 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDeepTIO: A Deep Thermal-Inertial Odometry with Visual Hallucination
Sep 16, 2019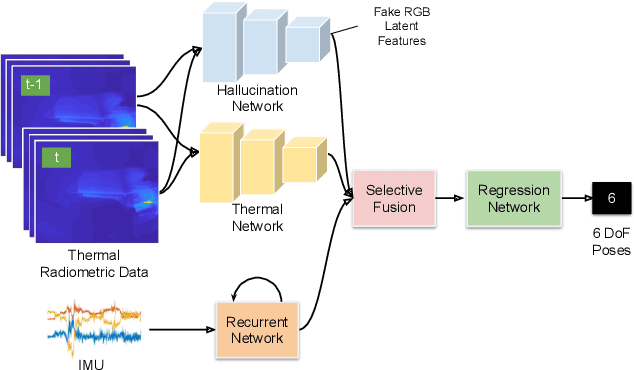
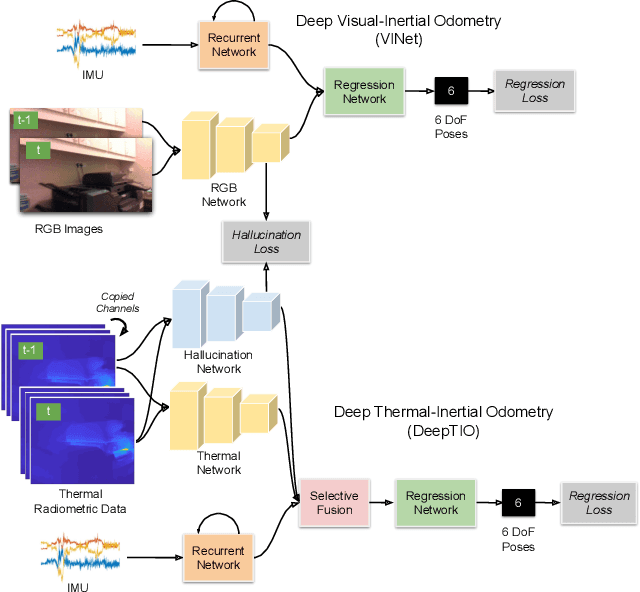
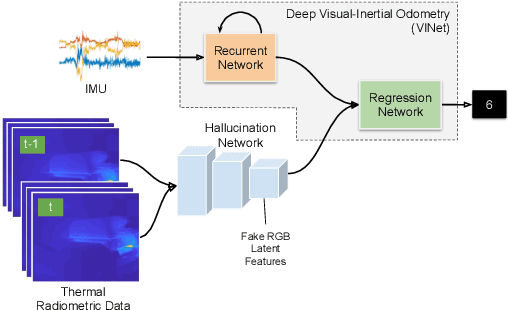
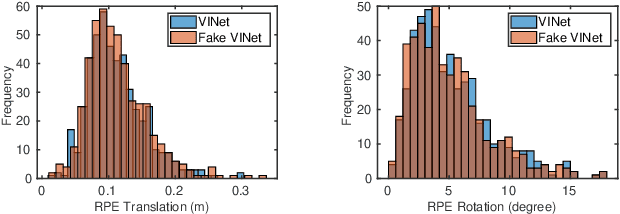
Visual odometry shows excellent performance in a wide range of environments. However, in visually-denied scenarios (e.g. heavy smoke or darkness), pose estimates degrade or even fail. Thermal imaging cameras are commonly used for perception and inspection when the environment has low visibility. However, their use in odometry estimation is hampered by the lack of robust visual features. In part, this is as a result of the sensor measuring the ambient temperature profile rather than scene appearance and geometry. To overcome these issues, we propose a Deep Neural Network model for thermal-inertial odometry (DeepTIO) by incorporating a visual hallucination network to provide the thermal network with complementary information. The hallucination network is taught to predict fake visual features from thermal images by using the robust Huber loss. We also employ selective fusion to attentively fuse the features from three different modalities, i.e thermal, hallucination, and inertial features. Extensive experiments are performed in our large scale hand-held data in benign and smoke-filled environments, showing the efficacy of the proposed model.
