 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSLAM: A Unified Encoder for Speech and Language Modeling via Speech-Text Joint Pre-Training
Oct 20, 2021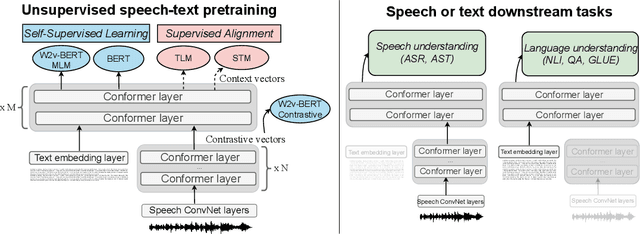
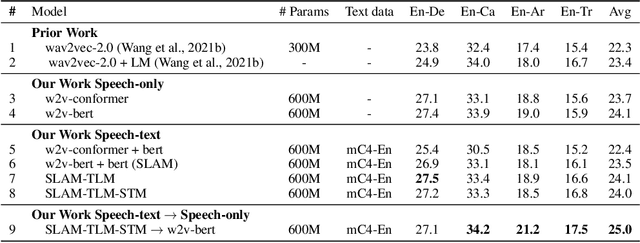
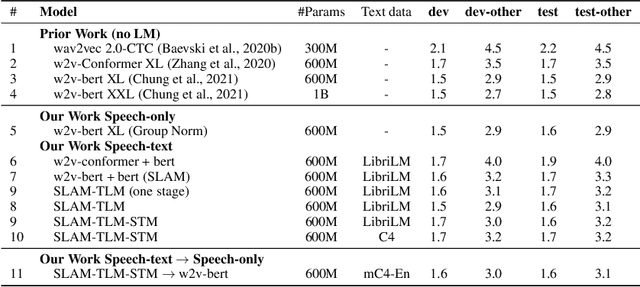
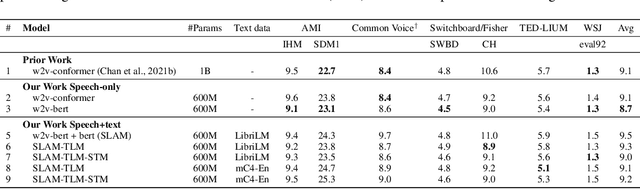
Unsupervised pre-training is now the predominant approach for both text and speech understanding. Self-attention models pre-trained on large amounts of unannotated data have been hugely successful when fine-tuned on downstream tasks from a variety of domains and languages. This paper takes the universality of unsupervised language pre-training one step further, by unifying speech and text pre-training within a single model. We build a single encoder with the BERT objective on unlabeled text together with the w2v-BERT objective on unlabeled speech. To further align our model representations across modalities, we leverage alignment losses, specifically Translation Language Modeling (TLM) and Speech Text Matching (STM) that make use of supervised speech-text recognition data. We demonstrate that incorporating both speech and text data during pre-training can significantly improve downstream quality on CoVoST~2 speech translation, by around 1 BLEU compared to single-modality pre-trained models, while retaining close to SotA performance on LibriSpeech and SpeechStew ASR tasks. On four GLUE tasks and text-normalization, we observe evidence of capacity limitations and interference between the two modalities, leading to degraded performance compared to an equivalent text-only model, while still being competitive with BERT. Through extensive empirical analysis we also demonstrate the importance of the choice of objective function for speech pre-training, and the beneficial effect of adding additional supervised signals on the quality of the learned representations.
