 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeIntegrating High-Resolution Tactile Sensing into Grasp Stability Prediction
Jun 12, 2022

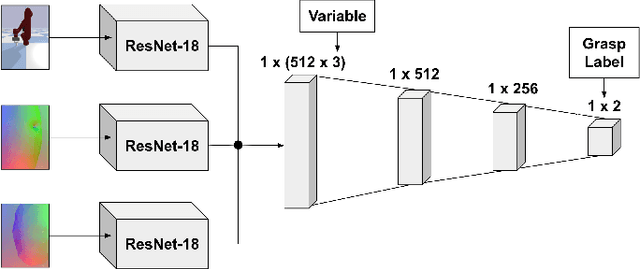
We investigate how high-resolution tactile sensors can be utilized in combination with vision and depth sensing, to improve grasp stability prediction. Recent advances in simulating high-resolution tactile sensing, in particular the TACTO simulator, enabled us to evaluate how neural networks can be trained with a combination of sensing modalities. With the large amounts of data needed to train large neural networks, robotic simulators provide a fast way to automate the data collection process. We expand on the existing work through an ablation study and an increased set of objects taken from the YCB benchmark set. Our results indicate that while the combination of vision, depth, and tactile sensing provides the best prediction results on known objects, the network fails to generalize to unknown objects. Our work also addresses existing issues with robotic grasping in tactile simulation and how to overcome them.
Shared-Control Robotic Manipulation in Virtual Reality
May 21, 2022



In this paper, we present the implementation details of a Virtual Reality (VR)-based teleoperation interface for moving a robotic manipulator. We propose an iterative human-in-the-loop design where the user sets the next task-space waypoint for the robot's end effector and executes the action on the physical robot before setting the next waypoints. Information from the robot's surroundings is provided to the user in two forms: as a point cloud in 3D space and a video stream projected on a virtual wall. The feasibility of the selected end effector pose is communicated to the user by the color of the virtual end effector. The interface is demonstrated to successfully work for a pick and place scenario, however, our trials showed that the fluency of the interaction and the autonomy level of the system can be increased.
AR Point&Click: An Interface for Setting Robot Navigation Goals
Mar 29, 2022


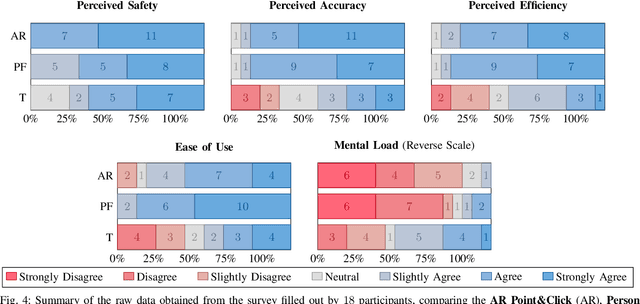
This paper considers the problem of designating navigation goal locations for interactive mobile robots. We propose a point-and-click interface, implemented with an Augmented Reality (AR) headset. The cameras on the AR headset are used to detect natural pointing gestures performed by the user. The selected goal is visualized through the AR headset, allowing the users to adjust the goal location if desired. We conduct a user study in which participants set consecutive navigation goals for the robot using three different interfaces: AR Point & Click, Person Following and Tablet (birdeye map view). Results show that the proposed AR Point&Click interface improved the perceived accuracy, efficiency and reduced mental load compared to the baseline tablet interface, and it performed on-par to the Person Following method. These results show that the AR Point\&Click is a feasible interaction model for setting navigation goals.
On-The-Go Robot-to-Human Handovers with a Mobile Manipulator
Mar 16, 2022
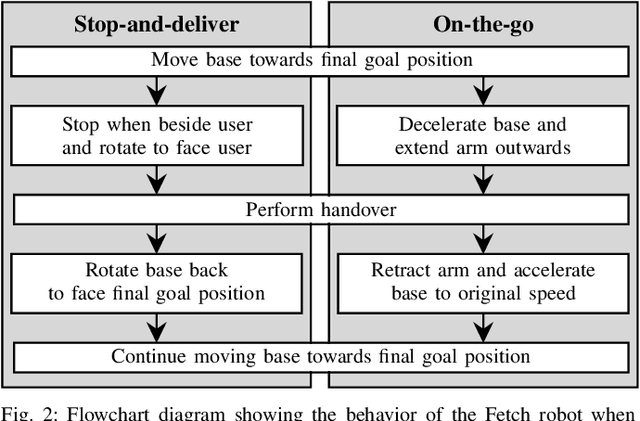