Milli-RIO: Ego-Motion Estimation with Millimetre-Wave Radar and Inertial Measurement Unit Sensor
Sep 12, 2019
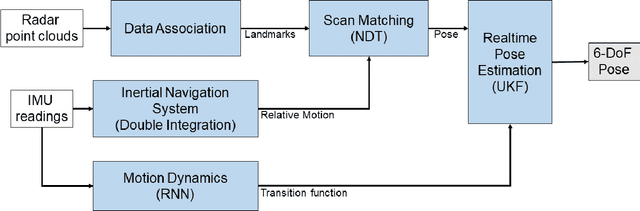
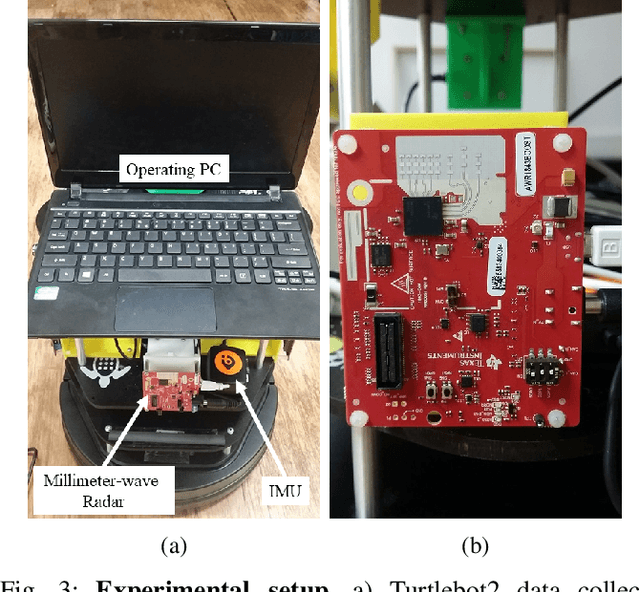
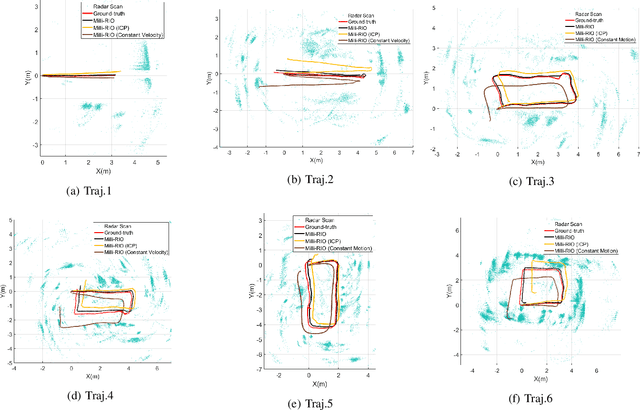
With the fast-growing demand of location-based services in various indoor environments, robust indoor ego-motion estimation has attracted significant interest in the last decades. Single-chip millimeter-wave (MMWave) radar as an emerging technology provides an alternative and complementary solution for robust ego-motion estimation. This paper introduces Milli-RIO, a MMWave radar based solution making use of a fixed beam antenna and inertial measurement unit sensor to calculate 6 degree-of-freedom pose of a moving radar. Detailed quantitative and qualitative evaluations prove that the proposed method achieves precisions on the order of few centimetres for indoor localization tasks.
