 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDiffusion Based Causal Representation Learning
Nov 09, 2023Causal reasoning can be considered a cornerstone of intelligent systems. Having access to an underlying causal graph comes with the promise of cause-effect estimation and the identification of efficient and safe interventions. However, learning causal representations remains a major challenge, due to the complexity of many real-world systems. Previous works on causal representation learning have mostly focused on Variational Auto-Encoders (VAE). These methods only provide representations from a point estimate, and they are unsuitable to handle high dimensions. To overcome these problems, we proposed a new Diffusion-based Causal Representation Learning (DCRL) algorithm. This algorithm uses diffusion-based representations for causal discovery. DCRL offers access to infinite dimensional latent codes, which encode different levels of information in the latent code. In a first proof of principle, we investigate the use of DCRL for causal representation learning. We further demonstrate experimentally that this approach performs comparably well in identifying the causal structure and causal variables.
DiffEnc: Variational Diffusion with a Learned Encoder
Oct 30, 2023Diffusion models may be viewed as hierarchical variational autoencoders (VAEs) with two improvements: parameter sharing for the conditional distributions in the generative process and efficient computation of the loss as independent terms over the hierarchy. We consider two changes to the diffusion model that retain these advantages while adding flexibility to the model. Firstly, we introduce a data- and depth-dependent mean function in the diffusion process, which leads to a modified diffusion loss. Our proposed framework, DiffEnc, achieves state-of-the-art likelihood on CIFAR-10. Secondly, we let the ratio of the noise variance of the reverse encoder process and the generative process be a free weight parameter rather than being fixed to 1. This leads to theoretical insights: For a finite depth hierarchy, the evidence lower bound (ELBO) can be used as an objective for a weighted diffusion loss approach and for optimizing the noise schedule specifically for inference. For the infinite-depth hierarchy, on the other hand, the weight parameter has to be 1 to have a well-defined ELBO.
On the Generalization of Learned Structured Representations
Apr 25, 2023Despite tremendous progress over the past decade, deep learning methods generally fall short of human-level systematic generalization. It has been argued that explicitly capturing the underlying structure of data should allow connectionist systems to generalize in a more predictable and systematic manner. Indeed, evidence in humans suggests that interpreting the world in terms of symbol-like compositional entities may be crucial for intelligent behavior and high-level reasoning. Another common limitation of deep learning systems is that they require large amounts of training data, which can be expensive to obtain. In representation learning, large datasets are leveraged to learn generic data representations that may be useful for efficient learning of arbitrary downstream tasks. This thesis is about structured representation learning. We study methods that learn, with little or no supervision, representations of unstructured data that capture its hidden structure. In the first part of the thesis, we focus on representations that disentangle the explanatory factors of variation of the data. We scale up disentangled representation learning to a novel robotic dataset, and perform a systematic large-scale study on the role of pretrained representations for out-of-distribution generalization in downstream robotic tasks. The second part of this thesis focuses on object-centric representations, which capture the compositional structure of the input in terms of symbol-like entities, such as objects in visual scenes. Object-centric learning methods learn to form meaningful entities from unstructured input, enabling symbolic information processing on a connectionist substrate. In this study, we train a selection of methods on several common datasets, and investigate their usefulness for downstream tasks and their ability to generalize out of distribution.
