 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCo-training Transformer with Videos and Images Improves Action Recognition
Dec 14, 2021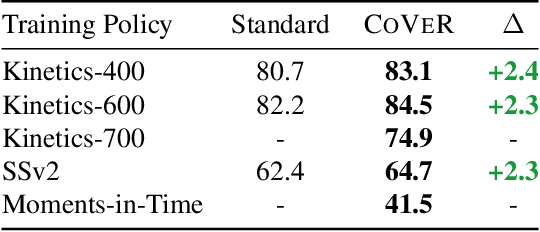
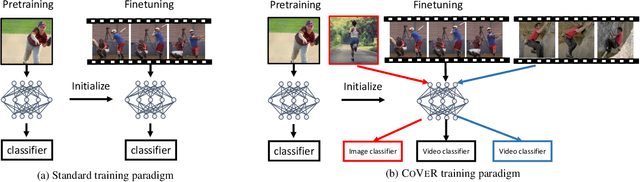

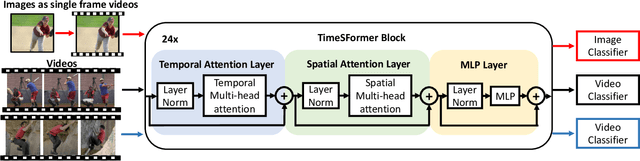
In learning action recognition, models are typically pre-trained on object recognition with images, such as ImageNet, and later fine-tuned on target action recognition with videos. This approach has achieved good empirical performance especially with recent transformer-based video architectures. While recently many works aim to design more advanced transformer architectures for action recognition, less effort has been made on how to train video transformers. In this work, we explore several training paradigms and present two findings. First, video transformers benefit from joint training on diverse video datasets and label spaces (e.g., Kinetics is appearance-focused while SomethingSomething is motion-focused). Second, by further co-training with images (as single-frame videos), the video transformers learn even better video representations. We term this approach as Co-training Videos and Images for Action Recognition (CoVeR). In particular, when pretrained on ImageNet-21K based on the TimeSFormer architecture, CoVeR improves Kinetics-400 Top-1 Accuracy by 2.4%, Kinetics-600 by 2.3%, and SomethingSomething-v2 by 2.3%. When pretrained