 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAndreas Stolcke
Fusion of Embeddings Networks for Robust Combination of Text Dependent and Independent Speaker Recognition
Jun 18, 2021
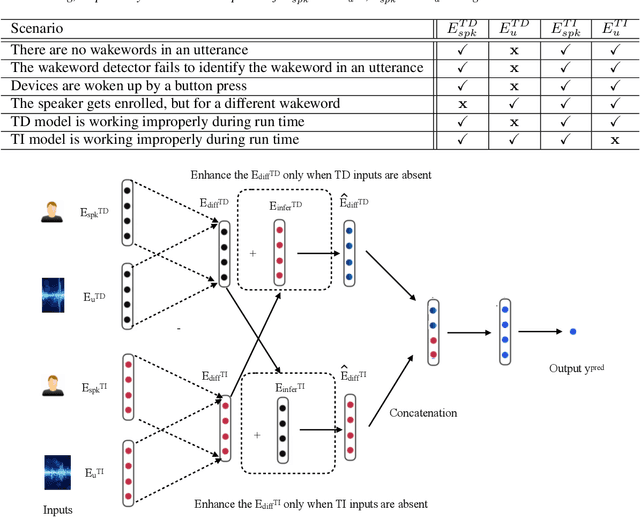
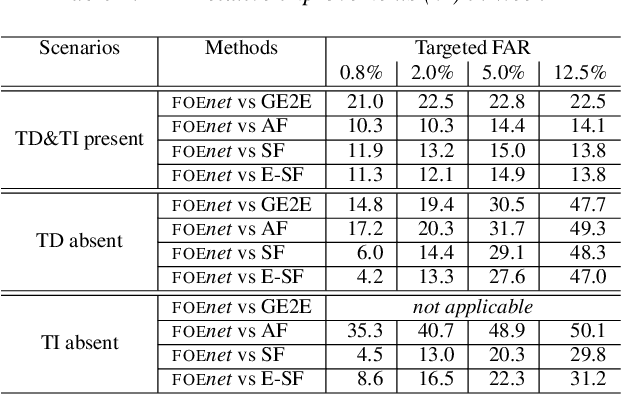
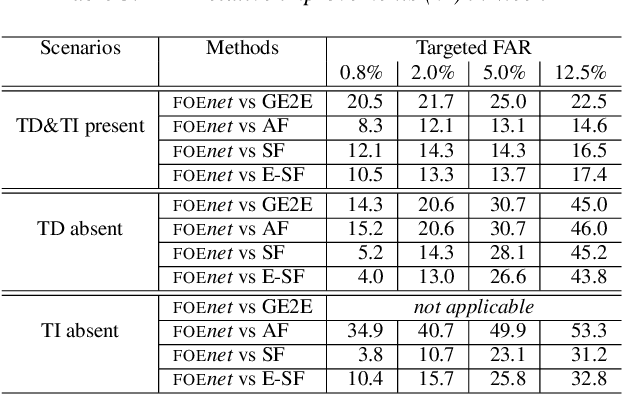
By implicitly recognizing a user based on his/her speech input, speaker identification enables many downstream applications, such as personalized system behavior and expedited shopping checkouts. Based on whether the speech content is constrained or not, both text-dependent (TD) and text-independent (TI) speaker recognition models may be used. We wish to combine the advantages of both types of models through an ensemble system to make more reliable predictions. However, any such combined approach has to be robust to incomplete inputs, i.e., when either TD or TI input is missing. As a solution we propose a fusion of embeddings network foenet architecture, combining joint learning with neural attention. We compare foenet with four competitive baseline methods on a dataset of voice assistant inputs, and show that it achieves higher accuracy than the baseline and score fusion methods, especially in the presence of incomplete inputs.