Improved Language Identification Through Cross-Lingual Self-Supervised Learning
Aug 04, 2021
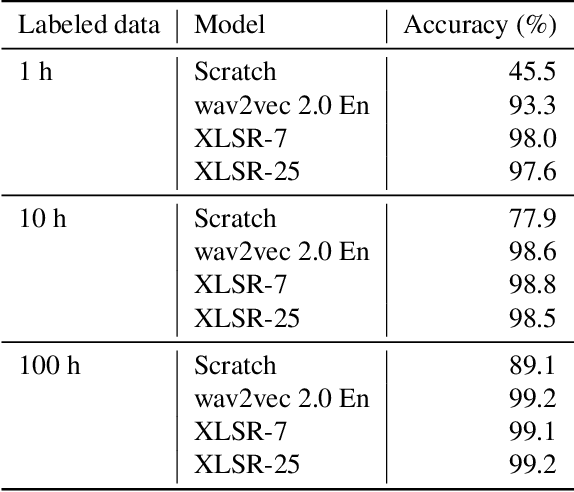
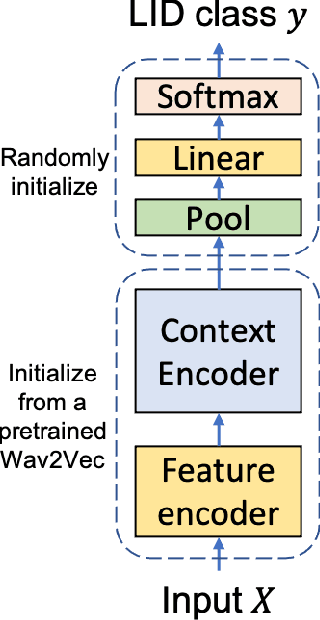
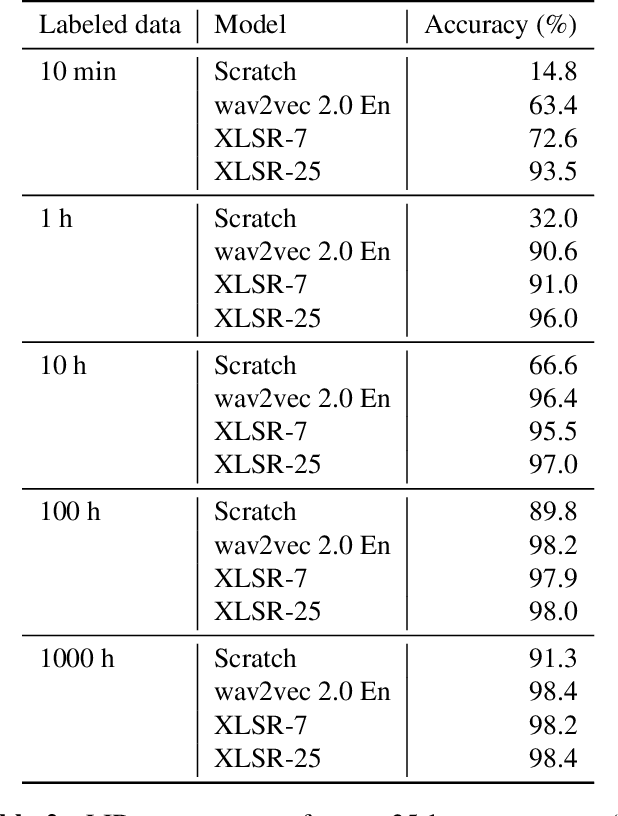
Language identification greatly impacts the success of downstream tasks such as automatic speech recognition. Recently, self-supervised speech representations learned by wav2vec 2.0 have been shown to be very effective for a range of speech tasks. We extend previous self-supervised work on language identification by experimenting with pre-trained models which were learned on real-world unconstrained speech in multiple languages and not just on English. We show that models pre-trained on many languages perform better and enable language identification systems that require very little labeled data to perform well. Results on a 25 languages setup show that with only 10 minutes of labeled data per language, a cross-lingually pre-trained model can achieve over 93% accuracy.
