 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeJailbreakBench: An Open Robustness Benchmark for Jailbreaking Large Language Models
Mar 28, 2024



Jailbreak attacks cause large language models (LLMs) to generate harmful, unethical, or otherwise objectionable content. Evaluating these attacks presents a number of challenges, which the current collection of benchmarks and evaluation techniques do not adequately address. First, there is no clear standard of practice regarding jailbreaking evaluation. Second, existing works compute costs and success rates in incomparable ways. And third, numerous works are not reproducible, as they withhold adversarial prompts, involve closed-source code, or rely on evolving proprietary APIs. To address these challenges, we introduce JailbreakBench, an open-sourced benchmark with the following components: (1) a new jailbreaking dataset containing 100 unique behaviors, which we call JBB-Behaviors; (2) an evolving repository of state-of-the-art adversarial prompts, which we refer to as jailbreak artifacts; (3) a standardized evaluation framework that includes a clearly defined threat model, system prompts, chat templates, and scoring functions; and (4) a leaderboard that tracks the performance of attacks and defenses for various LLMs. We have carefully considered the potential ethical implications of releasing this benchmark, and believe that it will be a net positive for the community. Over time, we will expand and adapt the benchmark to reflect technical and methodological advances in the research community.
A Safe Harbor for AI Evaluation and Red Teaming
Mar 07, 2024



Independent evaluation and red teaming are critical for identifying the risks posed by generative AI systems. However, the terms of service and enforcement strategies used by prominent AI companies to deter model misuse have disincentives on good faith safety evaluations. This causes some researchers to fear that conducting such research or releasing their findings will result in account suspensions or legal reprisal. Although some companies offer researcher access programs, they are an inadequate substitute for independent research access, as they have limited community representation, receive inadequate funding, and lack independence from corporate incentives. We propose that major AI developers commit to providing a legal and technical safe harbor, indemnifying public interest safety research and protecting it from the threat of account suspensions or legal reprisal. These proposals emerged from our collective experience conducting safety, privacy, and trustworthiness research on generative AI systems, where norms and incentives could be better aligned with public interests, without exacerbating model misuse. We believe these commitments are a necessary step towards more inclusive and unimpeded community efforts to tackle the risks of generative AI.
Defending Large Language Models against Jailbreak Attacks via Semantic Smoothing
Feb 28, 2024



Aligned large language models (LLMs) are vulnerable to jailbreaking attacks, which bypass the safeguards of targeted LLMs and fool them into generating objectionable content. While initial defenses show promise against token-based threat models, there do not exist defenses that provide robustness against semantic attacks and avoid unfavorable trade-offs between robustness and nominal performance. To meet this need, we propose SEMANTICSMOOTH, a smoothing-based defense that aggregates the predictions of multiple semantically transformed copies of a given input prompt. Experimental results demonstrate that SEMANTICSMOOTH achieves state-of-the-art robustness against GCG, PAIR, and AutoDAN attacks while maintaining strong nominal performance on instruction following benchmarks such as InstructionFollowing and AlpacaEval. The codes will be publicly available at https://github.com/UCSB-NLP-Chang/SemanticSmooth.
Data-Driven Modeling and Verification of Perception-Based Autonomous Systems
Dec 11, 2023This paper addresses the problem of data-driven modeling and verification of perception-based autonomous systems. We assume the perception model can be decomposed into a canonical model (obtained from first principles or a simulator) and a noise model that contains the measurement noise introduced by the real environment. We focus on two types of noise, benign and adversarial noise, and develop a data-driven model for each type using generative models and classifiers, respectively. We show that the trained models perform well according to a variety of evaluation metrics based on downstream tasks such as state estimation and control. Finally, we verify the safety of two systems with high-dimensional data-driven models, namely an image-based version of mountain car (a reinforcement learning benchmark) as well as the F1/10 car, which uses LiDAR measurements to navigate a racing track.
