 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTransformers Learn Shortcuts to Automata
Oct 19, 2022Algorithmic reasoning requires capabilities which are most naturally understood through recurrent models of computation, like the Turing machine. However, Transformer models, while lacking recurrence, are able to perform such reasoning using far fewer layers than the number of reasoning steps. This raises the question: what solutions are these shallow and non-recurrent models finding? We investigate this question in the setting of learning automata, discrete dynamical systems naturally suited to recurrent modeling and expressing algorithmic tasks. Our theoretical results completely characterize shortcut solutions, whereby a shallow Transformer with only $o(T)$ layers can exactly replicate the computation of an automaton on an input sequence of length $T$. By representing automata using the algebraic structure of their underlying transformation semigroups, we obtain $O(\log T)$-depth simulators for all automata and $O(1)$-depth simulators for all automata whose associated groups are solvable. Empirically, we perform synthetic experiments by training Transformers to simulate a wide variety of automata, and show that shortcut solutions can be learned via standard training. We further investigate the brittleness of these solutions and propose potential mitigations.
Hybrid RL: Using Both Offline and Online Data Can Make RL Efficient
Oct 13, 2022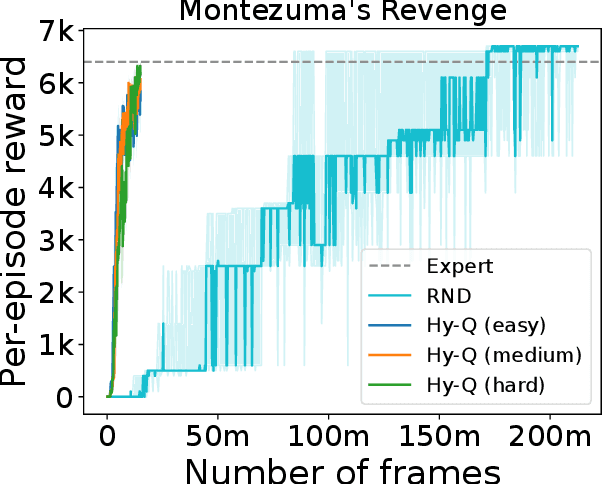
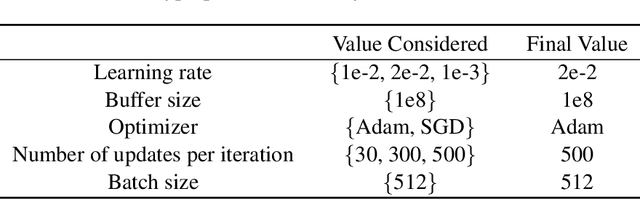
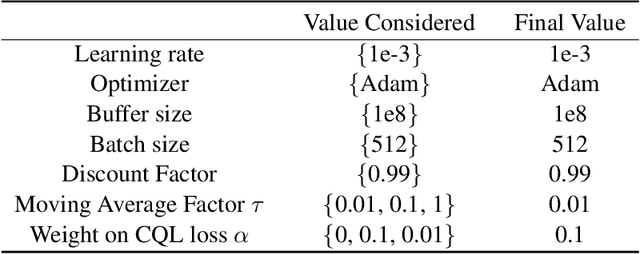
We consider a hybrid reinforcement learning setting (Hybrid RL), in which an agent has access to an offline dataset and the ability to collect experience via real-world online interaction. The framework mitigates the challenges that arise in both pure offline and online RL settings, allowing for the design of simple and highly effective algorithms, in both theory and practice. We demonstrate these advantages by adapting the classical Q learning/iteration algorithm to the hybrid setting, which we call Hybrid Q-Learning or Hy-Q. In our theoretical results, we prove that the algorithm is both computationally and statistically efficient whenever the offline dataset supports a high-quality policy and the environment has bounded bilinear rank. Notably, we require no assumptions on the coverage provided by the initial distribution, in contrast with guarantees for policy gradient/iteration methods. In our experimental results, we show that Hy-Q with neural network function approximation outperforms state-of-the-art online, offline, and hybrid RL baselines on challenging benchmarks, including Montezuma's Revenge.