on larger-scale image datasets following previous state-of-the-art, CoVeR achieves best results on Kinetics-400 (87.2%), Kinetics-600 (87.9%), Kinetics-700 (79.8%), SomethingSomething-v2 (70.9%), and Moments-in-Time (46.1%), with a simple spatio-temporal video transformer.
GLaM: Efficient Scaling of Language Models with Mixture-of-Experts
Dec 13, 2021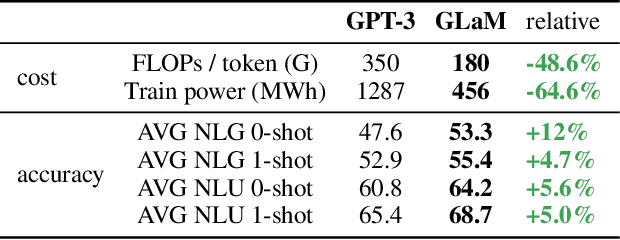
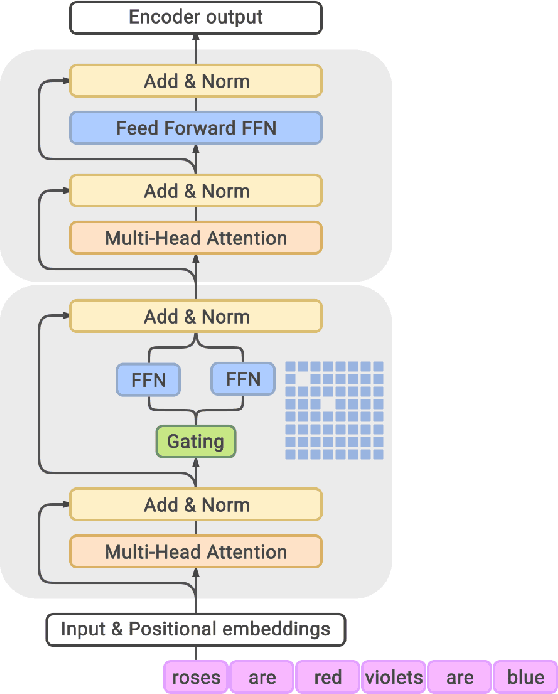
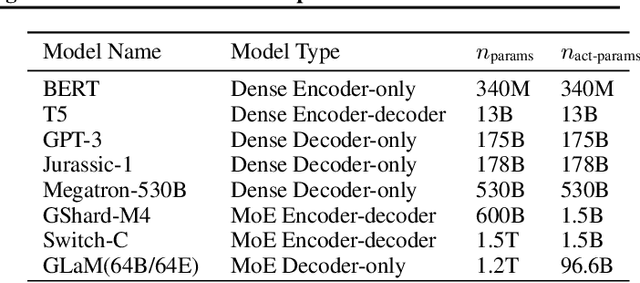
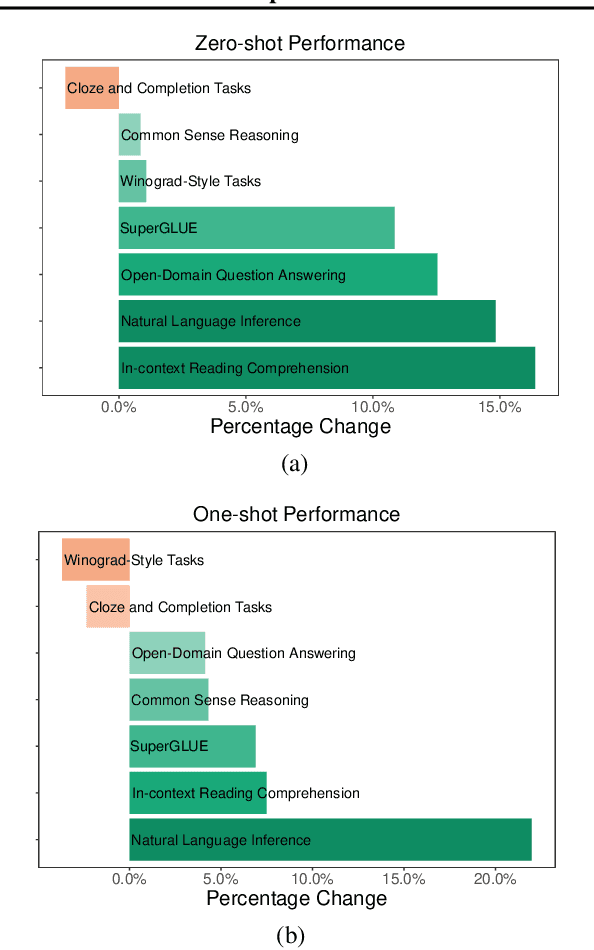
Scaling language models with more data, compute and parameters has driven significant progress in natural language processing. For example, thanks to scaling, GPT-3 was able to achieve strong results on in-context learning tasks. However, training these large dense models requires significant amounts of computing resources. In this paper, we propose and develop a family of language models named GLaM (Generalist Language Model), which uses a sparsely activated mixture-of-experts architecture to scale the model capacity while also incurring substantially less training cost compared to dense variants. The largest GLaM has 1.2 trillion parameters, which is approximately 7x larger than GPT-3. It consumes only 1/3 of the energy used to train GPT-3 and requires half of the computation flops for inference, while still achieving better overall zero-shot and one-shot performance across 29 NLP tasks.