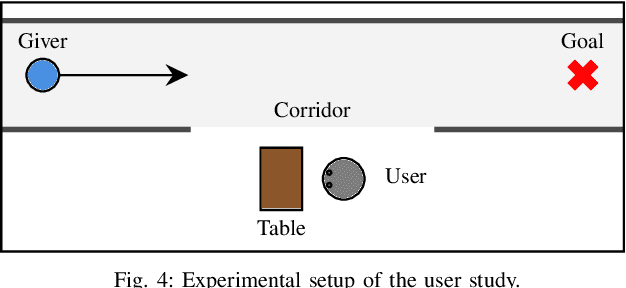
Existing approaches to direct robot-to-human handovers are typically implemented on fixed-base robot arms, or on mobile manipulators that come to a full stop before performing the handover. We propose "on-the-go" handovers which permit a moving mobile manipulator to hand over an object to a human without stopping. The on-the-go handover motion is generated with a reactive controller that allows simultaneous control of the base and the arm. In a user study, human receivers subjectively assessed on-the-go handovers to be more efficient, predictable, natural, better timed and safer than handovers that implemented a "stop-and-deliver" behavior.
Visibility Maximization Controller for Robotic Manipulation
Feb 25, 2022
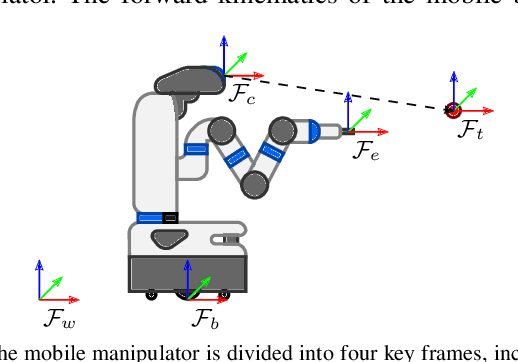
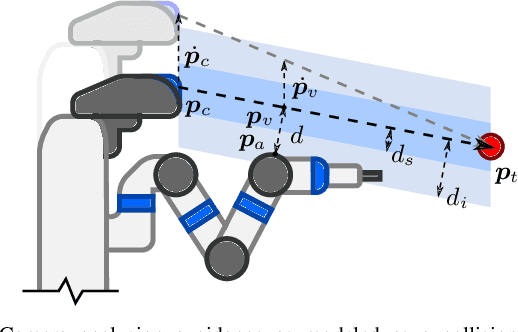
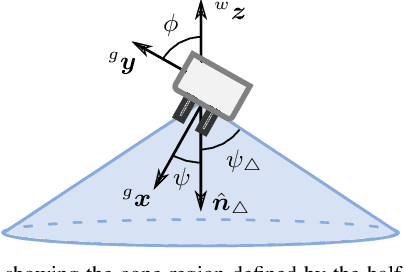
Occlusions caused by a robot's own body is a common problem for closed-loop control methods employed in eye-to-hand camera setups. We propose an optimization-based reactive controller that minimizes self-occlusions while achieving a desired goal pose. The approach allows coordinated control between the robot's base, arm and head by encoding the line-of-sight visibility to the target as a soft constraint along with other task-related constraints, and solving for feasible joint and base velocities. The generalizability of the approach is demonstrated in simulated and real-world experiments, on robots with fixed or mobile bases, with moving or fixed objects, and multiple objects. The experiments revealed a trade-off between occlusion rates and other task metrics. While a planning-based baseline achieved lower occlusion rates than the proposed controller, it came at the expense of highly inefficient paths and a significant drop in the task success. On the other hand, the proposed controller is shown to improve visibility to the line target object(s) without sacrificing too much from the task success and efficiency. Videos and code can be found at: rhys-newbury.github.io/projects/vmc/.
Metrics for Evaluating Social Conformity of Crowd Navigation Algorithms
Feb 02, 2022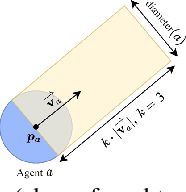
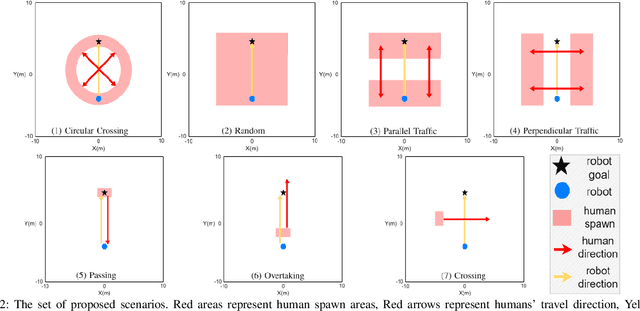