Graph-based Label Propagation for Semi-Supervised Speaker Identification
Jun 15, 2021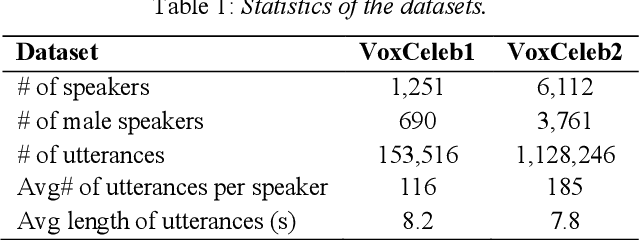
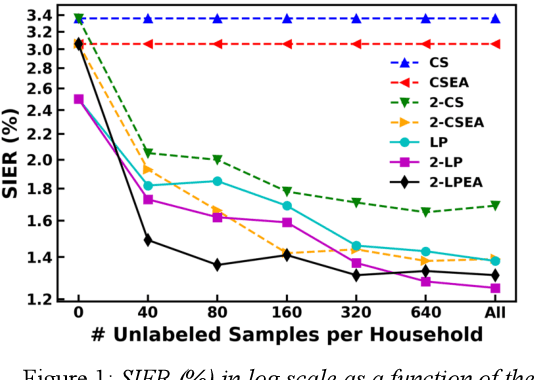
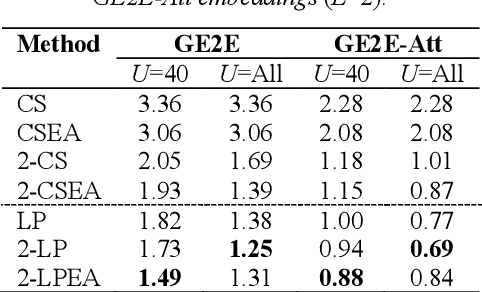
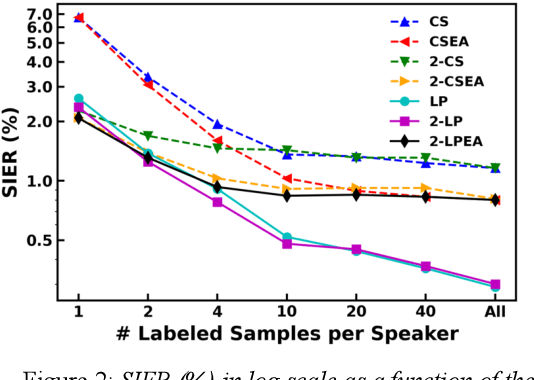
Speaker identification in the household scenario (e.g., for smart speakers) is typically based on only a few enrollment utterances but a much larger set of unlabeled data, suggesting semisupervised learning to improve speaker profiles. We propose a graph-based semi-supervised learning approach for speaker identification in the household scenario, to leverage the unlabeled speech samples. In contrast to most of the works in speaker recognition that focus on speaker-discriminative embeddings, this work focuses on speaker label inference (scoring). Given a pre-trained embedding extractor, graph-based learning allows us to integrate information about both labeled and unlabeled utterances. Considering each utterance as a graph node, we represent pairwise utterance similarity scores as edge weights. Graphs are constructed per household, and speaker identities are propagated to unlabeled nodes to optimize a global consistency criterion. We show in experiments on the VoxCeleb dataset that this approach makes effective use of unlabeled data and improves speaker identification accuracy compared to two state-of-the-art scoring methods as well as their semi-supervised variants based on pseudo-labels.