Finetuned Language Models Are Zero-Shot Learners
Sep 03, 2021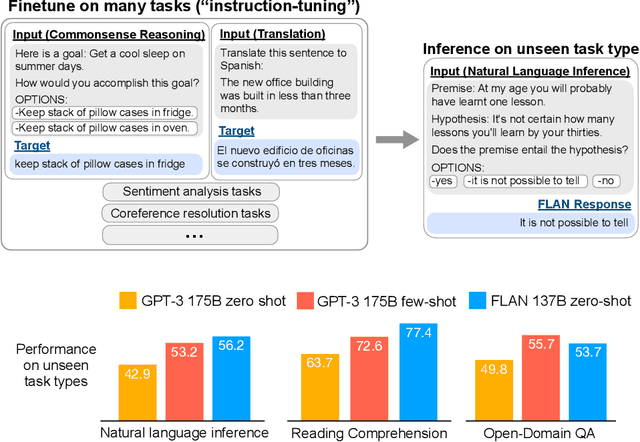
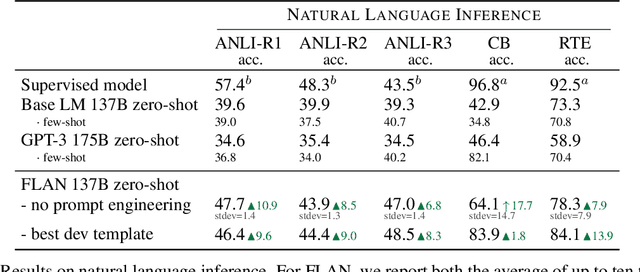
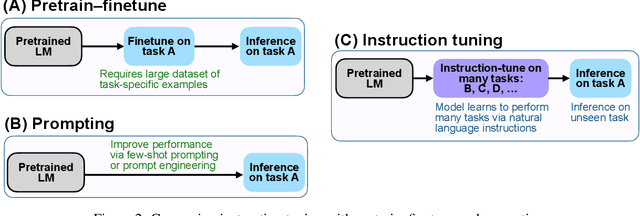
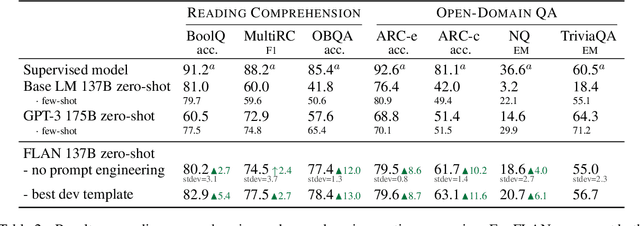
This paper explores a simple method for improving the zero-shot learning abilities of language models. We show that instruction tuning -- finetuning language models on a collection of tasks described via instructions -- substantially boosts zero-shot performance on unseen tasks. We take a 137B parameter pretrained language model and instruction-tune it on over 60 NLP tasks verbalized via natural language instruction templates. We evaluate this instruction-tuned model, which we call FLAN, on unseen task types. FLAN substantially improves the performance of its unmodified counterpart and surpasses zero-shot 175B GPT-3 on 19 of 25 tasks that we evaluate. FLAN even outperforms few-shot GPT-3 by a large margin on ANLI, RTE, BoolQ, AI2-ARC, OpenbookQA, and StoryCloze. Ablation studies reveal that number of tasks and model scale are key components to the success of instruction tuning.