Recent protocols and metrics for training and evaluating autonomous robot navigation through crowds are inconsistent due to diversified definitions of "social behavior". This makes it difficult, if not impossible, to effectively compare published navigation algorithms. Furthermore, with the lack of a good evaluation protocol, resulting algorithms may fail to generalize, due to lack of diversity in training. To address these gaps, this paper facilitates a more comprehensive evaluation and objective comparison of crowd navigation algorithms by proposing a consistent set of metrics that accounts for both efficiency and social conformity, and a systematic protocol comprising multiple crowd navigation scenarios of varying complexity for evaluation. We tested four state-of-the-art algorithms under this protocol. Results revealed that some state-of-the-art algorithms have much challenge in generalizing, and using our protocol for training, we were able to improve the algorithm's performance. We demonstrate that the set of proposed metrics provides more insight and effectively differentiates the performance of these algorithms with respect to efficiency and social conformity.
Speed Maps: An Application to Guide Robots in Human Environments
Nov 04, 2021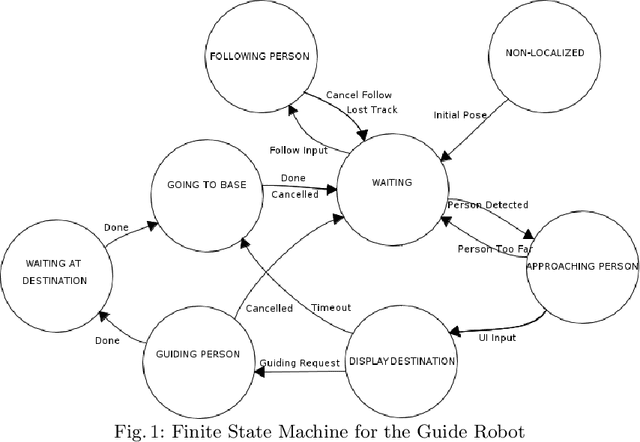
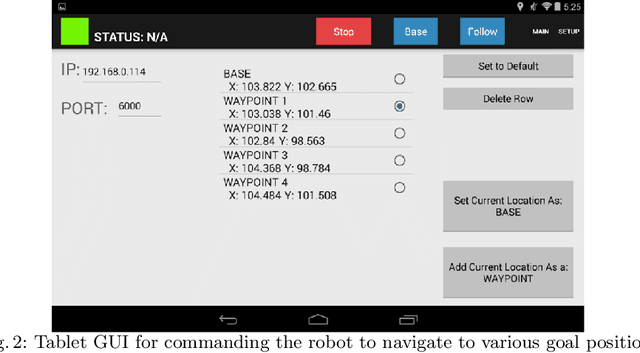


We present the concept of speed maps: speed limits for mobile robots in human environments. Static speed maps allow for faster navigation on corridors while limiting the speed around corners and in rooms. Dynamic speed maps put limits on speed around humans. We demonstrate the concept for a mobile robot that guides people to annotated landmarks on the map. The robot keeps a metric map for navigation and a semantic map to hold planar surfaces for tasking. The system supports automatic initialization upon the detection of a specially designed QR code. We show that speed maps not only can reduce the impact of a potential collision but can also reduce navigation time.
ARviz -- An Augmented Reality-enabled Visualization Platform for ROS Applications
Oct 29, 2021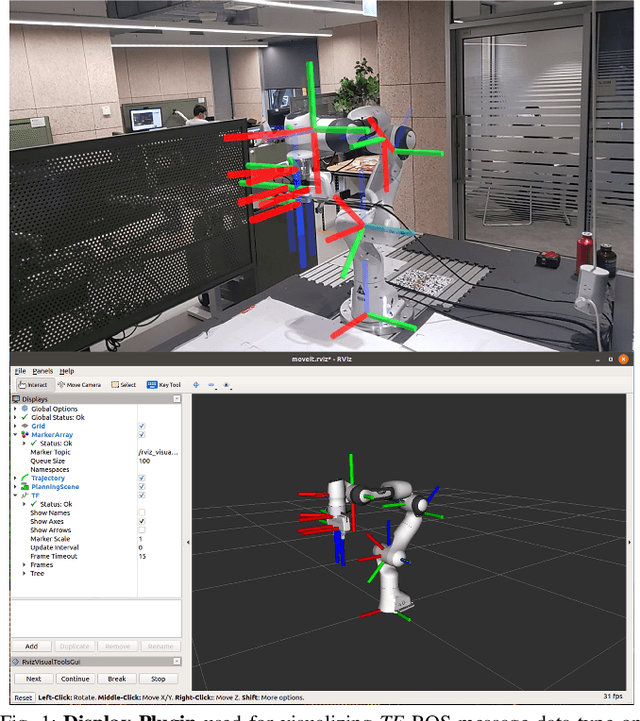
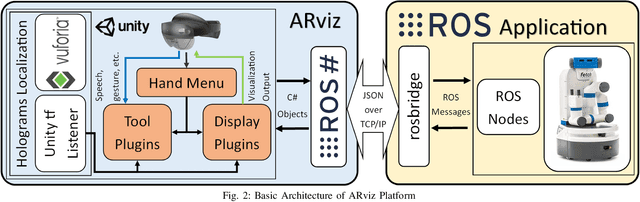