AtLoc: Attention Guided Camera Localization
Sep 08, 2019
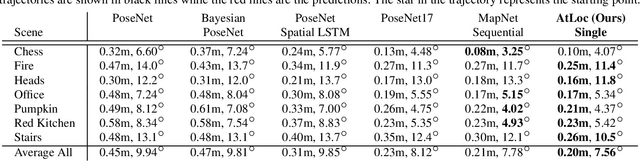
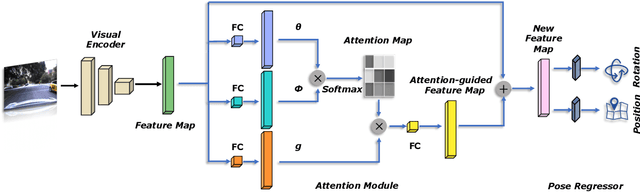
Deep learning has achieved impressive results in camera localization, but current single-image techniques typically suffer from a lack of robustness, leading to large outliers. To some extent, this has been tackled by sequential (multi-images) or geometry constraint approaches, which can learn to reject dynamic objects and illumination conditions to achieve better performance. In this work, we show that attention can be used to force the network to focus on more geometrically robust objects and features, achieving state-of-the-art performance in common benchmark, even if using only a single image as input. Extensive experimental evidence is provided through public indoor and outdoor datasets. Through visualization of the saliency maps, we demonstrate how the network learns to reject dynamic objects, yielding superior global camera pose regression performance. The source code is avaliable at https://github.com/BingCS/AtLoc.
Autonomous Learning for Face Recognition in the Wild via Ambient Wireless Cues
Aug 14, 2019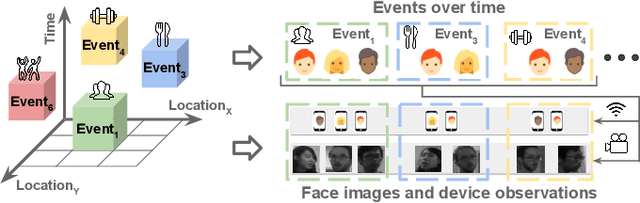

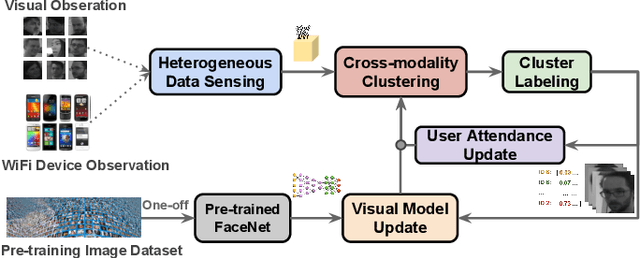
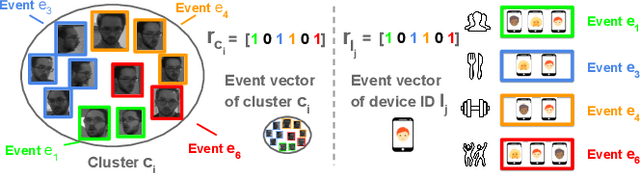
Facial recognition is a key enabling component for emerging Internet of Things (IoT) services such as smart homes or responsive offices. Through the use of deep neural networks, facial recognition has achieved excellent performance. However, this is only possibly when trained with hundreds of images of each user in different viewing and lighting conditions. Clearly, this level of effort in enrolment and labelling is impossible for wide-spread deployment and adoption. Inspired by the fact that most people carry smart wireless devices with them, e.g. smartphones, we propose to use this wireless identifier as a supervisory label. This allows us to curate a dataset of facial images that are unique to a certain domain e.g. a set of people in a particular office. This custom corpus can then be used to finetune existing pre-trained models e.g. FaceNet. However, due to the vagaries of wireless propagation in buildings, the supervisory labels are noisy and weak.We propose a novel technique, AutoTune, which learns and refines the association between a face and wireless identifier over time, by increasing the inter-cluster separation and minimizing the intra-cluster distance. Through extensive experiments with multiple users on two sites, we demonstrate the ability of AutoTune to design an environment-specific, continually evolving facial recognition system with entirely no user effort.