Jailbreaking Black Box Large Language Models in Twenty Queries
Oct 13, 2023



There is growing interest in ensuring that large language models (LLMs) align with human values. However, the alignment of such models is vulnerable to adversarial jailbreaks, which coax LLMs into overriding their safety guardrails. The identification of these vulnerabilities is therefore instrumental in understanding inherent weaknesses and preventing future misuse. To this end, we propose Prompt Automatic Iterative Refinement (PAIR), an algorithm that generates semantic jailbreaks with only black-box access to an LLM. PAIR -- which is inspired by social engineering attacks -- uses an attacker LLM to automatically generate jailbreaks for a separate targeted LLM without human intervention. In this way, the attacker LLM iteratively queries the target LLM to update and refine a candidate jailbreak. Empirically, PAIR often requires fewer than twenty queries to produce a jailbreak, which is orders of magnitude more efficient than existing algorithms. PAIR also achieves competitive jailbreaking success rates and transferability on open and closed-source LLMs, including GPT-3.5/4, Vicuna, and PaLM-2.
SmoothLLM: Defending Large Language Models Against Jailbreaking Attacks
Oct 13, 2023



Despite efforts to align large language models (LLMs) with human values, widely-used LLMs such as GPT, Llama, Claude, and PaLM are susceptible to jailbreaking attacks, wherein an adversary fools a targeted LLM into generating objectionable content. To address this vulnerability, we propose SmoothLLM, the first algorithm designed to mitigate jailbreaking attacks on LLMs. Based on our finding that adversarially-generated prompts are brittle to character-level changes, our defense first randomly perturbs multiple copies of a given input prompt, and then aggregates the corresponding predictions to detect adversarial inputs. SmoothLLM reduces the attack success rate on numerous popular LLMs to below one percentage point, avoids unnecessary conservatism, and admits provable guarantees on attack mitigation. Moreover, our defense uses exponentially fewer queries than existing attacks and is compatible with any LLM.
Adversarial Training Should Be Cast as a Non-Zero-Sum Game
Jun 19, 2023One prominent approach toward resolving the adversarial vulnerability of deep neural networks is the two-player zero-sum paradigm of adversarial training, in which predictors are trained against adversarially-chosen perturbations of data. Despite the promise of this approach, algorithms based on this paradigm have not engendered sufficient levels of robustness, and suffer from pathological behavior like robust overfitting. To understand this shortcoming, we first show that the commonly used surrogate-based relaxation used in adversarial training algorithms voids all guarantees on the robustness of trained classifiers. The identification of this pitfall informs a novel non-zero-sum bilevel formulation of adversarial training, wherein each player optimizes a different objective function. Our formulation naturally yields a simple algorithmic framework that matches and in some cases outperforms state-of-the-art attacks, attains comparable levels of robustness to standard adversarial training algorithms, and does not suffer from robust overfitting.