Unsupervised Speech Recognition
May 24, 2021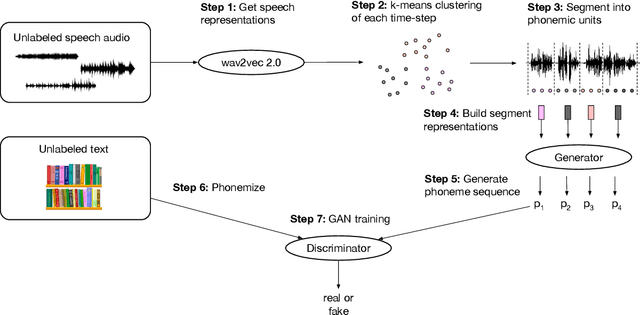

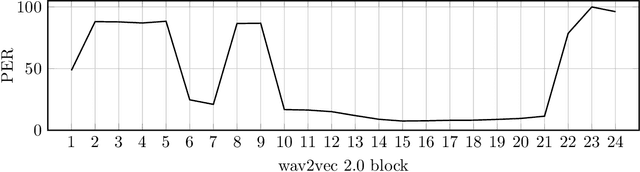
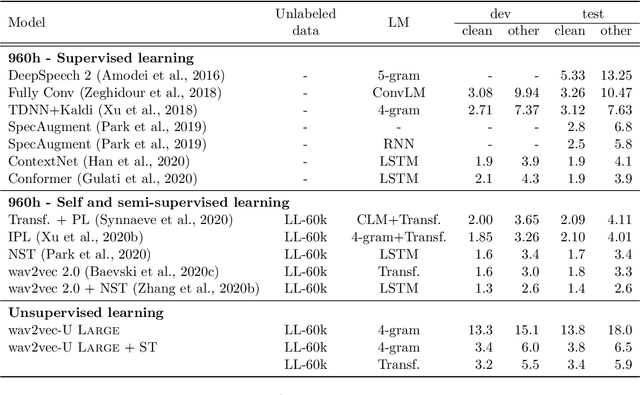
Despite rapid progress in the recent past, current speech recognition systems still require labeled training data which limits this technology to a small fraction of the languages spoken around the globe. This paper describes wav2vec-U, short for wav2vec Unsupervised, a method to train speech recognition models without any labeled data. We leverage self-supervised speech representations to segment unlabeled audio and learn a mapping from these representations to phonemes via adversarial training. The right representations are key to the success of our method. Compared to the best previous unsupervised work, wav2vec-U reduces the phoneme error rate on the TIMIT benchmark from 26.1 to 11.3. On the larger English Librispeech benchmark, wav2vec-U achieves a word error rate of 5.9 on test-other, rivaling some of the best published systems trained on 960 hours of labeled data from only two years ago. We also experiment on nine other languages, including low-resource languages such as Kyrgyz, Swahili and Tatar.
Larger-Scale Transformers for Multilingual Masked Language Modeling
May 02, 2021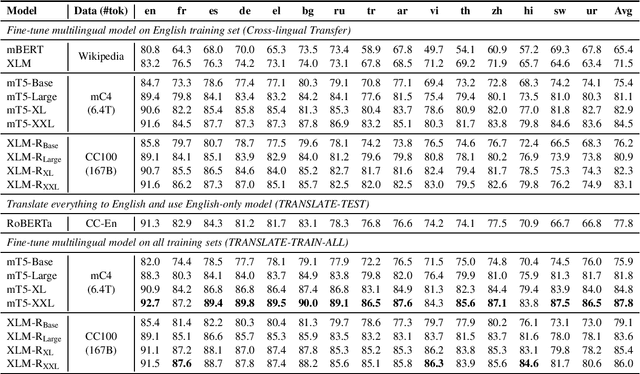
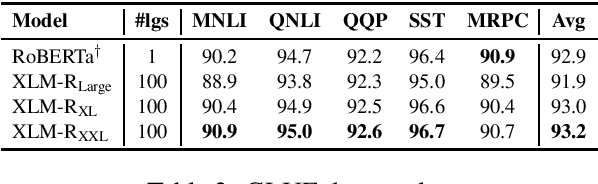

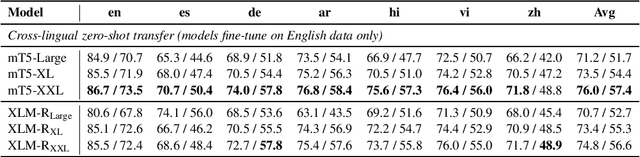
Recent work has demonstrated the effectiveness of cross-lingual language model pretraining for cross-lingual understanding. In this study, we present the results of two larger multilingual masked language models, with 3.5B and 10.7B parameters. Our two new models dubbed XLM-R XL and XLM-R XXL outperform XLM-R by 1.8% and 2.4% average accuracy on XNLI. Our model also outperforms the RoBERTa-Large model on several English tasks of the GLUE benchmark by 0.3% on average while handling 99 more languages. This suggests pretrained models with larger capacity may obtain both strong performance on high-resource languages while greatly improving low-resource languages. We make our code and models publicly available.
