 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAda-NAV: Adaptive Trajectory-Based Sample Efficient Policy Learning for Robotic Navigation
Jun 09, 2023Reinforcement learning methods, while effective for learning robotic navigation strategies, are known to be highly sample inefficient. This sample inefficiency comes in part from not suitably balancing the explore-exploit dilemma, especially in the presence of non-stationarity, during policy optimization. To incorporate a balance of exploration-exploitation for sample efficiency, we propose Ada-NAV, an adaptive trajectory length scheme where the length grows as a policy's randomness, represented by its Shannon or differential entropy, decreases. Our adaptive trajectory length scheme emphasizes exploration at the beginning of training due to more frequent gradient updates and emphasizes exploitation later on with longer trajectories. In gridworld, simulated robotic environments, and real-world robotic experiments, we demonstrate the merits of the approach over constant and randomly sampled trajectory lengths in terms of performance and sample efficiency. For a fixed sample budget, Ada-NAV results in an 18% increase in navigation success rate, a 20-38% decrease in the navigation path length, and 9.32% decrease in the elevation cost compared to the policies obtained by the other methods. We also demonstrate that Ada-NAV can be transferred and integrated into a Clearpath Husky robot without significant performance degradation.
A Gradient-based Approach for Online Robust Deep Neural Network Training with Noisy Labels
Jun 08, 2023Learning with noisy labels is an important topic for scalable training in many real-world scenarios. However, few previous research considers this problem in the online setting, where the arrival of data is streaming. In this paper, we propose a novel gradient-based approach to enable the detection of noisy labels for the online learning of model parameters, named Online Gradient-based Robust Selection (OGRS). In contrast to the previous sample selection approach for the offline training that requires the estimation of a clean ratio of the dataset before each epoch of training, OGRS can automatically select clean samples by steps of gradient update from datasets with varying clean ratios without changing the parameter setting. During the training process, the OGRS method selects clean samples at each iteration and feeds the selected sample to incrementally update the model parameters. We provide a detailed theoretical analysis to demonstrate data selection process is converging to the low-loss region of the sample space, by introducing and proving the sub-linear local Lagrangian regret of the non-convex constrained optimization problem. Experimental results show that it outperforms state-of-the-art methods in different settings.
Scalable Primal-Dual Actor-Critic Method for Safe Multi-Agent RL with General Utilities
May 27, 2023We investigate safe multi-agent reinforcement learning, where agents seek to collectively maximize an aggregate sum of local objectives while satisfying their own safety constraints. The objective and constraints are described by {\it general utilities}, i.e., nonlinear functions of the long-term state-action occupancy measure, which encompass broader decision-making goals such as risk, exploration, or imitations. The exponential growth of the state-action space size with the number of agents presents challenges for global observability, further exacerbated by the global coupling arising from agents' safety constraints. To tackle this issue, we propose a primal-dual method utilizing shadow reward and $\kappa$-hop neighbor truncation under a form of correlation decay property, where $\kappa$ is the communication radius. In the exact setting, our algorithm converges to a first-order stationary point (FOSP) at the rate of $\mathcal{O}\left(T^{-2/3}\right)$. In the sample-based setting, we demonstrate that, with high probability, our algorithm requires $\widetilde{\mathcal{O}}\left(\epsilon^{-3.5}\right)$ samples to achieve an $\epsilon$-FOSP with an approximation error of $\mathcal{O}(\phi_0^{2\kappa})$, where $\phi_0\in (0,1)$. Finally, we demonstrate the effectiveness of our model through extensive numerical experiments.
Sharpened Lazy Incremental Quasi-Newton Method
May 26, 2023We consider the finite sum minimization of $n$ strongly convex and smooth functions with Lipschitz continuous Hessians in $d$ dimensions. In many applications where such problems arise, including maximum likelihood estimation, empirical risk minimization, and unsupervised learning, the number of observations $n$ is large, and it becomes necessary to use incremental or stochastic algorithms whose per-iteration complexity is independent of $n$. Of these, the incremental/stochastic variants of the Newton method exhibit superlinear convergence, but incur a per-iteration complexity of $O(d^3)$, which may be prohibitive in large-scale settings. On the other hand, the incremental Quasi-Newton method incurs a per-iteration complexity of $O(d^2)$ but its superlinear convergence rate has only been characterized asymptotically. This work puts forth the Sharpened Lazy Incremental Quasi-Newton (SLIQN) method that achieves the best of both worlds: an explicit superlinear convergence rate with a per-iteration complexity of $O(d^2)$. Building upon the recently proposed Sharpened Quasi-Newton method, the proposed incremental variant incorporates a hybrid update strategy incorporating both classic and greedy BFGS updates. The proposed lazy update rule distributes the computational complexity between the iterations, so as to enable a per-iteration complexity of $O(d^2)$. Numerical tests demonstrate the superiority of SLIQN over all other incremental and stochastic Quasi-Newton variants.
