 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAdversarially Trained Actor Critic for Offline Reinforcement Learning
Feb 05, 2022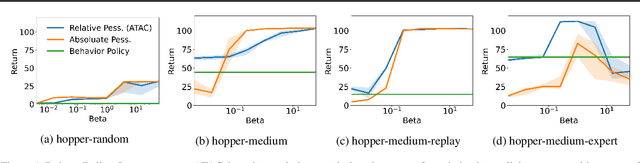
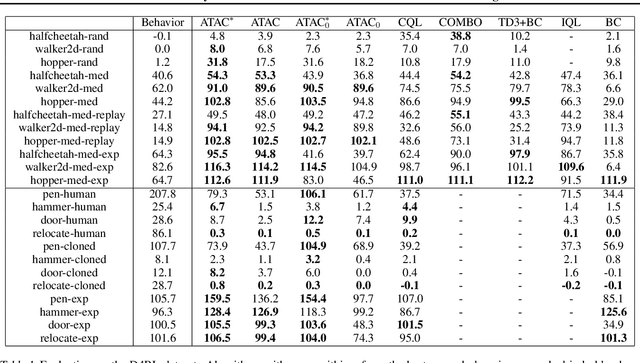
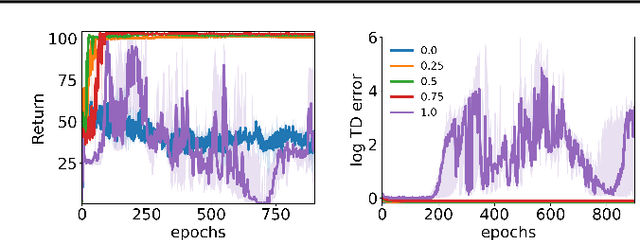
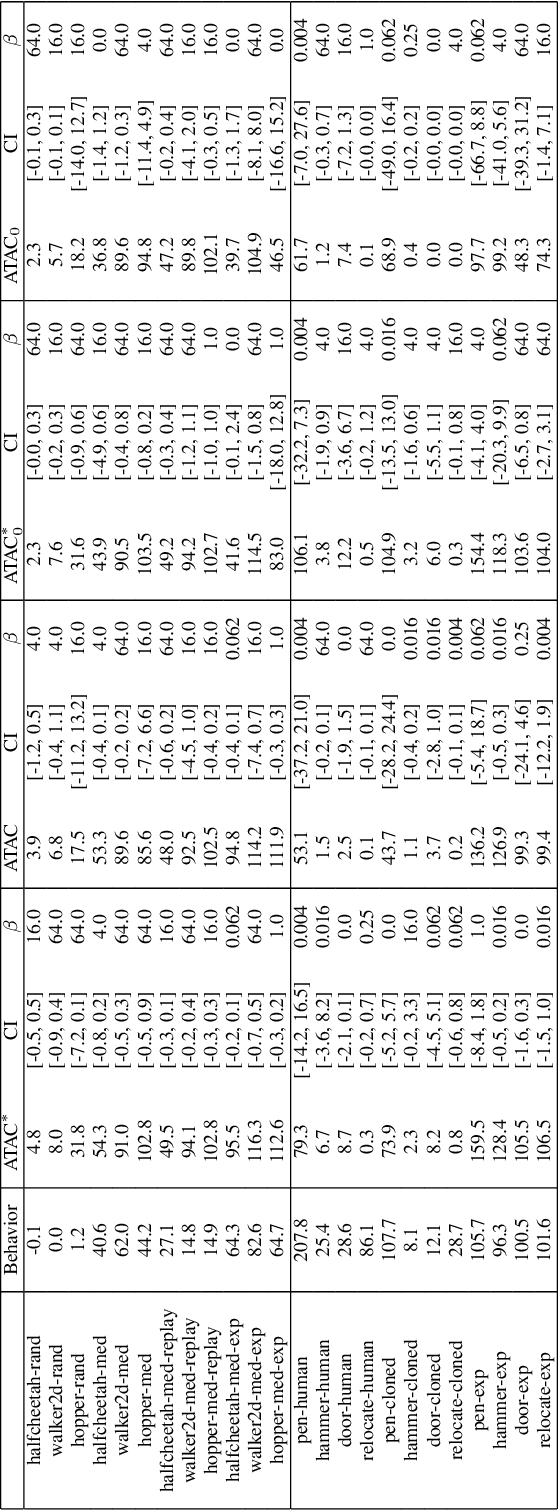
We propose Adversarially Trained Actor Critic (ATAC), a new model-free algorithm for offline reinforcement learning under insufficient data coverage, based on a two-player Stackelberg game framing of offline RL: A policy actor competes against an adversarially trained value critic, who finds data-consistent scenarios where the actor is inferior to the data-collection behavior policy. We prove that, when the actor attains no regret in the two-player game, running ATAC produces a policy that provably 1) outperforms the behavior policy over a wide range of hyperparameters, and 2) competes with the best policy covered by data with appropriately chosen hyperparameters. Compared with existing works, notably our framework offers both theoretical guarantees for general function approximation and a deep RL implementation scalable to complex environments and large datasets. In the D4RL benchmark, ATAC consistently outperforms state-of-the-art offline RL algorithms on a range of continuous control tasks
Efficient Reinforcement Learning in Block MDPs: A Model-free Representation Learning Approach
Feb 02, 2022
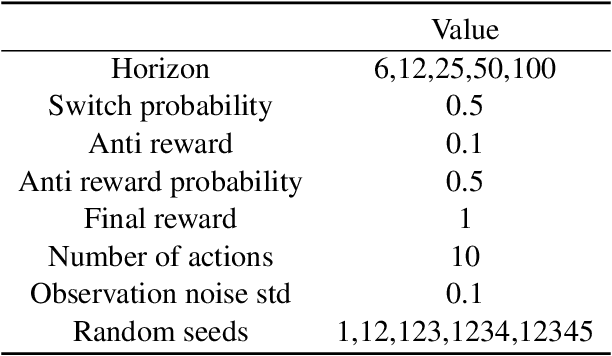
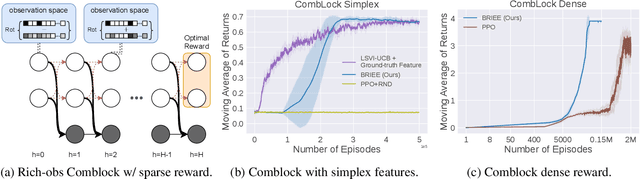
We present BRIEE (Block-structured Representation learning with Interleaved Explore Exploit), an algorithm for efficient reinforcement learning in Markov Decision Processes with block-structured dynamics (i.e., Block MDPs), where rich observations are generated from a set of unknown latent states. BRIEE interleaves latent states discovery, exploration, and exploitation together, and can provably learn a near-optimal policy with sample complexity