DynaNet: Neural Kalman Dynamical Model for Motion Estimation and Prediction
Aug 11, 2019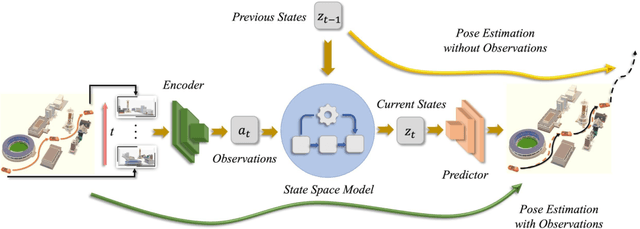
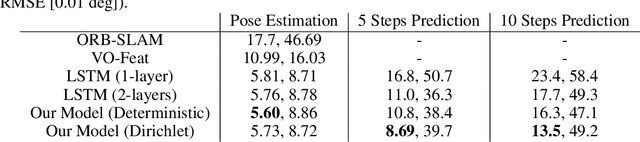
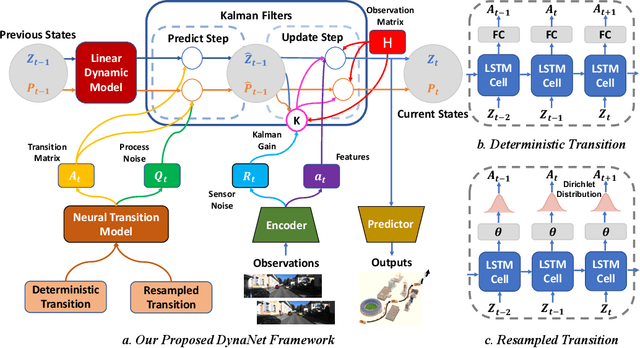

Dynamical models estimate and predict the temporal evolution of physical systems. State Space Models (SSMs) in particular represent the system dynamics with many desirable properties, such as being able to model uncertainty in both the model and measurements, and optimal (in the Bayesian sense) recursive formulations e.g. the Kalman Filter. However, they require significant domain knowledge to derive the parametric form and considerable hand-tuning to correctly set all the parameters. Data driven techniques e.g. Recurrent Neural Networks have emerged as compelling alternatives to SSMs with wide success across a number of challenging tasks, in part due to their ability to extract relevant features from rich inputs. They however lack interpretability and robustness to unseen conditions. In this work, we present DynaNet, a hybrid deep learning and time-varying state-space model which can be trained end-to-end. Our neural Kalman dynamical model allows us to exploit the relative merits of each approach. We demonstrate state-of-the-art estimation and prediction on a number of physically challenging tasks, including visual odometry, sensor fusion for visual-inertial navigation and pendulum control. In addition we show how DynaNet can indicate failures through investigation of properties such as the rate of innovation (Kalman Gain).
