 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePrITTI: Primitive-based Generation of Controllable and Editable 3D Semantic Scenes
Jun 23, 2025Large-scale 3D semantic scene generation has predominantly relied on voxel-based representations, which are memory-intensive, bound by fixed resolutions, and challenging to edit. In contrast, primitives represent semantic entities using compact, coarse 3D structures that are easy to manipulate and compose, making them an ideal representation for this task. In this paper, we introduce PrITTI, a latent diffusion-based framework that leverages primitives as the main foundational elements for generating compositional, controllable, and editable 3D semantic scene layouts. Our method adopts a hybrid representation, modeling ground surfaces in a rasterized format while encoding objects as vectorized 3D primitives. This decomposition is also reflected in a structured latent representation that enables flexible scene manipulation of ground and object components. To overcome the orientation ambiguities in conventional encoding methods, we introduce a stable Cholesky-based parameterization that jointly encodes object size and orientation. Experiments on the KITTI-360 dataset show that PrITTI outperforms a voxel-based baseline in generation quality, while reducing memory requirements by up to $3\times$. In addition, PrITTI enables direct instance-level manipulation of objects in the scene and supports a range of downstream applications, including scene inpainting, outpainting, and photo-realistic street-view synthesis.
ReSim: Reliable World Simulation for Autonomous Driving
Jun 11, 2025How can we reliably simulate future driving scenarios under a wide range of ego driving behaviors? Recent driving world models, developed exclusively on real-world driving data composed mainly of safe expert trajectories, struggle to follow hazardous or non-expert behaviors, which are rare in such data. This limitation restricts their applicability to tasks such as policy evaluation. In this work, we address this challenge by enriching real-world human demonstrations with diverse non-expert data collected from a driving simulator (e.g., CARLA), and building a controllable world model trained on this heterogeneous corpus. Starting with a video generator featuring a diffusion transformer architecture, we devise several strategies to effectively integrate conditioning signals and improve prediction controllability and fidelity. The resulting model, ReSim, enables Reliable Simulation of diverse open-world driving scenarios under various actions, including hazardous non-expert ones. To close the gap between high-fidelity simulation and applications that require reward signals to judge different actions, we introduce a Video2Reward module that estimates a reward from ReSim's simulated future. Our ReSim paradigm achieves up to 44% higher visual fidelity, improves controllability for both expert and non-expert actions by over 50%, and boosts planning and policy selection performance on NAVSIM by 2% and 25%, respectively.
Pseudo-Simulation for Autonomous Driving
Jun 04, 2025Existing evaluation paradigms for Autonomous Vehicles (AVs) face critical limitations. Real-world evaluation is often challenging due to safety concerns and a lack of reproducibility, whereas closed-loop simulation can face insufficient realism or high computational costs. Open-loop evaluation, while being efficient and data-driven, relies on metrics that generally overlook compounding errors. In this paper, we propose pseudo-simulation, a novel paradigm that addresses these limitations. Pseudo-simulation operates on real datasets, similar to open-loop evaluation, but augments them with synthetic observations generated prior to evaluation using 3D Gaussian Splatting. Our key idea is to approximate potential future states the AV might encounter by generating a diverse set of observations that vary in position, heading, and speed. Our method then assigns a higher importance to synthetic observations that best match the AV's likely behavior using a novel proximity-based weighting scheme. This enables evaluating error recovery and the mitigation of causal confusion, as in closed-loop benchmarks, without requiring sequential interactive simulation. We show that pseudo-simulation is better correlated with closed-loop simulations (R^2=0.8) than the best existing open-loop approach (R^2=0.7). We also establish a public leaderboard for the community to benchmark new methodologies with pseudo-simulation. Our code is available at https://github.com/autonomousvision/navsim.
Benchmarking Feature Upsampling Methods for Vision Foundation Models using Interactive Segmentation
May 04, 2025Vision Foundation Models (VFMs) are large-scale, pre-trained models that serve as general-purpose backbones for various computer vision tasks. As VFMs' popularity grows, there is an increasing interest in understanding their effectiveness for dense prediction tasks. However, VFMs typically produce low-resolution features, limiting their direct applicability in this context. One way to tackle this limitation is by employing a task-agnostic feature upsampling module that refines VFM features resolution. To assess the effectiveness of this approach, we investigate Interactive Segmentation (IS) as a novel benchmark for evaluating feature upsampling methods on VFMs. Due to its inherent multimodal input, consisting of an image and a set of user-defined clicks, as well as its dense mask output, IS creates a challenging environment that demands comprehensive visual scene understanding. Our benchmarking experiments show that selecting appropriate upsampling strategies significantly improves VFM features quality. The code is released at https://github.com/havrylovv/iSegProbe
CaRL: Learning Scalable Planning Policies with Simple Rewards
Apr 24, 2025We investigate reinforcement learning (RL) for privileged planning in autonomous driving. State-of-the-art approaches for this task are rule-based, but these methods do not scale to the long tail. RL, on the other hand, is scalable and does not suffer from compounding errors like imitation learning. Contemporary RL approaches for driving use complex shaped rewards that sum multiple individual rewards, \eg~progress, position, or orientation rewards. We show that PPO fails to optimize a popular version of these rewards when the mini-batch size is increased, which limits the scalability of these approaches. Instead, we propose a new reward design based primarily on optimizing a single intuitive reward term: route completion. Infractions are penalized by terminating the episode or multiplicatively reducing route completion. We find that PPO scales well with higher mini-batch sizes when trained with our simple reward, even improving performance. Training with large mini-batch sizes enables efficient scaling via distributed data parallelism. We scale PPO to 300M samples in CARLA and 500M samples in nuPlan with a single 8-GPU node. The resulting model achieves 64 DS on the CARLA longest6 v2 benchmark, outperforming other RL methods with more complex rewards by a large margin. Requiring only minimal adaptations from its use in CARLA, the same method is the best learning-based approach on nuPlan. It scores 91.3 in non-reactive and 90.6 in reactive traffic on the Val14 benchmark while being an order of magnitude faster than prior work.
LoftUp: Learning a Coordinate-Based Feature Upsampler for Vision Foundation Models
Apr 18, 2025