Probable Domain Generalization via Quantile Risk Minimization
Jul 20, 2022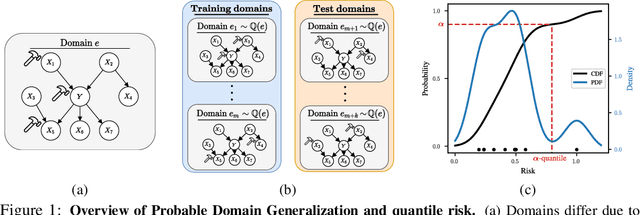
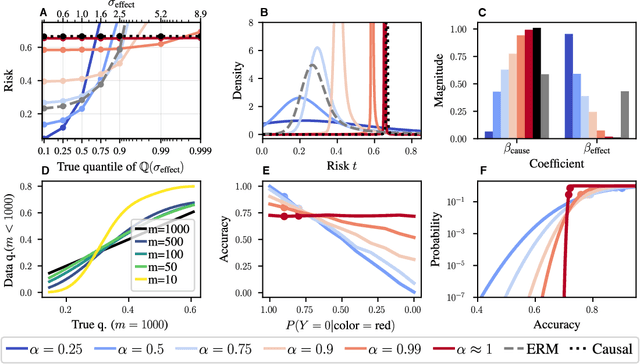
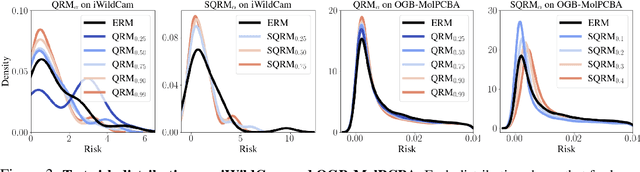
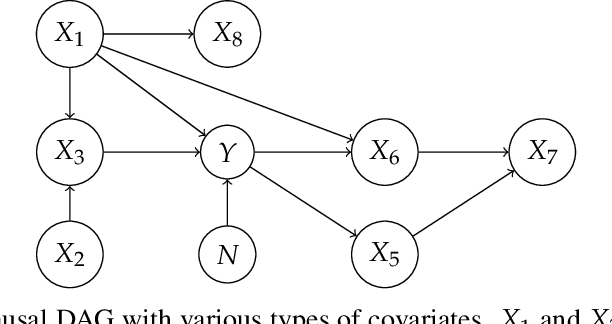
Domain generalization (DG) seeks predictors which perform well on unseen test distributions by leveraging labeled training data from multiple related distributions or domains. To achieve this, the standard formulation optimizes for worst-case performance over the set of all possible domains. However, with worst-case shifts very unlikely in practice, this generally leads to overly-conservative solutions. In fact, a recent study found that no DG algorithm outperformed empirical risk minimization in terms of average performance. In this work, we argue that DG is neither a worst-case problem nor an average-case problem, but rather a probabilistic one. To this end, we propose a probabilistic framework for DG, which we call Probable Domain Generalization, wherein our key idea is that distribution shifts seen during training should inform us of probable shifts at test time. To realize this, we explicitly relate training and test domains as draws from the same underlying meta-distribution, and propose a new optimization problem -- Quantile Risk Minimization (QRM) -- which requires that predictors generalize with high probability. We then prove that QRM: (i) produces predictors that generalize to new domains with a desired probability, given sufficiently many domains and samples; and (ii) recovers the causal predictor as the desired probability of generalization approaches one. In our experiments, we introduce a more holistic quantile-focused evaluation protocol for DG, and show that our algorithms outperform state-of-the-art baselines on real and synthetic data.
Toward Certified Robustness Against Real-World Distribution Shifts
Jun 09, 2022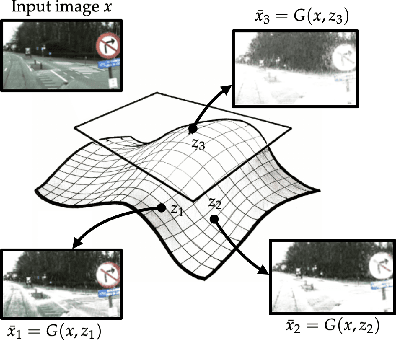
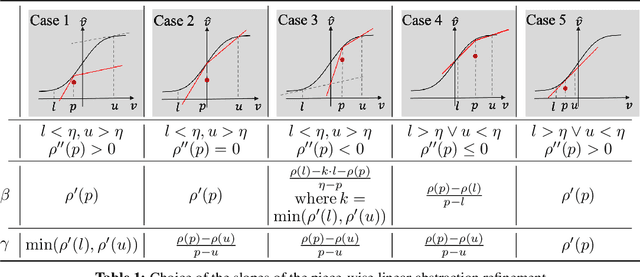
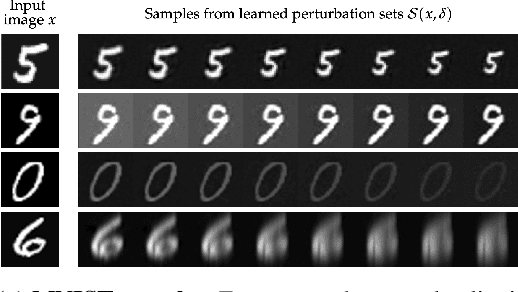
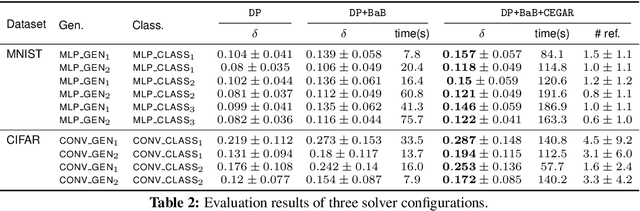
We consider the problem of certifying the robustness of deep neural networks against real-world distribution shifts. To do so, we bridge the gap between hand-crafted specifications and realistic deployment settings by proposing a novel neural-symbolic verification framework, in which we train a generative model to learn perturbations from data and define specifications with respect to the output of the learned model. A unique challenge arising from this setting is that existing verifiers cannot tightly approximate sigmoid activations, which are fundamental to many state-of-the-art generative models. To address this challenge, we propose a general meta-algorithm for handling sigmoid activations which leverages classical notions of counter-example-guided abstraction refinement. The key idea is to "lazily" refine the abstraction of sigmoid functions to exclude spurious counter-examples found in the previous abstraction, thus guaranteeing progress in the verification process while keeping the state-space small. Experiments on the MNIST and CIFAR-10 datasets show that our framework significantly outperforms existing methods on a range of challenging distribution shifts.
