 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeI2CANSAY:Inter-Class Analogical Augmentation and Intra-Class Significance Analysis for Non-Exemplar Online Task-Free Continual Learning
Apr 21, 2024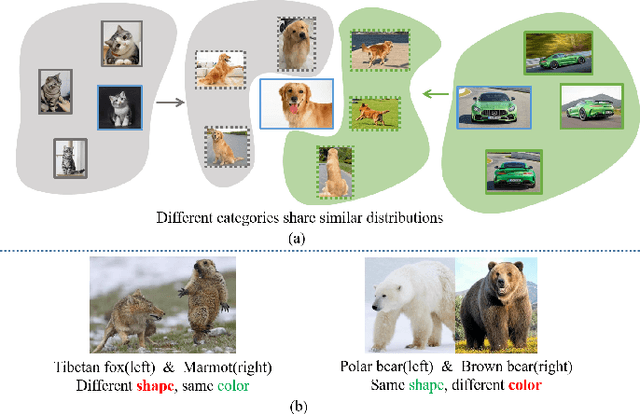
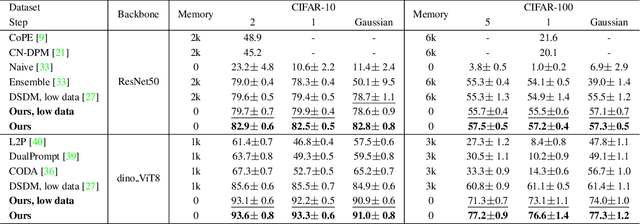
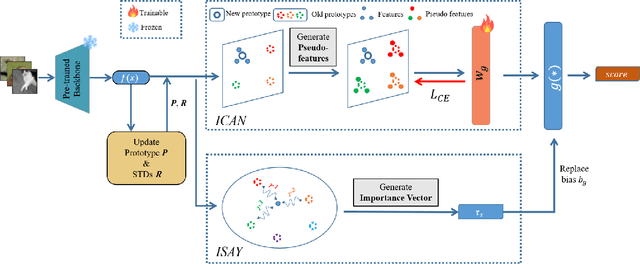
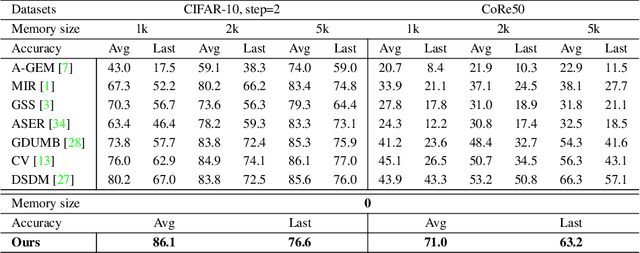
Online task-free continual learning (OTFCL) is a more challenging variant of continual learning which emphasizes the gradual shift of task boundaries and learns in an online mode. Existing methods rely on a memory buffer composed of old samples to prevent forgetting. However,the use of memory buffers not only raises privacy concerns but also hinders the efficient learning of new samples. To address this problem, we propose a novel framework called I2CANSAY that gets rid of the dependence on memory buffers and efficiently learns the knowledge of new data from one-shot samples. Concretely, our framework comprises two main modules. Firstly, the Inter-Class Analogical Augmentation (ICAN) module generates diverse pseudo-features for old classes based on the inter-class analogy of feature distributions for different new classes, serving as a substitute for the memory buffer. Secondly, the Intra-Class Significance Analysis (ISAY) module analyzes the significance of attributes for each class via its distribution standard deviation, and generates the importance vector as a correction bias for the linear classifier, thereby enhancing the capability of learning from new samples. We run our experiments on four popular image classification datasets: CoRe50, CIFAR-10, CIFAR-100, and CUB-200, our approach outperforms the prior state-of-the-art by a large margin.
MoE-FFD: Mixture of Experts for Generalized and Parameter-Efficient Face Forgery Detection
Apr 12, 2024Deepfakes have recently raised significant trust issues and security concerns among the public. Compared to CNN face forgery detectors, ViT-based methods take advantage of the expressivity of transformers, achieving superior detection performance. However, these approaches still exhibit the following limitations: (1). Fully fine-tuning ViT-based models from ImageNet weights demands substantial computational and storage resources; (2). ViT-based methods struggle to capture local forgery clues, leading to model bias and limited generalizability. To tackle these challenges, this work introduces Mixture-of-Experts modules for Face Forgery Detection (MoE-FFD), a generalized yet parameter-efficient ViT-based approach. MoE-FFD only updates lightweight Low-Rank Adaptation (LoRA) and Adapter layers while keeping the ViT backbone frozen, thereby achieving parameter-efficient training. Moreover, MoE-FFD leverages the expressivity of transformers and local priors of CNNs to simultaneously extract global and local forgery clues. Additionally, novel MoE modules are designed to scale the model's capacity and select optimal forgery experts, further enhancing forgery detection performance. The proposed MoE learning scheme can be seamlessly adapted to various transformer backbones in a plug-and-play manner. Extensive experimental results demonstrate that the proposed method achieves state-of-the-art face forgery detection performance with reduced parameter overhead. The code will be released upon acceptance.
Cross-Domain Few-Shot Segmentation via Iterative Support-Query Correspondence Mining
Jan 16, 2024