scaling polynomially in the number of latent states, actions, and the time horizon, with no dependence on the size of the potentially infinite observation space. Empirically, we show that BRIEE is more sample efficient than the state-of-art Block MDP algorithm HOMER and other empirical RL baselines on challenging rich-observation combination lock problems that require deep exploration.
Provable RL with Exogenous Distractors via Multistep Inverse Dynamics
Oct 17, 2021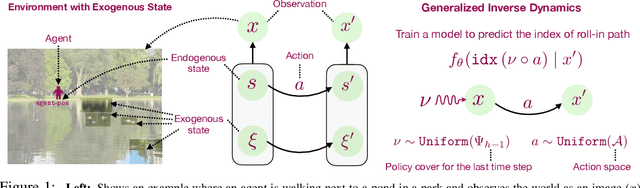

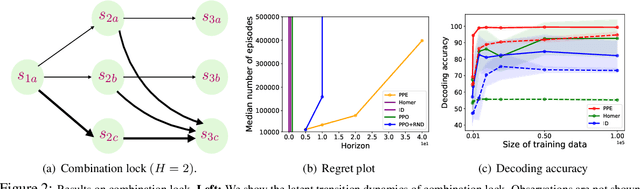
Many real-world applications of reinforcement learning (RL) require the agent to deal with high-dimensional observations such as those generated from a megapixel camera. Prior work has addressed such problems with representation learning, through which the agent can provably extract endogenous, latent state information from raw observations and subsequently plan efficiently. However, such approaches can fail in the presence of temporally correlated noise in the observations, a phenomenon that is common in practice. We initiate the formal study of latent state discovery in the presence of such exogenous noise sources by proposing a new model, the Exogenous Block MDP (EX-BMDP), for rich observation RL. We start by establishing several negative results, by highlighting failure cases of prior representation learning based approaches. Then, we introduce the Predictive Path Elimination (PPE) algorithm, that learns a generalization of inverse dynamics and is provably sample and computationally efficient in EX-BMDPs when the endogenous state dynamics are near deterministic. The sample complexity of PPE depends polynomially on the size of the latent endogenous state space while not directly depending on the size of the observation space, nor the exogenous state space. We provide experiments on challenging exploration problems which show that our approach works empirically.
