 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSSL-Net: A Synergistic Spectral and Learning-based Network for Efficient Bird Sound Classification
Sep 15, 2023Efficient and accurate bird sound classification is of important for ecology, habitat protection and scientific research, as it plays a central role in monitoring the distribution and abundance of species. However, prevailing methods typically demand extensively labeled audio datasets and have highly customized frameworks, imposing substantial computational and annotation loads. In this study, we present an efficient and general framework called SSL-Net, which combines spectral and learned features to identify different bird sounds. Encouraging empirical results gleaned from a standard field-collected bird audio dataset validate the efficacy of our method in extracting features efficiently and achieving heightened performance in bird sound classification, even when working with limited sample sizes. Furthermore, we present three feature fusion strategies, aiding engineers and researchers in their selection through quantitative analysis.
Deep Learning for Visual Localization and Mapping: A Survey
Aug 27, 2023



Deep learning based localization and mapping approaches have recently emerged as a new research direction and receive significant attentions from both industry and academia. Instead of creating hand-designed algorithms based on physical models or geometric theories, deep learning solutions provide an alternative to solve the problem in a data-driven way. Benefiting from the ever-increasing volumes of data and computational power on devices, these learning methods are fast evolving into a new area that shows potentials to track self-motion and estimate environmental model accurately and robustly for mobile agents. In this work, we provide a comprehensive survey, and propose a taxonomy for the localization and mapping methods using deep learning. This survey aims to discuss two basic questions: whether deep learning is promising to localization and mapping; how deep learning should be applied to solve this problem. To this end, a series of localization and mapping topics are investigated, from the learning based visual odometry, global relocalization, to mapping, and simultaneous localization and mapping (SLAM). It is our hope that this survey organically weaves together the recent works in this vein from robotics, computer vision and machine learning communities, and serves as a guideline for future researchers to apply deep learning to tackle the problem of visual localization and mapping.
Fast model inference and training on-board of Satellites
Jul 17, 2023



Artificial intelligence onboard satellites has the potential to reduce data transmission requirements, enable real-time decision-making and collaboration within constellations. This study deploys a lightweight foundational model called RaVAEn on D-Orbit's ION SCV004 satellite. RaVAEn is a variational auto-encoder (VAE) that generates compressed latent vectors from small image tiles, enabling several downstream tasks. In this work we demonstrate the reliable use of RaVAEn onboard a satellite, achieving an encoding time of 0.110s for tiles of a 4.8x4.8 km$^2$ area. In addition, we showcase fast few-shot training onboard a satellite using the latent representation of data. We compare the deployment of the model on the on-board CPU and on the available Myriad vision processing unit (VPU) accelerator. To our knowledge, this work shows for the first time the deployment of a multi-task model on-board a CubeSat and the on-board training of a machine learning model.
Multi-body SE(3) Equivariance for Unsupervised Rigid Segmentation and Motion Estimation
Jun 08, 2023A truly generalizable approach to rigid segmentation and motion estimation is fundamental to 3D understanding of articulated objects and moving scenes. In view of the tightly coupled relationship between segmentation and motion estimates, we present an SE(3) equivariant architecture and a training strategy to tackle this task in an unsupervised manner. Our architecture comprises two lightweight and inter-connected heads that predict segmentation masks using point-level invariant features and motion estimates from SE(3) equivariant features without the prerequisites of category information. Our unified training strategy can be performed online while jointly optimizing the two predictions by exploiting the interrelations among scene flow, segmentation mask, and rigid transformations. We show experiments on four datasets as evidence of the superiority of our method both in terms of model performance and computational efficiency with only 0.25M parameters and 0.92G FLOPs. To the best of our knowledge, this is the first work designed for category-agnostic part-level SE(3) equivariance in dynamic point clouds.
Decoupling Skill Learning from Robotic Control for Generalizable Object Manipulation
Mar 09, 2023Recent works in robotic manipulation through reinforcement learning (RL) or imitation learning (IL) have shown potential for tackling a range of tasks e.g., opening a drawer or a cupboard. However, these techniques generalize poorly to unseen objects. We conjecture that this is due to the high-dimensional action space for joint control. In this paper, we take an alternative approach and separate the task of learning 'what to do' from 'how to do it' i.e., whole-body control. We pose the RL problem as one of determining the skill dynamics for a disembodied virtual manipulator interacting with articulated objects. The whole-body robotic kinematic control is optimized to execute the high-dimensional joint motion to reach the goals in the workspace. It does so by solving a quadratic programming (QP) model with robotic singularity and kinematic constraints. Our experiments on manipulating complex articulated objects show that the proposed approach is more generalizable to unseen objects with large intra-class variations, outperforming previous approaches. The evaluation results indicate that our approach generates more compliant robotic motion and outperforms the pure RL and IL baselines in task success rates. Additional information and videos are available at https://kl-research.github.io/decoupskill
Tracking People in Highly Dynamic Industrial Environments
Feb 01, 2023