Cross-Domain Few-Shot Segmentation (CD-FSS) poses the challenge of segmenting novel categories from a distinct domain using only limited exemplars. In this paper, we undertake a comprehensive study of CD-FSS and uncover two crucial insights: (i) the necessity of a fine-tuning stage to effectively transfer the learned meta-knowledge across domains, and (ii) the overfitting risk during the na\"ive fine-tuning due to the scarcity of novel category examples. With these insights, we propose a novel cross-domain fine-tuning strategy that addresses the challenging CD-FSS tasks. We first design Bi-directional Few-shot Prediction (BFP), which establishes support-query correspondence in a bi-directional manner, crafting augmented supervision to reduce the overfitting risk. Then we further extend BFP into Iterative Few-shot Adaptor (IFA), which is a recursive framework to capture the support-query correspondence iteratively, targeting maximal exploitation of supervisory signals from the sparse novel category samples. Extensive empirical evaluations show that our method significantly outperforms the state-of-the-arts (+7.8\%), which verifies that IFA tackles the cross-domain challenges and mitigates the overfitting simultaneously. Code will be made available.
Diffusion-EXR: Controllable Review Generation for Explainable Recommendation via Diffusion Models
Dec 24, 2023



Denoising Diffusion Probabilistic Model (DDPM) has shown great competence in image and audio generation tasks. However, there exist few attempts to employ DDPM in the text generation, especially review generation under recommendation systems. Fueled by the predicted reviews explainability that justifies recommendations could assist users better understand the recommended items and increase the transparency of recommendation system, we propose a Diffusion Model-based Review Generation towards EXplainable Recommendation named Diffusion-EXR. Diffusion-EXR corrupts the sequence of review embeddings by incrementally introducing varied levels of Gaussian noise to the sequence of word embeddings and learns to reconstruct the original word representations in the reverse process. The nature of DDPM enables our lightweight Transformer backbone to perform excellently in the recommendation review generation task. Extensive experimental results have demonstrated that Diffusion-EXR can achieve state-of-the-art review generation for recommendation on two publicly available benchmark datasets.
SinSR: Diffusion-Based Image Super-Resolution in a Single Step
Nov 23, 2023While super-resolution (SR) methods based on diffusion models exhibit promising results, their practical application is hindered by the substantial number of required inference steps. Recent methods utilize degraded images in the initial state, thereby shortening the Markov chain. Nevertheless, these solutions either rely on a precise formulation of the degradation process or still necessitate a relatively lengthy generation path (e.g., 15 iterations). To enhance inference speed, we propose a simple yet effective method for achieving single-step SR generation, named SinSR. Specifically, we first derive a deterministic sampling process from the most recent state-of-the-art (SOTA) method for accelerating diffusion-based SR. This allows the mapping between the input random noise and the generated high-resolution image to be obtained in a reduced and acceptable number of inference steps during training. We show that this deterministic mapping can be distilled into a student model that performs SR within only one inference step. Additionally, we propose a novel consistency-preserving loss to simultaneously leverage the ground-truth image during the distillation process, ensuring that the performance of the student model is not solely bound by the feature manifold of the teacher model, resulting in further performance improvement. Extensive experiments conducted on synthetic and real-world datasets demonstrate that the proposed method can achieve comparable or even superior performance compared to both previous SOTA methods and the teacher model, in just one sampling step, resulting in a remarkable up to x10 speedup for inference. Our code will be released at https://github.com/wyf0912/SinSR
Pixel-Inconsistency Modeling for Image Manipulation Localization
Sep 30, 2023