Bellman-consistent Pessimism for Offline Reinforcement Learning
Jul 01, 2021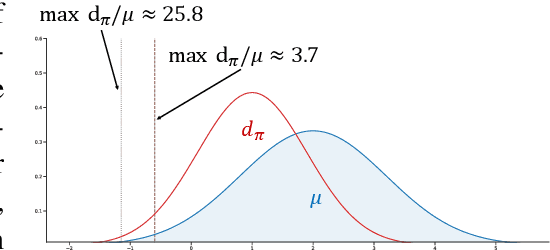
The use of pessimism, when reasoning about datasets lacking exhaustive exploration has recently gained prominence in offline reinforcement learning. Despite the robustness it adds to the algorithm, overly pessimistic reasoning can be equally damaging in precluding the discovery of good policies, which is an issue for the popular bonus-based pessimism. In this paper, we introduce the notion of Bellman-consistent pessimism for general function approximation: instead of calculating a point-wise lower bound for the value function, we implement pessimism at the initial state over the set of functions consistent with the Bellman equations. Our theoretical guarantees only require Bellman closedness as standard in the exploratory setting, in which case bonus-based pessimism fails to provide guarantees. Even in the special case of linear MDPs where stronger function-approximation assumptions hold, our result improves upon a recent bonus-based approach by $\mathcal{O}(d)$ in its sample complexity when the action space is finite. Remarkably, our algorithms automatically adapt to the best bias-variance tradeoff in the hindsight, whereas most prior approaches require tuning extra hyperparameters a priori.
Cautiously Optimistic Policy Optimization and Exploration with Linear Function Approximation
Mar 24, 2021
Policy optimization methods are popular reinforcement learning algorithms, because their incremental and on-policy nature makes them more stable than the value-based counterparts. However, the same properties also make them slow to converge and sample inefficient, as the on-policy requirement precludes data reuse and the incremental updates couple large iteration complexity into the sample complexity. These characteristics have been observed in experiments as well as in theory in the recent work of~\citet{agarwal2020pc}, which provides a policy optimization method PCPG that can robustly find near optimal polices for approximately linear Markov decision processes but suffers from an extremely poor sample complexity compared with value-based techniques. In this paper, we propose a new algorithm, COPOE, that overcomes the sample complexity issue of PCPG while retaining its robustness to model misspecification. Compared with PCPG, COPOE makes several important algorithmic enhancements, such as enabling data reuse, and uses more refined analysis techniques, which we expect to be more broadly applicable to designing new reinforcement learning algorithms. The result is an improvement in sample complexity from $\widetilde{O}(1/\epsilon^{11})$ for PCPG to $\widetilde{O}(1/\epsilon^3)$ for PCPG, nearly bridging the gap with value-based techniques.
Provably Correct Optimization and Exploration with Non-linear Policies
Mar 22, 2021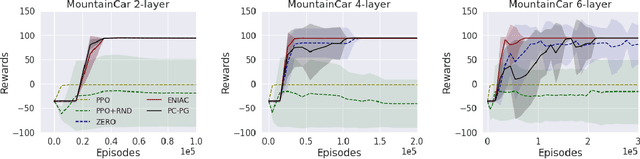
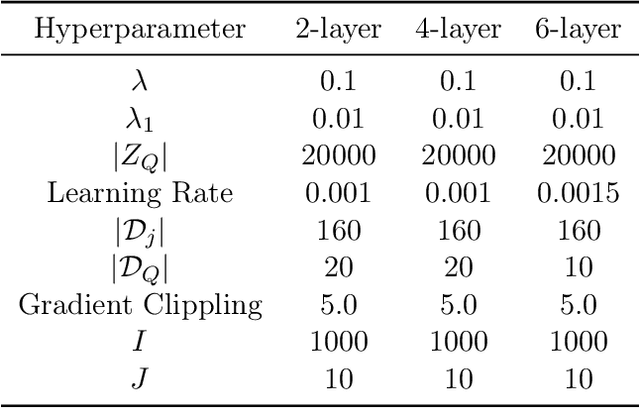
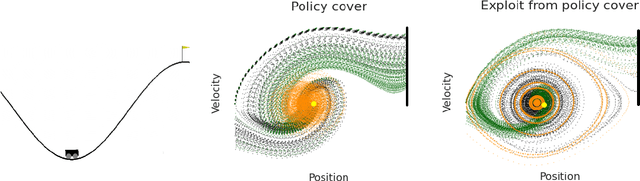
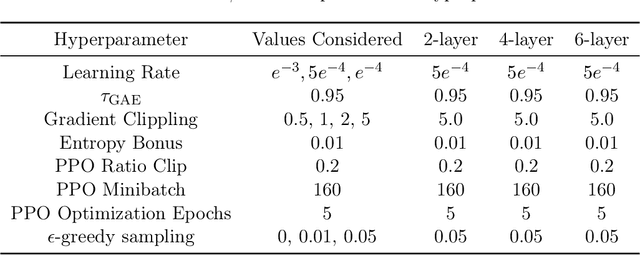
Policy optimization methods remain a powerful workhorse in empirical Reinforcement Learning (RL), with a focus on neural policies that can easily reason over complex and continuous state and/or action spaces. Theoretical understanding of strategic exploration in policy-based methods with non-linear function approximation, however, is largely missing. In this paper, we address this question by designing ENIAC, an actor-critic method that allows non-linear function approximation in the critic. We show that under certain assumptions, e.g., a bounded eluder dimension $d$ for the critic class, the learner finds a near-optimal policy in $O(\poly(d))$ exploration rounds. The method is robust to model misspecification and strictly extends existing works on linear function approximation. We also develop some computational optimizations of our approach with slightly worse statistical guarantees and an empirical adaptation building on existing deep RL tools. We empirically evaluate this adaptation and show that it outperforms prior heuristics inspired by linear methods, establishing the value via correctly reasoning about the agent's uncertainty under non-linear function approximation.