Distilling Knowledge From a Deep Pose Regressor Network
Aug 02, 2019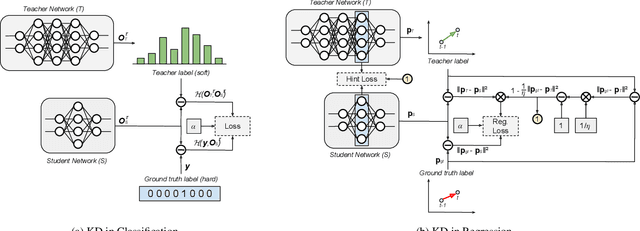
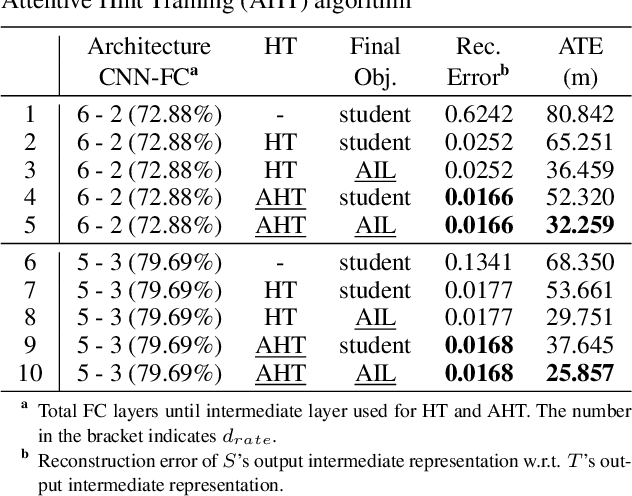
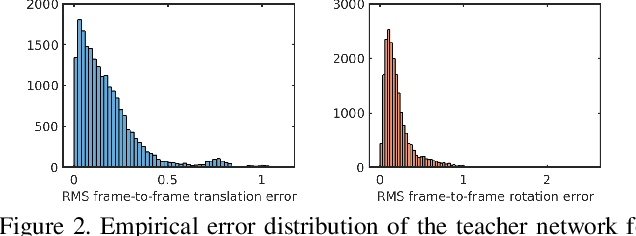
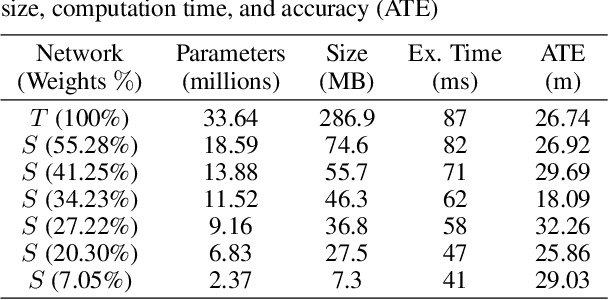
This paper presents a novel method to distill knowledge from a deep pose regressor network for efficient Visual Odometry (VO). Standard distillation relies on "dark knowledge" for successful knowledge transfer. As this knowledge is not available in pose regression and the teacher prediction is not always accurate, we propose to emphasize the knowledge transfer only when we trust the teacher. We achieve this by using teacher loss as a confidence score which places variable relative importance on the teacher prediction. We inject this confidence score to the main training task via Attentive Imitation Loss (AIL) and when learning the intermediate representation of the teacher through Attentive Hint Training (AHT) approach. To the best of our knowledge, this is the first work which successfully distill the knowledge from a deep pose regression network. Our evaluation on the KITTI and Malaga dataset shows that we can keep the student prediction close to the teacher with up to 92.95% parameter reduction and 2.12x faster in computation time.
Learning Object Bounding Boxes for 3D Instance Segmentation on Point Clouds
Jun 04, 2019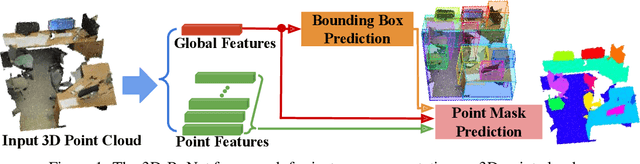
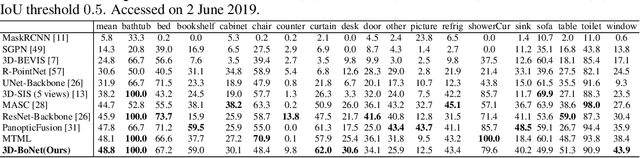
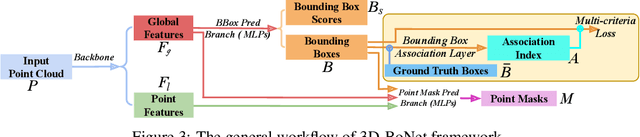
We propose a novel, conceptually simple and general framework for instance segmentation on 3D point clouds. Our method, called 3D-BoNet, follows the simple design philosophy of per-point multilayer perceptrons (MLPs). The framework directly regresses 3D bounding boxes for all instances in a point cloud, while simultaneously predicting a point-level mask for each instance. It consists of a backbone network followed by two parallel network branches for 1) bounding box regression and 2) point mask prediction. 3D-BoNet is single-stage, anchor-free and end-to-end trainable. Moreover, it is remarkably computationally efficient as, unlike existing approaches, it does not require any post-processing steps such as non-maximum suppression, feature sampling, clustering or voting. Extensive experiments show that our approach surpasses existing work on both ScanNet and S3DIS datasets while being approximately 10x more computationally efficient. Comprehensive ablation studies demonstrate the effectiveness of our design.