Guaranteed Discovery of Controllable Latent States with Multi-Step Inverse Models
Jul 17, 2022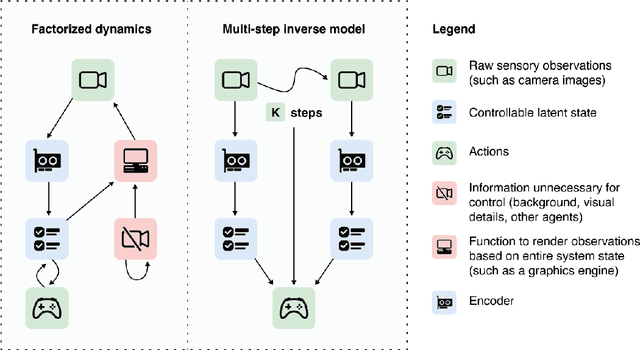
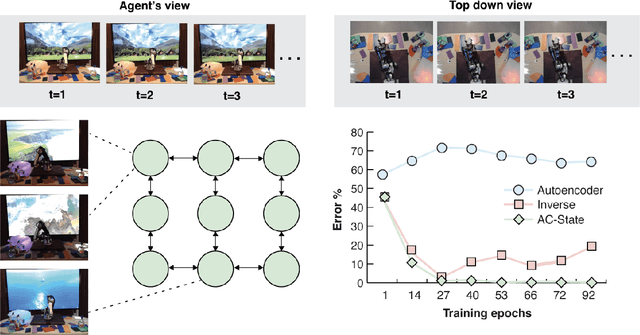
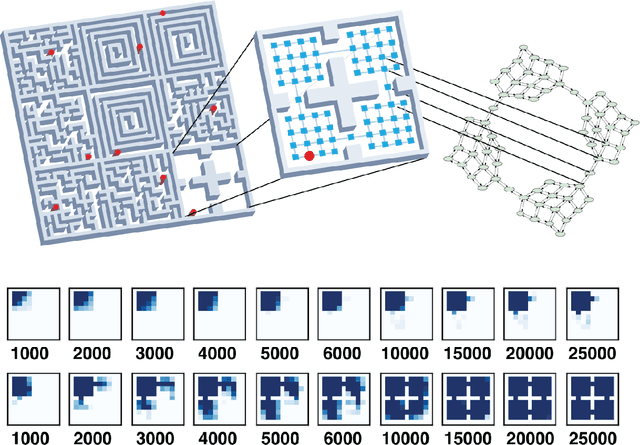
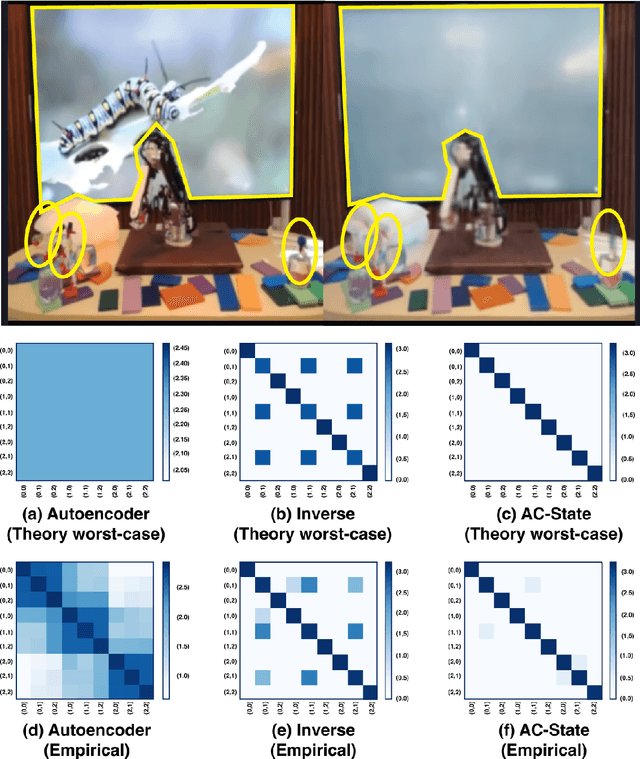
A person walking along a city street who tries to model all aspects of the world would quickly be overwhelmed by a multitude of shops, cars, and people moving in and out of view, following their own complex and inscrutable dynamics. Exploration and navigation in such an environment is an everyday task, requiring no vast exertion of mental resources. Is it possible to turn this fire hose of sensory information into a minimal latent state which is necessary and sufficient for an agent to successfully act in the world? We formulate this question concretely, and propose the Agent-Controllable State Discovery algorithm (AC-State), which has theoretical guarantees and is practically demonstrated to discover the \textit{minimal controllable latent state} which contains all of the information necessary for controlling the agent, while fully discarding all irrelevant information. This algorithm consists of a multi-step inverse model (predicting actions from distant observations) with an information bottleneck. AC-State enables localization, exploration, and navigation without reward or demonstrations. We demonstrate the discovery of controllable latent state in three domains: localizing a robot arm with distractions (e.g., changing lighting conditions and background), exploring in a maze alongside other agents, and navigating in the Matterport house simulator.