Towards a Dimension-Free Understanding of Adaptive Linear Control
Mar 19, 2021We study the problem of adaptive control of the linear quadratic regulator for systems in very high, or even infinite dimension. We demonstrate that while sublinear regret requires finite dimensional inputs, the ambient state dimension of the system need not be bounded in order to perform online control. We provide the first regret bounds for LQR which hold for infinite dimensional systems, replacing dependence on ambient dimension with more natural notions of problem complexity. Our guarantees arise from a novel perturbation bound for certainty equivalence which scales with the prediction error in estimating the system parameters, without requiring consistent parameter recovery in more stringent measures like the operator norm. When specialized to finite dimensional settings, our bounds recover near optimal dimension and time horizon dependence.
Model-free Representation Learning and Exploration in Low-rank MDPs
Feb 14, 2021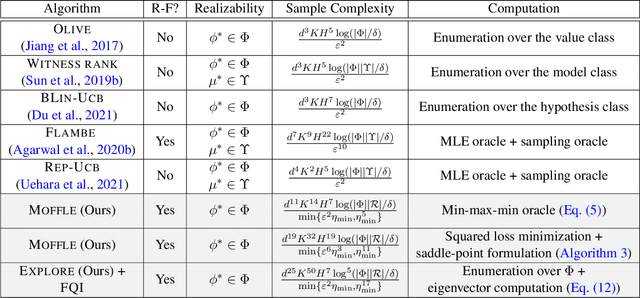
The low rank MDP has emerged as an important model for studying representation learning and exploration in reinforcement learning. With a known representation, several model-free exploration strategies exist. In contrast, all algorithms for the unknown representation setting are model-based, thereby requiring the ability to model the full dynamics. In this work, we present the first model-free representation learning algorithms for low rank MDPs. The key algorithmic contribution is a new minimax representation learning objective, for which we provide variants with differing tradeoffs in their statistical and computational properties. We interleave this representation learning step with an exploration strategy to cover the state space in a reward-free manner. The resulting algorithms are provably sample efficient and can accommodate general function approximation to scale to complex environments.
