 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Novel Automatic Framework for Speaker Drift Detection in Synthesized Speech
Apr 07, 2026Recent diffusion-based text-to-speech (TTS) models achieve high naturalness and expressiveness, yet often suffer from speaker drift, a subtle, gradual shift in perceived speaker identity within a single utterance. This underexplored phenomenon undermines the coherence of synthetic speech, especially in long-form or interactive settings. We introduce the first automatic framework for detecting speaker drift by formulating it as a binary classification task over utterance-level speaker consistency. Our method computes cosine similarity across overlapping segments of synthesized speech and prompts large language models (LLMs) with structured representations to assess drift. We provide theoretical guarantees for cosine-based drift detection and demonstrate that speaker embeddings exhibit meaningful geometric clustering on the unit sphere. To support evaluation, we construct a high-quality synthetic benchmark with human-validated speaker drift annotations. Experiments with multiple state-of-the-art LLMs confirm the viability of this embedding-to-reasoning pipeline. Our work establishes speaker drift as a standalone research problem and bridges geometric signal analysis with LLM-based perceptual reasoning in modern TTS.
End-to-end Neural Diarization: From Transformer to Conformer
Jun 14, 2021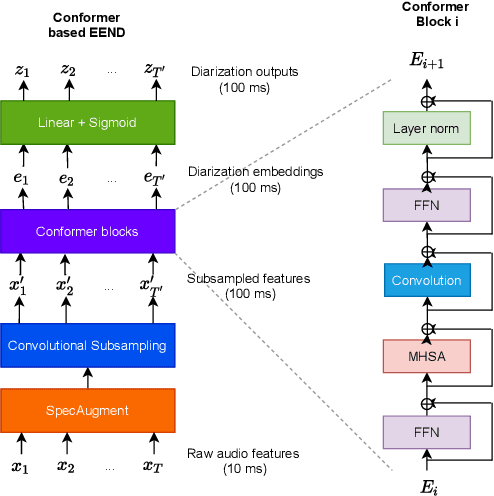
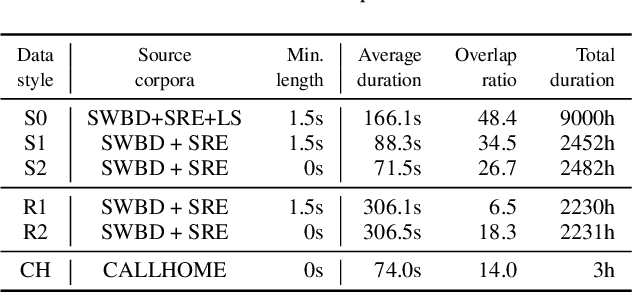
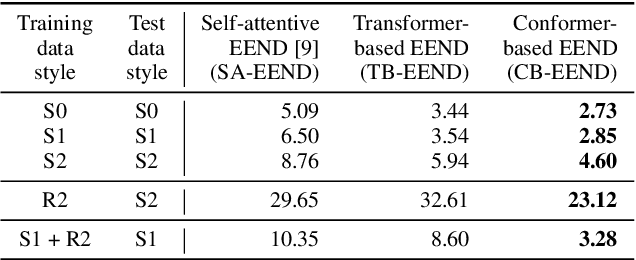
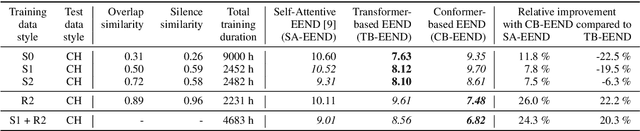
We propose a new end-to-end neural diarization (EEND) system that is based on Conformer, a recently proposed neural architecture that combines convolutional mappings and Transformer to model both local and global dependencies in speech. We first show that data augmentation and convolutional subsampling layers enhance the original self-attentive EEND in the Transformer-based EEND, and then Conformer gives an additional gain over the Transformer-based EEND. However, we notice that the Conformer-based EEND does not generalize as well from simulated to real conversation data as the Transformer-based model. This leads us to quantify the mismatch between simulated data and real speaker behavior in terms of temporal statistics reflecting turn-taking between speakers, and investigate its correlation with diarization error. By mixing simulated and real data in EEND training, we mitigate the mismatch further, with Conformer-based EEND achieving 24% error reduction over the baseline SA-EEND system, and 10% improvement over the best augmented Transformer-based system, on two-speaker CALLHOME data.