To date, the majority of positioning systems have been designed to operate within environments that have long-term stable macro-structure with potential small-scale dynamics. These assumptions allow the existing positioning systems to produce and utilize stable maps. However, in highly dynamic industrial settings these assumptions are no longer valid and the task of tracking people is more challenging due to the rapid large-scale changes in structure. In this paper we propose a novel positioning system for tracking people in highly dynamic industrial environments, such as construction sites. The proposed system leverages the existing CCTV camera infrastructure found in many industrial settings along with radio and inertial sensors within each worker's mobile phone to accurately track multiple people. This multi-target multi-sensor tracking framework also allows our system to use cross-modality training in order to deal with the environment dynamics. In particular, we show how our system uses cross-modality training in order to automatically keep track environmental changes (i.e. new walls) by utilizing occlusion maps. In addition, we show how these maps can be used in conjunction with social forces to accurately predict human motion and increase the tracking accuracy. We have conducted extensive real-world experiments in a construction site showing significant accuracy improvement via cross-modality training and the use of social forces.
Fusion of Radio and Camera Sensor Data for Accurate Indoor Positioning
Feb 01, 2023



Indoor positioning systems have received a lot of attention recently due to their importance for many location-based services, e.g. indoor navigation and smart buildings. Lightweight solutions based on WiFi and inertial sensing have gained popularity, but are not fit for demanding applications, such as expert museum guides and industrial settings, which typically require sub-meter location information. In this paper, we propose a novel positioning system, RAVEL (Radio And Vision Enhanced Localization), which fuses anonymous visual detections captured by widely available camera infrastructure, with radio readings (e.g. WiFi radio data). Although visual trackers can provide excellent positioning accuracy, they are plagued by issues such as occlusions and people entering/exiting the scene, preventing their use as a robust tracking solution. By incorporating radio measurements, visually ambiguous or missing data can be resolved through multi-hypothesis tracking. We evaluate our system in a complex museum environment with dim lighting and multiple people moving around in a space cluttered with exhibit stands. Our experiments show that although the WiFi measurements are not by themselves sufficiently accurate, when they are fused with camera data, they become a catalyst for pulling together ambiguous, fragmented, and anonymous visual tracklets into accurate and continuous paths, yielding typical errors below 1 meter.
Sample, Crop, Track: Self-Supervised Mobile 3D Object Detection for Urban Driving LiDAR
Sep 21, 2022
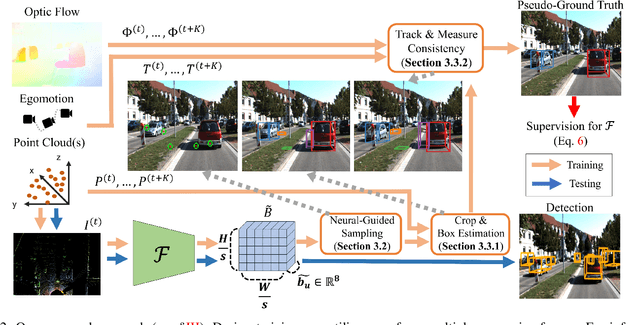
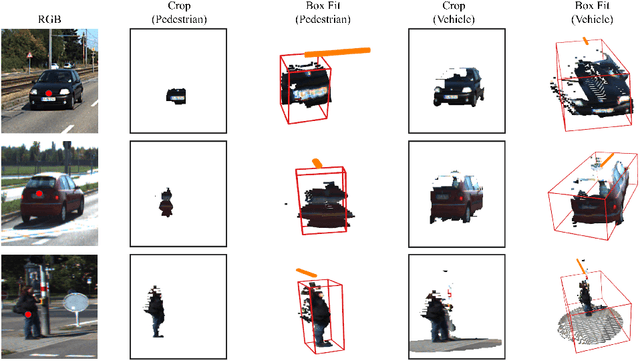
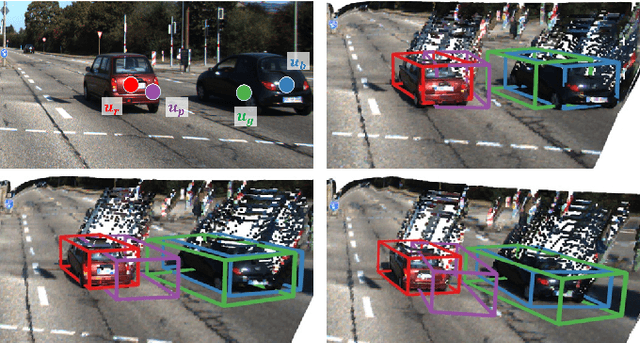
Deep learning has led to great progress in the detection of mobile (i.e. movement-capable) objects in urban driving scenes in recent years. Supervised approaches typically require the annotation of large training sets; there has thus been great interest in leveraging weakly, semi- or self-supervised methods to avoid this, with much success. Whilst weakly and semi-supervised methods require some annotation, self-supervised methods have used cues such as motion to relieve the need for annotation altogether. However, a complete absence of annotation typically degrades their performance, and ambiguities that arise during motion grouping can inhibit their ability to find accurate object boundaries. In this paper, we propose a new self-supervised mobile object detection approach called SCT. This uses both motion cues and expected object sizes to improve detection performance, and predicts a dense grid of 3D oriented bounding boxes to improve object discovery. We significantly outperform the state-of-the-art self-supervised mobile object detection method TCR on the KITTI tracking benchmark, and achieve performance that is within 30% of the fully supervised PV-RCNN++ method for IoUs <= 0.5.
When the Sun Goes Down: Repairing Photometric Losses for All-Day Depth Estimation
Jun 28, 2022
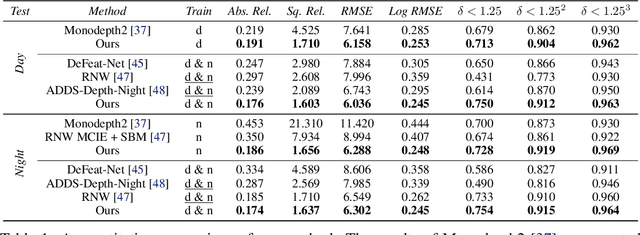
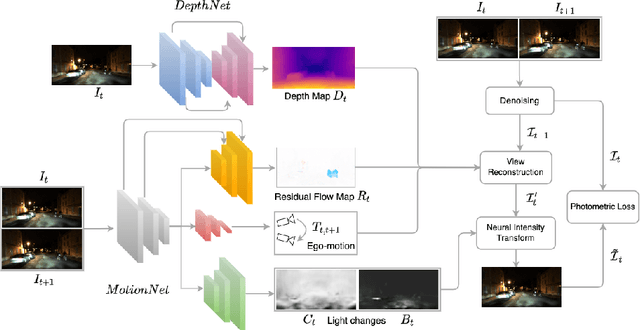
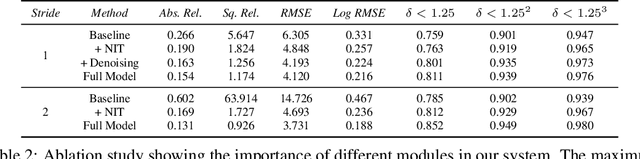
Self-supervised deep learning methods for joint depth and ego-motion estimation can yield accurate trajectories without needing ground-truth training data. However, as they typically use photometric losses, their performance can degrade significantly when the assumptions these losses make (e.g. temporal illumination consistency, a static scene, and the absence of noise and occlusions) are violated. This limits their use for e.g. nighttime sequences, which tend to contain many point light sources (including on dynamic objects) and low signal-to-noise ratio (SNR) in darker image regions. In this paper, we show how to use a combination of three techniques to allow the existing photometric losses to work for both day and nighttime images. First, we introduce a per-pixel neural intensity transformation to compensate for the light changes that occur between successive frames. Second, we predict a per-pixel residual flow map that we use to correct the reprojection correspondences induced by the estimated ego-motion and depth from the networks. And third, we denoise the training images to improve the robustness and accuracy of our approach. These changes allow us to train a single model for both day and nighttime images without needing separate encoders or extra feature networks like existing methods. We perform extensive experiments and ablation studies on the challenging Oxford RobotCar dataset to demonstrate the efficacy of our approach for both day and nighttime sequences.
RangeUDF: Semantic Surface Reconstruction from 3D Point Clouds
Apr 19, 2022