Scalable Multi-Agent Reinforcement Learning with General Utilities
Feb 15, 2023We study the scalable multi-agent reinforcement learning (MARL) with general utilities, defined as nonlinear functions of the team's long-term state-action occupancy measure. The objective is to find a localized policy that maximizes the average of the team's local utility functions without the full observability of each agent in the team. By exploiting the spatial correlation decay property of the network structure, we propose a scalable distributed policy gradient algorithm with shadow reward and localized policy that consists of three steps: (1) shadow reward estimation, (2) truncated shadow Q-function estimation, and (3) truncated policy gradient estimation and policy update. Our algorithm converges, with high probability, to $\epsilon$-stationarity with $\widetilde{\mc{O}}(\epsilon^{-2})$ samples up to some approximation error that decreases exponentially in the communication radius. This is the first result in the literature on multi-agent RL with general utilities that does not require the full observability.
Beyond Exponentially Fast Mixing in Average-Reward Reinforcement Learning via Multi-Level Monte Carlo Actor-Critic
Feb 01, 2023


Many existing reinforcement learning (RL) methods employ stochastic gradient iteration on the back end, whose stability hinges upon a hypothesis that the data-generating process mixes exponentially fast with a rate parameter that appears in the step-size selection. Unfortunately, this assumption is violated for large state spaces or settings with sparse rewards, and the mixing time is unknown, making the step size inoperable. In this work, we propose an RL methodology attuned to the mixing time by employing a multi-level Monte Carlo estimator for the critic, the actor, and the average reward embedded within an actor-critic (AC) algorithm. This method, which we call \textbf{M}ulti-level \textbf{A}ctor-\textbf{C}ritic (MAC), is developed especially for infinite-horizon average-reward settings and neither relies on oracle knowledge of the mixing time in its parameter selection nor assumes its exponential decay; it, therefore, is readily applicable to applications with slower mixing times. Nonetheless, it achieves a convergence rate comparable to the state-of-the-art AC algorithms. We experimentally show that these alleviated restrictions on the technical conditions required for stability translate to superior performance in practice for RL problems with sparse rewards.
STEERING: Stein Information Directed Exploration for Model-Based Reinforcement Learning
Jan 28, 2023Directed Exploration is a crucial challenge in reinforcement learning (RL), especially when rewards are sparse. Information-directed sampling (IDS), which optimizes the information ratio, seeks to do so by augmenting regret with information gain. However, estimating information gain is computationally intractable or relies on restrictive assumptions which prohibit its use in many practical instances. In this work, we posit an alternative exploration incentive in terms of the integral probability metric (IPM) between a current estimate of the transition model and the unknown optimal, which under suitable conditions, can be computed in closed form with the kernelized Stein discrepancy (KSD). Based on KSD, we develop a novel algorithm STEERING: \textbf{STE}in information dir\textbf{E}cted exploration for model-based \textbf{R}einforcement Learn\textbf{ING}. To enable its derivation, we develop fundamentally new variants of KSD for discrete conditional distributions. We further establish that STEERING archives sublinear Bayesian regret, improving upon prior learning rates of information-augmented MBRL, IDS included. Experimentally, we show that the proposed algorithm is computationally affordable and outperforms several prior approaches.