Learning Monocular Visual Odometry through Geometry-Aware Curriculum Learning
Mar 25, 2019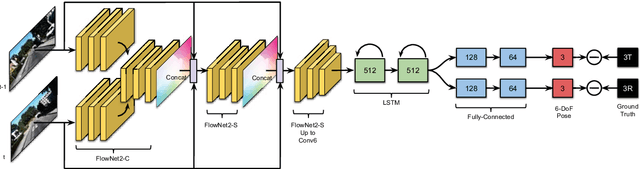
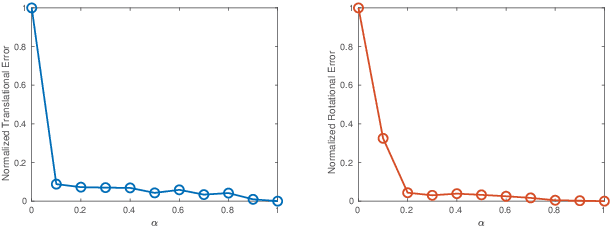
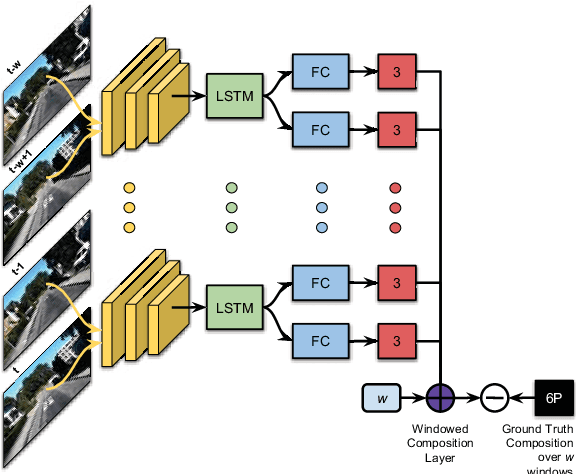
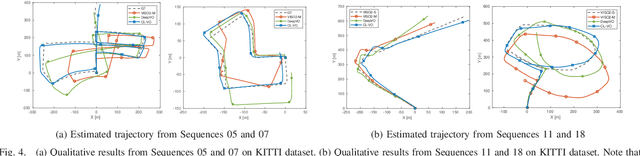
Inspired by the cognitive process of humans and animals, Curriculum Learning (CL) trains a model by gradually increasing the difficulty of the training data. In this paper, we study whether CL can be applied to complex geometry problems like estimating monocular Visual Odometry (VO). Unlike existing CL approaches, we present a novel CL strategy for learning the geometry of monocular VO by gradually making the learning objective more difficult during training. To this end, we propose a novel geometry-aware objective function by jointly optimizing relative and composite transformations over small windows via bounded pose regression loss. A cascade optical flow network followed by recurrent network with a differentiable windowed composition layer, termed CL-VO, is devised to learn the proposed objective. Evaluation on three real-world datasets shows superior performance of CL-VO over state-of-the-art feature-based and learning-based VO.
