 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFasterViT: Fast Vision Transformers with Hierarchical Attention
Jun 09, 2023We design a new family of hybrid CNN-ViT neural networks, named FasterViT, with a focus on high image throughput for computer vision (CV) applications. FasterViT combines the benefits of fast local representation learning in CNNs and global modeling properties in ViT. Our newly introduced Hierarchical Attention (HAT) approach decomposes global self-attention with quadratic complexity into a multi-level attention with reduced computational costs. We benefit from efficient window-based self-attention. Each window has access to dedicated carrier tokens that participate in local and global representation learning. At a high level, global self-attentions enable the efficient cross-window communication at lower costs. FasterViT achieves a SOTA Pareto-front in terms of accuracy \vs image throughput. We have extensively validated its effectiveness on various CV tasks including classification, object detection and segmentation. We also show that HAT can be used as a plug-and-play module for existing networks and enhance them. We further demonstrate significantly faster and more accurate performance than competitive counterparts for images with high resolution. Code is available at https://github.com/NVlabs/FasterViT.
Progressive Learning of 3D Reconstruction Network from 2D GAN Data
May 18, 2023



This paper presents a method to reconstruct high-quality textured 3D models from single images. Current methods rely on datasets with expensive annotations; multi-view images and their camera parameters. Our method relies on GAN generated multi-view image datasets which have a negligible annotation cost. However, they are not strictly multi-view consistent and sometimes GANs output distorted images. This results in degraded reconstruction qualities. In this work, to overcome these limitations of generated datasets, we have two main contributions which lead us to achieve state-of-the-art results on challenging objects: 1) A robust multi-stage learning scheme that gradually relies more on the models own predictions when calculating losses, 2) A novel adversarial learning pipeline with online pseudo-ground truth generations to achieve fine details. Our work provides a bridge from 2D supervisions of GAN models to 3D reconstruction models and removes the expensive annotation efforts. We show significant improvements over previous methods whether they were trained on GAN generated multi-view images or on real images with expensive annotations. Please visit our web-page for 3D visuals: https://research.nvidia.com/labs/adlr/progressive-3d-learning
Preserve Your Own Correlation: A Noise Prior for Video Diffusion Models
May 17, 2023Despite tremendous progress in generating high-quality images using diffusion models, synthesizing a sequence of animated frames that are both photorealistic and temporally coherent is still in its infancy. While off-the-shelf billion-scale datasets for image generation are available, collecting similar video data of the same scale is still challenging. Also, training a video diffusion model is computationally much more expensive than its image counterpart. In this work, we explore finetuning a pretrained image diffusion model with video data as a practical solution for the video synthesis task. We find that naively extending the image noise prior to video noise prior in video diffusion leads to sub-optimal performance. Our carefully designed video noise prior leads to substantially better performance. Extensive experimental validation shows that our model, Preserve Your Own Correlation (PYoCo), attains SOTA zero-shot text-to-video results on the UCF-101 and MSR-VTT benchmarks. It also achieves SOTA video generation quality on the small-scale UCF-101 benchmark with a $10\times$ smaller model using significantly less computation than the prior art.
Fine Detailed Texture Learning for 3D Meshes with Generative Models
Mar 17, 2022
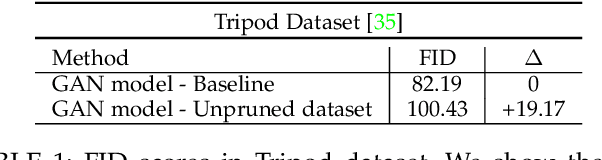
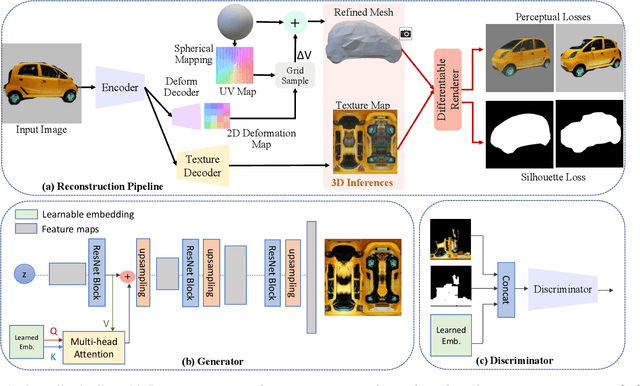