On the Statistical Efficiency of Reward-Free Exploration in Non-Linear RL
Jun 21, 2022
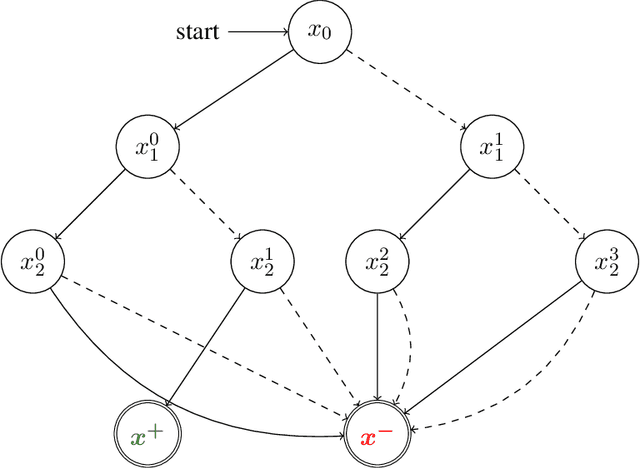
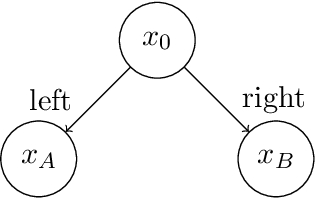
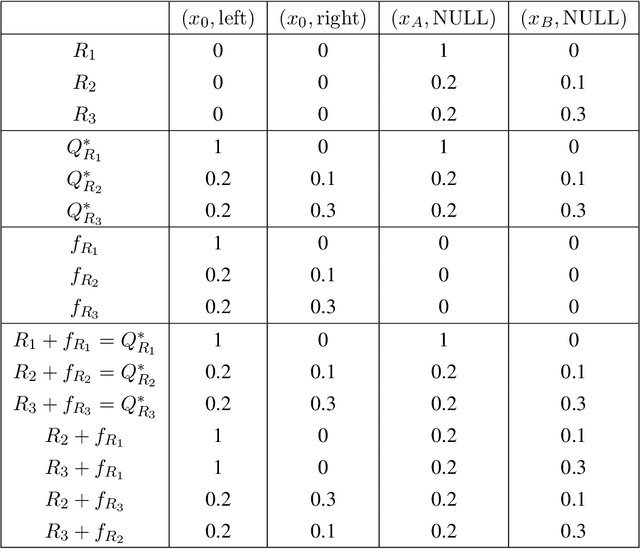
We study reward-free reinforcement learning (RL) under general non-linear function approximation, and establish sample efficiency and hardness results under various standard structural assumptions. On the positive side, we propose the RFOLIVE (Reward-Free OLIVE) algorithm for sample-efficient reward-free exploration under minimal structural assumptions, which covers the previously studied settings of linear MDPs (Jin et al., 2020b), linear completeness (Zanette et al., 2020b) and low-rank MDPs with unknown representation (Modi et al., 2021). Our analyses indicate that the explorability or reachability assumptions, previously made for the latter two settings, are not necessary statistically for reward-free exploration. On the negative side, we provide a statistical hardness result for both reward-free and reward-aware exploration under linear completeness assumptions when the underlying features are unknown, showing an exponential separation between low-rank and linear completeness settings.
Sample-Efficient Reinforcement Learning in the Presence of Exogenous Information
Jun 09, 2022
In real-world reinforcement learning applications the learner's observation space is ubiquitously high-dimensional with both relevant and irrelevant information about the task at hand. Learning from high-dimensional observations has been the subject of extensive investigation in supervised learning and statistics (e.g., via sparsity), but analogous issues in reinforcement learning are not well understood, even in finite state/action (tabular) domains. We introduce a new problem setting for reinforcement learning, the Exogenous Markov Decision Process (ExoMDP), in which the state space admits an (unknown) factorization into a small controllable (or, endogenous) component and a large irrelevant (or, exogenous) component; the exogenous component is independent of the learner's actions, but evolves in an arbitrary, temporally correlated fashion. We provide a new algorithm, ExoRL, which learns a near-optimal policy with sample complexity polynomial in the size of the endogenous component and nearly independent of the size of the exogenous component, thereby offering a doubly-exponential improvement over off-the-shelf algorithms. Our results highlight for the first time that sample-efficient reinforcement learning is possible in the presence of exogenous information, and provide a simple, user-friendly benchmark for investigation going forward.