End-to-end Neural Diarization: From Transformer to Conformer
Jun 14, 2021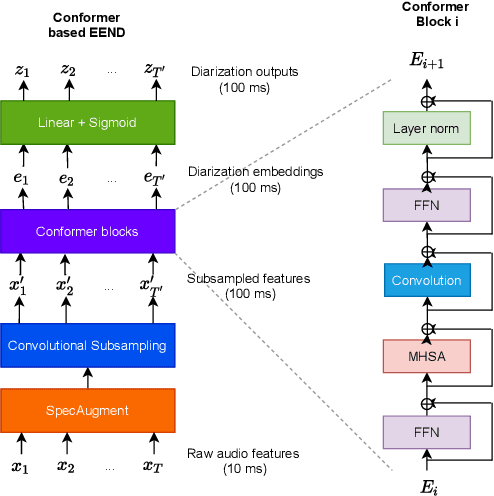
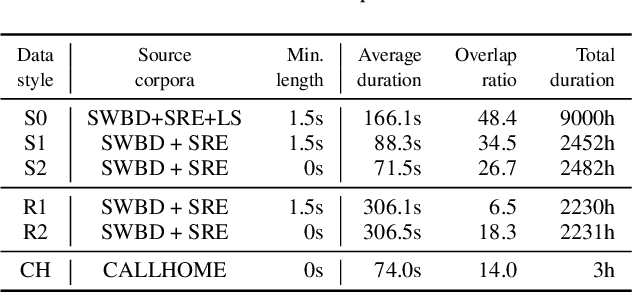
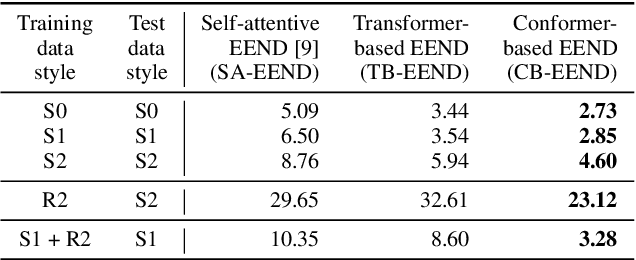
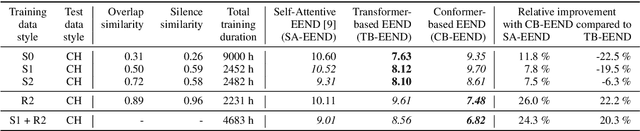
We propose a new end-to-end neural diarization (EEND) system that is based on Conformer, a recently proposed neural architecture that combines convolutional mappings and Transformer to model both local and global dependencies in speech. We first show that data augmentation and convolutional subsampling layers enhance the original self-attentive EEND in the Transformer-based EEND, and then Conformer gives an additional gain over the Transformer-based EEND. However, we notice that the Conformer-based EEND does not generalize as well from simulated to real conversation data as the Transformer-based model. This leads us to quantify the mismatch between simulated data and real speaker behavior in terms of temporal statistics reflecting turn-taking between speakers, and investigate its correlation with diarization error. By mixing simulated and real data in EEND training, we mitigate the mismatch further, with Conformer-based EEND achieving 24% error reduction over the baseline SA-EEND system, and 10% improvement over the best augmented Transformer-based system, on two-speaker CALLHOME data.
Attention-based Contextual Language Model Adaptation for Speech Recognition
Jun 02, 2021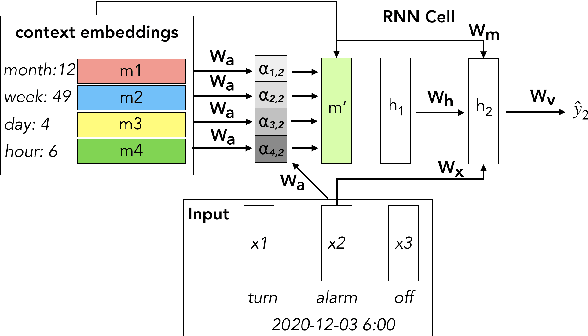
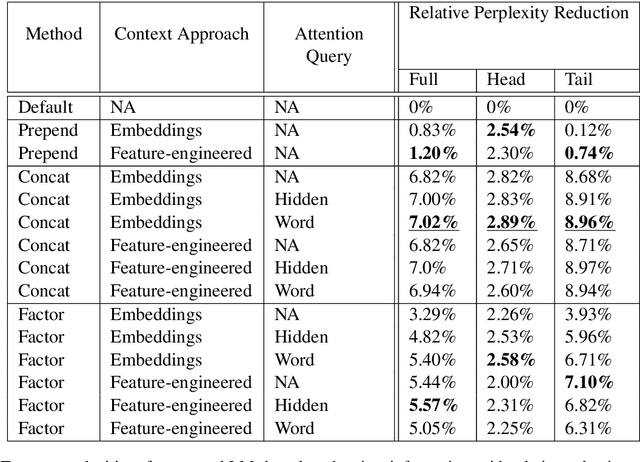
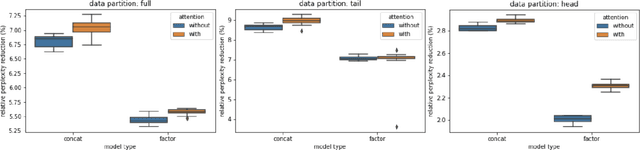
Language modeling (LM) for automatic speech recognition (ASR) does not usually incorporate utterance level contextual information. For some domains like voice assistants, however, additional context, such as the time at which an utterance was spoken, provides a rich input signal. We introduce an attention mechanism for training neural speech recognition language models on both text and non-linguistic contextual data. When applied to a large de-identified dataset of utterances collected by a popular voice assistant platform, our method reduces perplexity by 7.0% relative over a standard LM that does not incorporate contextual information. When evaluated on utterances extracted from the long tail of the dataset, our method improves perplexity by 9.0% relative over a standard LM and by over 2.8% relative when compared to a state-of-the-art model for contextual LM.