This paper presents a method to reconstruct high-quality textured 3D models from both multi-view and single-view images. The reconstruction is posed as an adaptation problem and is done progressively where in the first stage, we focus on learning accurate geometry, whereas in the second stage, we focus on learning the texture with a generative adversarial network. In the generative learning pipeline, we propose two improvements. First, since the learned textures should be spatially aligned, we propose an attention mechanism that relies on the learnable positions of pixels. Secondly, since discriminator receives aligned texture maps, we augment its input with a learnable embedding which improves the feedback to the generator. We achieve significant improvements on multi-view sequences from Tripod dataset as well as on single-view image datasets, Pascal 3D+ and CUB. We demonstrate that our method achieves superior 3D textured models compared to the previous works. Please visit our web-page for 3D visuals.
Leveraging Bitstream Metadata for Fast and Accurate Video Compression Correction
Jan 31, 2022Video compression is a central feature of the modern internet powering technologies from social media to video conferencing. While video compression continues to mature, for many, and particularly for extreme, compression settings, quality loss is still noticeable. These extreme settings nevertheless have important applications to the efficient transmission of videos over bandwidth constrained or otherwise unstable connections. In this work, we develop a deep learning architecture capable of restoring detail to compressed videos which leverages the underlying structure and motion information embedded in the video bitstream. We show that this improves restoration accuracy compared to prior compression correction methods and is competitive when compared with recent deep-learning-based video compression methods on rate-distortion while achieving higher throughput.
Adaptive Fourier Neural Operators: Efficient Token Mixers for Transformers
Nov 24, 2021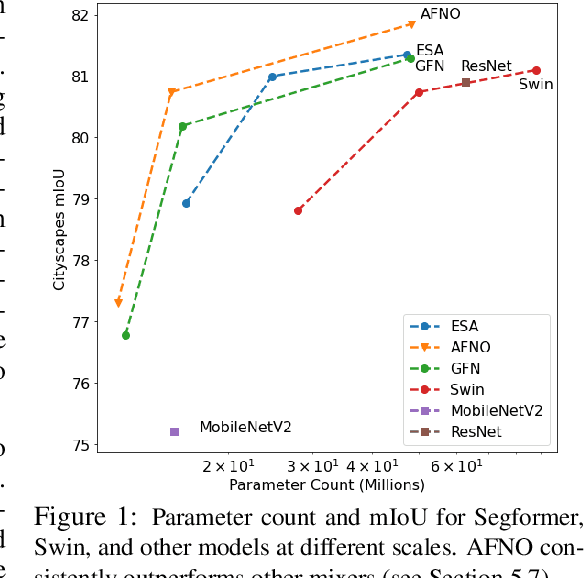

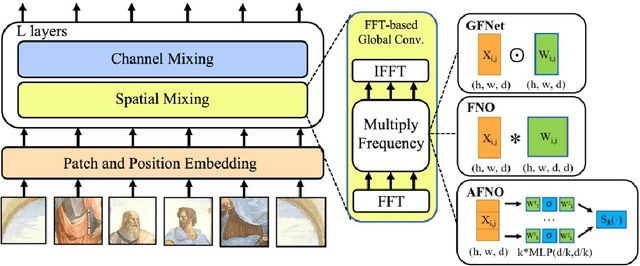

Vision transformers have delivered tremendous success in representation learning. This is primarily due to effective token mixing through self attention. However, this scales quadratically with the number of pixels, which becomes infeasible for high-resolution inputs. To cope with this challenge, we propose Adaptive Fourier Neural Operator (AFNO) as an efficient token mixer that learns to mix in the Fourier domain. AFNO is based on a principled foundation of operator learning which allows us to frame token mixing as a continuous global convolution without any dependence on the input resolution. This principle was previously used to design FNO, which solves global convolution efficiently in the Fourier domain and has shown promise in learning challenging PDEs. To handle challenges in visual representation learning such as discontinuities in images and high resolution inputs, we propose principled architectural modifications to FNO which results in memory and computational efficiency. This includes imposing a block-diagonal structure on the channel mixing weights, adaptively sharing weights across tokens, and sparsifying the frequency modes via soft-thresholding and shrinkage. The resulting model is highly parallel with a quasi-linear complexity and has linear memory in the sequence size. AFNO outperforms self-attention mechanisms for few-shot segmentation in terms of both efficiency and accuracy. For Cityscapes segmentation with the Segformer-B3 backbone, AFNO can handle a sequence size of 65k and outperforms other efficient self-attention mechanisms.
View Generalization for Single Image Textured 3D Models
Jun 10, 2021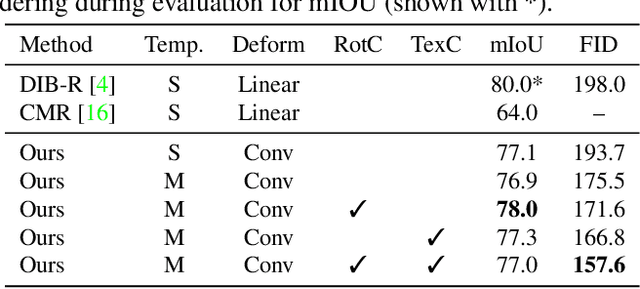