A Sharp Characterization of Linear Estimators for Offline Policy Evaluation
Mar 08, 2022Offline policy evaluation is a fundamental statistical problem in reinforcement learning that involves estimating the value function of some decision-making policy given data collected by a potentially different policy. In order to tackle problems with complex, high-dimensional observations, there has been significant interest from theoreticians and practitioners alike in understanding the possibility of function approximation in reinforcement learning. Despite significant study, a sharp characterization of when we might expect offline policy evaluation to be tractable, even in the simplest setting of linear function approximation, has so far remained elusive, with a surprising number of strong negative results recently appearing in the literature. In this work, we identify simple control-theoretic and linear-algebraic conditions that are necessary and sufficient for classical methods, in particular Fitted Q-iteration (FQI) and least squares temporal difference learning (LSTD), to succeed at offline policy evaluation. Using this characterization, we establish a precise hierarchy of regimes under which these estimators succeed. We prove that LSTD works under strictly weaker conditions than FQI. Furthermore, we establish that if a problem is not solvable via LSTD, then it cannot be solved by a broad class of linear estimators, even in the limit of infinite data. Taken together, our results provide a complete picture of the behavior of linear estimators for offline policy evaluation (OPE), unify previously disparate analyses of canonical algorithms, and provide significantly sharper notions of the underlying statistical complexity of OPE.
Understanding Contrastive Learning Requires Incorporating Inductive Biases
Feb 28, 2022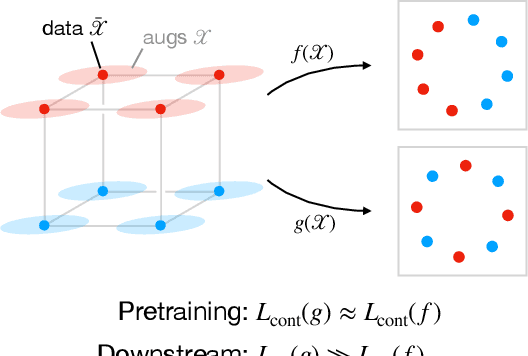
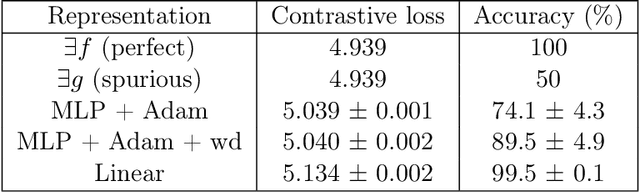
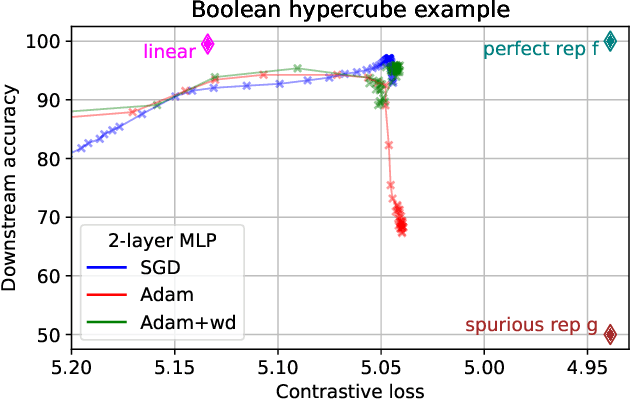
Contrastive learning is a popular form of self-supervised learning that encourages augmentations (views) of the same input to have more similar representations compared to augmentations of different inputs. Recent attempts to theoretically explain the success of contrastive learning on downstream classification tasks prove guarantees depending on properties of {\em augmentations} and the value of {\em contrastive loss} of representations. We demonstrate that such analyses, that ignore {\em inductive biases} of the function class and training algorithm, cannot adequately explain the success of contrastive learning, even {\em provably} leading to vacuous guarantees in some settings. Extensive experiments on image and text domains highlight the ubiquity of this problem -- different function classes and algorithms behave very differently on downstream tasks, despite having the same augmentations and contrastive losses. Theoretical analysis is presented for the class of linear representations, where incorporating inductive biases of the function class allows contrastive learning to work with less stringent conditions compared to prior analyses.