Listen with Intent: Improving Speech Recognition with Audio-to-Intent Front-End
May 14, 2021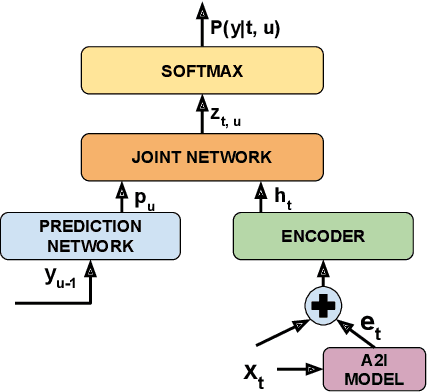
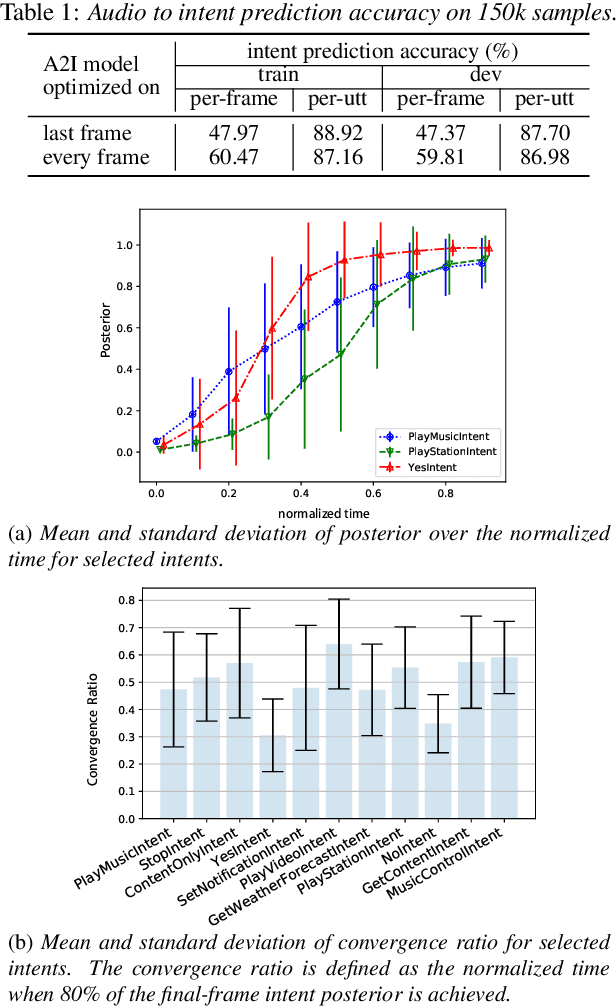
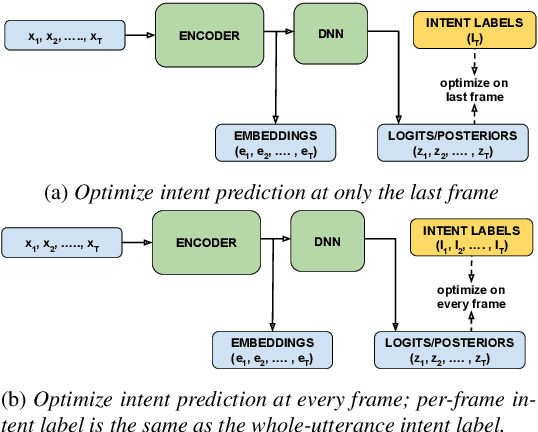
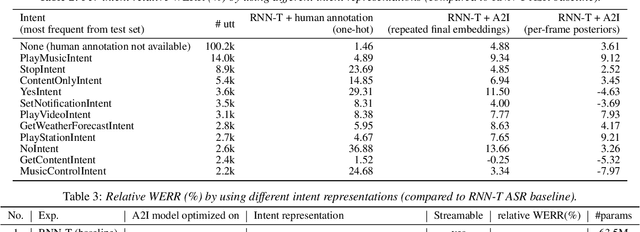
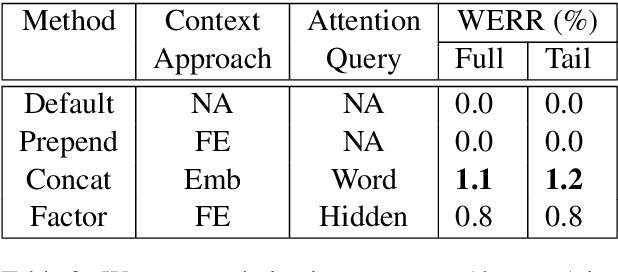
Comprehending the overall intent of an utterance helps a listener recognize the individual words spoken. Inspired by this fact, we perform a novel study of the impact of explicitly incorporating intent representations as additional information to improve a recurrent neural network-transducer (RNN-T) based automatic speech recognition (ASR) system. An audio-to-intent (A2I) model encodes the intent of the utterance in the form of embeddings or posteriors, and these are used as auxiliary inputs for RNN-T training and inference. Experimenting with a 50k-hour far-field English speech corpus, this study shows that when running the system in non-streaming mode, where intent representation is extracted from the entire utterance and then used to bias streaming RNN-T search from the start, it provides a 5.56% relative word error rate reduction (WERR). On the other hand, a streaming system using per-frame intent posteriors as extra inputs for the RNN-T ASR system yields a 3.33% relative WERR. A further detailed analysis of the streaming system indicates that our proposed method brings especially good gain on media-playing related intents (e.g. 9.12% relative WERR on PlayMusicIntent).
