 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSlots, Transitions, Loops: Learning Composable World Models for ARC
Jun 10, 2026ARC tests in-context rule induction: given a few input-output demonstrations, a model must infer the hidden rule and apply it to a new query. While many approaches express ARC rules through language, code, or symbolic programs, ARC itself is visual-symbolic: rules appear as grid transitions over objects, colors, shapes, and spatial relations. We introduce Loop-OWM, an object-centric world-modeling architecture that learns these rules as composable transitions over structured states. It combines color-prototype slots, demonstration-conditioned task summaries, and a looped transition model with dense propagation and slot-conditioned correction. On both ARC-1 and ARC-2, Loop-OWM outperforms non-looped and looped baselines with comparable or fewer parameters. These results suggest that ARC rules can be learned not only as language descriptions or searched programs, but also as transitions over visual-symbolic world states.
Echoes of the Prior: A Computational Phenomenology of Forgetting
Jun 10, 2026Memory is not merely the storage of data; it is the scaffolding of reality. When biological memory fades, the world does not simply turn black; it regresses into an unrecognizable chaos. Echoes of the Prior is an interactive installation that attempts to visualize this subjective phenomenology of forgetting. By inducing controlled synaptic decay within a Feed-Forward 3D Reconstruction model, we create an artistic analogy for the erosion of the brain's predictive priors. We position the Neural Network not as a tool for engineering, but as a cognitive proxy - a silicon brain whose structural degeneration evokes the disorienting, poetic, and terrifying experience of losing one's grip on the world. Ultimately, we offer this framework as a catalyst, inviting the wider community to explore the uncharted potential of neuromorphic aesthetics in visualizing the fragility of intelligence. Interactive demo see https://decart-4d.github.io/.
GraphDreamer: Compositional 3D Scene Synthesis from Scene Graphs
Nov 30, 2023As pretrained text-to-image diffusion models become increasingly powerful, recent efforts have been made to distill knowledge from these text-to-image pretrained models for optimizing a text-guided 3D model. Most of the existing methods generate a holistic 3D model from a plain text input. This can be problematic when the text describes a complex scene with multiple objects, because the vectorized text embeddings are inherently unable to capture a complex description with multiple entities and relationships. Holistic 3D modeling of the entire scene further prevents accurate grounding of text entities and concepts. To address this limitation, we propose GraphDreamer, a novel framework to generate compositional 3D scenes from scene graphs, where objects are represented as nodes and their interactions as edges. By exploiting node and edge information in scene graphs, our method makes better use of the pretrained text-to-image diffusion model and is able to fully disentangle different objects without image-level supervision. To facilitate modeling of object-wise relationships, we use signed distance fields as representation and impose a constraint to avoid inter-penetration of objects. To avoid manual scene graph creation, we design a text prompt for ChatGPT to generate scene graphs based on text inputs. We conduct both qualitative and quantitative experiments to validate the effectiveness of GraphDreamer in generating high-fidelity compositional 3D scenes with disentangled object entities.
Learning Causal Representation for Face Transfer across Large Appearance Gap
Oct 17, 2021
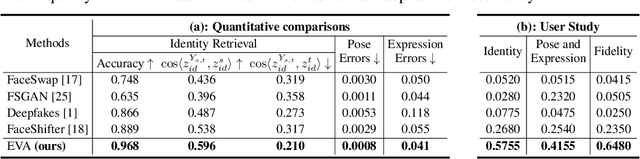
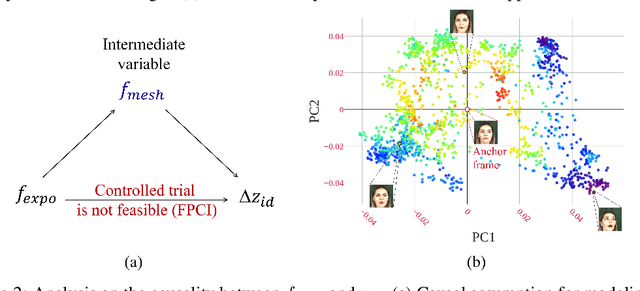
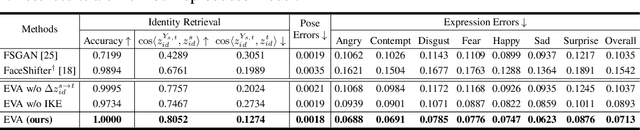
Identity transfer often faces the challenge of generalizing to new situations where large pose and expression or background gaps exist between source and target face images. To improve generalization in such situations, biases take a key role~\cite{mitchell_1980_bias}. This paper proposes an Errors-in-Variables Adapter (EVA) model to induce learning of proper generalizations by explicitly employing biases to identity estimation based on prior knowledge about the target situation. To better match the source face with the target situation in terms of pose, expression, and background factors, we model the bias as a causal effect of the target situation on source identity and estimate this effect through a controlled intervention trial. To achieve smoother transfer for the target face across the identity gap, we eliminate the target face specificity through multiple kernel regressions. The kernels are used to constrain the regressions to operate only on identity information in the internal representations of the target image, while leaving other perceptual information invariant. Combining these post-regression representations with the biased estimation for identity, EVA shows impressive performance even in the presence of large gaps, providing empirical evidence supporting the utility of the inductive biases in identity estimation.