Provable Reinforcement Learning with a Short-Term Memory
Feb 08, 2022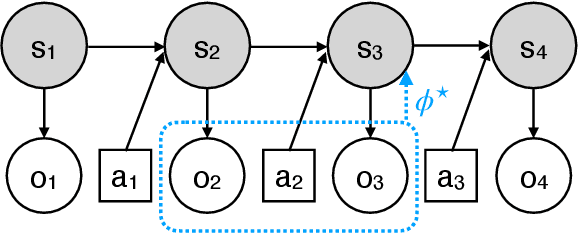
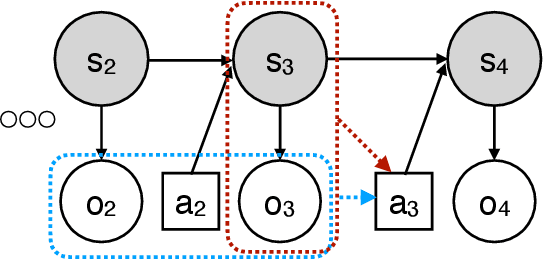
Real-world sequential decision making problems commonly involve partial observability, which requires the agent to maintain a memory of history in order to infer the latent states, plan and make good decisions. Coping with partial observability in general is extremely challenging, as a number of worst-case statistical and computational barriers are known in learning Partially Observable Markov Decision Processes (POMDPs). Motivated by the problem structure in several physical applications, as well as a commonly used technique known as "frame stacking", this paper proposes to study a new subclass of POMDPs, whose latent states can be decoded by the most recent history of a short length $m$. We establish a set of upper and lower bounds on the sample complexity for learning near-optimal policies for this class of problems in both tabular and rich-observation settings (where the number of observations is enormous). In particular, in the rich-observation setting, we develop new algorithms using a novel "moment matching" approach with a sample complexity that scales exponentially with the short length $m$ rather than the problem horizon, and is independent of the number of observations. Our results show that a short-term memory suffices for reinforcement learning in these environments.
Efficient and Optimal Algorithms for Contextual Dueling Bandits under Realizability
Nov 24, 2021We study the $K$-armed contextual dueling bandit problem, a sequential decision making setting in which the learner uses contextual information to make two decisions, but only observes \emph{preference-based feedback} suggesting that one decision was better than the other. We focus on the regret minimization problem under realizability, where the feedback is generated by a pairwise preference matrix that is well-specified by a given function class $\mathcal F$. We provide a new algorithm that achieves the optimal regret rate for a new notion of best response regret, which is a strictly stronger performance measure than those considered in prior works. The algorithm is also computationally efficient, running in polynomial time assuming access to an online oracle for square loss regression over $\mathcal F$. This resolves an open problem of Dud\'ik et al. [2015] on oracle efficient, regret-optimal algorithms for contextual dueling bandits.
Offline Reinforcement Learning: Fundamental Barriers for Value Function Approximation
Nov 21, 2021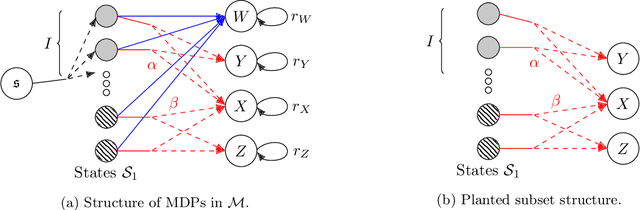
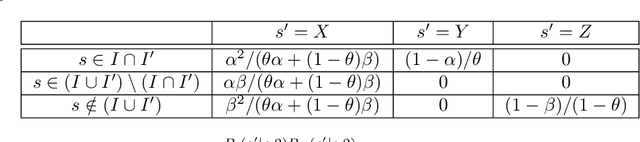
We consider the offline reinforcement learning problem, where the aim is to learn a decision making policy from logged data. Offline RL -- particularly when coupled with (value) function approximation to allow for generalization in large or continuous state spaces -- is becoming increasingly relevant in practice, because it avoids costly and time-consuming online data collection and is well suited to safety-critical domains. Existing sample complexity guarantees for offline value function approximation methods typically require both (1) distributional assumptions (i.e., good coverage) and (2) representational assumptions (i.e., ability to represent some or all $Q$-value functions) stronger than what is required for supervised learning. However, the necessity of these conditions and the fundamental limits of offline RL are not well understood in spite of decades of research. This led Chen and Jiang (2019) to conjecture that concentrability (the most standard notion of coverage) and realizability (the weakest representation condition) alone are not sufficient for sample-efficient offline RL. We resolve this conjecture in the positive by proving that in general, even if both concentrability and realizability are satisfied, any algorithm requires sample complexity polynomial in the size of the state space to learn a non-trivial policy. Our results show that sample-efficient offline reinforcement learning requires either restrictive coverage conditions or representation conditions that go beyond supervised learning, and highlight a phenomenon called over-coverage which serves as a fundamental barrier for offline value function approximation methods. A consequence of our results for reinforcement learning with linear function approximation is that the separation between online and offline RL can be arbitrarily large, even in constant dimension.