Chordal Sparsity for Lipschitz Constant Estimation of Deep Neural Networks
Apr 02, 2022
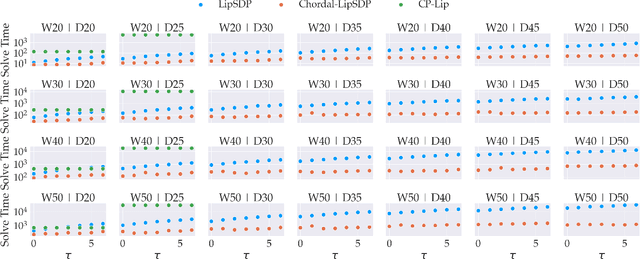
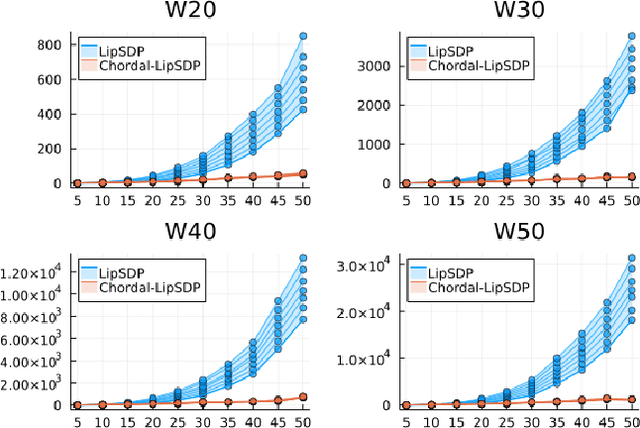
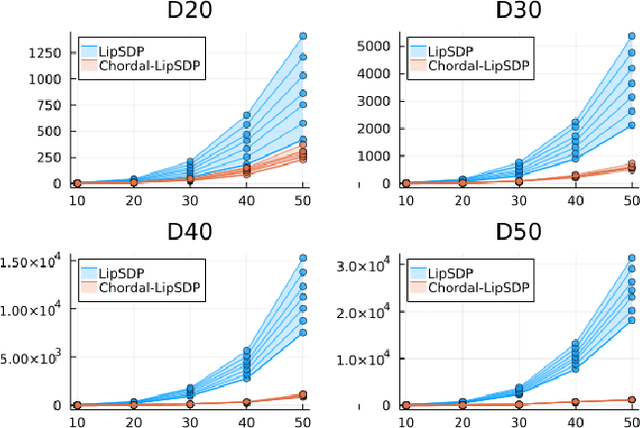
Lipschitz constants of neural networks allow for guarantees of robustness in image classification, safety in controller design, and generalizability beyond the training data. As calculating Lipschitz constants is NP-hard, techniques for estimating Lipschitz constants must navigate the trade-off between scalability and accuracy. In this work, we significantly push the scalability frontier of a semidefinite programming technique known as LipSDP while achieving zero accuracy loss. We first show that LipSDP has chordal sparsity, which allows us to derive a chordally sparse formulation that we call Chordal-LipSDP. The key benefit is that the main computational bottleneck of LipSDP, a large semidefinite constraint, is now decomposed into an equivalent collection of smaller ones: allowing Chordal-LipSDP to outperform LipSDP particularly as the network depth grows. Moreover, our formulation uses a tunable sparsity parameter that enables one to gain tighter estimates without incurring a significant computational cost. We illustrate the scalability of our approach through extensive numerical experiments.