Large-Scale Self- and Semi-Supervised Learning for Speech Translation
Apr 14, 2021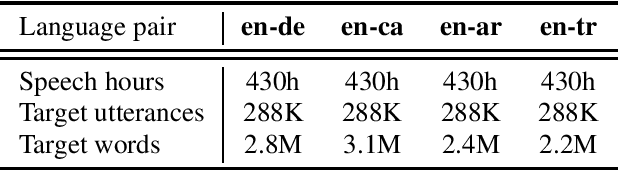
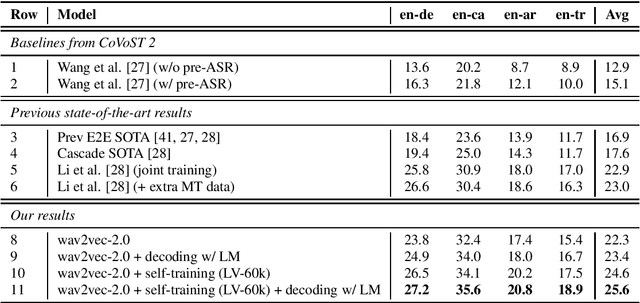

In this paper, we improve speech translation (ST) through effectively leveraging large quantities of unlabeled speech and text data in different and complementary ways. We explore both pretraining and self-training by using the large Libri-Light speech audio corpus and language modeling with CommonCrawl. Our experiments improve over the previous state of the art by 2.6 BLEU on average on all four considered CoVoST 2 language pairs via a simple recipe of combining wav2vec 2.0 pretraining, a single iteration of self-training and decoding with a language model. Different to existing work, our approach does not leverage any other supervision than ST data. Code and models will be publicly released.
Supervised Contrastive Learning for Pre-trained Language Model Fine-tuning
Nov 12, 2020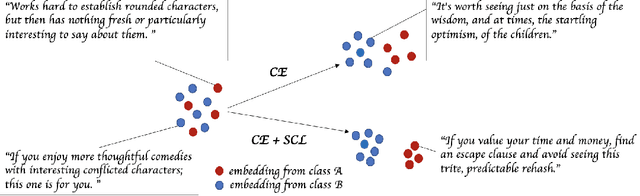


State-of-the-art natural language understanding classification models follow two-stages: pre-training a large language model on an auxiliary task, and then fine-tuning the model on a task-specific labeled dataset using cross-entropy loss. Cross-entropy loss has several shortcomings that can lead to sub-optimal generalization and instability. Driven by the intuition that good generalization requires capturing the similarity between examples in one class and contrasting them with examples in other classes, we propose a supervised contrastive learning (SCL) objective for the fine-tuning stage. Combined with cross-entropy, the SCL loss we propose obtains improvements over a strong RoBERTa-Large baseline on multiple datasets of the GLUE benchmark in both the high-data and low-data regimes, and it does not require any specialized architecture, data augmentation of any kind, memory banks, or additional unsupervised data. We also demonstrate that the new objective leads to models that are more robust to different levels of noise in the training data, and can generalize better to related tasks with limited labeled task data.