Selective Sensor Fusion for Neural Visual-Inertial Odometry
Mar 04, 2019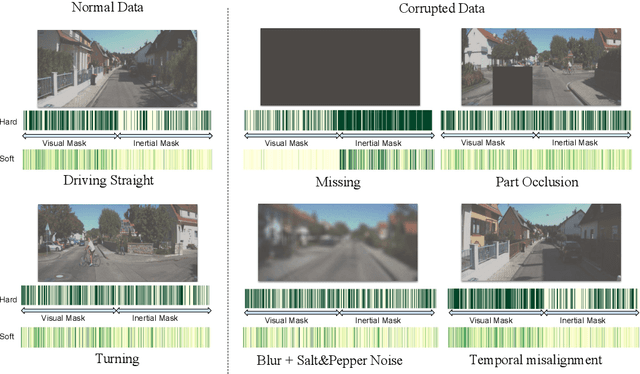
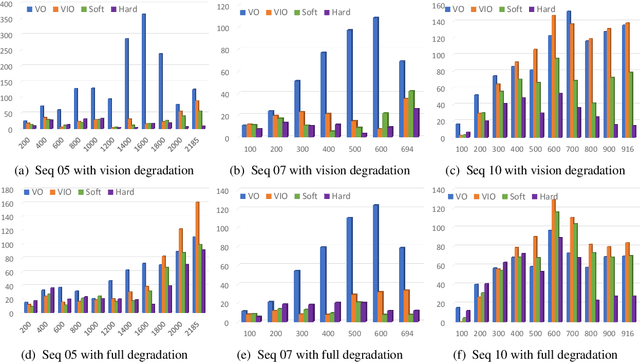
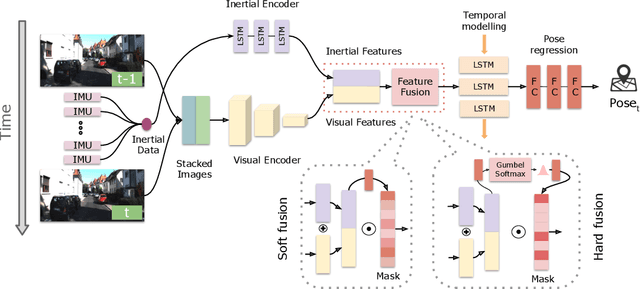
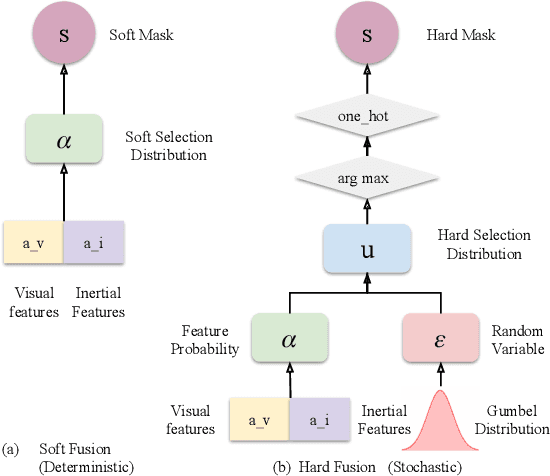
Deep learning approaches for Visual-Inertial Odometry (VIO) have proven successful, but they rarely focus on incorporating robust fusion strategies for dealing with imperfect input sensory data. We propose a novel end-to-end selective sensor fusion framework for monocular VIO, which fuses monocular images and inertial measurements in order to estimate the trajectory whilst improving robustness to real-life issues, such as missing and corrupted data or bad sensor synchronization. In particular, we propose two fusion modalities based on different masking strategies: deterministic soft fusion and stochastic hard fusion, and we compare with previously proposed direct fusion baselines. During testing, the network is able to selectively process the features of the available sensor modalities and produce a trajectory at scale. We present a thorough investigation on the performances on three public autonomous driving, Micro Aerial Vehicle (MAV) and hand-held VIO datasets. The results demonstrate the effectiveness of the fusion strategies, which offer better performances compared to direct fusion, particularly in presence of corrupted data. In addition, we study the interpretability of the fusion networks by visualising the masking layers in different scenarios and with varying data corruption, revealing interesting correlations between the fusion networks and imperfect sensory input data.
