance Adaptation
Apr 13, 2020
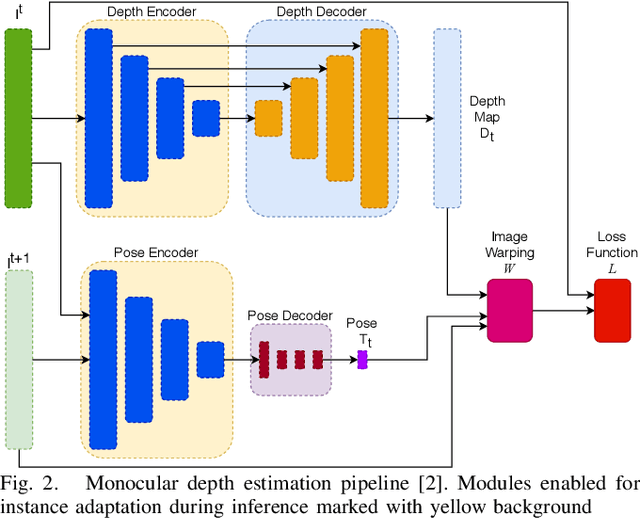
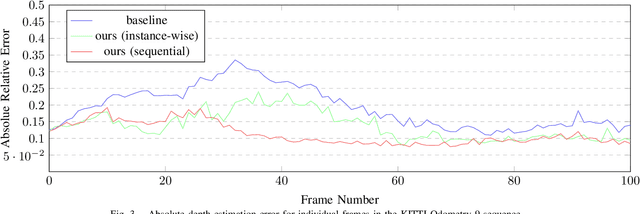
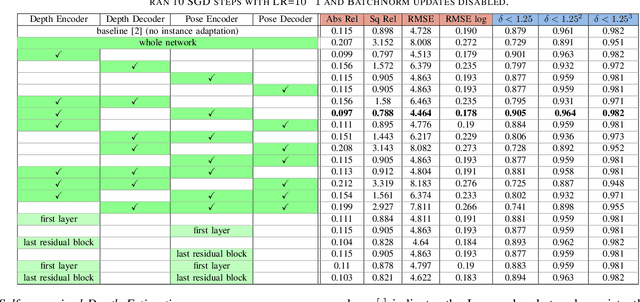
Recent advances in self-supervised learning havedemonstrated that it is possible to learn accurate monoculardepth reconstruction from raw video data, without using any 3Dground truth for supervision. However, in robotics applications,multiple views of a scene may or may not be available, depend-ing on the actions of the robot, switching between monocularand multi-view reconstruction. To address this mixed setting,we proposed a new approach that extends any off-the-shelfself-supervised monocular depth reconstruction system to usemore than one image at test time. Our method builds on astandard prior learned to perform monocular reconstruction,but uses self-supervision at test time to further improve thereconstruction accuracy when multiple images are available.When used to update the correct components of the model, thisapproach is highly-effective. On the standard KITTI bench-mark, our self-supervised method consistently outperformsall the previous methods with an average 25% reduction inabsolute error for the three common setups (monocular, stereoand monocular+stereo), and comes very close in accuracy whencompared to the fully-supervised state-of-the-art methods.
Speech2Action: Cross-modal Supervision for Action Recognition
Mar 30, 2020

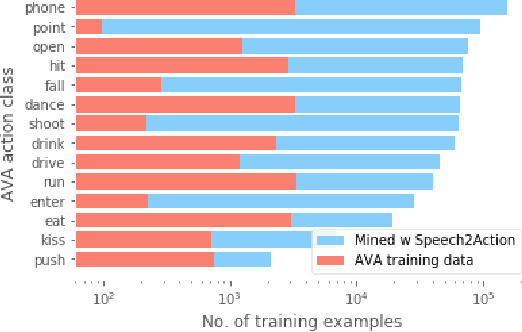
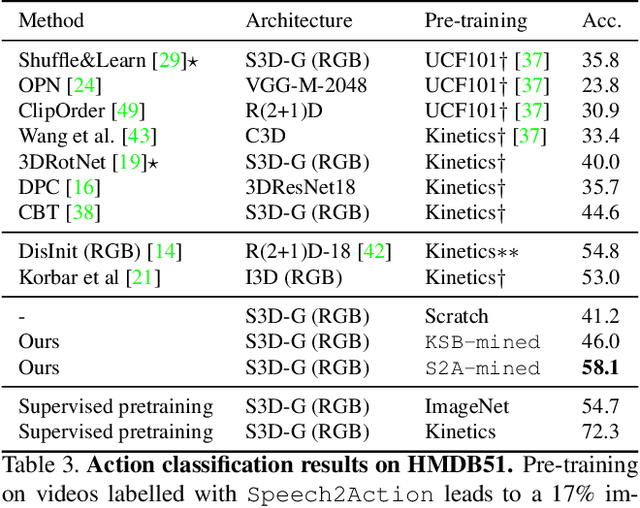
Is it possible to guess human action from dialogue alone? In this work we investigate the link between spoken words and actions in movies. We note that movie screenplays describe actions, as well as contain the speech of characters and hence can be used to learn this correlation with no additional supervision. We train a BERT-based Speech2Action classifier on over a thousand movie screenplays, to predict action labels from transcribed speech segments. We then apply this model to the speech segments of a large unlabelled movie corpus (188M speech segments from 288K movies). Using the predictions of this model, we obtain weak action labels for over 800K video clips. By training on these video clips, we demonstrate superior action recognition performance on standard action recognition benchmarks, without using a single manually labelled action example.