Reranking Machine Translation Hypotheses with Structured and Web-based Language Models
Apr 25, 2021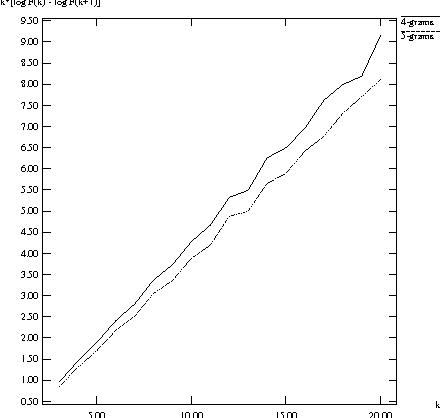
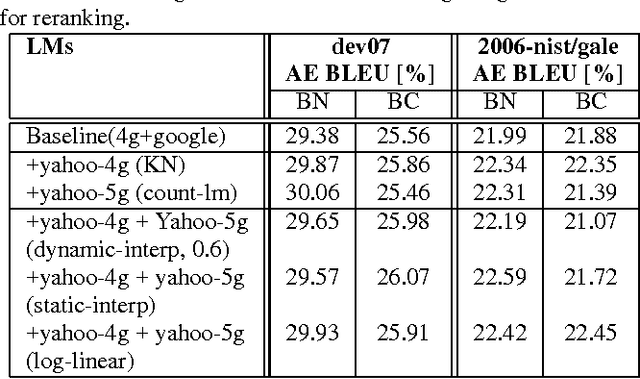
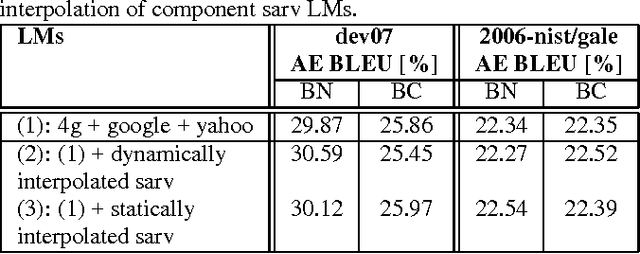
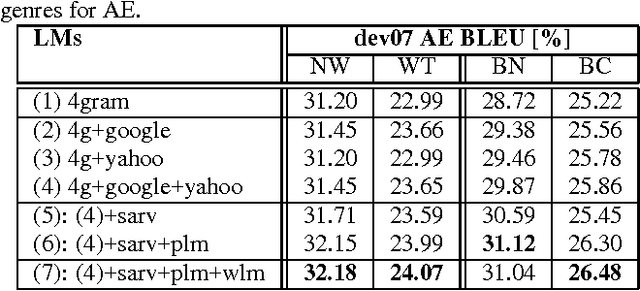
In this paper, we investigate the use of linguistically motivated and computationally efficient structured language models for reranking N-best hypotheses in a statistical machine translation system. These language models, developed from Constraint Dependency Grammar parses, tightly integrate knowledge of words, morphological and lexical features, and syntactic dependency constraints. Two structured language models are applied for N-best rescoring, one is an almost-parsing language model, and the other utilizes more syntactic features by explicitly modeling syntactic dependencies between words. We also investigate effective and efficient language modeling methods to use N-grams extracted from up to 1 teraword of web documents. We apply all these language models for N-best re-ranking on the NIST and DARPA GALE program 2006 and 2007 machine translation evaluation tasks and find that the combination of these language models increases the BLEU score up to 1.6% absolutely on blind test sets.