Learning with Training Wheels: Speeding up Training with a Simple Controller for Deep Reinforcement Learning
Dec 12, 2018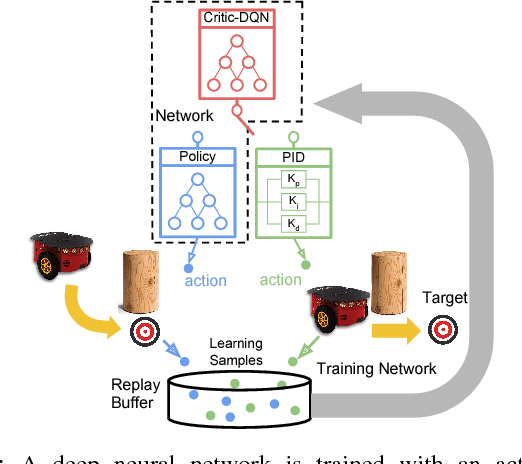
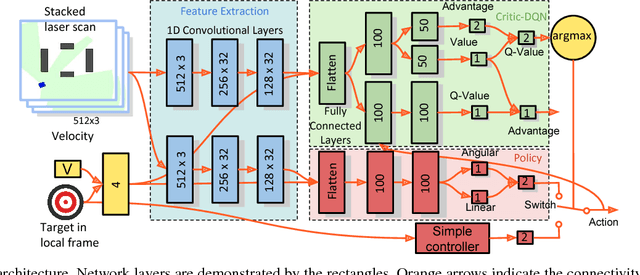
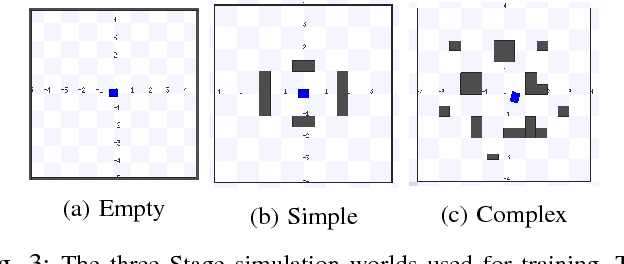
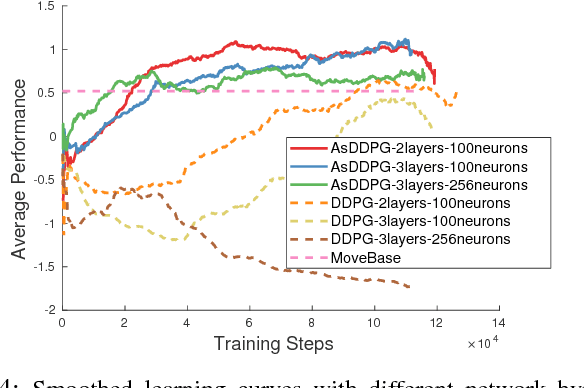
Deep Reinforcement Learning (DRL) has been applied successfully to many robotic applications. However, the large number of trials needed for training is a key issue. Most of existing techniques developed to improve training efficiency (e.g. imitation) target on general tasks rather than being tailored for robot applications, which have their specific context to benefit from. We propose a novel framework, Assisted Reinforcement Learning, where a classical controller (e.g. a PID controller) is used as an alternative, switchable policy to speed up training of DRL for local planning and navigation problems. The core idea is that the simple control law allows the robot to rapidly learn sensible primitives, like driving in a straight line, instead of random exploration. As the actor network becomes more advanced, it can then take over to perform more complex actions, like obstacle avoidance. Eventually, the simple controller can be discarded entirely. We show that not only does this technique train faster, it also is less sensitive to the structure of the DRL network and consistently outperforms a standard Deep Deterministic Policy Gradient network. We demonstrate the results in both simulation and real-world experiments.