Oracle-free Reinforcement Learning in Mean-Field Games along a Single Sample Path
Aug 26, 2022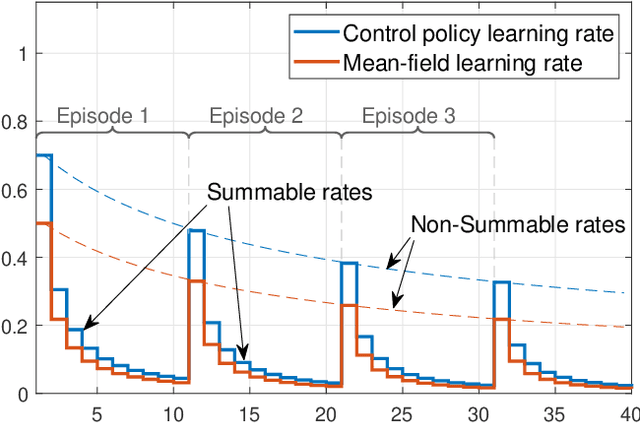
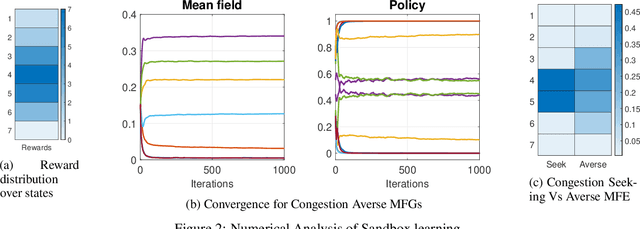
We consider online reinforcement learning in Mean-Field Games. In contrast to the existing works, we alleviate the need for a mean-field oracle by developing an algorithm that estimates the mean-field and the optimal policy using a single sample path of the generic agent. We call this Sandbox Learning, as it can be used as a warm-start for any agent operating in a multi-agent non-cooperative setting. We adopt a two timescale approach in which an online fixed-point recursion for the mean-field operates on a slower timescale and in tandem with a control policy update on a faster timescale for the generic agent. Under a sufficient exploration condition, we provide finite sample convergence guarantees in terms of convergence of the mean-field and control policy to the mean-field equilibrium. The sample complexity of the Sandbox learning algorithm is $\mathcal{O}(\epsilon^{-4})$. Finally, we empirically demonstrate effectiveness of the sandbox learning algorithm in a congestion game.
FedBC: Calibrating Global and Local Models via Federated Learning Beyond Consensus
Jun 26, 2022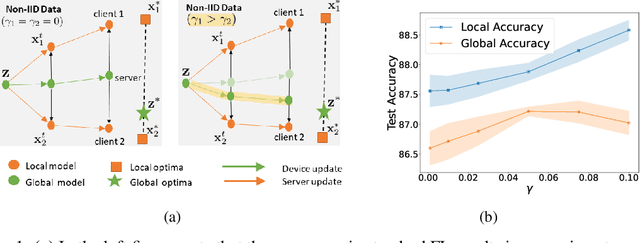
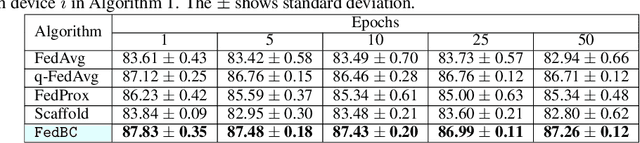
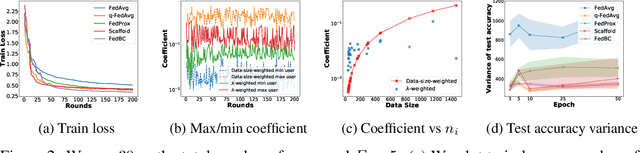
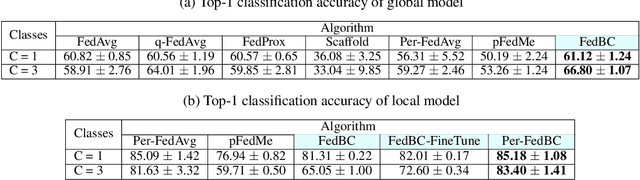
In federated learning (FL), the objective of collaboratively learning a global model through aggregation of model updates across devices tends to oppose the goal of personalization via local information. In this work, we calibrate this tradeoff in a quantitative manner through a multi-criterion optimization-based framework, which we cast as a constrained program: the objective for a device is its local objective, which it seeks to minimize while satisfying nonlinear constraints that quantify the proximity between the local and the global model. By considering the Lagrangian relaxation of this problem, we develop an algorithm that allows each node to minimize its local component of Lagrangian through queries to a first-order gradient oracle. Then, the server executes Lagrange multiplier ascent steps followed by a Lagrange multiplier-weighted averaging step. We call this instantiation of the primal-dual method Federated Learning Beyond Consensus ($\texttt{FedBC}$). Theoretically, we establish that $\texttt{FedBC}$ converges to a first-order stationary point at rates that matches the state of the art, up to an additional error term that depends on the tolerance parameter that arises due to the proximity constraints. Overall, the analysis is a novel characterization of primal-dual methods applied to non-convex saddle point problems with nonlinear constraints. Finally, we demonstrate that $\texttt{FedBC}$ balances the global and local model test accuracy metrics across a suite of datasets (Synthetic, MNIST, CIFAR-10, Shakespeare), achieving competitive performance with the state of the art.