Assessing Neural Network Robustness via Adversarial Pivotal Tuning
Nov 17, 2022The ability to assess the robustness of image classifiers to a diverse set of manipulations is essential to their deployment in the real world. Recently, semantic manipulations of real images have been considered for this purpose, as they may not arise using standard adversarial settings. However, such semantic manipulations are often limited to style, color or attribute changes. While expressive, these manipulations do not consider the full capacity of a pretrained generator to affect adversarial image manipulations. In this work, we aim at leveraging the full capacity of a pretrained image generator to generate highly detailed, diverse and photorealistic image manipulations. Inspired by recent GAN-based image inversion methods, we propose a method called Adversarial Pivotal Tuning (APT). APT first finds a pivot latent space input to a pretrained generator that best reconstructs an input image. It then adjusts the weights of the generator to create small, but semantic, manipulations which fool a pretrained classifier. Crucially, APT changes both the input and the weights of the pretrained generator, while preserving its expressive latent editing capability, thus allowing the use of its full capacity in creating semantic adversarial manipulations. We demonstrate that APT generates a variety of semantic image manipulations, which preserve the input image class, but which fool a variety of pretrained classifiers. We further demonstrate that classifiers trained to be robust to other robustness benchmarks, are not robust to our generated manipulations and propose an approach to improve the robustness towards our generated manipulations. Code available at: https://captaine.github.io/apt/
DCI-ES: An Extended Disentanglement Framework with Connections to Identifiability
Oct 01, 2022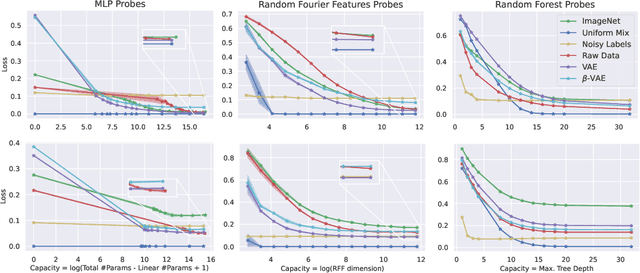
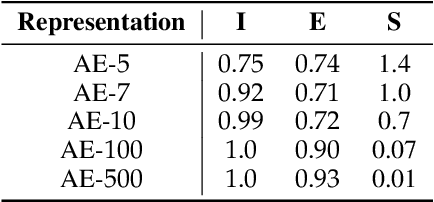
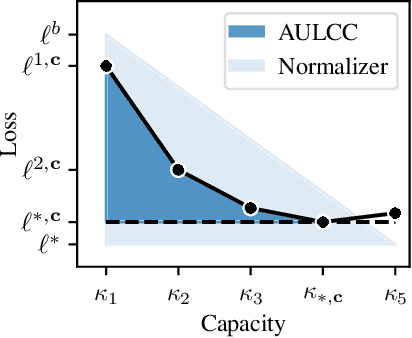
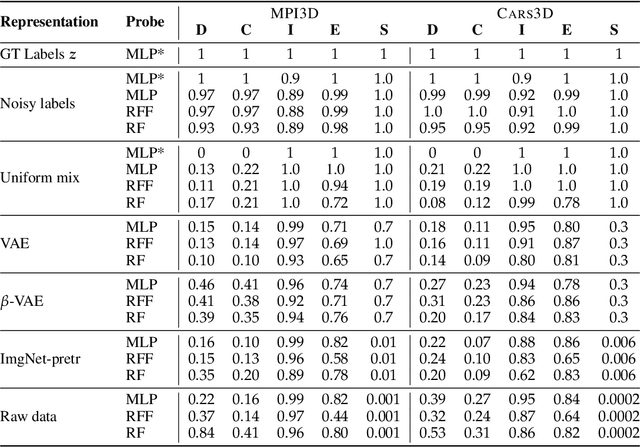
In representation learning, a common approach is to seek representations which disentangle the underlying factors of variation. Eastwood & Williams (2018) proposed three metrics for quantifying the quality of such disentangled representations: disentanglement (D), completeness (C) and informativeness (I). In this work, we first connect this DCI framework to two common notions of linear and nonlinear identifiability, thus establishing a formal link between disentanglement and the closely-related field of independent component analysis. We then propose an extended DCI-ES framework with two new measures of representation quality - explicitness (E) and size (S) - and point out how D and C can be computed for black-box predictors. Our main idea is that the functional capacity required to use a representation is an important but thus-far neglected aspect of representation quality, which we quantify using explicitness or ease-of-use (E). We illustrate the relevance of our extensions on the MPI3D and Cars3D datasets.
