 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePlantCamo: Plant Camouflage Detection
Oct 23, 2024



Camouflaged Object Detection (COD) aims to detect objects with camouflaged properties. Although previous studies have focused on natural (animals and insects) and unnatural (artistic and synthetic) camouflage detection, plant camouflage has been neglected. However, plant camouflage plays a vital role in natural camouflage. Therefore, this paper introduces a new challenging problem of Plant Camouflage Detection (PCD). To address this problem, we introduce the PlantCamo dataset, which comprises 1,250 images with camouflaged plants representing 58 object categories in various natural scenes. To investigate the current status of plant camouflage detection, we conduct a large-scale benchmark study using 20+ cutting-edge COD models on the proposed dataset. Due to the unique characteristics of plant camouflage, including holes and irregular borders, we developed a new framework, named PCNet, dedicated to PCD. Our PCNet surpasses performance thanks to its multi-scale global feature enhancement and refinement. Finally, we discuss the potential applications and insights, hoping this work fills the gap in fine-grained COD research and facilitates further intelligent ecology research. All resources will be available on https://github.com/yjybuaa/PlantCamo.
NCRF: Neural Contact Radiance Fields for Free-Viewpoint Rendering of Hand-Object Interaction
Feb 09, 2024Modeling hand-object interactions is a fundamentally challenging task in 3D computer vision. Despite remarkable progress that has been achieved in this field, existing methods still fail to synthesize the hand-object interaction photo-realistically, suffering from degraded rendering quality caused by the heavy mutual occlusions between the hand and the object, and inaccurate hand-object pose estimation. To tackle these challenges, we present a novel free-viewpoint rendering framework, Neural Contact Radiance Field (NCRF), to reconstruct hand-object interactions from a sparse set of videos. In particular, the proposed NCRF framework consists of two key components: (a) A contact optimization field that predicts an accurate contact field from 3D query points for achieving desirable contact between the hand and the object. (b) A hand-object neural radiance field to learn an implicit hand-object representation in a static canonical space, in concert with the specifically designed hand-object motion field to produce observation-to-canonical correspondences. We jointly learn these key components where they mutually help and regularize each other with visual and geometric constraints, producing a high-quality hand-object reconstruction that achieves photo-realistic novel view synthesis. Extensive experiments on HO3D and DexYCB datasets show that our approach outperforms the current state-of-the-art in terms of both rendering quality and pose estimation accuracy.
Efficient View Synthesis and 3D-based Multi-Frame Denoising with Multiplane Feature Representations
Apr 05, 2023While current multi-frame restoration methods combine information from multiple input images using 2D alignment techniques, recent advances in novel view synthesis are paving the way for a new paradigm relying on volumetric scene representations. In this work, we introduce the first 3D-based multi-frame denoising method that significantly outperforms its 2D-based counterparts with lower computational requirements. Our method extends the multiplane image (MPI) framework for novel view synthesis by introducing a learnable encoder-renderer pair manipulating multiplane representations in feature space. The encoder fuses information across views and operates in a depth-wise manner while the renderer fuses information across depths and operates in a view-wise manner. The two modules are trained end-to-end and learn to separate depths in an unsupervised way, giving rise to Multiplane Feature (MPF) representations. Experiments on the Spaces and Real Forward-Facing datasets as well as on raw burst data validate our approach for view synthesis, multi-frame denoising, and view synthesis under noisy conditions.
Tunable Convolutions with Parametric Multi-Loss Optimization
Apr 03, 2023Behavior of neural networks is irremediably determined by the specific loss and data used during training. However it is often desirable to tune the model at inference time based on external factors such as preferences of the user or dynamic characteristics of the data. This is especially important to balance the perception-distortion trade-off of ill-posed image-to-image translation tasks. In this work, we propose to optimize a parametric tunable convolutional layer, which includes a number of different kernels, using a parametric multi-loss, which includes an equal number of objectives. Our key insight is to use a shared set of parameters to dynamically interpolate both the objectives and the kernels. During training, these parameters are sampled at random to explicitly optimize all possible combinations of objectives and consequently disentangle their effect into the corresponding kernels. During inference, these parameters become interactive inputs of the model hence enabling reliable and consistent control over the model behavior. Extensive experimental results demonstrate that our tunable convolutions effectively work as a drop-in replacement for traditional convolutions in existing neural networks at virtually no extra computational cost, outperforming state-of-the-art control strategies in a wide range of applications; including image denoising, deblurring, super-resolution, and style transfer.