* With a correction to the math in Figure 1 caption
Wav2vec-C: A Self-supervised Model for Speech Representation Learning
Mar 09, 2021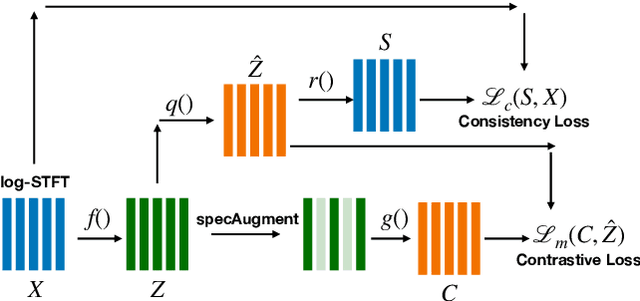

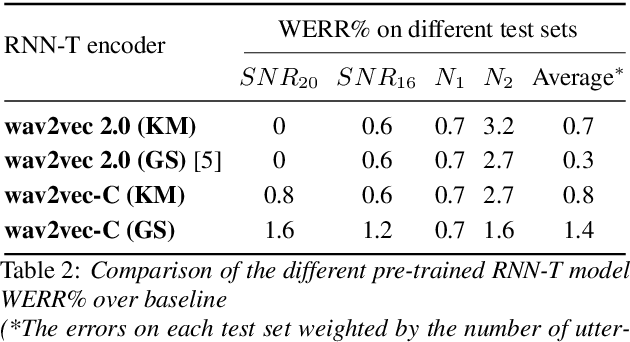
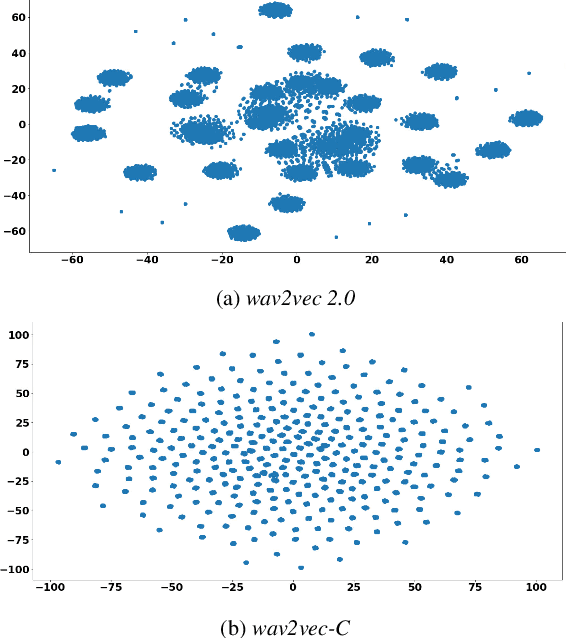
Wav2vec-C introduces a novel representation learning technique combining elements from wav2vec 2.0 and VQ-VAE. Our model learns to reproduce quantized representations from partially masked speech encoding using a contrastive loss in a way similar to Wav2vec 2.0. However, the quantization process is regularized by an additional consistency network that learns to reconstruct the input features to the wav2vec 2.0 network from the quantized representations in a way similar to a VQ-VAE model. The proposed self-supervised model is trained on 10k hours of unlabeled data and subsequently used as the speech encoder in a RNN-T ASR model and fine-tuned with 1k hours of labeled data. This work is one of only a few studies of self-supervised learning on speech tasks with a large volume of real far-field labeled data. The Wav2vec-C encoded representations achieves, on average, twice the error reduction over baseline and a higher codebook utilization in comparison to wav2vec 2.0