BEDS-Bench: Behavior of EHR-models under Distributional Shift--A Benchmark
Jul 17, 2021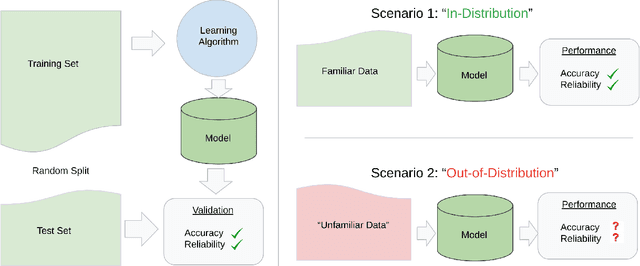
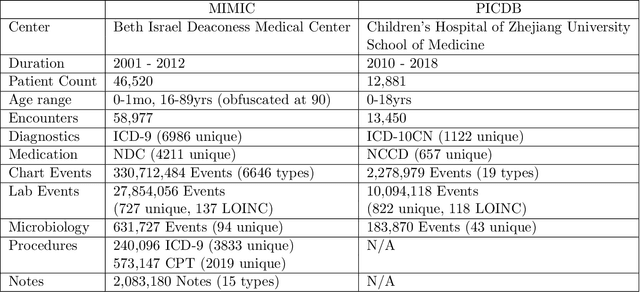
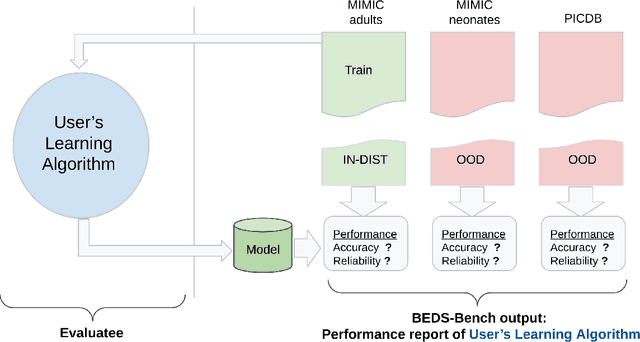
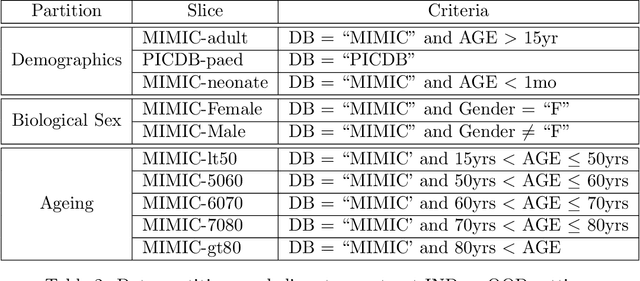
Machine learning has recently demonstrated impressive progress in predictive accuracy across a wide array of tasks. Most ML approaches focus on generalization performance on unseen data that are similar to the training data (In-Distribution, or IND). However, real world applications and deployments of ML rarely enjoy the comfort of encountering examples that are always IND. In such situations, most ML models commonly display erratic behavior on Out-of-Distribution (OOD) examples, such as assigning high confidence to wrong predictions, or vice-versa. Implications of such unusual model behavior are further exacerbated in the healthcare setting, where patient health can potentially be put at risk. It is crucial to study the behavior and robustness properties of models under distributional shift, understand common failure modes, and take mitigation steps before the model is deployed. Having a benchmark that shines light upon these aspects of a model is a first and necessary step in addressing the issue. Recent work and interest in increasing model robustness in OOD settings have focused more on image modality, while the Electronic Health Record (EHR) modality is still largely under-explored. We aim to bridge this gap by releasing BEDS-Bench, a benchmark for quantifying the behavior of ML models over EHR data under OOD settings. We use two open access, de-identified EHR datasets to construct several OOD data settings to run tests on, and measure relevant metrics that characterize crucial aspects of a model's OOD behavior. We evaluate several learning algorithms under BEDS-Bench and find that all of them show poor generalization performance under distributional shift in general. Our results highlight the need and the potential to improve robustness of EHR models under distributional shift, and BEDS-Bench provides one way to measure progress towards that goal.
