 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeElucidating the Design Space of Flow Matching for Cellular Microscopy
Mar 25, 2026Flow-matching generative models are increasingly used to simulate cell responses to biological perturbations. However, the design space for building such models is large and underexplored. We systematically analyse the design space of flow matching models for cell-microscopy images, finding that many popular techniques are unnecessary and can even hurt performance. We develop a simple, stable, and scalable recipe which we use to train our foundation model. We scale our model to two orders of magnitude larger than prior methods, achieving a two-fold FID and ten-fold KID improvement over prior methods. We then fine-tune our model with pre-trained molecular embeddings to achieve state-of-the-art performance simulating responses to unseen molecules. Code is available at https://github.com/valence-labs/microscopy-flow-matching
TxPert: Leveraging Biochemical Relationships for Out-of-Distribution Transcriptomic Perturbation Prediction
May 20, 2025Accurately predicting cellular responses to genetic perturbations is essential for understanding disease mechanisms and designing effective therapies. Yet exhaustively exploring the space of possible perturbations (e.g., multi-gene perturbations or across tissues and cell types) is prohibitively expensive, motivating methods that can generalize to unseen conditions. In this work, we explore how knowledge graphs of gene-gene relationships can improve out-of-distribution (OOD) prediction across three challenging settings: unseen single perturbations; unseen double perturbations; and unseen cell lines. In particular, we present: (i) TxPert, a new state-of-the-art method that leverages multiple biological knowledge networks to predict transcriptional responses under OOD scenarios; (ii) an in-depth analysis demonstrating the impact of graphs, model architecture, and data on performance; and (iii) an expanded benchmarking framework that strengthens evaluation standards for perturbation modeling.
Towards scientific discovery with dictionary learning: Extracting biological concepts from microscopy foundation models
Dec 20, 2024Dictionary learning (DL) has emerged as a powerful interpretability tool for large language models. By extracting known concepts (e.g., Golden-Gate Bridge) from human-interpretable data (e.g., text), sparse DL can elucidate a model's inner workings. In this work, we ask if DL can also be used to discover unknown concepts from less human-interpretable scientific data (e.g., cell images), ultimately enabling modern approaches to scientific discovery. As a first step, we use DL algorithms to study microscopy foundation models trained on multi-cell image data, where little prior knowledge exists regarding which high-level concepts should arise. We show that sparse dictionaries indeed extract biologically-meaningful concepts such as cell type and genetic perturbation type. We also propose a new DL algorithm, Iterative Codebook Feature Learning~(ICFL), and combine it with a pre-processing step that uses PCA whitening from a control dataset. In our experiments, we demonstrate that both ICFL and PCA improve the selectivity of extracted features compared to TopK sparse autoencoders.
GIVT: Generative Infinite-Vocabulary Transformers
Dec 04, 2023



We introduce generative infinite-vocabulary transformers (GIVT) which generate vector sequences with real-valued entries, instead of discrete tokens from a finite vocabulary. To this end, we propose two surprisingly simple modifications to decoder-only transformers: 1) at the input, we replace the finite-vocabulary lookup table with a linear projection of the input vectors; and 2) at the output, we replace the logits prediction (usually mapped to a categorical distribution) with the parameters of a multivariate Gaussian mixture model. Inspired by the image-generation paradigm of VQ-GAN and MaskGIT, where transformers are used to model the discrete latent sequences of a VQ-VAE, we use GIVT to model the unquantized real-valued latent sequences of a VAE. When applying GIVT to class-conditional image generation with iterative masked modeling, we show competitive results with MaskGIT, while our approach outperforms both VQ-GAN and MaskGIT when using it for causal modeling. Finally, we obtain competitive results outside of image generation when applying our approach to panoptic segmentation and depth estimation with a VAE-based variant of the UViM framework.
