 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePost-Training Embedding Alignment for Decoupling Enrollment and Runtime Speaker Recognition Models
Jan 23, 2024

Automated speaker identification (SID) is a crucial step for the personalization of a wide range of speech-enabled services. Typical SID systems use a symmetric enrollment-verification framework with a single model to derive embeddings both offline for voice profiles extracted from enrollment utterances, and online from runtime utterances. Due to the distinct circumstances of enrollment and runtime, such as different computation and latency constraints, several applications would benefit from an asymmetric enrollment-verification framework that uses different models for enrollment and runtime embedding generation. To support this asymmetric SID where each of the two models can be updated independently, we propose using a lightweight neural network to map the embeddings from the two independent models to a shared speaker embedding space. Our results show that this approach significantly outperforms cosine scoring in a shared speaker logit space for models that were trained with a contrastive loss on large datasets with many speaker identities. This proposed Neural Embedding Speaker Space Alignment (NESSA) combined with an asymmetric update of only one of the models delivers at least 60% of the performance gain achieved by updating both models in the standard symmetric SID approach.
Adversarial Reweighting for Speaker Verification Fairness
Jul 15, 2022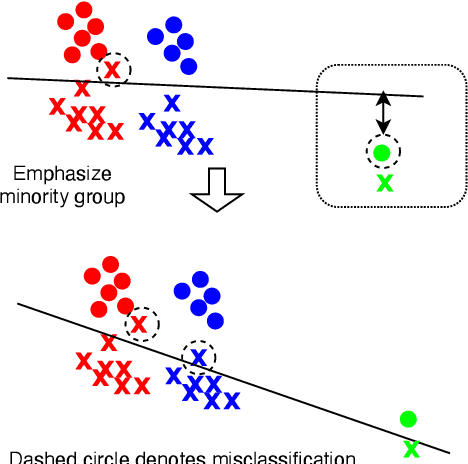
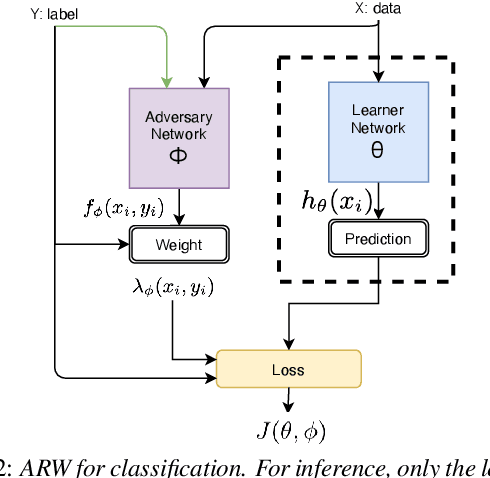
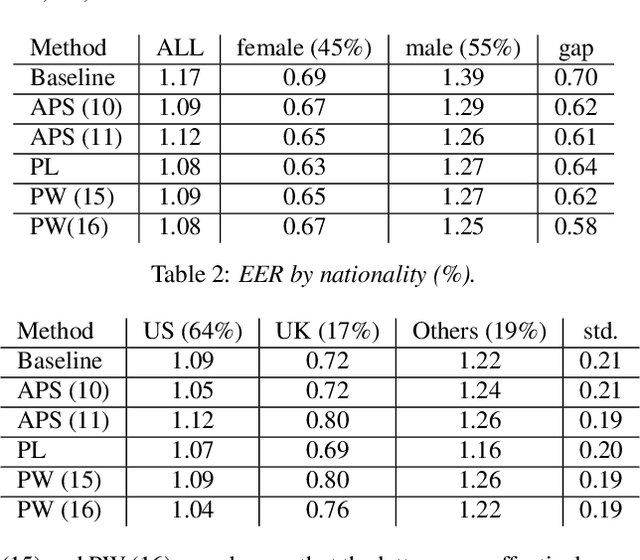
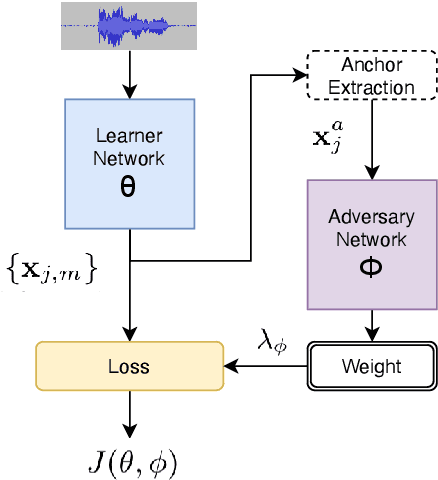
We address performance fairness for speaker verification using the adversarial reweighting (ARW) method. ARW is reformulated for speaker verification with metric learning, and shown to improve results across different subgroups of gender and nationality, without requiring annotation of subgroups in the training data. An adversarial network learns a weight for each training sample in the batch so that the main learner is forced to focus on poorly performing instances. Using a min-max optimization algorithm, this method improves overall speaker verification fairness. We present three different ARWformulations: accumulated pairwise similarity, pseudo-labeling, and pairwise weighting, and measure their performance in terms of equal error rate (EER) on the VoxCeleb corpus. Results show that the pairwise weighting method can achieve 1.08% overall EER, 1.25% for male and 0.67% for female speakers, with relative EER reductions of 7.7%, 10.1% and 3.0%, respectively. For nationality subgroups, the proposed algorithm showed 1.04% EER for US speakers, 0.76% for UK speakers, and 1.22% for all others. The absolute EER gap between gender groups was reduced from 0.70% to 0.58%, while the standard deviation over nationality groups decreased from 0.21 to 0.19.