Self-training and Pre-training are Complementary for Speech Recognition
Oct 22, 2020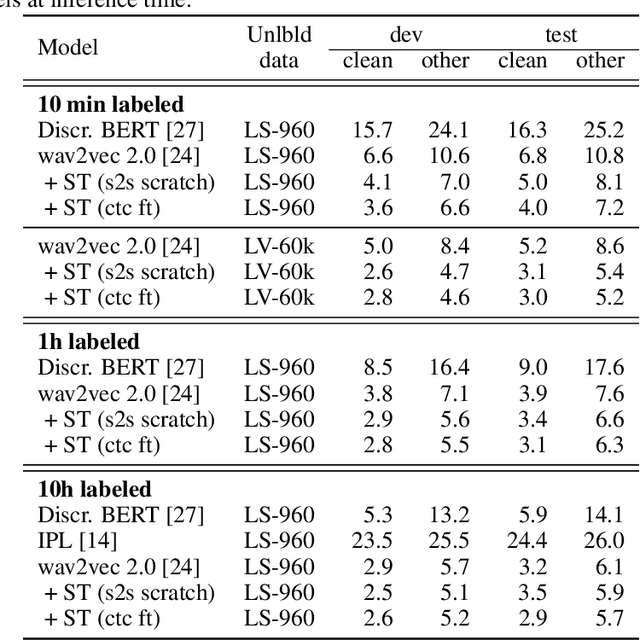
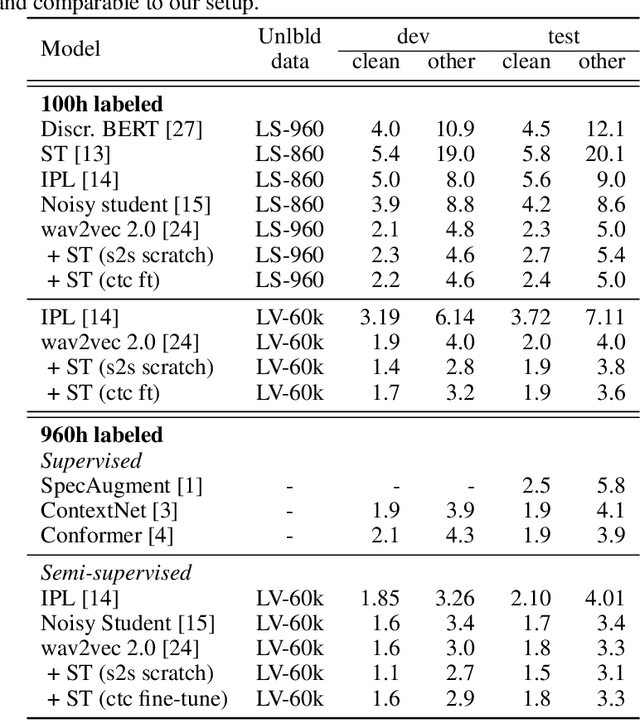
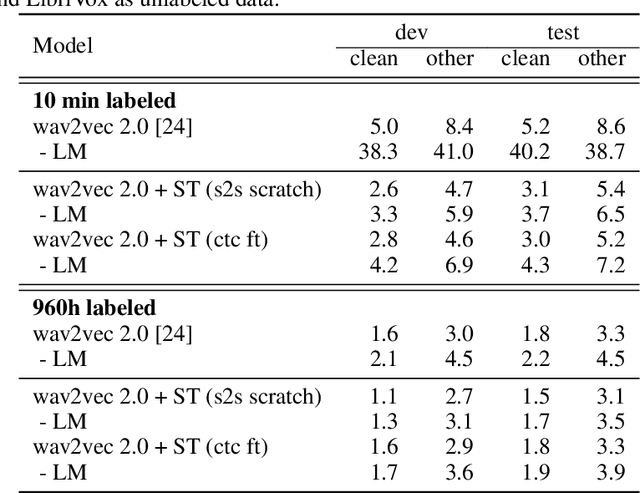
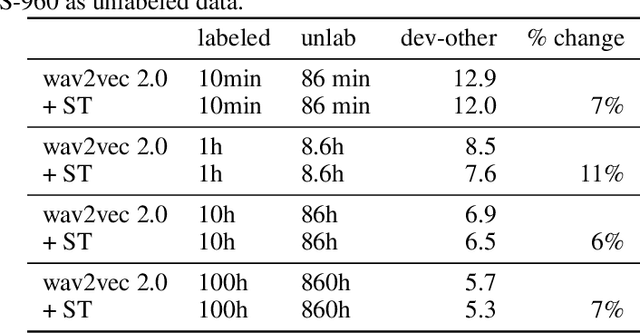
Self-training and unsupervised pre-training have emerged as effective approaches to improve speech recognition systems using unlabeled data. However, it is not clear whether they learn similar patterns or if they can be effectively combined. In this paper, we show that pseudo-labeling and pre-training with wav2vec 2.0 are complementary in a variety of labeled data setups. Using just 10 minutes of labeled data from Libri-light as well as 53k hours of unlabeled data from LibriVox achieves WERs of 3.0%/5.2% on the clean and other test sets of Librispeech - rivaling the best published systems trained on 960 hours of labeled data only a year ago. Training on all labeled data of Librispeech achieves WERs of 1.5%/3.1%.
Self-training Improves Pre-training for Natural Language Understanding