Assaying Out-Of-Distribution Generalization in Transfer Learning
Jul 19, 2022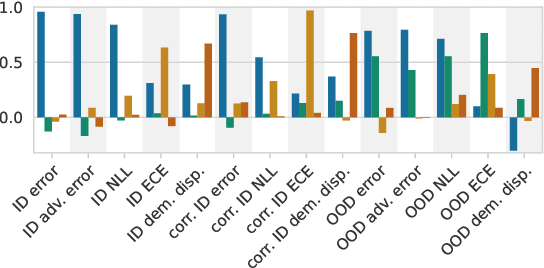
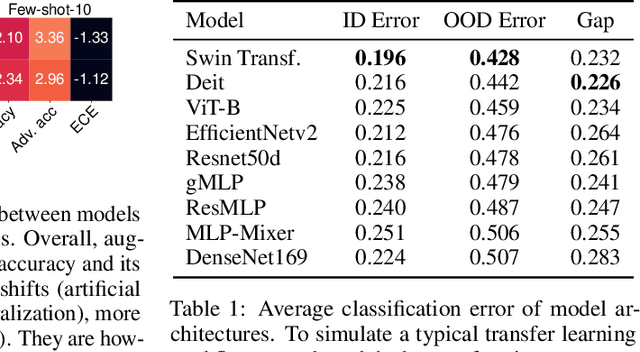
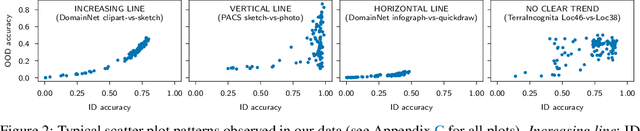
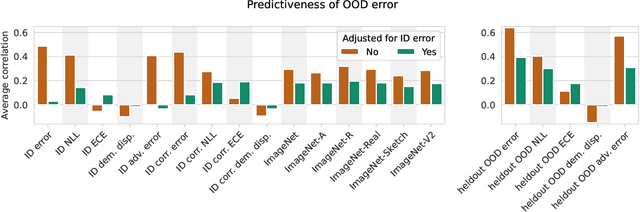
Since out-of-distribution generalization is a generally ill-posed problem, various proxy targets (e.g., calibration, adversarial robustness, algorithmic corruptions, invariance across shifts) were studied across different research programs resulting in different recommendations. While sharing the same aspirational goal, these approaches have never been tested under the same experimental conditions on real data. In this paper, we take a unified view of previous work, highlighting message discrepancies that we address empirically, and providing recommendations on how to measure the robustness of a model and how to improve it. To this end, we collect 172 publicly available dataset pairs for training and out-of-distribution evaluation of accuracy, calibration error, adversarial attacks, environment invariance, and synthetic corruptions. We fine-tune over 31k networks, from nine different architectures in the many- and few-shot setting. Our findings confirm that in- and out-of-distribution accuracies tend to increase jointly, but show that their relation is largely dataset-dependent, and in general more nuanced and more complex than posited by previous, smaller scale studies.
Diffusion Models for Video Prediction and Infilling
Jun 15, 2022



To predict and anticipate future outcomes or reason about missing information in a sequence is a key ability for agents to be able to make intelligent decisions. This requires strong temporally coherent generative capabilities. Diffusion models have shown huge success in several generative tasks lately, but have not been extensively explored in the video domain. We present Random-Mask Video Diffusion (RaMViD), which extends image diffusion models to videos using 3D convolutions, and introduces a new conditioning technique during training. By varying the mask we condition on, the model is able to perform video prediction, infilling and upsampling. Since we do not use concatenation to condition on a mask, as done in most conditionally trained diffusion models, we are able to decrease the memory footprint. We evaluated the model on two benchmark datasets for video prediction and one for video generation on which we achieved competitive results. On Kinetics-600 we achieved state-of-the-art for video prediction.