Learning Dual-Fused Modality-Aware Representations for RGBD Tracking
Nov 15, 2022



With the development of depth sensors in recent years, RGBD object tracking has received significant attention. Compared with the traditional RGB object tracking, the addition of the depth modality can effectively solve the target and background interference. However, some existing RGBD trackers use the two modalities separately and thus some particularly useful shared information between them is ignored. On the other hand, some methods attempt to fuse the two modalities by treating them equally, resulting in the missing of modality-specific features. To tackle these limitations, we propose a novel Dual-fused Modality-aware Tracker (termed DMTracker) which aims to learn informative and discriminative representations of the target objects for robust RGBD tracking. The first fusion module focuses on extracting the shared information between modalities based on cross-modal attention. The second aims at integrating the RGB-specific and depth-specific information to enhance the fused features. By fusing both the modality-shared and modality-specific information in a modality-aware scheme, our DMTracker can learn discriminative representations in complex tracking scenes. Experiments show that our proposed tracker achieves very promising results on challenging RGBD benchmarks.
Prompting for Multi-Modal Tracking
Aug 01, 2022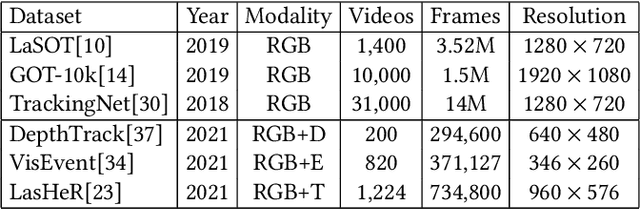
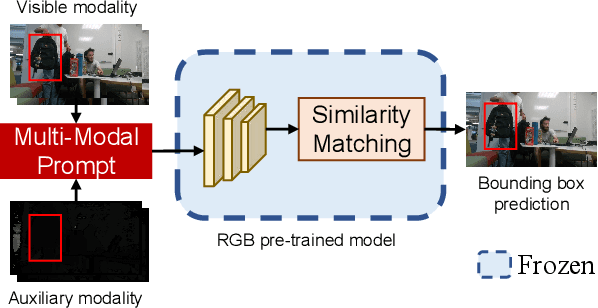
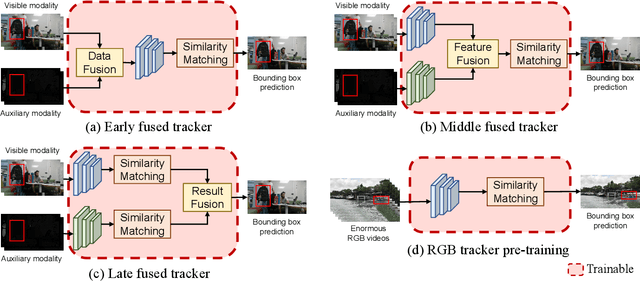
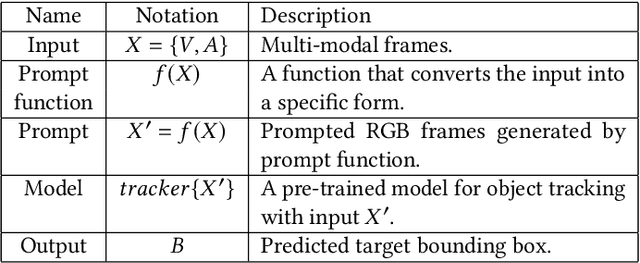
Multi-modal tracking gains attention due to its ability to be more accurate and robust in complex scenarios compared to traditional RGB-based tracking. Its key lies in how to fuse multi-modal data and reduce the gap between modalities. However, multi-modal tracking still severely suffers from data deficiency, thus resulting in the insufficient learning of fusion modules. Instead of building such a fusion module, in this paper, we provide a new perspective on multi-modal tracking by attaching importance to the multi-modal visual prompts. We design a novel multi-modal prompt tracker (ProTrack), which can transfer the multi-modal inputs to a single modality by the prompt paradigm. By best employing the tracking ability of pre-trained RGB trackers learning at scale, our ProTrack can achieve high-performance multi-modal tracking by only altering the inputs, even without any extra training on multi-modal data. Extensive experiments on 5 benchmark datasets demonstrate the effectiveness of the proposed ProTrack.