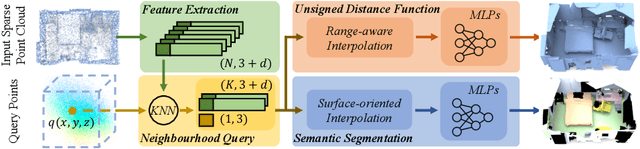
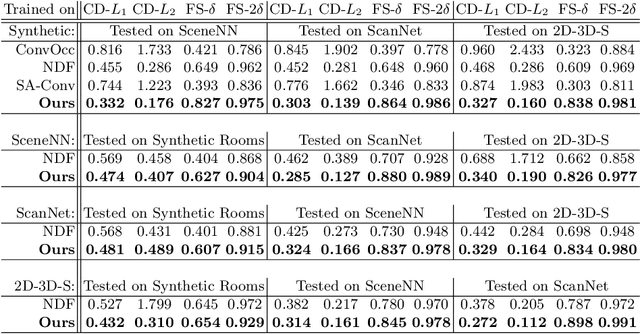
We present RangeUDF, a new implicit representation based framework to recover the geometry and semantics of continuous 3D scene surfaces from point clouds. Unlike occupancy fields or signed distance fields which can only model closed 3D surfaces, our approach is not restricted to any type of topology. Being different from the existing unsigned distance fields, our framework does not suffer from any surface ambiguity. In addition, our RangeUDF can jointly estimate precise semantics for continuous surfaces. The key to our approach is a range-aware unsigned distance function together with a surface-oriented semantic segmentation module. Extensive experiments show that RangeUDF clearly surpasses state-of-the-art approaches for surface reconstruction on four point cloud datasets. Moreover, RangeUDF demonstrates superior generalization capability across multiple unseen datasets, which is nearly impossible for all existing approaches.