Inductive Biases for Object-Centric Representations in the Presence of Complex Textures
Apr 26, 2022

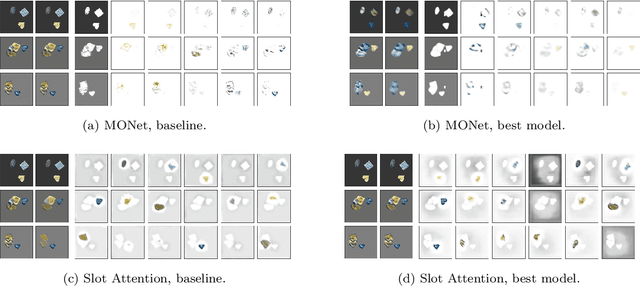
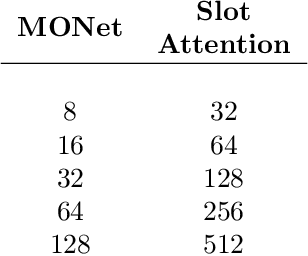
Understanding which inductive biases could be helpful for the unsupervised learning of object-centric representations of natural scenes is challenging. We use neural style transfer to generate datasets where objects have complex textures while still retaining ground-truth annotations. We find that methods that use a single module to reconstruct both the shape and visual appearance of each object learn more useful representations and achieve better object separation. In addition, we observe that adjusting the latent space size is not sufficient to improve segmentation performance. Finally, the downstream usefulness of the representations is significantly more strongly correlated with segmentation quality than with reconstruction accuracy.
Image Super-Resolution With Deep Variational Autoencoders
Mar 17, 2022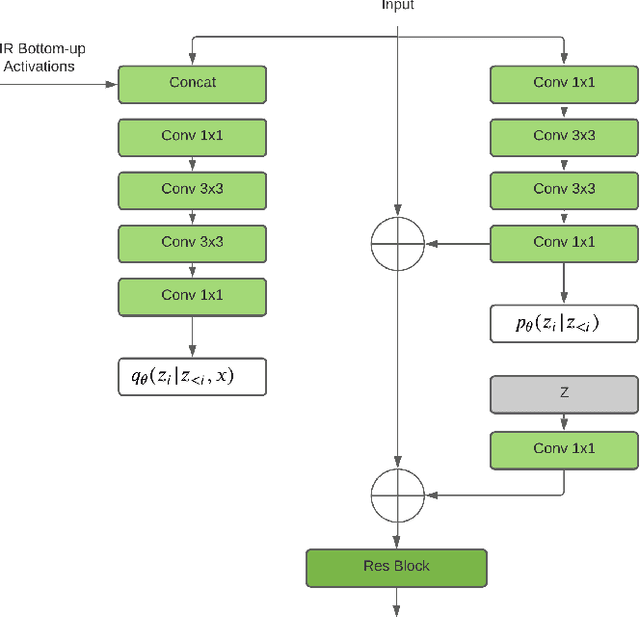
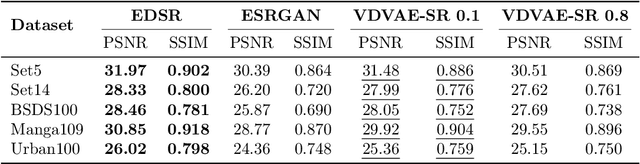
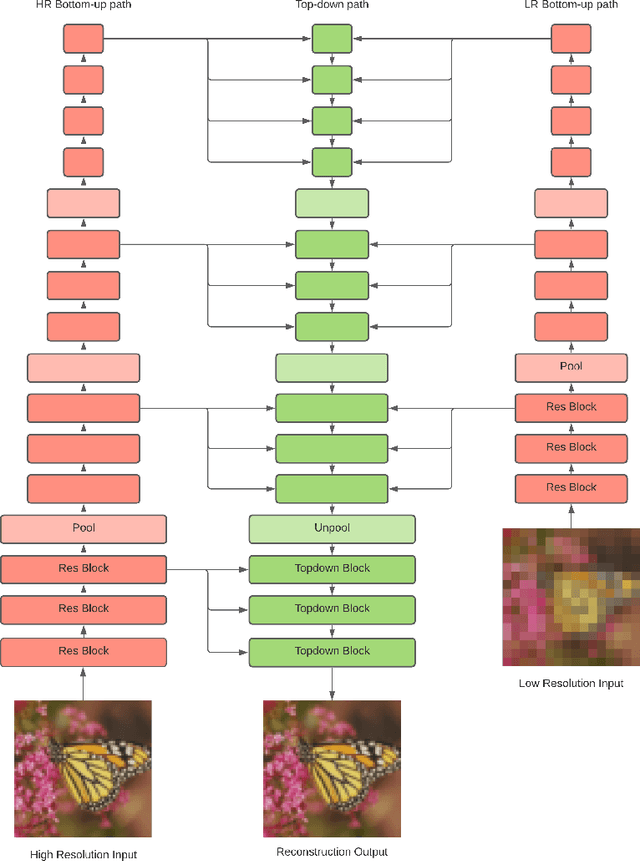
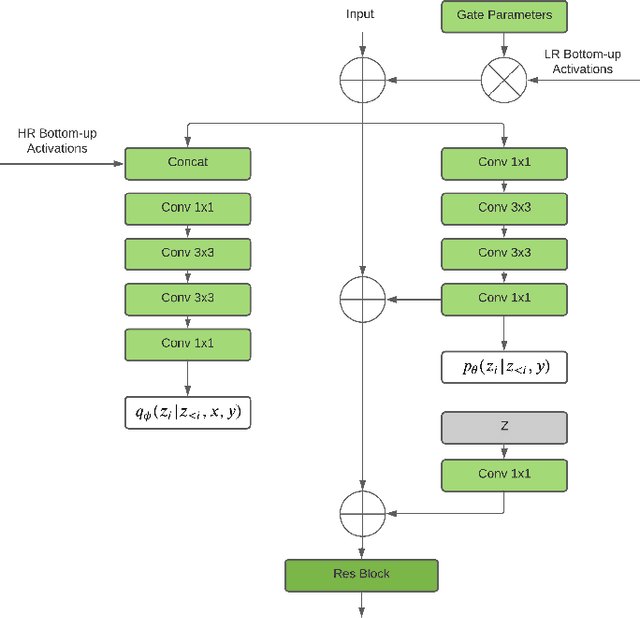