PC-PG: Policy Cover Directed Exploration for Provable Policy Gradient Learning
Aug 13, 2020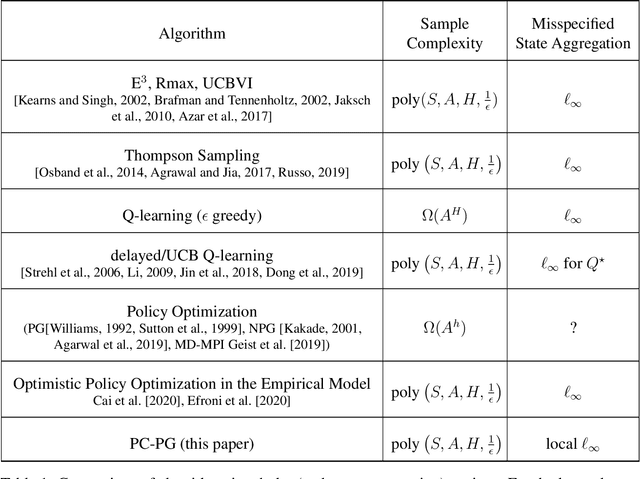
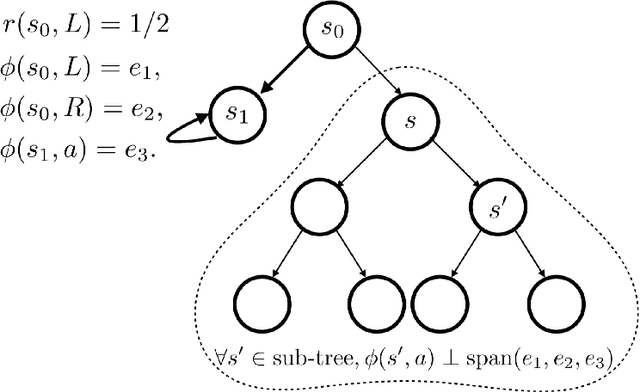
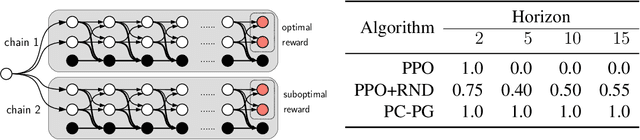
Direct policy gradient methods for reinforcement learning are a successful approach for a variety of reasons: they are model free, they directly optimize the performance metric of interest, and they allow for richly parameterized policies. Their primary drawback is that, by being local in nature, they fail to adequately explore the environment. In contrast, while model-based approaches and Q-learning directly handle exploration through the use of optimism, their ability to handle model misspecification and function approximation is far less evident. This work introduces the the Policy Cover-Policy Gradient (PC-PG) algorithm, which provably balances the exploration vs. exploitation tradeoff using an ensemble of learned policies (the policy cover). PC-PG enjoys polynomial sample complexity and run time for both tabular MDPs and, more generally, linear MDPs in an infinite dimensional RKHS. Furthermore, PC-PG also has strong guarantees under model misspecification that go beyond the standard worst case $\ell_{\infty}$ assumptions; this includes approximation guarantees for state aggregation under an average case error assumption, along with guarantees under a more general assumption where the approximation error under distribution shift is controlled. We complement the theory with empirical evaluation across a variety of domains in both reward-free and reward-driven settings.
Provably Good Batch Reinforcement Learning Without Great Exploration
Jul 22, 2020
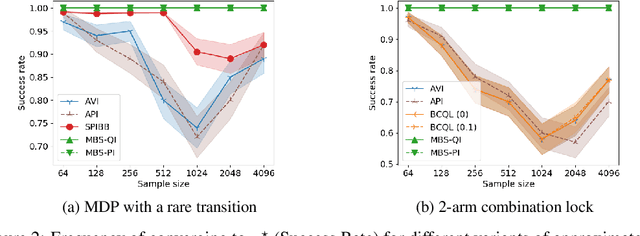
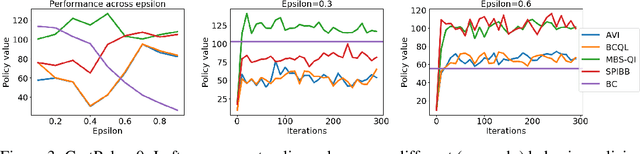
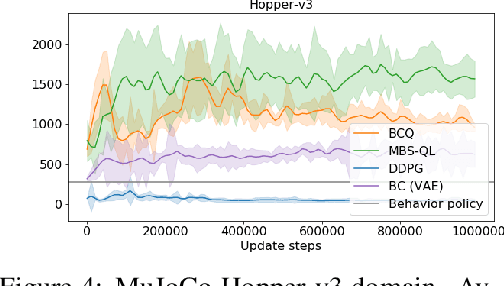
Batch reinforcement learning (RL) is important to apply RL algorithms to many high stakes tasks. Doing batch RL in a way that yields a reliable new policy in large domains is challenging: a new decision policy may visit states and actions outside the support of the batch data, and function approximation and optimization with limited samples can further increase the potential of learning policies with overly optimistic estimates of their future performance. Recent algorithms have shown promise but can still be overly optimistic in their expected outcomes. Theoretical work that provides strong guarantees on the performance of the output policy relies on a strong concentrability assumption, that makes it unsuitable for cases where the ratio between state-action distributions of behavior policy and some candidate policies is large. This is because in the traditional analysis, the error bound scales up with this ratio. We show that a small modification to Bellman optimality and evaluation back-up to take a more conservative update can have much stronger guarantees. In certain settings, they can find the approximately best policy within the state-action space explored by the batch data, without requiring a priori assumptions of concentrability. We highlight the necessity of our conservative update and the limitations of previous algorithms and analyses by illustrative MDP examples, and demonstrate an empirical comparison of our algorithm and other state-of-the-art batch RL baselines in standard benchmarks.