Self-Supervised Disentanglement by Leveraging Structure in Data Augmentations
Nov 15, 2023



Self-supervised representation learning often uses data augmentations to induce some invariance to "style" attributes of the data. However, with downstream tasks generally unknown at training time, it is difficult to deduce a priori which attributes of the data are indeed "style" and can be safely discarded. To address this, we introduce a more principled approach that seeks to disentangle style features rather than discard them. The key idea is to add multiple style embedding spaces where: (i) each is invariant to all-but-one augmentation; and (ii) joint entropy is maximized. We formalize our structured data-augmentation procedure from a causal latent-variable-model perspective, and prove identifiability of both content and (multiple blocks of) style variables. We empirically demonstrate the benefits of our approach on synthetic datasets and then present promising but limited results on ImageNet.
Spuriosity Didn't Kill the Classifier: Using Invariant Predictions to Harness Spurious Features
Jul 19, 2023



To avoid failures on out-of-distribution data, recent works have sought to extract features that have a stable or invariant relationship with the label across domains, discarding the "spurious" or unstable features whose relationship with the label changes across domains. However, unstable features often carry complementary information about the label that could boost performance if used correctly in the test domain. Our main contribution is to show that it is possible to learn how to use these unstable features in the test domain without labels. In particular, we prove that pseudo-labels based on stable features provide sufficient guidance for doing so, provided that stable and unstable features are conditionally independent given the label. Based on this theoretical insight, we propose Stable Feature Boosting (SFB), an algorithm for: (i) learning a predictor that separates stable and conditionally-independent unstable features; and (ii) using the stable-feature predictions to adapt the unstable-feature predictions in the test domain. Theoretically, we prove that SFB can learn an asymptotically-optimal predictor without test-domain labels. Empirically, we demonstrate the effectiveness of SFB on real and synthetic data.
DCI-ES: An Extended Disentanglement Framework with Connections to Identifiability
Oct 01, 2022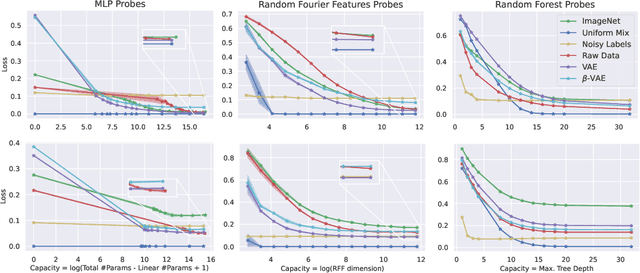
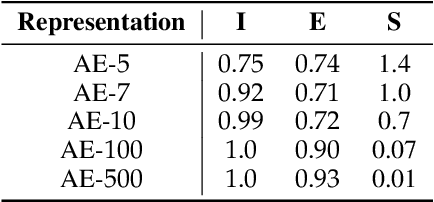
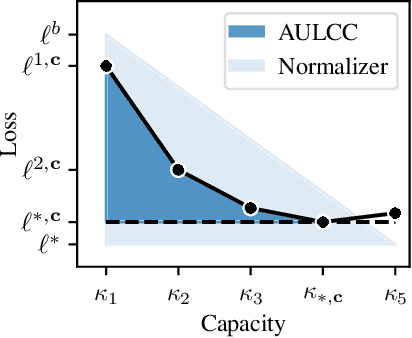
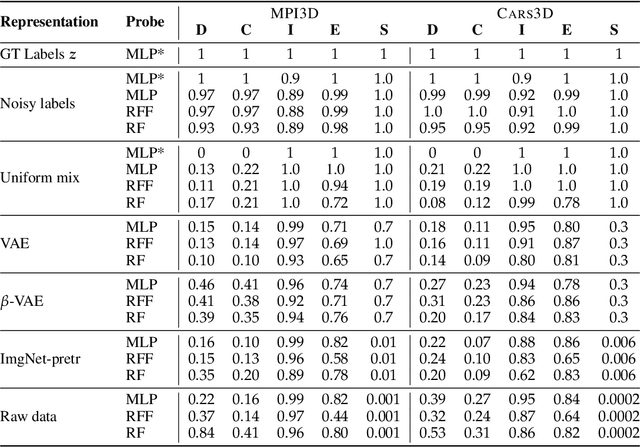
In representation learning, a common approach is to seek representations which disentangle the underlying factors of variation. Eastwood & Williams (2018) proposed three metrics for quantifying the quality of such disentangled representations: disentanglement (D), completeness (C) and informativeness (I). In this work, we first connect this DCI framework to two common notions of linear and nonlinear identifiability, thus establishing a formal link between disentanglement and the closely-related field of independent component analysis. We then propose an extended DCI-ES framework with two new measures of representation quality - explicitness (E) and size (S) - and point out how D and C can be computed for black-box predictors. Our main idea is that the functional capacity required to use a representation is an important but thus-far neglected aspect of representation quality, which we quantify using explicitness or ease-of-use (E). We illustrate the relevance of our extensions on the MPI3D and Cars3D datasets.