Image super-resolution (SR) techniques are used to generate a high-resolution image from a low-resolution image. Until now, deep generative models such as autoregressive models and Generative Adversarial Networks (GANs) have proven to be effective at modelling high-resolution images. Models based on Variational Autoencoders (VAEs) have often been criticized for their feeble generative performance, but with new advancements such as VDVAE (very deep VAE), there is now strong evidence that deep VAEs have the potential to outperform current state-of-the-art models for high-resolution image generation. In this paper, we introduce VDVAE-SR, a new model that aims to exploit the most recent deep VAE methodologies to improve upon image super-resolution using transfer learning on pretrained VDVAEs. Through qualitative and quantitative evaluations, we show that the proposed model is competitive with other state-of-the-art methods.
Conditional Generation of Medical Time Series for Extrapolation to Underrepresented Populations
Jan 20, 2022
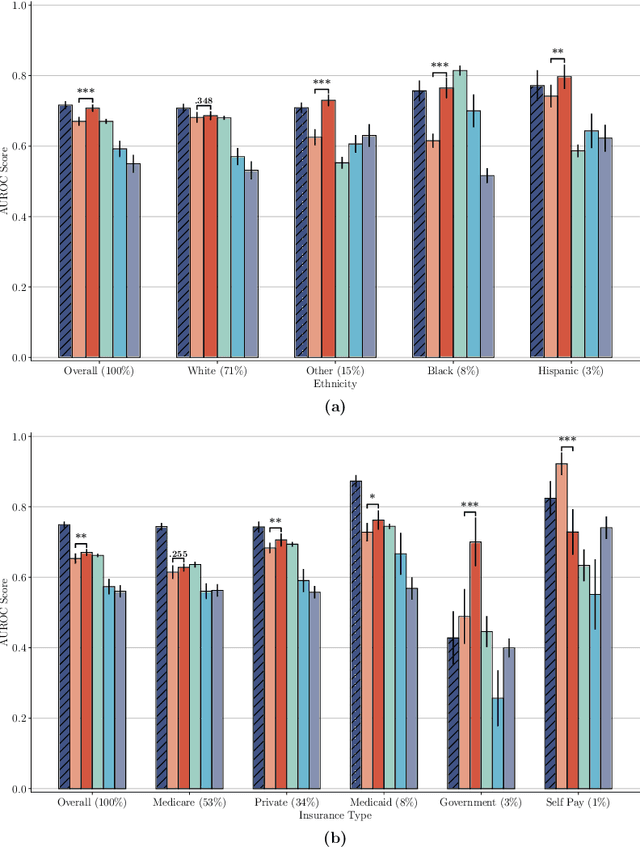
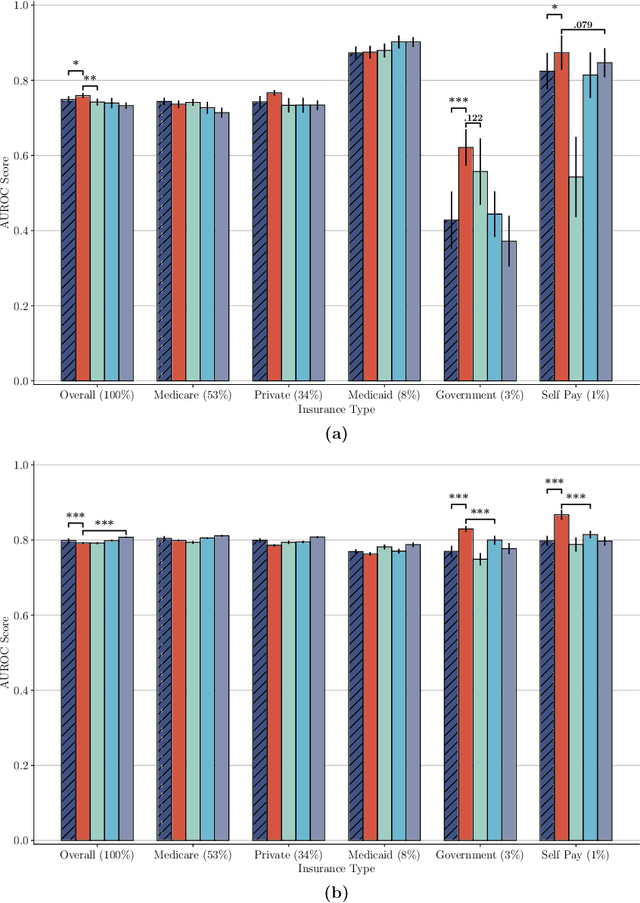
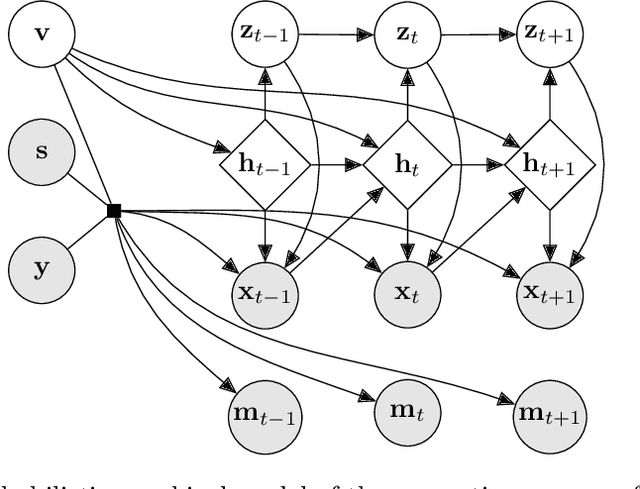
The widespread adoption of electronic health records (EHRs) and subsequent increased availability of longitudinal healthcare data has led to significant advances in our understanding of health and disease with direct and immediate impact on the development of new diagnostics and therapeutic treatment options. However, access to EHRs is often restricted due to their perceived sensitive nature and associated legal concerns, and the cohorts therein typically are those seen at a specific hospital or network of hospitals and therefore not representative of the wider population of patients. Here, we present HealthGen, a new approach for the conditional generation of synthetic EHRs that maintains an accurate representation of real patient characteristics, temporal information and missingness patterns. We demonstrate experimentally that HealthGen generates synthetic cohorts that are significantly more faithful to real patient EHRs than the current state-of-the-art, and that augmenting real data sets with conditionally generated cohorts of underrepresented subpopulations of patients can significantly enhance the generalisability of models derived from these data sets to different patient populations. Synthetic conditionally generated EHRs could help increase the accessibility of longitudinal healthcare data sets and improve the generalisability of inferences made from these data sets to underrepresented populations.