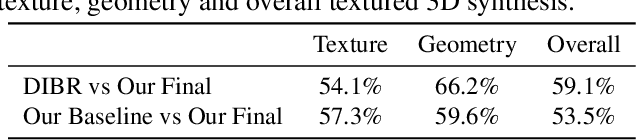
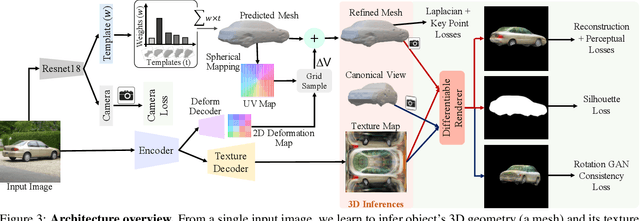
Humans can easily infer the underlying 3D geometry and texture of an object only from a single 2D image. Current computer vision methods can do this, too, but suffer from view generalization problems - the models inferred tend to make poor predictions of appearance in novel views. As for generalization problems in machine learning, the difficulty is balancing single-view accuracy (cf. training error; bias) with novel view accuracy (cf. test error; variance). We describe a class of models whose geometric rigidity is easily controlled to manage this tradeoff. We describe a cycle consistency loss that improves view generalization (roughly, a model from a generated view should predict the original view well). View generalization of textures requires that models share texture information, so a car seen from the back still has headlights because other cars have headlights. We describe a cycle consistency loss that encourages model textures to be aligned, so as to encourage sharing. We compare our method against the state-of-the-art method and show both qualitative and quantitative improvements.
Dual Contrastive Loss and Attention for GANs
Mar 31, 2021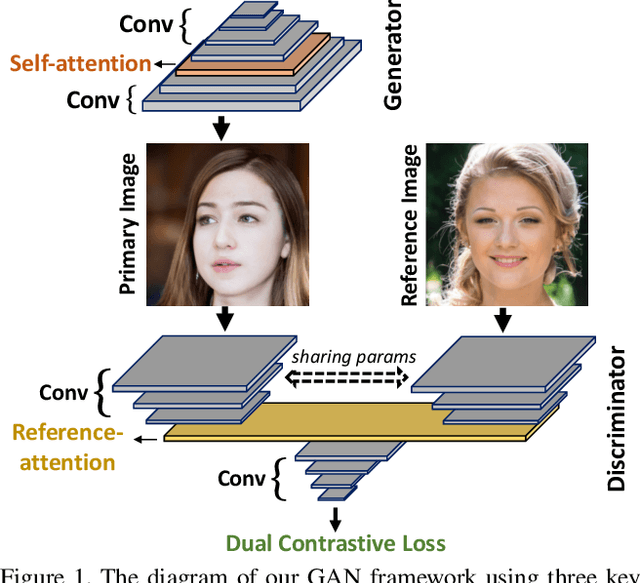
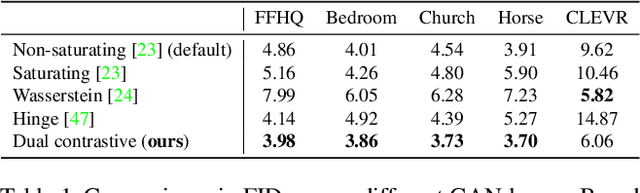
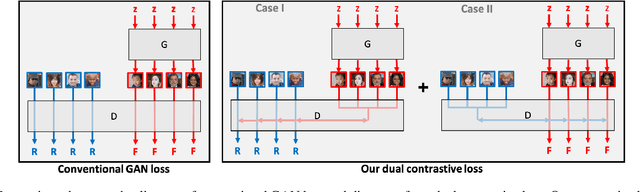