Personalization Strategies for End-to-End Speech Recognition Systems
Feb 15, 2021
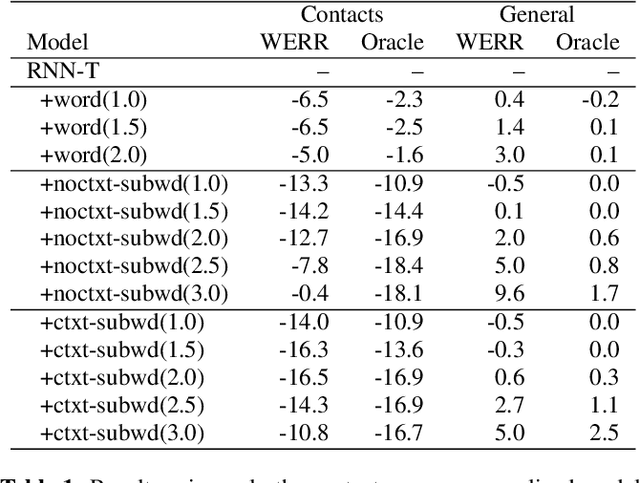
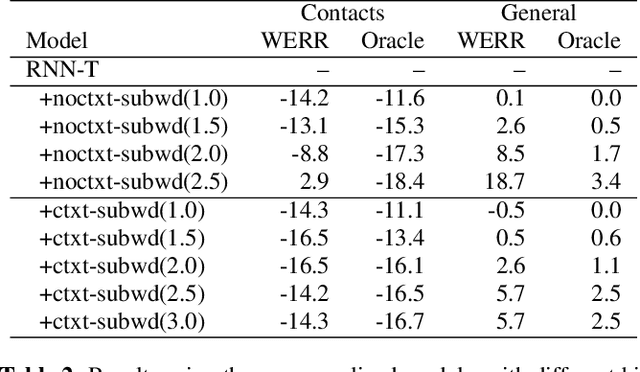
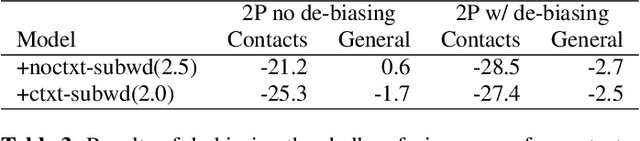
The recognition of personalized content, such as contact names, remains a challenging problem for end-to-end speech recognition systems. In this work, we demonstrate how first and second-pass rescoring strategies can be leveraged together to improve the recognition of such words. Following previous work, we use a shallow fusion approach to bias towards recognition of personalized content in the first-pass decoding. We show that such an approach can improve personalized content recognition by up to 16% with minimum degradation on the general use case. We describe a fast and scalable algorithm that enables our biasing models to remain at the word-level, while applying the biasing at the subword level. This has the advantage of not requiring the biasing models to be dependent on any subword symbol table. We also describe a novel second-pass de-biasing approach: used in conjunction with a first-pass shallow fusion that optimizes on oracle WER, we can achieve an additional 14% improvement on personalized content recognition, and even improve accuracy for the general use case by up to 2.5%.