BURG-Toolkit: Robot Grasping Experiments in Simulation and the Real World
May 27, 2022
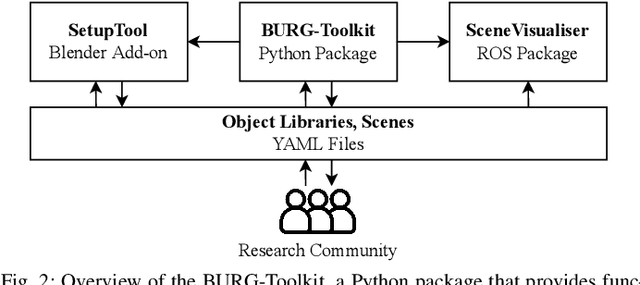

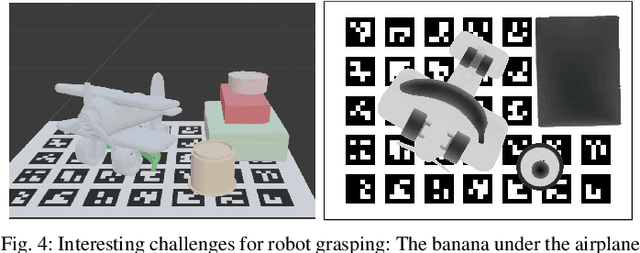
This paper presents BURG-Toolkit, a set of open-source tools for Benchmarking and Understanding Robotic Grasping. Our tools allow researchers to: (1) create virtual scenes for generating training data and performing grasping in simulation; (2) recreate the scene by arranging the corresponding objects accurately in the physical world for real robot experiments, supporting an analysis of the sim-to-real gap; and (3) share the scenes with other researchers to foster comparability and reproducibility of experimental results. We explain how to use our tools by describing some potential use cases. We further provide proof-of-concept experimental results quantifying the sim-to-real gap for robot grasping in some example scenes. The tools are available at: https://mrudorfer.github.io/burg-toolkit/
NTIRE 2022 Challenge on High Dynamic Range Imaging: Methods and Results
May 25, 2022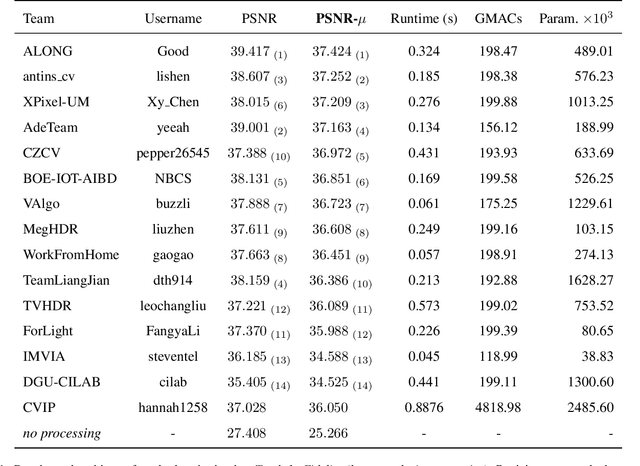
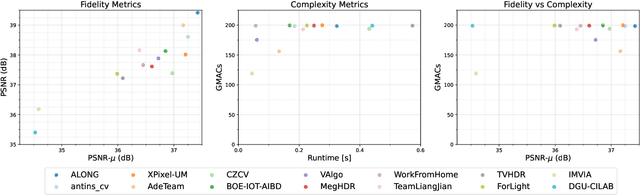
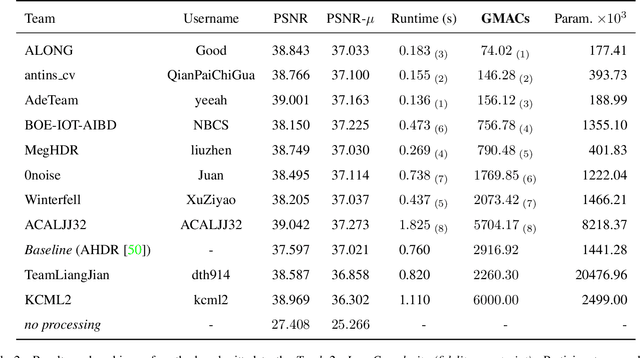
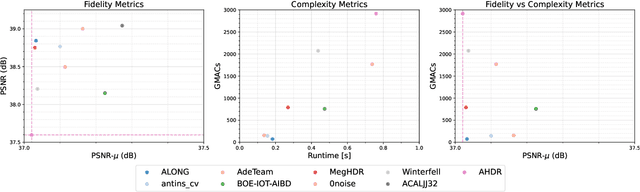
This paper reviews the challenge on constrained high dynamic range (HDR) imaging that was part of the New Trends in Image Restoration and Enhancement (NTIRE) workshop, held in conjunction with CVPR 2022. This manuscript focuses on the competition set-up, datasets, the proposed methods and their results. The challenge aims at estimating an HDR image from multiple respective low dynamic range (LDR) observations, which might suffer from under- or over-exposed regions and different sources of noise. The challenge is composed of two tracks with an emphasis on fidelity and complexity constraints: In Track 1, participants