MUFASA: Multimodal Fusion Architecture Search for Electronic Health Records
Feb 03, 2021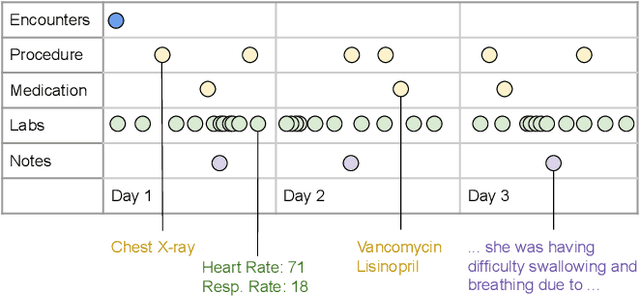
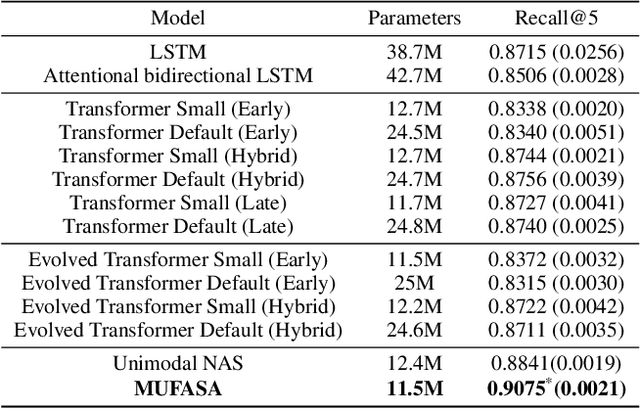
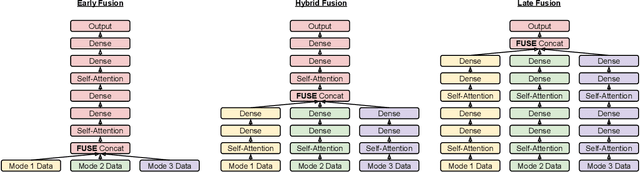

One important challenge of applying deep learning to electronic health records (EHR) is the complexity of their multimodal structure. EHR usually contains a mixture of structured (codes) and unstructured (free-text) data with sparse and irregular longitudinal features -- all of which doctors utilize when making decisions. In the deep learning regime, determining how different modality representations should be fused together is a difficult problem, which is often addressed by handcrafted modeling and intuition. In this work, we extend state-of-the-art neural architecture search (NAS) methods and propose MUltimodal Fusion Architecture SeArch (MUFASA) to simultaneously search across multimodal fusion strategies and modality-specific architectures for the first time. We demonstrate empirically that our MUFASA method outperforms established unimodal NAS on public EHR data with comparable computation costs. In addition, MUFASA produces architectures that outperform Transformer and Evolved Transformer. Compared with these baselines on CCS diagnosis code prediction, our discovered models improve top-5 recall from 0.88 to 0.91 and demonstrate the ability to generalize to other EHR tasks. Studying our top architecture in depth, we provide empirical evidence that MUFASA's improvements are derived from its ability to both customize modeling for each data modality and find effective fusion strategies.
Learnability and Complexity of Quantum Samples
Oct 22, 2020
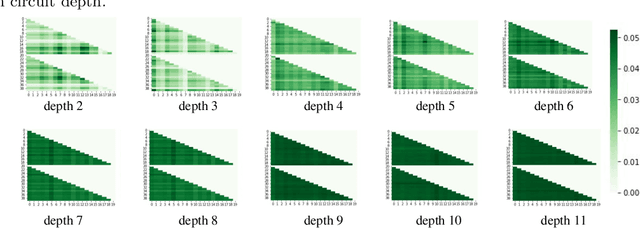
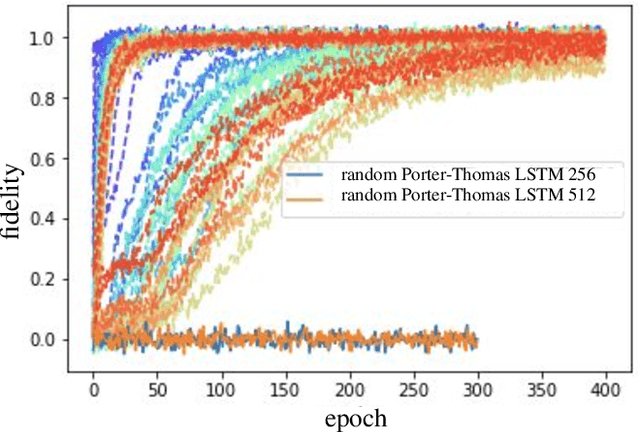
Given a quantum circuit, a quantum computer can sample the output distribution exponentially faster in the number of bits than classical computers. A similar exponential separation has yet to be established in generative models through quantum sample learning: given samples from an n-qubit computation, can we learn the underlying quantum distribution using models with training parameters that scale polynomial in n under a fixed training time? We study four kinds of generative models: Deep Boltzmann machine (DBM), Generative Adversarial Networks (GANs), Long Short-Term Memory (LSTM) and Autoregressive GAN, on learning quantum data set generated by deep random circuits. We demonstrate the leading performance of LSTM in learning quantum samples, and thus the autoregressive structure present in the underlying quantum distribution from random quantum circuits. Both numerical experiments and a theoretical proof in the case of the DBM show exponentially growing complexity of learning-agent parameters required for achieving a fixed accuracy as n increases. Finally, we establish a connection between learnability and the complexity of generative models by benchmarking learnability against different sets of samples drawn from probability distributions of variable degrees of complexities in their quantum and classical representations.