Vision foundation models (VFMs) such as DINOv2 and CLIP have achieved impressive results on various downstream tasks, but their limited feature resolution hampers performance in applications requiring pixel-level understanding. Feature upsampling offers a promising direction to address this challenge. In this work, we identify two critical factors for enhancing feature upsampling: the upsampler architecture and the training objective. For the upsampler architecture, we introduce a coordinate-based cross-attention transformer that integrates the high-resolution images with coordinates and low-resolution VFM features to generate sharp, high-quality features. For the training objective, we propose constructing high-resolution pseudo-groundtruth features by leveraging class-agnostic masks and self-distillation. Our approach effectively captures fine-grained details and adapts flexibly to various input and feature resolutions. Through experiments, we demonstrate that our approach significantly outperforms existing feature upsampling techniques across various downstream tasks. Our code is released at https://github.com/andrehuang/loftup.
Scholar Inbox: Personalized Paper Recommendations for Scientists
Apr 11, 2025



Scholar Inbox is a new open-access platform designed to address the challenges researchers face in staying current with the rapidly expanding volume of scientific literature. We provide personalized recommendations, continuous updates from open-access archives (arXiv, bioRxiv, etc.), visual paper summaries, semantic search, and a range of tools to streamline research workflows and promote open research access. The platform's personalized recommendation system is trained on user ratings, ensuring that recommendations are tailored to individual researchers' interests. To further enhance the user experience, Scholar Inbox also offers a map of science that provides an overview of research across domains, enabling users to easily explore specific topics. We use this map to address the cold start problem common in recommender systems, as well as an active learning strategy that iteratively prompts users to rate a selection of papers, allowing the system to learn user preferences quickly. We evaluate the quality of our recommendation system on a novel dataset of 800k user ratings, which we make publicly available, as well as via an extensive user study. https://www.scholar-inbox.com/
Easi3R: Estimating Disentangled Motion from DUSt3R Without Training
Mar 31, 2025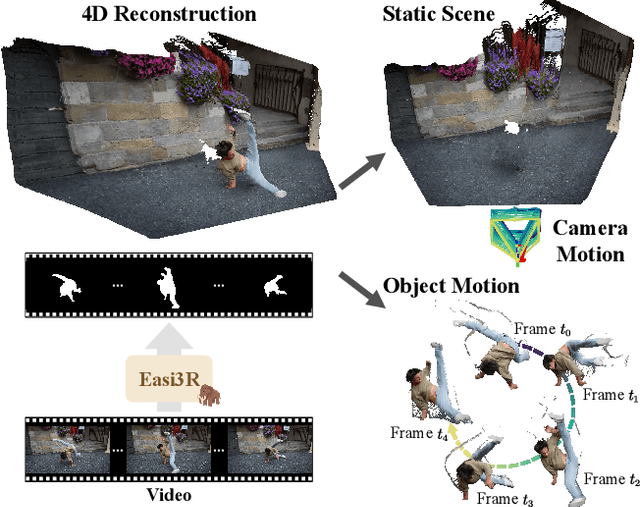