Digital image forensics plays a crucial role in image authentication and manipulation localization. Despite the progress powered by deep neural networks, existing forgery localization methodologies exhibit limitations when deployed to unseen datasets and perturbed images (i.e., lack of generalization and robustness to real-world applications). To circumvent these problems and aid image integrity, this paper presents a generalized and robust manipulation localization model through the analysis of pixel inconsistency artifacts. The rationale is grounded on the observation that most image signal processors (ISP) involve the demosaicing process, which introduces pixel correlations in pristine images. Moreover, manipulating operations, including splicing, copy-move, and inpainting, directly affect such pixel regularity. We, therefore, first split the input image into several blocks and design masked self-attention mechanisms to model the global pixel dependency in input images. Simultaneously, we optimize another local pixel dependency stream to mine local manipulation clues within input forgery images. In addition, we design novel Learning-to-Weight Modules (LWM) to combine features from the two streams, thereby enhancing the final forgery localization performance. To improve the training process, we propose a novel Pixel-Inconsistency Data Augmentation (PIDA) strategy, driving the model to focus on capturing inherent pixel-level artifacts instead of mining semantic forgery traces. This work establishes a comprehensive benchmark integrating 15 representative detection models across 12 datasets. Extensive experiments show that our method successfully extracts inherent pixel-inconsistency forgery fingerprints and achieve state-of-the-art generalization and robustness performances in image manipulation localization.
Forgery-aware Adaptive Vision Transformer for Face Forgery Detection
Sep 20, 2023With the advancement in face manipulation technologies, the importance of face forgery detection in protecting authentication integrity becomes increasingly evident. Previous Vision Transformer (ViT)-based detectors have demonstrated subpar performance in cross-database evaluations, primarily because fully fine-tuning with limited Deepfake data often leads to forgetting pre-trained knowledge and over-fitting to data-specific ones. To circumvent these issues, we propose a novel Forgery-aware Adaptive Vision Transformer (FA-ViT). In FA-ViT, the vanilla ViT's parameters are frozen to preserve its pre-trained knowledge, while two specially designed components, the Local-aware Forgery Injector (LFI) and the Global-aware Forgery Adaptor (GFA), are employed to adapt forgery-related knowledge. our proposed FA-ViT effectively combines these two different types of knowledge to form the general forgery features for detecting Deepfakes. Specifically, LFI captures local discriminative information and incorporates these information into ViT via Neighborhood-Preserving Cross Attention (NPCA). Simultaneously, GFA learns adaptive knowledge in the self-attention layer, bridging the gap between the two different domain. Furthermore, we design a novel Single Domain Pairwise Learning (SDPL) to facilitate fine-grained information learning in FA-ViT. The extensive experiments demonstrate that our FA-ViT achieves state-of-the-art performance in cross-dataset evaluation and cross-manipulation scenarios, and improves the robustness against unseen perturbations.
ExposureDiffusion: Learning to Expose for Low-light Image Enhancement
Jul 15, 2023



Previous raw image-based low-light image enhancement methods predominantly relied on feed-forward neural networks to learn deterministic mappings from low-light to normally-exposed images. However, they failed to capture critical distribution information, leading to visually undesirable results. This work addresses the issue by seamlessly integrating a diffusion model with a physics-based exposure model. Different from a vanilla diffusion model that has to perform Gaussian denoising, with the injected physics-based exposure model, our restoration process can directly start from a noisy image instead of pure noise. As such, our method obtains significantly improved performance and reduced inference time compared with vanilla diffusion models. To make full use of the advantages of different intermediate steps, we further propose an adaptive residual layer that effectively screens out the side-effect in the iterative refinement when the intermediate results have been already well-exposed. The proposed framework can work with both real-paired datasets, SOTA noise models, and different backbone networks. Note that, the proposed framework is compatible with real-paired datasets, real/synthetic noise models, and different backbone networks. We evaluate the proposed method on various public benchmarks, achieving promising results with consistent improvements using different exposure models and backbones. Besides, the proposed method achieves better generalization capacity for unseen amplifying ratios and better performance than a larger feedforward neural model when few parameters are adopted.
One-Shot Action Recognition via Multi-Scale Spatial-Temporal Skeleton Matching
Jul 14, 2023



One-shot skeleton action recognition, which aims to learn a skeleton action recognition model with a single training sample, has attracted increasing interest due to the challenge of collecting and annotating large-scale skeleton action data. However, most existing studies match skeleton sequences by comparing their feature vectors directly which neglects spatial structures and temporal orders of skeleton data. This paper presents a novel one-shot skeleton action recognition technique that handles skeleton action recognition via multi-scale spatial-temporal feature matching. We represent skeleton data at multiple spatial and temporal scales and achieve optimal feature matching from two perspectives. The first is multi-scale matching which captures the scale-wise semantic relevance of skeleton data at multiple spatial and temporal scales simultaneously. The second is cross-scale matching which handles different motion magnitudes and speeds by capturing sample-wise relevance across multiple scales. Extensive experiments over three large-scale datasets (NTU RGB+D, NTU RGB+D 120, and PKU-MMD) show that our method achieves superior one-shot skeleton action recognition, and it outperforms the state-of-the-art consistently by large margins.
Enhancing Low-Light Images Using Infrared-Encoded Images
Jul 09, 2023



Low-light image enhancement task is essential yet challenging as it is ill-posed intrinsically. Previous arts mainly focus on the low-light images captured in the visible spectrum using pixel-wise loss, which limits the capacity of recovering the brightness, contrast, and texture details due to the small number of income photons. In this work, we propose a novel approach to increase the visibility of images captured under low-light environments by removing the in-camera infrared (IR) cut-off filter, which allows for the capture of more photons and results in improved signal-to-noise ratio due to the inclusion of information from the IR spectrum. To verify the proposed strategy, we collect a paired dataset of low-light images captured without the IR cut-off filter, with corresponding long-exposure reference images with an external filter. The experimental results on the proposed dataset demonstrate the effectiveness of the proposed method, showing better performance quantitatively and qualitatively. The dataset and code are publicly available at https://wyf0912.github.io/ELIEI/