are asked to optimize objective fidelity scores while imposing a low-complexity constraint (i.e. solutions can not exceed a given number of operations). In Track 2, participants are asked to minimize the complexity of their solutions while imposing a constraint on fidelity scores (i.e. solutions are required to obtain a higher fidelity score than the prescribed baseline). Both tracks use the same data and metrics: Fidelity is measured by means of PSNR with respect to a ground-truth HDR image (computed both directly and with a canonical tonemapping operation), while complexity metrics include the number of Multiply-Accumulate (MAC) operations and runtime (in seconds).
* CVPR Workshops 2022. 15 pages, 21 figures, 2 tables
CroMo: Cross-Modal Learning for Monocular Depth Estimation
Mar 28, 2022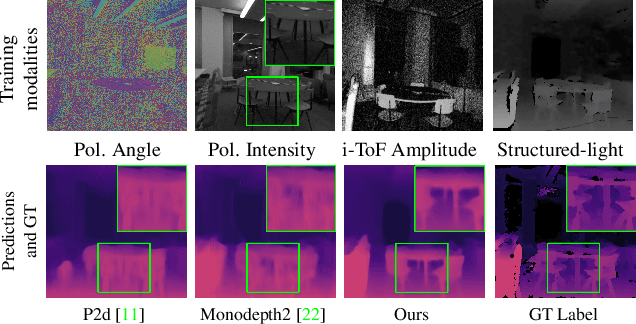
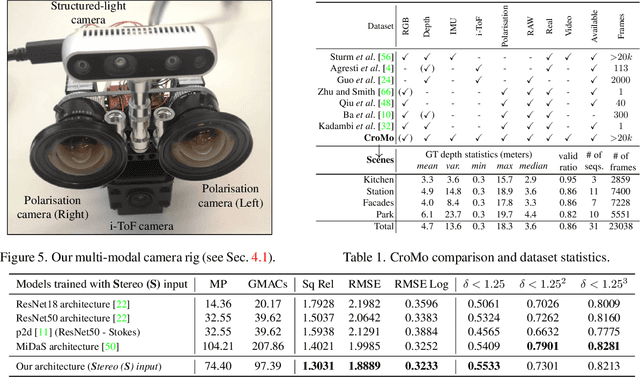

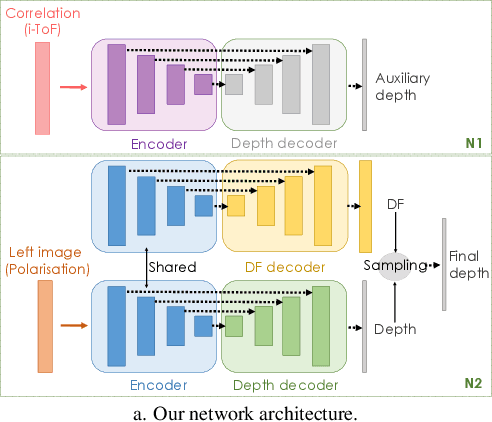
Learning-based depth estimation has witnessed recent progress in multiple directions; from self-supervision using monocular video to supervised methods offering highest accuracy. Complementary to supervision, further boosts to performance and robustness are gained by combining information from multiple signals. In this paper we systematically investigate key trade-offs associated with sensor and modality design choices as well as related model training strategies. Our study leads us to a new method, capable of connecting modality-specific advantages from polarisation, Time-of-Flight and structured-light inputs. We propose a novel pipeline capable of estimating depth from monocular polarisation for which we evaluate various training signals. The inversion of differentiable analytic models thereby connects scene geometry with polarisation and ToF signals and enables self-supervised and cross-modal