Fusion of Embeddings Networks for Robust Combination of Text Dependent and Independent Speaker Recognition
Jun 18, 2021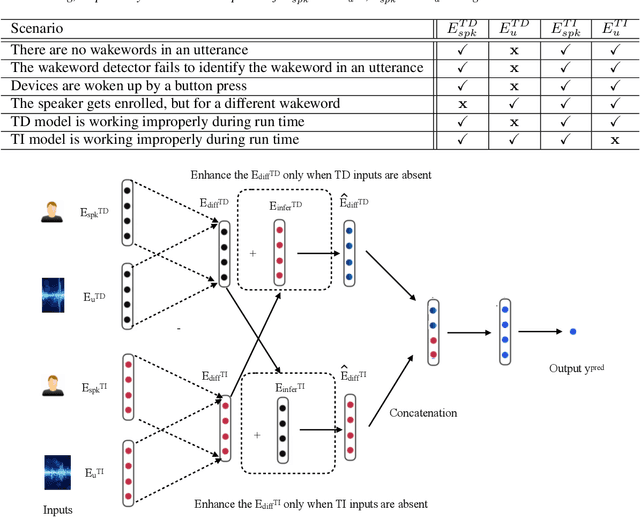
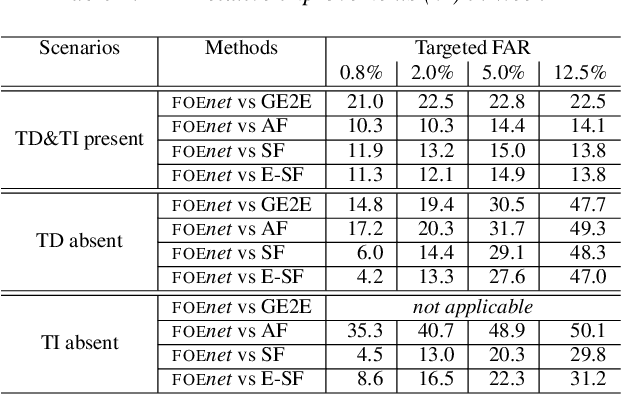
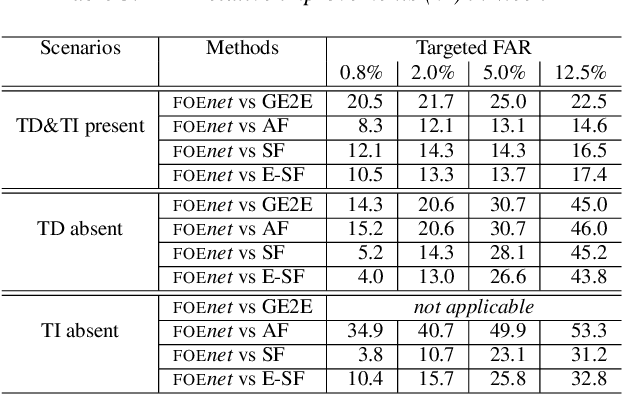
By implicitly recognizing a user based on his/her speech input, speaker identification enables many downstream applications, such as personalized system behavior and expedited shopping checkouts. Based on whether the speech content is constrained or not, both text-dependent (TD) and text-independent (TI) speaker recognition models may be used. We wish to combine the advantages of both types of models through an ensemble system to make more reliable predictions. However, any such combined approach has to be robust to incomplete inputs, i.e., when either TD or TI input is missing. As a solution we propose a fusion of embeddings network foenet architecture, combining joint learning with neural attention. We compare foenet with four competitive baseline methods on a dataset of voice assistant inputs, and show that it achieves higher accuracy than the baseline and score fusion methods, especially in the presence of incomplete inputs.