Oct 05, 2020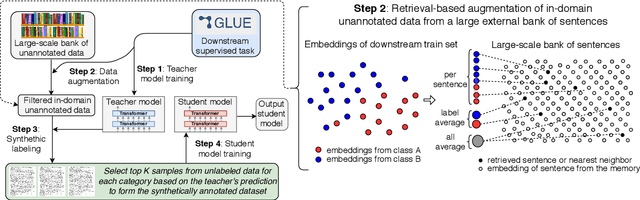
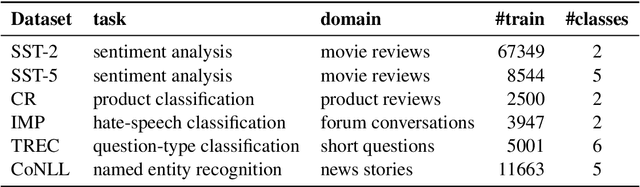
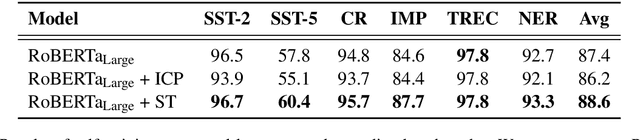

Unsupervised pre-training has led to much recent progress in natural language understanding. In this paper, we study self-training as another way to leverage unlabeled data through semi-supervised learning. To obtain additional data for a specific task, we introduce SentAugment, a data augmentation method which computes task-specific query embeddings from labeled data to retrieve sentences from a bank of billions of unlabeled sentences crawled from the web. Unlike previous semi-supervised methods, our approach does not require in-domain unlabeled data and is therefore more generally applicable. Experiments show that self-training is complementary to strong RoBERTa baselines on a variety of tasks. Our augmentation approach leads to scalable and effective self-training with improvements of up to 2.6% on standard text classification benchmarks. Finally, we also show strong gains on knowledge-distillation and few-shot learning.