Training independent subnetworks for robust prediction
Oct 13, 2020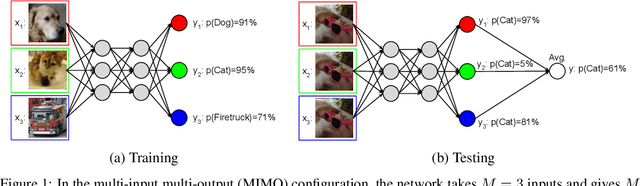
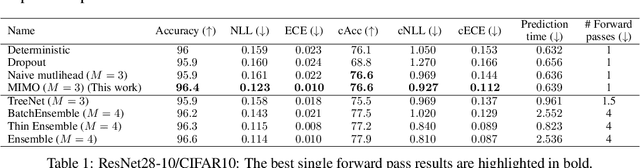

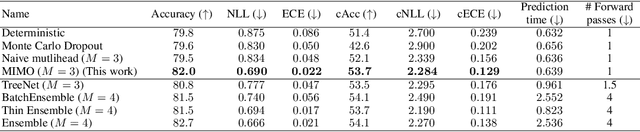
Recent approaches to efficiently ensemble neural networks have shown that strong robustness and uncertainty performance can be achieved with a negligible gain in parameters over the original network. However, these methods still require multiple forward passes for prediction, leading to a significant computational cost. In this work, we show a surprising result: the benefits of using multiple predictions can be achieved `for free' under a single model's forward pass. In particular, we show that, using a multi-input multi-output (MIMO) configuration, one can utilize a single model's capacity to train multiple subnetworks that independently learn the task at hand. By ensembling the predictions made by the subnetworks, we improve model robustness without increasing compute. We observe a significant improvement in negative log-likelihood, accuracy, and calibration error on CIFAR10, CIFAR100, ImageNet, and their out-of-distribution variants compared to previous methods.
Learning Unstable Dynamical Systems with Time-Weighted Logarithmic Loss
Jul 10, 2020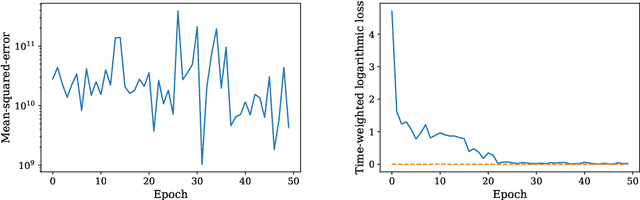
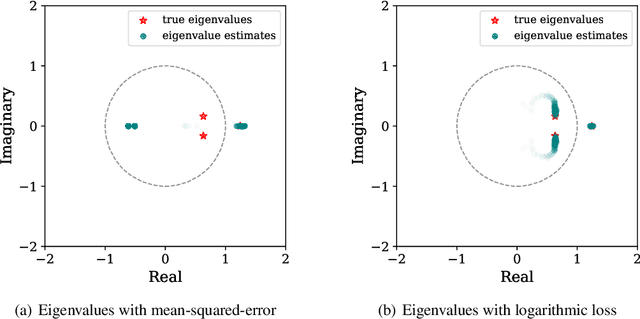
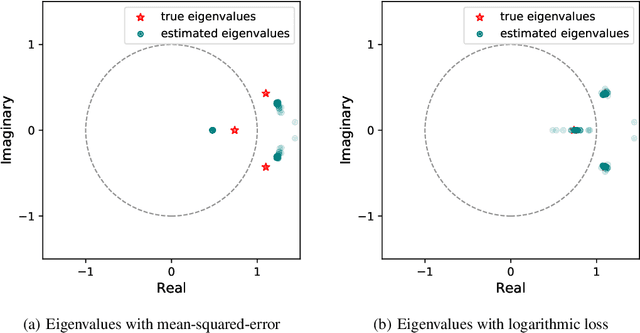
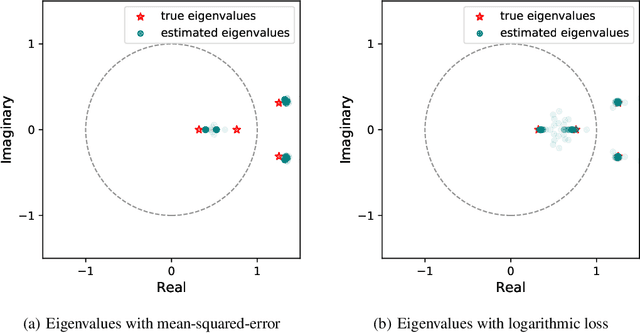
When training the parameters of a linear dynamical model, the gradient descent algorithm is likely to fail to converge if the squared-error loss is used as the training loss function. Restricting the parameter space to a smaller subset and running the gradient descent algorithm within this subset can allow learning stable dynamical systems, but this strategy does not work for unstable systems. In