Dealing with Sparse Rewards in Continuous Control Robotics via Heavy-Tailed Policies
Jun 12, 2022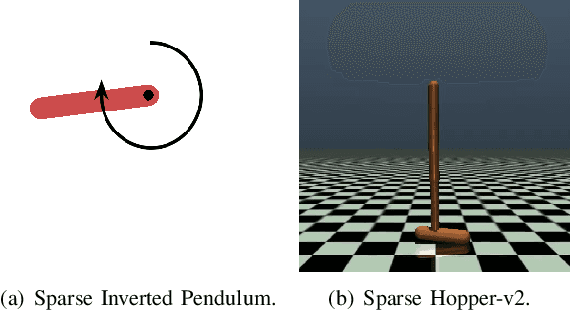
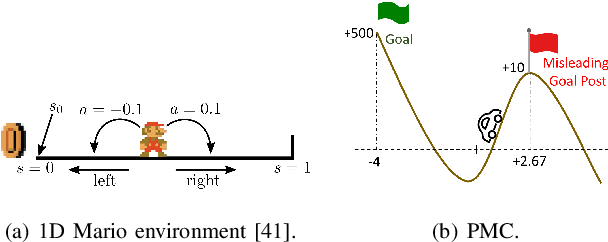
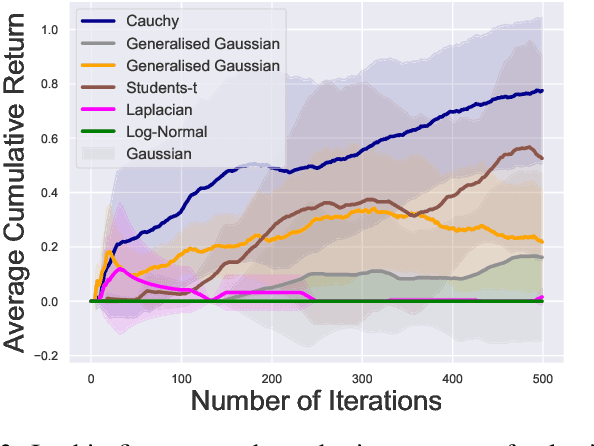
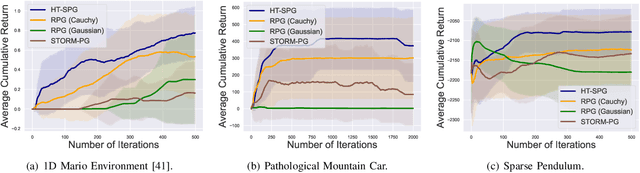
In this paper, we present a novel Heavy-Tailed Stochastic Policy Gradient (HT-PSG) algorithm to deal with the challenges of sparse rewards in continuous control problems. Sparse reward is common in continuous control robotics tasks such as manipulation and navigation, and makes the learning problem hard due to non-trivial estimation of value functions over the state space. This demands either reward shaping or expert demonstrations for the sparse reward environment. However, obtaining high-quality demonstrations is quite expensive and sometimes even impossible. We propose a heavy-tailed policy parametrization along with a modified momentum-based policy gradient tracking scheme (HT-SPG) to induce a stable exploratory behavior to the algorithm. The proposed algorithm does not require access to expert demonstrations. We test the performance of HT-SPG on various benchmark tasks of continuous control with sparse rewards such as 1D Mario, Pathological Mountain Car, Sparse Pendulum in OpenAI Gym, and Sparse MuJoCo environments (Hopper-v2). We show consistent performance improvement across all tasks in terms of high average cumulative reward. HT-SPG also demonstrates improved convergence speed with minimum samples, thereby emphasizing the sample efficiency of our proposed algorithm.