Unsupervised Cross-lingual Representation Learning for Speech Recognition
Jun 24, 2020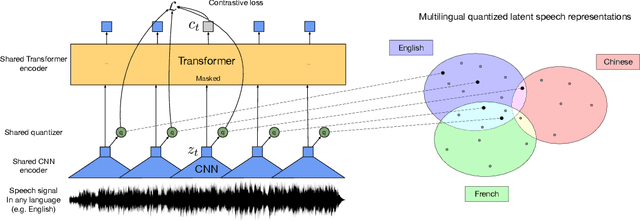
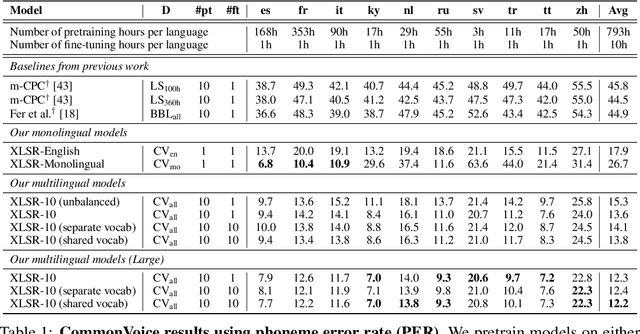
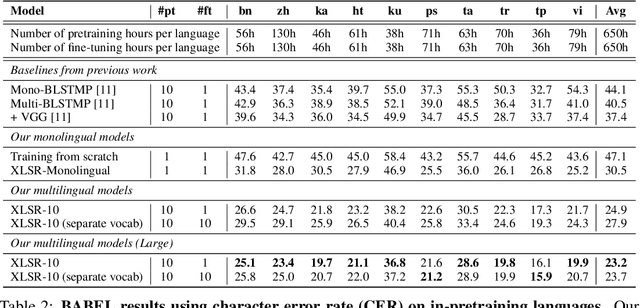
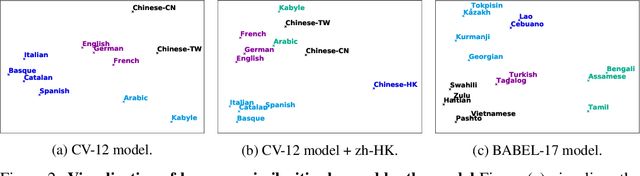
This paper presents XLSR which learns cross-lingual speech representations by pretraining a single model from the raw waveform of speech in multiple languages. We build on a concurrently introduced self-supervised model which is trained by solving a contrastive task over masked latent speech representations and jointly learns a quantization of the latents shared across languages. The resulting model is fine-tuned on labeled data and experiments show that cross-lingual pretraining significantly outperforms monolingual pretraining. On the CommonVoice benchmark, XLSR shows a relative phoneme error rate reduction of 72% compared to the best known results. On BABEL, our approach improves word error rate by 16% relative compared to the strongest comparable system. Our approach enables a single multilingual speech recognition model which is competitive to strong individual models. Analysis shows that the latent discrete speech representations are shared across languages with increased sharing for related languages.
CCNet: Extracting High Quality Monolingual Datasets from Web Crawl Data
Nov 15, 2019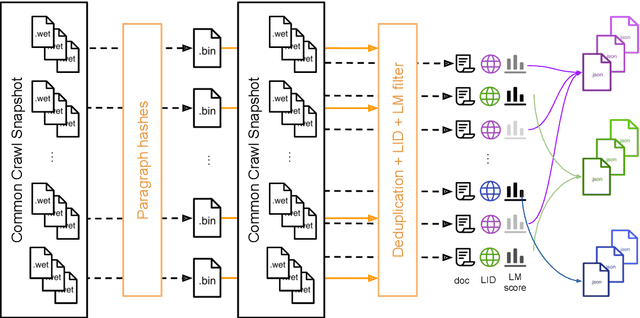
Pre-training text representations have led to significant improvements in many areas of natural language processing. The quality of these models benefits greatly from the size of the pretraining corpora as long as its quality is preserved. In this paper, we describe an automatic pipeline to extract massive high-quality monolingual datasets from Common Crawl for a variety of languages. Our pipeline follows the data processing introduced in fastText (Mikolov et al., 2017; Grave et al., 2018), that deduplicates documents and identifies their language. We augment this pipeline with a filtering step to select documents that are close to high quality corpora like Wikipedia.