Current robot interfaces such as teach pendants and 2D screen displays used for task visualization and interaction often seem unintuitive and limited in terms of information flow. This compromises task efficiency as interacting with the interface can distract the user from the task at hand. Augmented Reality (AR) technology offers the capability to create visually rich displays and intuitive interaction elements in situ. In recent years, AR has shown promising potential to enable effective human-robot interaction. We introduce ARviz - a versatile, extendable AR visualization platform built for robot applications developed with the widely used Robot Operating System (ROS) framework. ARviz aims to provide both a universal visualization platform with the capability of displaying any ROS message data type in AR, as well as a multimodal user interface for interacting with robots over ROS. ARviz is built as a platform incorporating a collection of plugins that provide visualization and/or interaction components. Users can also extend the platform by implementing new plugins to suit their needs. We present three use cases as well as two potential use cases to showcase the capabilities and benefits of the ARviz platform for human-robot interaction applications. The open access source code for our ARviz platform is available at: https://github.com/hri-group/arviz.
Mixing Human Demonstrations with Self-Exploration in Experience Replay for Deep Reinforcement Learning
Jul 14, 2021
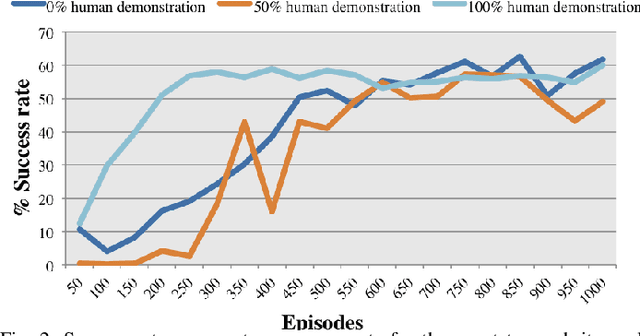
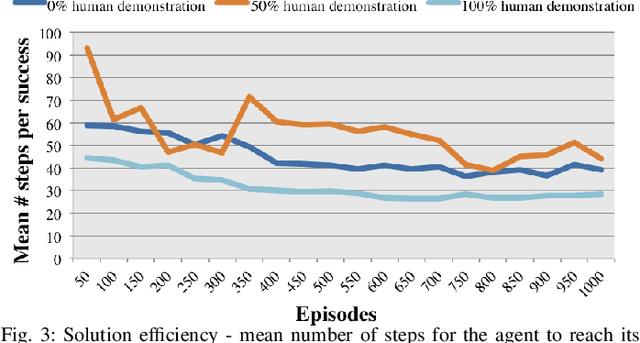
We investigate the effect of using human demonstration data in the replay buffer for Deep Reinforcement Learning. We use a policy gradient method with a modified experience replay buffer where a human demonstration experience is sampled with a given probability. We analyze different ratios of using demonstration data in a task where an agent attempts to reach a goal while avoiding obstacles. Our results suggest that while the agents trained by pure self-exploration and pure demonstration had similar success rates, the pure demonstration model converged faster to solutions with less number of steps.
Tabletop Object Rearrangement: Team ACRV's Entry to OCRTOC
Apr 15, 2021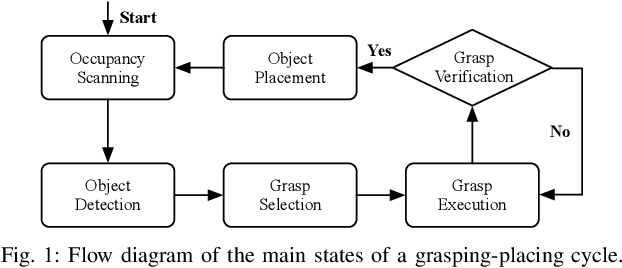
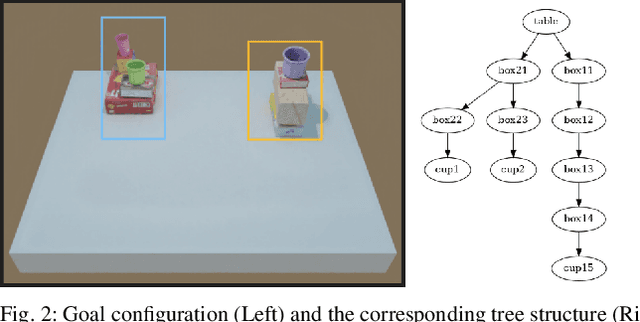
Open Cloud Robot Table Organization Challenge (OCRTOC) is one of the most comprehensive cloud-based robotic manipulation competitions. It focuses on rearranging tabletop objects using vision as its primary sensing modality. In this extended abstract, we present our entry to the OCRTOC2020 and the key challenges the team has experienced.