Probable Domain Generalization via Quantile Risk Minimization
Jul 20, 2022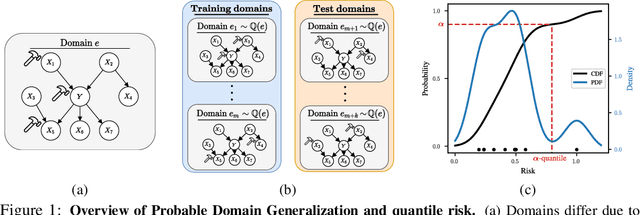
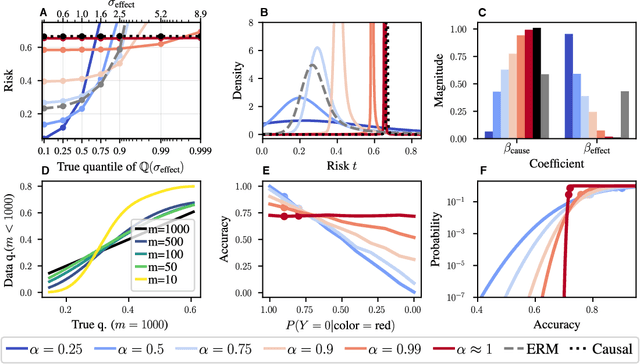
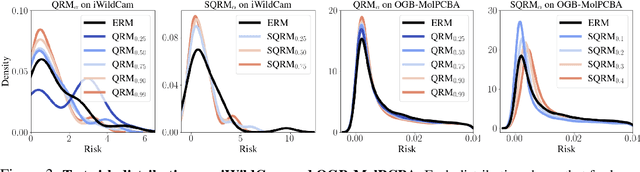
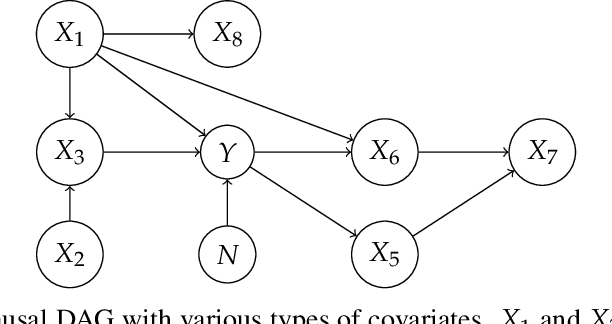
Domain generalization (DG) seeks predictors which perform well on unseen test distributions by leveraging labeled training data from multiple related distributions or domains. To achieve this, the standard formulation optimizes for worst-case performance over the set of all possible domains. However, with worst-case shifts very unlikely in practice, this generally leads to overly-conservative solutions. In fact, a recent study found that no DG algorithm outperformed empirical risk minimization in terms of average performance. In this work, we argue that DG is neither a worst-case problem nor an average-case problem, but rather a probabilistic one. To this end, we propose a probabilistic framework for DG, which we call Probable Domain Generalization, wherein our key idea is that distribution shifts seen during training should inform us of probable shifts at test time. To realize this, we explicitly relate training and test domains as draws from the same underlying meta-distribution, and propose a new optimization problem -- Quantile Risk Minimization (QRM) -- which requires that predictors generalize with high probability. We then prove that QRM: (i) produces predictors that generalize to new domains with a desired probability, given sufficiently many domains and samples; and (ii) recovers the causal predictor as the desired probability of generalization approaches one. In our experiments, we introduce a more holistic quantile-focused evaluation protocol for DG, and show that our algorithms outperform state-of-the-art baselines on real and synthetic data.