Generative Adversarial Networks (GANs) produce impressive results on unconditional image generation when powered with large-scale image datasets. Yet generated images are still easy to spot especially on datasets with high variance (e.g. bedroom, church). In this paper, we propose various improvements to further push the boundaries in image generation. Specifically, we propose a novel dual contrastive loss and show that, with this loss, discriminator learns more generalized and distinguishable representations to incentivize generation. In addition, we revisit attention and extensively experiment with different attention blocks in the generator. We find attention to be still an important module for successful image generation even though it was not used in the recent state-of-the-art models. Lastly, we study different attention architectures in the discriminator, and propose a reference attention mechanism. By combining the strengths of these remedies, we improve the compelling state-of-the-art Fr\'{e}chet Inception Distance (FID) by at least 17.5% on several benchmark datasets. We obtain even more significant improvements on compositional synthetic scenes (up to 47.5% in FID).
Transposer: Universal Texture Synthesis Using Feature Maps as Transposed Convolution Filter
Jul 14, 2020
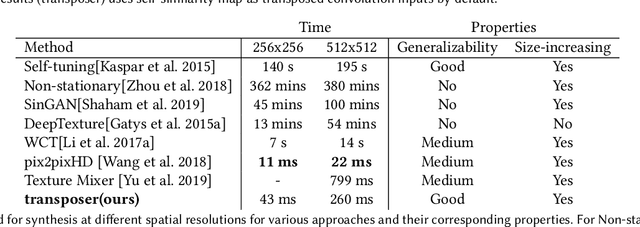

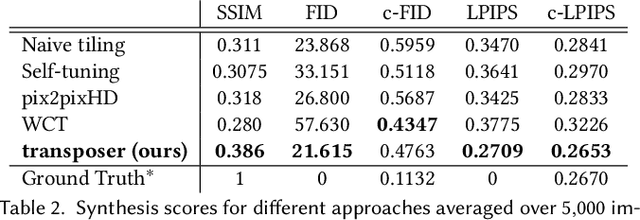
Conventional CNNs for texture synthesis consist of a sequence of (de)-convolution and up/down-sampling layers, where each layer operates locally and lacks the ability to capture the long-term structural dependency required by texture synthesis. Thus, they often simply enlarge the input texture, rather than perform reasonable synthesis. As a compromise, many recent methods sacrifice generalizability by training and testing on the same single (or fixed set of) texture image(s), resulting in huge re-training time costs for unseen images. In this work, based on the discovery that the assembling/stitching operation in traditional texture synthesis is analogous to a transposed convolution operation, we propose a novel way of using transposed convolution operation. Specifically, we directly treat the whole encoded feature map of the input texture as transposed convolution filters and the features' self-similarity map, which captures the auto-correlation information, as input to the transposed convolution. Such a design allows our framework, once trained, to be generalizable to perform synthesis of unseen textures with a single forward pass in nearly real-time. Our method achieves state-of-the-art texture synthesis quality based on various metrics. While self-similarity helps preserve the input textures' regular structural patterns, our framework can also take random noise maps for irregular input textures instead of self-similarity maps as transposed convolution inputs. It allows to get more diverse results as well as generate arbitrarily large texture outputs by directly sampling large noise maps in a single pass as well.
Hierarchical Multi-Scale Attention for Semantic Segmentation
May 21, 2020



Multi-scale inference is commonly used to improve the results of semantic segmentation. Multiple images scales are passed through a network and then the results are combined with averaging or max pooling. In this work, we present an attention-based approach to combining multi-scale predictions. We show that predictions at certain scales are better at resolving particular failures modes, and that the network learns to favor those scales for such cases in order to generate better predictions. Our attention mechanism is hierarchical, which enables it to be roughly 4x more memory efficient to train than other recent approaches. In addition to enabling faster training, this allows us to train with larger crop sizes which leads to greater model accuracy. We demonstrate the result of our method on two datasets: Cityscapes and Mapillary Vistas. For Cityscapes, which has a large number of weakly labelled images, we also leverage auto-labelling to improve generalization. Using our approach we achieve a new state-of-the-art results in both Mapillary (61.1 IOU val) and Cityscapes (85.1 IOU test).