Do as I mean, not as I say: Sequence Loss Training for Spoken Language Understanding
Feb 12, 2021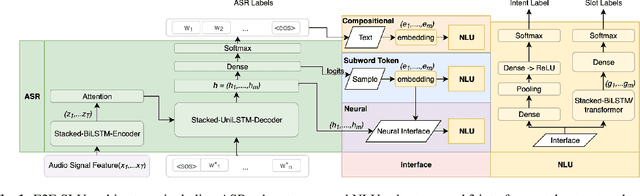
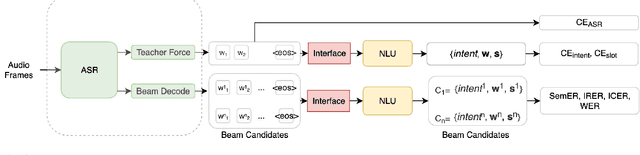
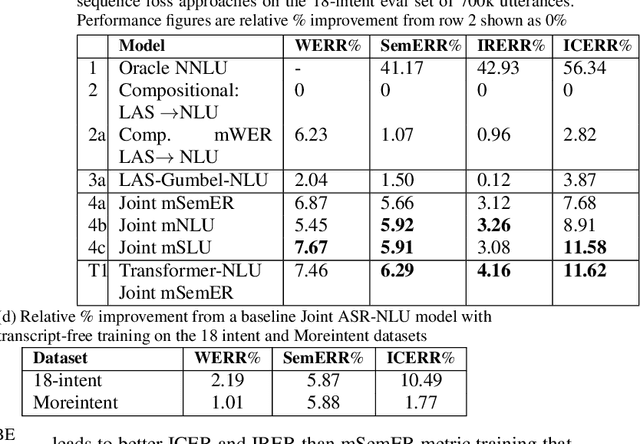
Spoken language understanding (SLU) systems extract transcriptions, as well as semantics of intent or named entities from speech, and are essential components of voice activated systems. SLU models, which either directly extract semantics from audio or are composed of pipelined automatic speech recognition (ASR) and natural language understanding (NLU) models, are typically trained via differentiable cross-entropy losses, even when the relevant performance metrics of interest are word or semantic error rates. In this work, we propose non-differentiable sequence losses based on SLU metrics as a proxy for semantic error and use the REINFORCE trick to train ASR and SLU models with this loss. We show that custom sequence loss training is the state-of-the-art on open SLU datasets and leads to 6% relative improvement in both ASR and NLU performance metrics on large proprietary datasets. We also demonstrate how the semantic sequence loss training paradigm can be used to update ASR and SLU models without transcripts, using semantic feedback alone.
Contrastive Unsupervised Learning for Speech Emotion Recognition
Feb 12, 2021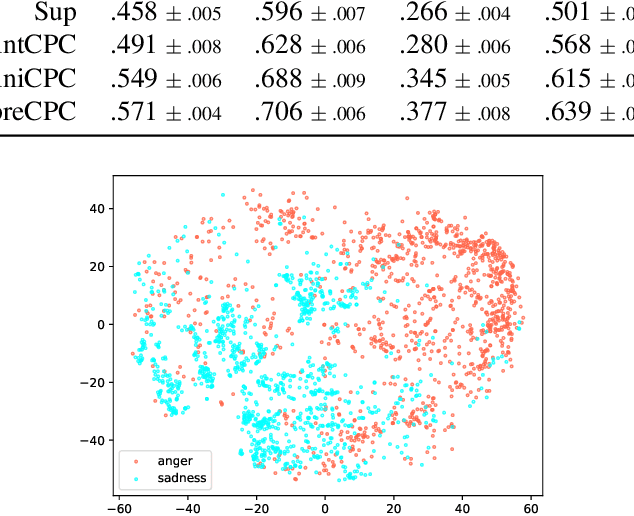

Speech emotion recognition (SER) is a key technology to enable more natural human-machine communication. However, SER has long suffered from a lack of public large-scale labeled datasets. To circumvent this problem, we investigate how unsupervised representation learning on unlabeled datasets can benefit SER. We show that the contrastive predictive coding (CPC) method can learn salient representations from unlabeled datasets, which improves emotion recognition performance. In our experiments, this method achieved state-of-the-art concordance correlation coefficient (CCC) performance for all emotion primitives (activation, valence, and dominance) on IEMOCAP. Additionally, on the MSP- Podcast dataset, our method obtained considerable performance improvements compared to baselines.