this work, we look into the dynamics of the gradient descent algorithm and pinpoint what causes the difficulty of learning unstable systems. We show that observations taken at different times from the system to be learned influence the dynamics of the gradient descent algorithm in substantially different degrees. We introduce a time-weighted logarithmic loss function to fix this imbalance and demonstrate its effectiveness in learning unstable systems.
Flow Contrastive Estimation of Energy-Based Models
Dec 02, 2019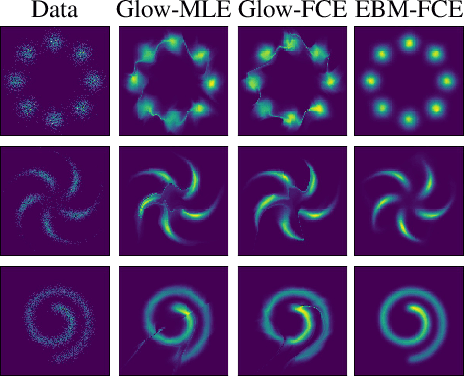
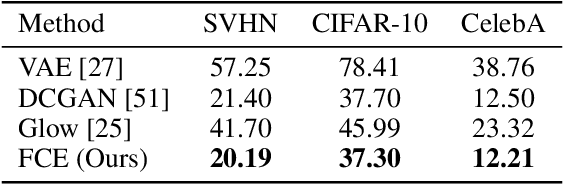
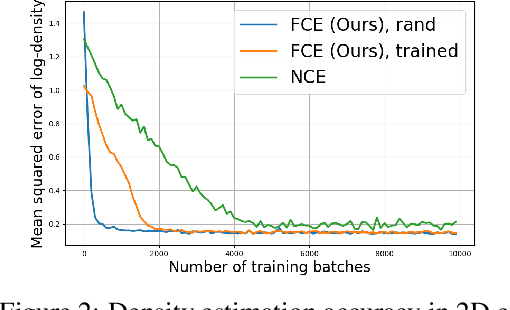
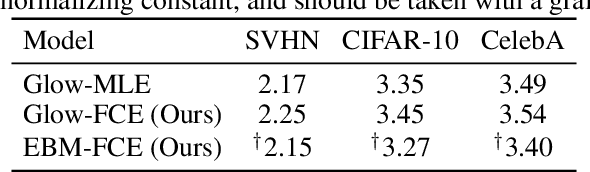
This paper studies a training method to jointly estimate an energy-based model and a flow-based model, in which the two models are iteratively updated based on a shared adversarial value function. This joint training method has the following traits. (1) The update of the energy-based model is based on noise contrastive estimation, with the flow model serving as a strong noise distribution. (2) The update of the flow model approximately minimizes the Jensen-Shannon divergence between the flow model and the data distribution. (3) Unlike generative adversarial networks (GAN) which estimates an implicit probability distribution defined by a generator model, our method estimates two explicit probabilistic distributions on the data. Using the proposed method we demonstrate a significant improvement on the synthesis quality of the flow model, and show the effectiveness of unsupervised feature learning by the learned energy-based model. Furthermore, the proposed training method can be easily adapted to semi-supervised learning. We achieve competitive results to the state-of-the-art semi-supervised learning methods.