learning. In the absence of existing multimodal datasets, we examine our approach with a custom-made multi-modal camera rig and collect CroMo; the first dataset to consist of synchronized stereo polarisation, indirect ToF and structured-light depth, captured at video rates. Extensive experiments on challenging video scenes confirm both qualitative and quantitative pipeline advantages where we are able to outperform competitive monocular depth estimation method.
RGBD Object Tracking: An In-depth Review
Mar 26, 2022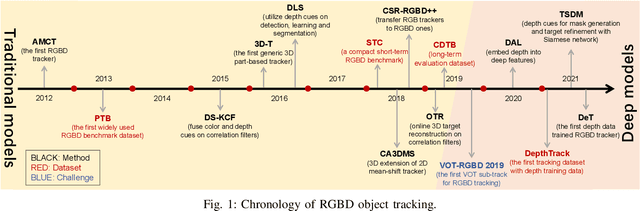
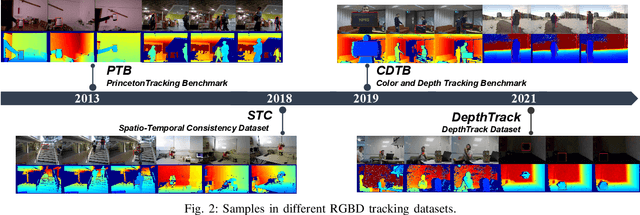
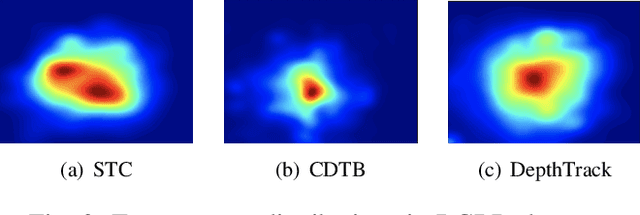
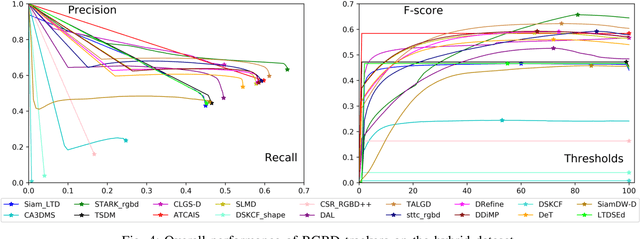
RGBD object tracking is gaining momentum in computer vision research thanks to the development of depth sensors. Although numerous RGBD trackers have been proposed with promising performance, an in-depth review for comprehensive understanding of this area is lacking. In this paper, we firstly review RGBD object trackers from different perspectives, including RGBD fusion, depth usage, and tracking framework. Then, we summarize the existing datasets and the evaluation metrics. We benchmark a representative set of RGBD trackers, and give detailed analyses based on their performances. Particularly, we are the first to provide depth quality evaluation and analysis of tracking results in depth-friendly scenarios in RGBD tracking. For long-term settings in most RGBD tracking videos, we give an analysis of trackers' performance on handling target disappearance. To enable better understanding of RGBD trackers, we propose robustness evaluation against input perturbations. Finally, we summarize the challenges and provide open directions for this community. All resources are publicly available at https://github.com/memoryunreal/RGBD-tracking-review.