Recent advances in DUSt3R have enabled robust estimation of dense point clouds and camera parameters of static scenes, leveraging Transformer network architectures and direct supervision on large-scale 3D datasets. In contrast, the limited scale and diversity of available 4D datasets present a major bottleneck for training a highly generalizable 4D model. This constraint has driven conventional 4D methods to fine-tune 3D models on scalable dynamic video data with additional geometric priors such as optical flow and depths. In this work, we take an opposite path and introduce Easi3R, a simple yet efficient training-free method for 4D reconstruction. Our approach applies attention adaptation during inference, eliminating the need for from-scratch pre-training or network fine-tuning. We find that the attention layers in DUSt3R inherently encode rich information about camera and object motion. By carefully disentangling these attention maps, we achieve accurate dynamic region segmentation, camera pose estimation, and 4D dense point map reconstruction. Extensive experiments on real-world dynamic videos demonstrate that our lightweight attention adaptation significantly outperforms previous state-of-the-art methods that are trained or finetuned on extensive dynamic datasets. Our code is publicly available for research purpose at https://easi3r.github.io/
GenFusion: Closing the Loop between Reconstruction and Generation via Videos
Mar 27, 2025



Recently, 3D reconstruction and generation have demonstrated impressive novel view synthesis results, achieving high fidelity and efficiency. However, a notable conditioning gap can be observed between these two fields, e.g., scalable 3D scene reconstruction often requires densely captured views, whereas 3D generation typically relies on a single or no input view, which significantly limits their applications. We found that the source of this phenomenon lies in the misalignment between 3D constraints and generative priors. To address this problem, we propose a reconstruction-driven video diffusion model that learns to condition video frames on artifact-prone RGB-D renderings. Moreover, we propose a cyclical fusion pipeline that iteratively adds restoration frames from the generative model to the training set, enabling progressive expansion and addressing the viewpoint saturation limitations seen in previous reconstruction and generation pipelines. Our evaluation, including view synthesis from sparse view and masked input, validates the effectiveness of our approach.
EVolSplat: Efficient Volume-based Gaussian Splatting for Urban View Synthesis
Mar 26, 2025



Novel view synthesis of urban scenes is essential for autonomous driving-related applications.Existing NeRF and 3DGS-based methods show promising results in achieving photorealistic renderings but require slow, per-scene optimization. We introduce EVolSplat, an efficient 3D Gaussian Splatting model for urban scenes that works in a feed-forward manner. Unlike existing feed-forward, pixel-aligned 3DGS methods, which often suffer from issues like multi-view inconsistencies and duplicated content, our approach predicts 3D Gaussians across multiple frames within a unified volume using a 3D convolutional network. This is achieved by initializing 3D Gaussians with noisy depth predictions, and then refining their geometric properties in 3D space and predicting color based on 2D textures. Our model also handles distant views and the sky with a flexible hemisphere background model. This enables us to perform fast, feed-forward reconstruction while achieving real-time rendering. Experimental evaluations on the KITTI-360 and Waymo datasets show that our method achieves state-of-the-art quality compared to existing feed-forward 3DGS- and NeRF-based methods.