Align-Deform-Subtract: An Interventional Framework for Explaining Object Differences
Mar 09, 2022



Given two object images, how can we explain their differences in terms of the underlying object properties? To address this question, we propose Align-Deform-Subtract (ADS) -- an interventional framework for explaining object differences. By leveraging semantic alignments in image-space as counterfactual interventions on the underlying object properties, ADS iteratively quantifies and removes differences in object properties. The result is a set of "disentangled" error measures which explain object differences in terms of their underlying properties. Experiments on real and synthetic data illustrate the efficacy of the framework.
Learning Object-Centric Representations of Multi-Object Scenes from Multiple Views
Nov 13, 2021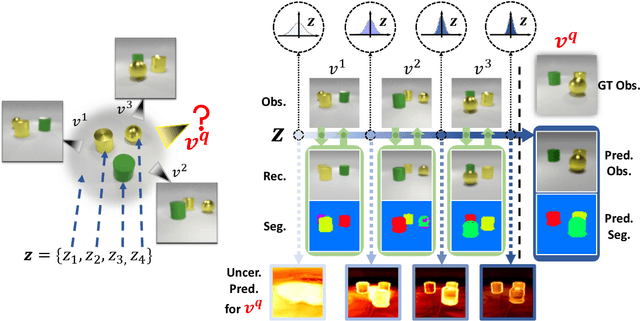
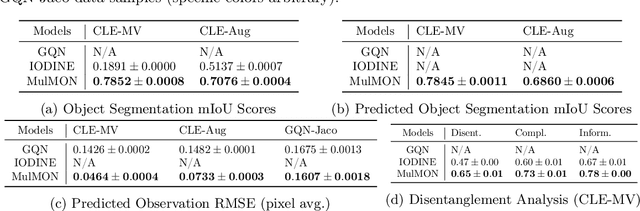
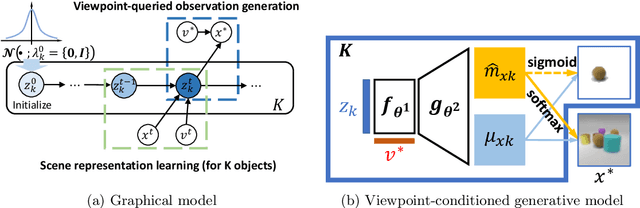

Learning object-centric representations of multi-object scenes is a promising approach towards machine intelligence, facilitating high-level reasoning and control from visual sensory data. However, current approaches for unsupervised object-centric scene representation are incapable of aggregating information from multiple observations of a scene. As a result, these "single-view" methods form their representations of a 3D scene based only on a single 2D observation (view). Naturally, this leads to several inaccuracies, with these methods falling victim to single-view spatial ambiguities. To address this, we propose The Multi-View and Multi-Object Network (MulMON) -- a method for learning accurate, object-centric representations of multi-object scenes by leveraging multiple views. In order to sidestep the main technical difficulty of the multi-object-multi-view scenario -- maintaining object correspondences across views -- MulMON iteratively updates the latent object representations for a scene over multiple views. To ensure that these iterative updates do indeed aggregate spatial information to form a complete 3D scene understanding, MulMON is asked to predict the appearance of the scene from novel viewpoints during training. Through experiments, we show that MulMON better-resolves spatial ambiguities than single-view methods -- learning more accurate and disentangled object representations -- and also achieves new functionality in predicting object segmentations for novel viewpoints.