Modelling EHR timeseries by restricting feature interaction
Nov 14, 2019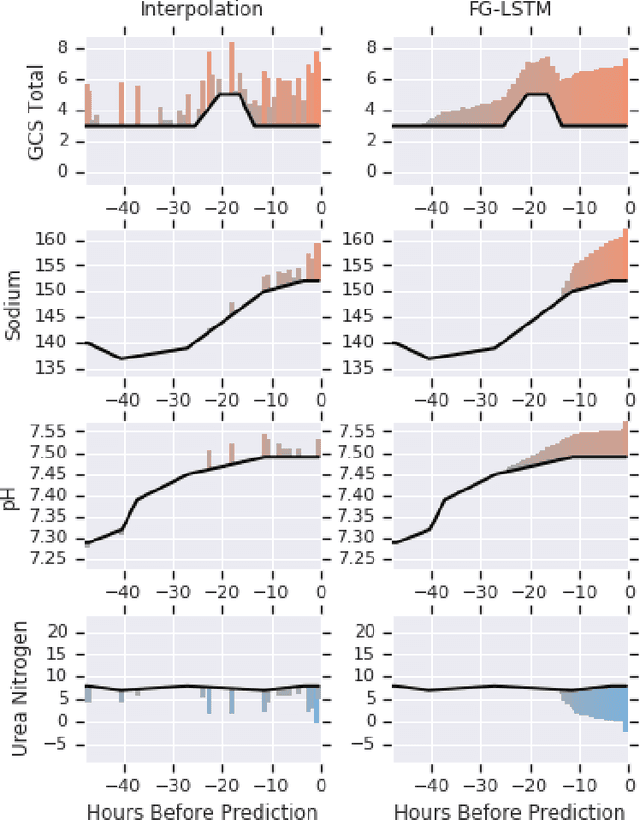
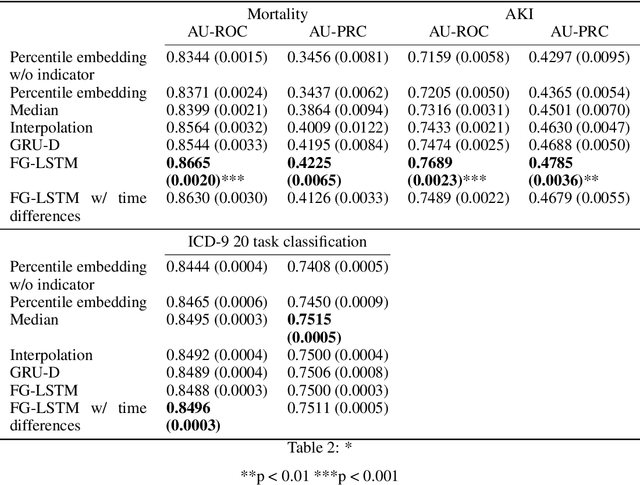
Time series data are prevalent in electronic health records, mostly in the form of physiological parameters such as vital signs and lab tests. The patterns of these values may be significant indicators of patients' clinical states and there might be patterns that are unknown to clinicians but are highly predictive of some outcomes. Many of these values are also missing which makes it difficult to apply existing methods like decision trees. We propose a recurrent neural network model that reduces overfitting to noisy observations by limiting interactions between features. We analyze its performance on mortality, ICD-9 and AKI prediction from observational values on the Medical Information Mart for Intensive Care III (MIMIC-III) dataset. Our models result in an improvement of 1.1% [p<0.01] in AU-ROC for mortality prediction under the MetaVision subset and 1.0% and 2.2% [p<0.01] respectively for mortality and AKI under the full MIMIC-III dataset compared to existing state-of-the-art interpolation, embedding and decay-based recurrent models.